

- 了解 elasticsearch 的基本概念及搜索的整体流程
- 理解 elasticsearch 涉及的关键性名词
- elasticsearch 环境搭建
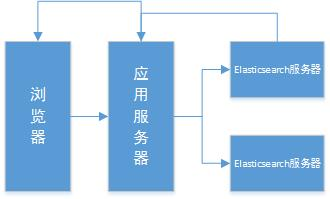
ElasticSearch 是一个基于 Lucene 的搜索服务器。它是一个分布式多用户能力的全文搜索引擎,基于 RESTful web 接口。Elasticsearch 是用 Java 开发的。
目前 Elasticsearch 与阿里云携手合作在阿里云上提供的 Elasticsearch 和 Kibana 托管云服务,包含 X-Pack 全部功能。目前应用 elasticsearch 构建搜索系统的公司有:Github 使用 Elasticsearch 搜索 TB 级别的数据、Sony(Sony 公司使用 elasticsearch 作为信息搜索引擎)国内有赶集网、京东等
cluster(集群)
代表一个集群,集群中有多个节点,其中有一个为主节点,默认这个主节点是可以通过选举产生的,配置方式可指定哪些节点主节点,哪些节点数据节点,主从节点是对于集群内部来说的。es 的一个概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部来说的,因为从外部来看 es 集群,在逻辑上是个整体,你与任何一个节点的通信和与整个 es 集群通信是等价的。
shards(分片)
代表索引分片,es 可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索,可提高搜索性能,当然也不是越大越好,还是要看你要存储的数据量,如果数据量大,可把分片设置大点,数据量小,可把分片设置小点,默认是 5 个分片,分片的数量只能在索引创建前指定,并且索引创建后不能更改。
replicas(副本)
代表索引副本,es 可以设置多个索引的副本,副本的作用一是提高系统的容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复。二是提高 es 的查询效率,es 会自动对搜索请求进行负载均衡。默认是 1 个副本。
gateway
代表 es 索引快照的存储方式,es 默认是先把索引存放到内存中,当内存满了时再持久化到本地硬盘,默认是 1 g,官方建议一个节点最大不超过 32G,超过 32G 性能反而会下降。gateway 对索引快照进行存储,当这个 es 集群关闭再重新启动时就会从 gateway 中读取索引备份数据。
discovery.zen
代表 es 的自动发现节点机制,es 是一个基于 p2p 的系统,它先通过广播寻找存在的节点,再通过多播协议来进行节点之间的通信,同时也支持点对点的交互。早期的版本不需要任何配置,只要在一个网段,启动后就会组成集群,非常方便,但是同时也带来了问题,某台机器的测试数据和另一台机器的数据会互相同步。
Transport
代表 es 内部节点或集群与客户端的交互方式,默认内部是使用 tcp 协议进行交互,同时它支持 http 协议(json 格式)、thrift、servlet、memcached、zeroMQ 等的传输协议(通过插件方式集成)java 客户端的方式是以 tcp 协议在 9300 端口上进行通信 http 客户端的方式是以 http 协议在 9200 端口上进行通信。
elasticsearch 安装
配置java环境变量
export ES_HOME=/home/lizejun/Desktop/elk/elasticsearch-2.3.4
export JAVA_HOME=/usr/local/jdk1.8.0_231/
export PATH=.:$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
source /etc/profile
sudo wget https://labfile.oss.aliyuncs.com/courses/1014/elasticsearch-2.3.4.zip
unzip elasticsearch-2.3.4.zip
cd elasticsearch-2.3.4/
mkdir logs
mkdir data
cd bin/
sudo wget https://labfile.oss.aliyuncs.com/courses/1014/elasticsearch-servicewrapper-master.zip
github地址: https://github.com/elastic/elasticsearch-servicewrapper
unzip elasticsearch-servicewrapper-master.zip
mv elasticsearch-servicewrapper-master/service/ .
