

目录
前言:
接上篇文章 MySql优化(四)索引优化分析(详细总结),本篇文章将进行案例分析,从实际出发解析MySQL优化。
一、索引语法
建立索引的 SQL 语句
1、创建索引
- 如果是CHAR和VARCHAR类型,length可以小于字段实际长度;
- 如果是BLOB和TEXT类型,必须指定length。
CREATE [UNIQUE] INDEX indexName ON mytable(columnname(length));
' or '
ALTER mytable ADD [UNIQUE] INDEX [indexName] ON(columnname(length));
2、删除索引
DROP INDEX [indexName] ON mytable;
3、查看索引
#\G表示将查询到的横向表格纵向输出,方便阅读
SHOW INDEX FROM table_name\G
使用ALTER 命令,有四种方式来添加数据表的索引
-
ALTER TABLE tbl_name ADD PRIMARY KEY(column_list):该语句添加一个主键,这意味着索引值必须是唯一的,且不能为NULL。
-
ALTER TABLE tbl_name ADD UNIQUE index_name(column_list):这条语句创建索引的值必须是唯一的(除了NULL外,NULL可能会出现多次)。
-
ALTER TABLE tbl_name ADD INDEX index_name(column_list):.添加普通索引,索引值可出现多次。
-
ALTER TABLE tbl_name ADD FULLTEXT index_name(column_list):该语句指定了索引为FULLTEXT,用于全文索引。
查看 mysql 索引:Index_type 为 BTREE

二、索引的使用情况
什么情况下适合建立索引?
- 主键自动建立唯一索引
- 频繁作为查询的条件的字段应该创建索引
- 查询中与其他表关联的字段,外键关系建立索引
- 频繁更新的字段不适合创建索引
- Where 条件里用不到的字段不创建索引
- 单间/组合索引的选择问题,Who?(在高并发下倾向创建组合索引)
- 查询中排序的字段,排序字段若通过索引去访问将大大提高排序的速度
- 查询中统计或者分组字段
情况下不适合创建索引?
-
表记录太少
-
经常增删改的表
-
数据重复且分布平均的表字段,因此应该只为经常查询和经常排序的数据列建立索引。注意,如果某个数据列包含许多重复的内容,为它建立索引就没有太大的实际效果。
案例分析:
- 假如一个user表,有10万行记录,其中性别(gentle)字段只有两种值,分布概率大约为50%,那么对user表,性别(gentle)字段建索引一般不会提高数据库的查询速度。
- 索引的选择性是指索引列中不同值的数目与表中记录数的比。如果一个表中有2000条记录,表索引列有1980个不同的值,那么这个索引的选择性就是1980/2000=0.99。
- 一个索引的选择性越接近于1,这个索引的效率就越高。
三、索引优化
单表索引优化
1、创建案例表
CREATE TABLE IF NOT EXISTS article (
id INT (10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
author_id INT (10) UNSIGNED NOT NULL,
category_id INT (10) UNSIGNED NOT NULL,
views INT (10) UNSIGNED NOT NULL,
comments INT (10) UNSIGNED NOT NULL,
title VARCHAR (255) NOT NULL,
content TEXT NOT NULL
) ;
INSERT INTO article (
author_id,
category_id,
views,
comments,
title,
content
)
VALUES
(1, 1, 1, 1, '1', '1'),
(2, 2, 2, 2, '2', '2'),
(1, 1, 3, 3, '3', '3') ;
查询案例:
查询category_id为1且comments 大于1的情况下,views最多的article_id。
SELECT id, author_id FROM article WHERE category_id = 1 AND comments > 1 ORDER BY views DESC LIMIT 1;

此时 article 表中只有一个主键索引
我们使用 explain 分析 SQL 语句的执行效率:
EXPLAIN SELECT id, author_id FROM article WHERE category_id = 1 AND comments > 1 ORDER BY views DESC LIMIT 1;
结论:
-
type是ALL,即最坏的情况。
-
Extra 里还出现了Using filesort,也是最坏的情况。
-
优化是必须的。
优化过程:
创建索引
在 category_id 列、comments 列和 views 列上建立联合索引
# ALTER TABLE article ADD INDEX idx_article_ccv('category_id', 'comments', 'views');
create index idx_article_ccv on article(category_id, comments, views);
再次执行查询:type变成了range,这是可以忍受的。但是extra里使用Using filesort仍是无法接受的。
mysql> EXPLAIN SELECT id, author_id FROM article WHERE category_id = 1 AND comments > 1 ORDER BY views DESC LIMIT 1;
+----+-------------+---------+------------+-------+-----------------+-----------------+---------+------+------+----------+---------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+-----------------+-----------------+---------+------+------+----------+---------------------------------------+
| 1 | SIMPLE | article | NULL | range | idx_article_ccv | idx_article_ccv | 8 | NULL | 1 | 100.00 | Using index condition; Using filesort |
+----+-------------+---------+------------+-------+-----------------+-----------------+---------+------+------+----------+---------------------------------------+
1 row in set, 1 warning (0.00 sec)

分析:
-
按照B+Tree索引的工作原理,先排序 category_id,如果遇到相同的 category_id 则再排序comments,如果遇到相同的 comments 则再排序 views。
-
当comments字段在联合索引里处于中间位置时,因为comments>1条件是一个范围值(所谓 range),MySQL 无法利用索引再对后面的views部分进行检索,即 range 类型查询字段后面的索引无效。
将查询条件中的 comments > 1 改为 comments = 1 ,发现 Use filesort 神奇地消失了,从这点可以验证:范围后的索引会导致索引失效
mysql> EXPLAIN SELECT id, author_id FROM article WHERE category_id = 1 AND comments = 1 ORDER BY views DESC LIMIT 1;
