第三次作业
学号:2017*****7175
姓名:刘振林
2.
filename: word_freq.py
阅读注释,在所有pass处删除pass,添加代码
from string import punctuation
# 读文件到缓冲区
def process_file(dst):
try:
L=open(dst,"r") # 打开文件
except IOError as s:
print (s)
return None
try:
bvffer = L.read() # 读文件到缓冲区
except:
print ("Read File Error!")
return None
L.close()
return bvffer
def process_buffer(bvffer):
if bvffer:
word_freq = {}
# 下面添加处理缓冲区 bvffer代码,统计
单词的频率,存放在字典word_freq
for i in bvffer.split():
word_666 = i.strip(punctuation + " ")
if word_666 in word_freq:
word_freq[word_666] += 1
else:
word_freq[word_666] = 1
return word_freq
def output_result(word_freq):
if word_freq:
sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True)
for item in sorted_word_freq[:10]:
print(item)
if name == "main":
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('dst')
args = parser.parse_args()
dst = args.dst
bvffer = process_file(dst)
word_freq = process_buffer(bvffer)
output_result(word_freq)
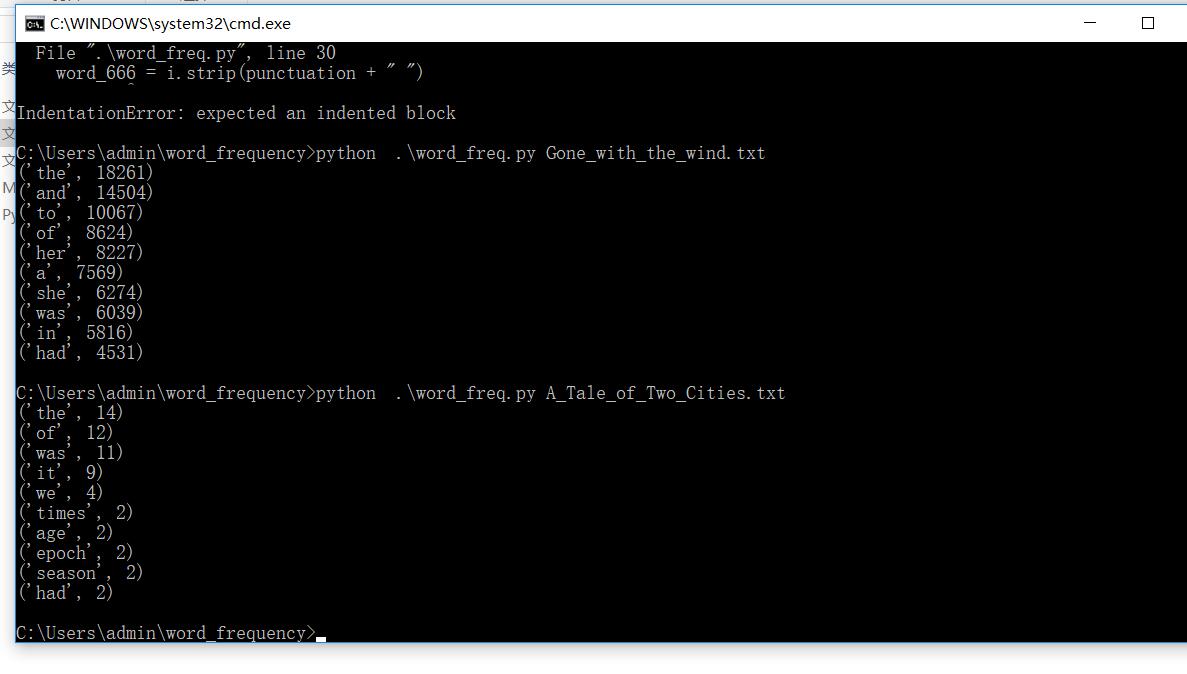
3.

4.