修改配置 elasticsearch-2.3.4/bin/service/elasticsearch.conf 和 elasticsearch-2.3.4/config/elasticsearch.yml
vim service/elasticsearch.conf
wrapper.java.classpath.1=%ES_HOME%/bin/service/lib/wrapper.jar
#wrapper.java.classpath.2=%ES_HOME%/lib/elasticsearch*.jar
wrapper.java.classpath.2=%ES_HOME%/lib/*.jar
wrapper.java.classpath.3=%ES_HOME%/lib/sigar/*.jar
# Initial Java Heap Size (in MB)
wrapper.java.initmemory=%ES_HEAP_SIZE%
wrapper.java.additional.10=-Des.insecure.allow.root=true
启动参数
# Application parameters. Add parameters as needed starting from 1
#wrapper.app.parameter.1=org.elasticsearch.bootstrap.ElasticsearchF
wrapper.app.parameter.1=org.elasticsearch.bootstrap.Elasticsearch
wrapper.app.parameter.2=start
# Initial Java Heap Size (in MB)
wrapper.java.initmemory=%ES_HEAP_SIZE% 默认是1024 ,修改:set.default.ES_HEAP_SIZE=1024
wrapper.java.additional.10=-Des.insecure.allow.root=true
vim elasticsearch-2.3.4/config/elasticsearch.yml
network.host: 127.0.0.1
security.manager.enabled: false
启动服务
cd /home/lizejun/Desktop/elk/elasticsearch-2.3.4/bin/service
sudo ./elasticsearch install
./elasticsearch start
./elasticsearch status
Elasticsearch is running: PID:37838, Wrapper:STARTED, Java:STARTED
Unsupported major.minor version 51.0
Version和JDK版本的对应关系:
52.0 -> 8.0
51.0 -> 7.0
50.0 -> 1.6
49.0 -> 1.5
jdk版本比较低
head插件安装和ik分词安装
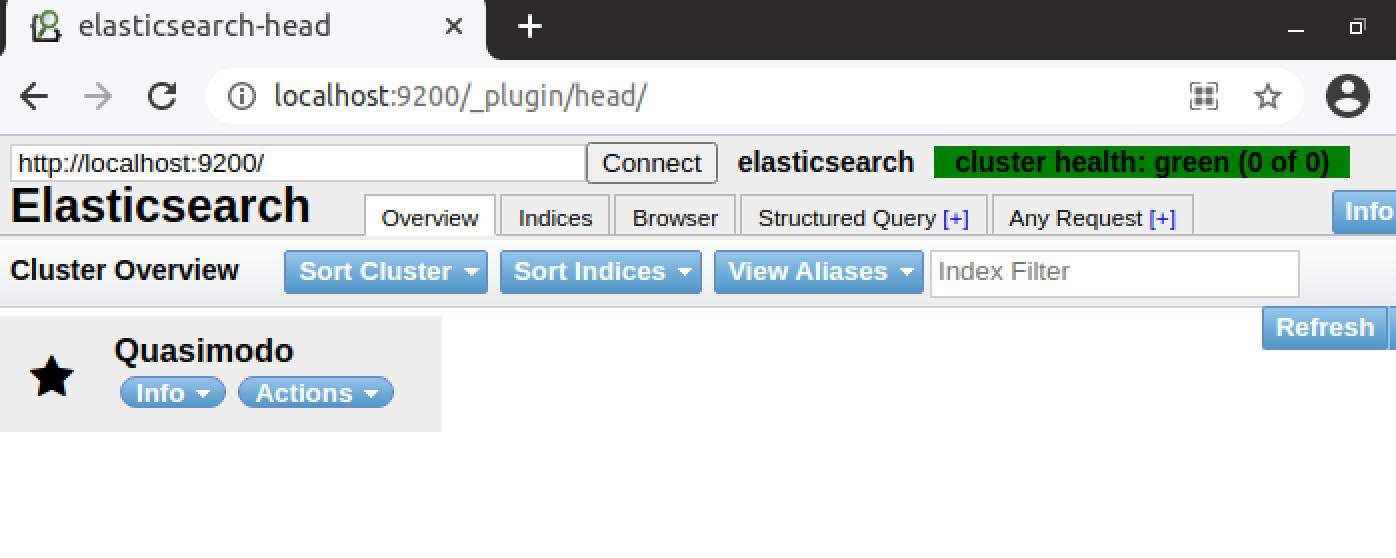
1.elasticsearch-head 是一个界面化的集群操作和管理工具,可以对集群进行傻瓜式操作。
-
显示集群的拓扑,并且能够执行索引和节点级别操作
-
搜索接口能够查询集群中原始 json 或表格格式的检索数据
-
能够快速访问并显示集群的状态
-
有一个输入窗口,允许任意调用 RESTful API
2.Elasticsearch 提供默认提供的分词器 standard (标准分词器)和 chinese (中文分词),会把每个汉字分开,而不是我们想要的根据关键词来分词,比如我们更希望 “中国人”,“中国”,“我”这样的分词,因此需要安装中文分词插件 IK 来实现此功能。elasticsearch-analysis-ik 是一款中文的分词插件,支持自定义词库。
/home/lizejun/Desktop/elk/elasticsearch-2.3.4/
mkdir plugins
sudo wget https://labfile.oss.aliyuncs.com/courses/1014/elasticsearch-head-master.zip
unzip elasticsearch-head-master.zip
mv elasticsearch-head-master head
/home/lizejun/Desktop/elk/elasticsearch-2.3.4/bin/service
./elasticsearch stop
./elasticsearch start
http://localhost:9200/_plugin/head/
ik
cd plugins/
mkdir elasticsearch-analysis-ik-1.8.1
sudo wget https://labfile.oss.aliyuncs.com/courses/1014/elasticsearch-analysis-ik-1.8.1.zip
unzip elasticsearch-analysis-ik-1.8.1.zip -d elasticsearch-analysis-ik-1.8.1
ls elasticsearch-analysis-ik-1.8.1
mv elasticsearch-analysis-ik-1.8.1.zip ~/Desktop/elk/
cd elasticsearch-analysis-ik-1.8.1/
vim plugin-descriptor.properties
cd /home/lizejun/Desktop/elk/elasticsearch-2.3.4/bin/service
./elasticsearch stop
./elasticsearch status
./elasticsearch start
cat ../../logs/elasticsearch.log|grep "ik-analyzer"
izejun@ubuntu:~/Desktop/elk/elasticsearch-2.3.4/bin/service$ cat ../../logs/elasticsearch.log|grep "ik-analyzer"
[2021-02-09 08:57:05,019][INFO ][ik-analyzer ] [Dict Loading] ik/custom/mydict.dic
[2021-02-09 08:57:05,020][INFO ][ik-analyzer ] [Dict Loading] ik/custom/single_word_low_freq.dic
[2021-02-09 08:57:05,022][INFO ][ik-analyzer ] [Dict Loading] ik/custom/ext_stopword.dic