+----+-------------+---------+------------+------+-----------------+-----------------+---------+-------------+------+----------+---------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+-----------------+-----------------+---------+-------------+------+----------+---------------------+
| 1 | SIMPLE | article | NULL | ref | idx_article_ccv | idx_article_ccv | 8 | const,const | 1 | 100.00 | Backward index scan |
+----+-------------+---------+------------+------+-----------------+-----------------+---------+-------------+------+----------+---------------------+
1 row in set, 1 warning (0.00 sec)

删除索引
删除刚才创建的 idx_article_ccv 索引
mysql> DROP INDEX idx_article_ccv ON article;
Query OK, 0 rows affected (0.04 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> SHOW INDEX FROM article;
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| article | 0 | PRIMARY | 1 | id | A | 3 | NULL | NULL | | BTREE | | | YES | NULL |
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
1 row in set (0.01 sec)
再次创建索引
create index idx_article_ccv on article(category_id, views);由于 range 后(comments > 1)的索引会失效,这次我们建立索引时,直接抛弃 comments 列,先利用 category_id 和 views 的联合索引查询所需要的数据,再从其中取出 comments > 1 的数据
再次执行查询:可以看到,type变为了ref,Extra中的Using filesort也消失了,结果非常理想
mysql> EXPLAIN SELECT id, author_id FROM article WHERE category_id = 1 AND comments > 1 ORDER BY views DESC LIMIT 1;
+----+-------------+---------+------------+------+-----------------+-----------------+---------+-------+------+----------+----------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+-----------------+-----------------+---------+-------+------+----------+----------------------------------+
| 1 | SIMPLE | article | NULL | ref | idx_article_ccv | idx_article_ccv | 4 | const | 2 | 33.33 | Using where; Backward index scan |
+----+-------------+---------+------------+------+-----------------+-----------------+---------+-------+------+----------+----------------------------------+
1 row in set, 1 warning (0.00 sec)
为了不影响之后的测试,删除该表的 idx_article_ccv 索引
DROP INDEX idx_article_ccv ON article;两表索引优化
两表索引优化分析:主外键
1、创建案例表
CREATE TABLE IF NOT EXISTS class(
id INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
card INT(10) UNSIGNED NOT NULL,
PRIMARY KEY(id)
);
CREATE TABLE IF NOT EXISTS book(
bookid INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
card INT(10) UNSIGNED NOT NULL,
PRIMARY KEY(bookid)
);
INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card) VALUES(FLOOR(1+(RAND()*20)));
2、查询案例
实现两表的连接,连接条件是 class.card = book.card
SELECT * FROM class LEFT JOIN book ON class.card = book.card;使用 explain 分析 SQL 语句的性能,可以看到:驱动表是左表 class 表
mysql> EXPLAIN SELECT * FROM class LEFT JOIN book ON class.card = book.card;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+--------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+--------------------------------------------+
| 1 | SIMPLE | class | NULL | ALL | NULL | NULL | NULL | NULL | 42 | 100.00 | NULL |
| 1 | SIMPLE | book | NULL | ALL | NULL | NULL | NULL | NULL | 40 | 100.00 | Using where; Using join buffer (hash join) |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+--------------------------------------------+
2 rows in set, 1 warning (0.00 sec)
结论:
- type 有 All ,rows 为表中数据总行数,说明 class 和 book 进行了全表检索
- 每次 class 表对 book 表进行左外连接时,都需要在 book 表中进行一次全表检索
添加索引:在右表添加索引
在 book 的 card 字段上添加索引:
mysql> ALTER TABLE book ADD INDEX Y (card);
Query OK, 0 rows affected (0.03 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> SHOW INDEX FROM book;