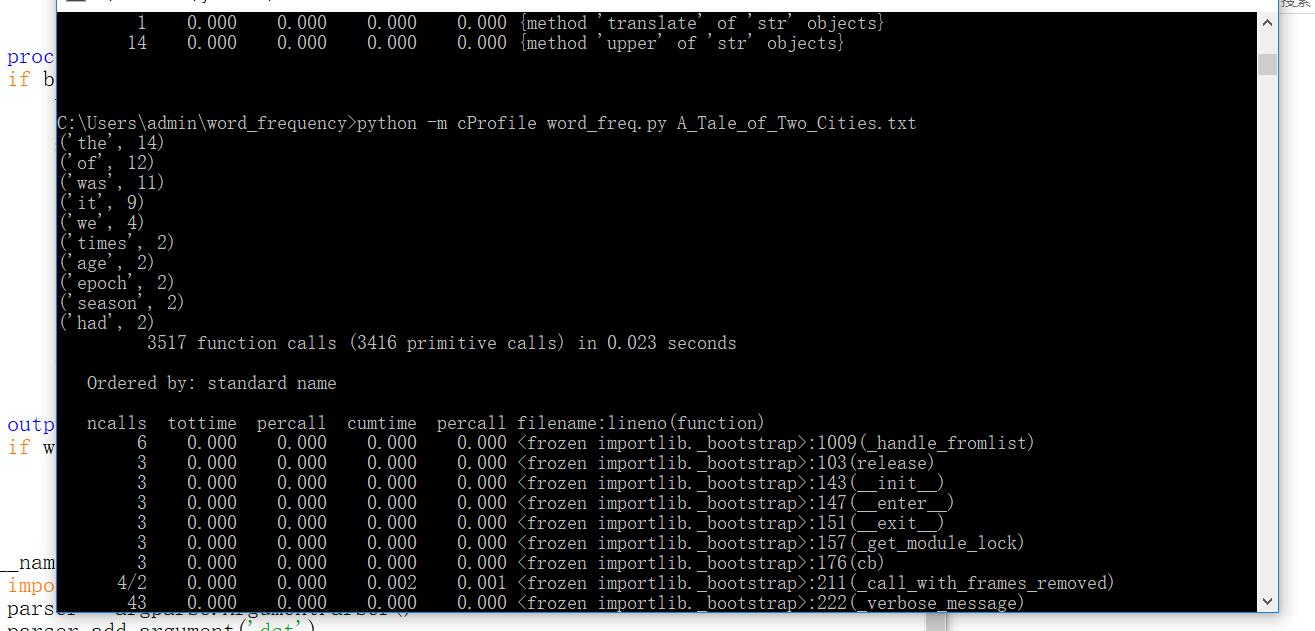
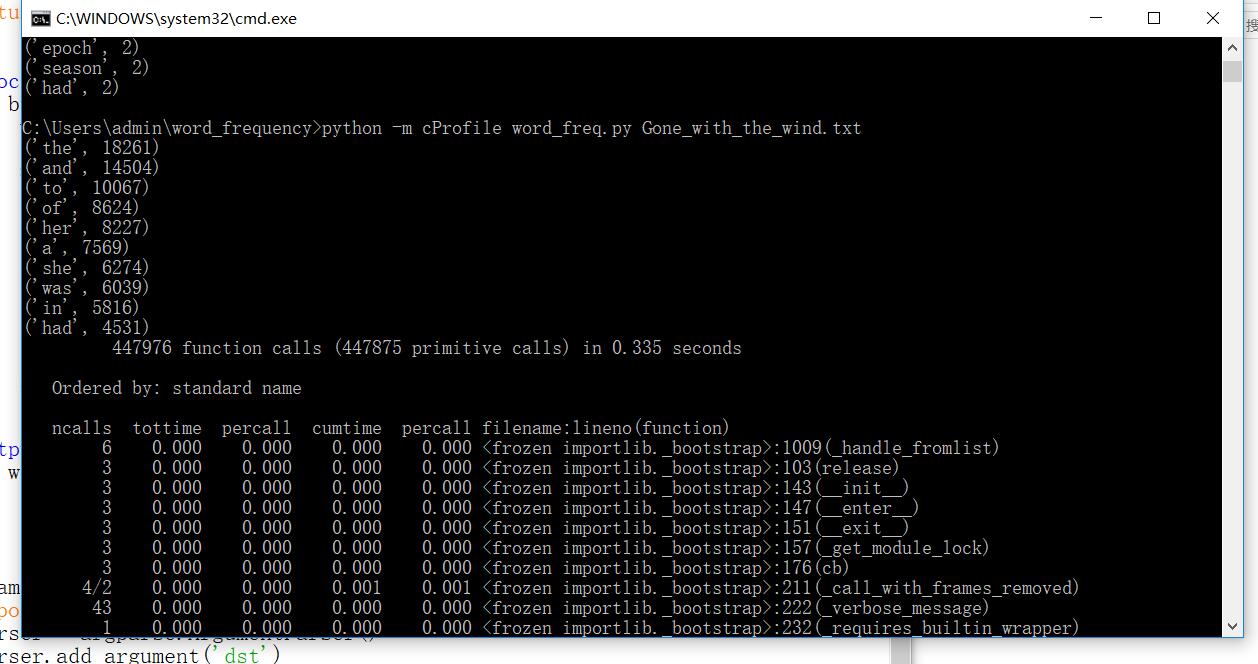
5.本次作业也让我更加熟练地运用python和Git

 浙公网安备 33010602011771号
浙公网安备 33010602011771号