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| book | 0 | PRIMARY | 1 | bookid | A | 40 | NULL | NULL | | BTREE | | | YES | NULL |
| book | 1 | Y | 1 | card | A | 17 | NULL | NULL | | BTREE | | | YES | NULL |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
2 rows in set (0.01 sec)
测试结果:可以看到第二行的type变为了ref,rows也变成了优化比较明显。
mysql> EXPLAIN SELECT * FROM class LEFT JOIN book ON class.card = book.card;
+----+-------------+-------+------------+------+---------------+------+---------+------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------------------+------+----------+-------------+
| 1 | SIMPLE | class | NULL | ALL | NULL | NULL | NULL | NULL | 42 | 100.00 | NULL |
| 1 | SIMPLE | book | NULL | ref | Y | Y | 4 | Index.class.card | 2 | 100.00 | Using index |
+----+-------------+-------+------------+------+---------------+------+---------+------------------+------+----------+-------------+
2 rows in set, 1 warning (0.00 sec)
分析:
-
这是由左连接特性决定的。LEFT JOIN条件用于确定如何从右表搜索行,左边一定都有,所以右边是我们的关键点,一定需要建立索引。
-
左表连接右表,则需要拿着左表的数据去右表里面查,索引需要在右表中建立索引
添加索引:在右表添加索引
删除之前 book 表中的索引
DROP INDEX Y ON book;
在 class 表的 card 字段上建立索引
ALTER TABLE class ADD INDEX X(card);我们先执行左连接,
mysql> EXPLAIN SELECT * FROM class LEFT JOIN book ON class.card = book.card;
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+--------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+--------------------------------------------+
| 1 | SIMPLE | class | NULL | index | NULL | X | 4 | NULL | 42 | 100.00 | Using index |
| 1 | SIMPLE | book | NULL | ALL | NULL | NULL | NULL | NULL | 40 | 100.00 | Using where; Using join buffer (hash join) |
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+--------------------------------------------+
2 rows in set, 1 warning (0.00 sec)
接下来执行右连接:可以看到第二行的type变为了ref,rows也变成了优化比较明显。
mysql> EXPLAIN SELECT * FROM class RIGHT JOIN book ON class.card = book.card;
+----+-------------+-------+------------+------+---------------+------+---------+-----------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+-----------------+------+----------+-------------+
| 1 | SIMPLE | book | NULL | ALL | NULL | NULL | NULL | NULL | 40 | 100.00 | NULL |
| 1 | SIMPLE | class | NULL | ref | X | X | 4 | Index.book.card | 2 | 100.00 | Using index |
+----+-------------+-------+------------+------+---------------+------+---------+-----------------+------+----------+-------------+
2 rows in set, 1 warning (0.00 sec)分析:
-
这是因为RIGHT JOIN条件用于确定如何从左表搜索行,右边一定都有,所以左边是我们的关键点,一定需要建立索引。
-
class RIGHT JOIN book :book 里面的数据一定存在于结果集中,我们需要拿着 book 表中的数据,去 class 表中搜索,所以索引需要建立在 class 表中
为了不影响之后的测试,删除该表的 idx_article_ccv 索引;
DROP INDEX X ON class;三表索引优化
1、创建案例表
CREATE TABLE IF NOT EXISTS phone(
phoneid INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
card INT(10) UNSIGNED NOT NULL,
PRIMARY KEY(phoneid)
)ENGINE=INNODB;
INSERT INTO phone(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO phone(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO phone(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO phone(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO phone(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO phone(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO phone(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO phone(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO phone(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO phone(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO phone(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO phone(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO phone(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO phone(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO phone(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO phone(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO phone(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO phone(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO phone(card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO phone(card) VALUES(FLOOR(1+(RAND()*20)));
2、查询案例
实现三表的连接查询:
SELECT * FROM class LEFT JOIN book ON class.card = book.card LEFT JOIN phone ON book.card = phone.card;explain 分析 SQL 指令:
mysql> EXPLAIN SELECT * FROM class LEFT JOIN book ON class.card = book.card LEFT JOIN phone ON book.card = phone.card;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+--------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+--------------------------------------------+
| 1 | SIMPLE | class | NULL | ALL | NULL | NULL | NULL | NULL | 42 | 100.00 | NULL |
| 1 | SIMPLE | book | NULL | ALL | NULL | NULL | NULL | NULL | 40 | 100.00 | Using where; Using join buffer (hash join) |
| 1 | SIMPLE | phone | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 100.00 | Using where; Using join buffer (hash join) |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+--------------------------------------------+
3 rows in set, 1 warning (0.00 sec)
结论:
- type 有All ,rows 为表数据总行数,说明 class、 book 和 phone 表都进行了全表检索
- Extra 中 Using join buffer ,表明连接过程中使用了 join 缓冲区
创建索引:
ALTER TABLE book ADD INDEX Y (card);
ALTER TABLE phone ADD INDEX Z (card);进行 LEFT JOIN ,永远都在右表的字段上建立索引
mysql> EXPLAIN SELECT * FROM class LEFT JOIN book ON class.card=book.card LEFT JOIN phone ON book.card = phone.card;
+----+-------------+-------+------------+------+---------------+------+---------+------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------------------+------+----------+-------------+
| 1 | SIMPLE | class | NULL | ALL | NULL | NULL | NULL | NULL | 42 | 100.00 | NULL |
| 1 | SIMPLE | book | NULL | ref | Y | Y | 4 | Index.class.card | 2 | 100.00 | Using index |
| 1 | SIMPLE | phone | NULL | ref | Z | Z | 4 | Index.book.card | 1 | 100.00 | Using index |
+----+-------------+-------+------------+------+---------------+------+---------+------------------+------+----------+-------------+
3 rows in set, 1 warning (0.00 sec)
Join 语句优化的结论
将 left join 看作是两层嵌套 for 循环
- 尽可能减少Join语句中的NestedLoop的循环总次数;
- 永远用小结果集驱动大的结果集(在大结果集中建立索引,在小结果集中遍历全表);
- 优先优化NestedLoop的内层循环;
- 保证Join语句中被驱动表上Join条件字段已经被索引;
- 当无法保证被驱动表的Join条件字段被索引且内存资源充足的前提下,不要太吝惜JoinBuffer的设置;
四、索引失效
索引失效准则
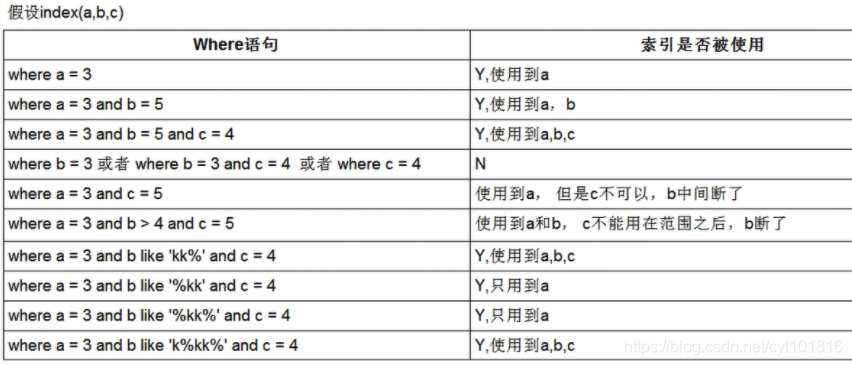
- 全值匹配我最爱
- 最佳左前缀法则:如果索引了多例,要遵守最左前缀法则。指的是查询从索引的最左前列开始并且不跳过索引中的列。
- 不在索引列上做任何操作(计算、函数、(自动or手动)类型转换),会导致索引失效而转向全表扫描
- 存储引擎不能使用索引中范围条件右边的列
- 尽量使用覆盖索引(只访问索引的查询(索引列和查询列一致)),减少select *
- mysql在使用不等于(!=或者<>)的时候无法使用索引会导致全表扫描
- is null,is not null 也无法使用索引(早期版本不能走索引,后续版本应该优化过,可以走索引)
- like以通配符开头(’%abc…’)mysql索引失效会变成全表扫描操作
- 字符串不加单引号索引失效
- 少用or,用它连接时会索引失效
索引优化面试题
索引优化面试题
create table test03(
id int primary key not null auto_increment,
c1 char(10),
c2 char(10),
c3 char(10),
c4 char(10),
c5 char(10)
);
insert into test03(c1,c2,c3,c4,c5) values ('a1','a2','a3','a4','a5');
insert into test03(c1,c2,c3,c4,c5) values ('b1','b2','b3','b4','b5');
insert into test03(c1,c2,c3,c4,c5) values ('c1','c2','c3','c4','c5');
insert into test03(c1,c2,c3,c4,c5) values ('d1','d2','d3','d4','d5');
insert into test03(c1,c2,c3,c4,c5) values ('e1','e2','e3','e4','e5');
create index idx_test03_c1234 on test03(c1,c2,c3,c4);
问题:我们创建了复合索引idx_test03_c1234,根据以下SQL分析下索引使用情况?
EXPLAIN SELECT * FROM test03 WHERE c1='a1' AND c2='a2' AND c3='a3' AND c4='a4';
全值匹配
mysql> EXPLAIN SELECT * FROM test03 WHERE c1='a1' AND c2='a2' AND c3='a3' AND c4='a4';
+----+-------------+--------+------------+------+------------------+------------------+---------+-------------------------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+------------------+------------------+---------+-------------------------+------+----------+-------+
| 1 | SIMPLE | test03 | NULL | ref | idx_test03_c1234 | idx_test03_c1234 | 124 | const,const,const,const | 1 | 100.00 | NULL |
+----+-------------+--------+------------+------+------------------+------------------+---------+-------------------------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
EXPLAIN SELECT * FROM test03 WHERE c4='a4' AND c3='a3' AND c2='a2' AND c1='a1';
mysql 优化器进行了优化,所以我们的索引都生效了
mysql> EXPLAIN SELECT * FROM test03 WHERE c4='a4' AND c3='a3' AND c2='a2' AND c1='a1';
+----+-------------+--------+------------+------+------------------+------------------+---------+-------------------------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+------------------+------------------+---------+-------------------------+------+----------+-------+
| 1 | SIMPLE | test03 | NULL | ref | idx_test03_c1234 | idx_test03_c1234 | 124 | const,const,const,const | 1 | 100.00 | NULL |
+----+-------------+--------+------------+------+------------------+------------------+---------+-------------------------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)EXPLAIN SELECT * FROM test03 WHERE c1='a1' AND c2='a2' AND c3>'a3' AND c4='a4';
c3 列使用了索引进行排序,并没有进行查找,导致 c4 无法用索引进行查找
mysql> EXPLAIN SELECT * FROM test03 WHERE c1='a1' AND c2='a2' AND c3>'a3' AND c4='a4';
+----+-------------+--------+------------+-------+------------------+------------------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+------------------+------------------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | test03 | NULL | range | idx_test03_c1234 | idx_test03_c1234 | 93 | NULL | 1 | 20.00 | Using index condition |
+----+-------------+--------+------------+-------+------------------+------------------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
EXPLAIN SELECT * FROM test03 WHERE c1='a1' AND c2='a2' AND c4>'a4' AND c3='a3';
mysql 优化器进行了优化,所以我们的索引都生效了,在 c4 时进行了范围搜索
mysql> EXPLAIN SELECT * FROM test03 WHERE c1='a1' AND c2='a2' AND c4>'a4' AND c3='a3';
+----+-------------+--------+------------+-------+------------------+------------------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+------------------+------------------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | test03 | NULL | range | idx_test03_c1234 | idx_test03_c1234 | 124 | NULL | 1 | 100.00 | Using index condition |
+----+-------------+--------+------------+-------+------------------+------------------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)EXPLAIN SELECT * FROM test03 WHERE c1='a1' AND c2='a2' AND c4='a4' ORDER BY c3;
c3 列将索引用于排序,而不是查找,c4 列没有用到索引
mysql> EXPLAIN SELECT * FROM test03 WHERE c1='a1' AND c2='a2' AND c4='a4' ORDER BY c3;
+----+-------------+--------+------------+------+------------------+------------------+---------+-------------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+------------------+------------------+---------+-------------+------+----------+-----------------------+
| 1 | SIMPLE | test03 | NULL | ref | idx_test03_c1234 | idx_test03_c1234 | 62 | const,const | 1 | 20.00 | Using index condition |
+----+-------------+--------+------------+------+------------------+------------------+---------+-------------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)EXPLAIN SELECT * FROM test03 WHERE c1='a1' AND c2='a2' ORDER BY c3;
c4 列都没有用到索引
mysql> EXPLAIN SELECT * FROM test03 WHERE c1='a1' AND c2='a2' ORDER BY c3;
+----+-------------+--------+------------+------+------------------+------------------+---------+-------------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+------------------+------------------+---------+-------------+------+----------+-------+
| 1 | SIMPLE | test03 | NULL | ref | idx_test03_c1234 | idx_test03_c1234 | 62 | const,const | 1 | 100.00 | NULL |
+----+-------------+--------+------------+------+------------------+------------------+---------+-------------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
EXPLAIN SELECT * FROM test03 WHERE c1='a1' AND c2='a2' ORDER BY c4;
因为索引建立的顺序和使用的顺序不一致,导致 mysql 动用了文件排序
看到 Using filesort 就要知道:此句 SQL 必须优化
mysql> EXPLAIN SELECT * FROM test03 WHERE c1='a1' AND c2='a2' ORDER BY c4;
+----+-------------+--------+------------+------+------------------+------------------+---------+-------------+------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+------------------+------------------+---------+-------------+------+----------+----------------+
| 1 | SIMPLE | test03 | NULL | ref | idx_test03_c1234 | idx_test03_c1234 | 62 | const,const | 1 | 100.00 | Using filesort |
+----+-------------+--------+------------+------+------------------+------------------+---------+-------------+------+----------+----------------+
1 row in set, 1 warning (0.00 sec)EXPLAIN SELECT * FROM test03 WHERE c1='a1' AND c5='a5' ORDER BY c2, c3;
只用 c1 一个字段索引,但是c2、c3用于排序,无filesort
难道因为排序的时候,c2 紧跟在 c1 之后,所以就不用 filesort 吗?
mysql> EXPLAIN SELECT * FROM test03 WHERE c1='a1' AND c5='a5' ORDER BY c2, c3;
+----+-------------+--------+------------+------+------------------+------------------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+------------------+------------------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | test03 | NULL | ref | idx_test03_c1234 | idx_test03_c1234 | 31 | const | 1 | 20.00 | Using where |
+----+-------------+--------+------------+------+------------------+------------------+---------+-------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
EXPLAIN SELECT * FROM test03 WHERE c1='a1' AND c5='a5' ORDER BY c3, c2;
出现了filesort,我们建的索引是1234,它没有按照顺序来,32颠倒了
mysql> EXPLAIN SELECT * FROM test03 WHERE c1='a1' AND c5='a5' ORDER BY c3, c2;
+----+-------------+--------+------------+------+------------------+------------------+---------+-------+------+----------+-----------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+------------------+------------------+---------+-------+------+----------+-----------------------------+
| 1 | SIMPLE | test03 | NULL | ref | idx_test03_c1234 | idx_test03_c1234 | 31 | const | 1 | 20.00 | Using where; Using filesort |
+----+-------------+--------+------------+------+------------------+------------------+---------+-------+------+----------+-----------------------------+
1 row in set, 1 warning (0.00 sec)
EXPLAIN SELECT * FROM test03 WHERE c1='a1' AND c2='a2' ORDER BY c2, c3;
用c1、c2两个字段索引,但是c2、c3用于排序,无filesort
mysql> EXPLAIN SELECT * FROM test03 WHERE c1='a1' AND c2='a2' ORDER BY c2, c3;
+----+-------------+--------+------------+------+------------------+------------------+---------+-------------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+------------------+------------------+---------+-------------+------+----------+-------+
| 1 | SIMPLE | test03 | NULL | ref | idx_test03_c1234 | idx_test03_c1234 | 62 | const,const | 1 | 100.00 | NULL |
+----+-------------+--------+------------+------+------------------+------------------+---------+-------------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)EXPLAIN SELECT * FROM test03 WHERE c1='a1' AND c2='a2' AND c5='a5' ORDER BY c2, c3;
和 c5 没啥关系
mysql> EXPLAIN SELECT * FROM test03 WHERE c1='a1' AND c2='a2' AND c5='a5' ORDER BY c2, c3;
+----+-------------+--------+------------+------+------------------+------------------+---------+-------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+------------------+------------------+---------+-------------+------+----------+-------------+
| 1 | SIMPLE | test03 | NULL | ref | idx_test03_c1234 | idx_test03_c1234 | 62 | const,const | 1 | 20.00 | Using where |
+----+-------------+--------+------------+------+------------------+------------------+---------+-------------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)EXPLAIN SELECT * FROM test03 WHERE c1='a1' AND c2='a2' AND c5='a5' ORDER BY c3, c2;
注意查询条件 c2=‘a2’ ,我都把 c2 查出来了(c2 为常量),我还给它排序作甚,所以没有产生 filesort
mysql> EXPLAIN SELECT * FROM test03 WHERE c1='a1' AND c2='a2' AND c5='a5' ORDER BY c3, c2;
+----+-------------+--------+------------+------+------------------+------------------+---------+-------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+------------------+------------------+---------+-------------+------+----------+-------------+
| 1 | SIMPLE | test03 | NULL | ref | idx_test03_c1234 | idx_test03_c1234 | 62 | const,const | 1 | 20.00 | Using where |
+----+-------------+--------+------------+------+------------------+------------------+---------+-------------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)EXPLAIN SELECT * FROM test03 WHERE c1='a1' AND c4='a4' GROUP BY c2, c3;
顺序为 1 2 3 ,没有产生文件排序
mysql> EXPLAIN SELECT * FROM test03 WHERE c1='a1' AND c4='a4' GROUP BY c2, c3;
+----+-------------+--------+------+------------------+------------------+---------+-------+------+------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+------+------------------+------------------+---------+-------+------+------------------------------------+
| 1 | SIMPLE | test03 | ref | idx_test03_c1234 | idx_test03_c1234 | 31 | const | 1 | Using index condition; Using where |
+----+-------------+--------+------+------------------+------------------+---------+-------+------+------------------------------------+
1 row in set (0.00 sec)
EXPLAIN SELECT * FROM test03 WHERE c1='a1' AND c4='a4' GROUP BY c3, c2;
group by 表面上叫分组,分组之前必排序,group by 和 order by 在索引上的问题基本是一样的
Using temporary; Using filesort 两个都有
mysql> EXPLAIN SELECT * FROM test03 WHERE c1='a1' AND c4='a4' GROUP BY c3, c2;
+----+-------------+--------+------+------------------+------------------+---------+-------+------+---------------------------------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+------+------------------+------------------+---------+-------+------+---------------------------------------------------------------------+
| 1 | SIMPLE | test03 | ref | idx_test03_c1234 | idx_test03_c1234 | 31 | const | 1 | Using index condition; Using where; Using temporary; Using filesort |
+----+-------------+--------+------+------------------+------------------+---------+-------+------+---------------------------------------------------------------------+
1 row in set (0.01 sec)
结论:
- group by 基本上都需要进行排序,但凡使用不当,会有临时表产生
- 定值为常量、范围之后失效,最终看排序的顺序
索引失效总结
- 对于单键索引,尽量选择针对当前query过滤性更好的索引
- 在选择组合索引的时候,当前query中过滤性最好的字段在索引字段顺序中,位置越靠左越好。
- 在选择组合索引的时候,尽量选择可以能包含当前query中的where子句中更多字段的索引
- 尽可能通过分析统计信息和调整query的写法来达到选择合适索引的目的
like 后面以常量开头,比如 like ‘kk%’ 和 like ‘k%kk%’ ,可以理解为就是常量
说明:本篇文章为上篇文章的内容补充,主要内容为案例分析,对于索引的使用恰到好处即可!
本文中用到的案例均为《尚硅谷——阳哥MySQL优化》,大家也可以学习,个人推荐!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号