ps -ef|grep elast|grep -v grep |wc -l
elasticsearch 外网访问
修改:elasticsearch.yml文件
添加
network.host: 0.0.0.0
elasticserch索引创建
- 了解 index 的基本概念
- 通过调用 api 的方式 创建 index
- 通过 head 查看创建的索引
- 通过调用 api 的方式删除 index
一个 index 是一个索引的集合,比如淘宝的商品信息和里面资讯信息肯定是两个不同的索引,Index 可以理解为逻辑数据库。
创建maven项目:syl_es 包名:com.syl.es
<mirror>
<id>aliyunmaven</id>
<mirrorOf>*</mirrorOf>
<name>阿里云公共仓库</name>
<url>https://maven.aliyun.com/repository/public</url>
</mirror>
pom依赖
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>2.3.4</version>
</dependency>
创建索引代码
package com.syl.es;
import org.elasticsearch.client.Client;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import java.net.InetAddress;
public class CreateIndex {
public static void main(String[] args) {
// createIndex("user");
for (int i = 0 ; i<10;i++){
createIndex("test"+i);
}
}
private static void createIndex(String indicas) {
String server = "192.168.154.129";
Integer port = 9300;
Client client = null;
try {
// 初始化连接
Settings settings = Settings.builder().build();
client = TransportClient.builder().settings(settings).build().addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName(server),port));
// 创建索引
client.admin().indices().prepareCreate(indicas).execute().actionGet();
// 关闭连接
client.close();
}catch (Exception e ){
e.printStackTrace();
}
}
}

默认5个分片
删除索引
/**
* 删除索引
* @param indices
*/
public static void deleteClusterName(String indices){
String server = "192.168.154.129";
Integer port = 9300;
Client client = null;
try {
// 初始化连接
Settings settings = Settings.settingsBuilder().build();
client = TransportClient.builder().settings(settings).build().addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName(server),port));
// 删除索引
client.admin().indices().prepareDelete(indices).execute().actionGet();
// 关闭连接
client.close();
}catch (Exception e ){
e.printStackTrace();
}
}
elasticsearch 的 mapping
- 了解 mapping 的基本概念
- 理解创建 mapping 的字段几种定义方式
- 通过 java 创建 elasticsearch 的 mapping
Mapping 对应数据库里的表定义,我们都知道数据库表有各种字段每种字段使用场景是不一样,mapping 中字段也类似数据库字段,定义形式不同搜索场景也不同 ,mapping 还有一些其他的含义,mapping 不仅告诉 ES 一个 field 中是什么类型的值,它还告诉 ES 如何索引数据以及数据是否能被搜索到,Mapping 是对于 index 上每种 type 的定义
mapping 字段定义的使用,我们下面针对常用的进行说明
index: "analyzed" //分词,不分词是:not_analyzed ,设置成 no,字段将不会被索引analyzer: "ik" //指定分词器search_analyzer: "ik" //设置搜索时的分词器,默认跟 ananlyzer 是一致的
package com.syl.es;
import org.elasticsearch.action.admin.indices.mapping.put.PutMappingRequest;
import org.elasticsearch.client.Client;
import org.elasticsearch.client.Requests;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.common.xcontent.XContentBuilder;
import org.elasticsearch.common.xcontent.XContentFactory;
import java.net.InetAddress;
public class CreateMapping {
public static void main(String[] args) {
createMapping("user","userinfo");
}
private static void createMapping(String indices, String mappingType) {
String server = "192.168.154.129";
Integer port = 9300;
Client client = null;
try {
// 初始化连接
Settings settings = Settings.settingsBuilder().build();
client = TransportClient.builder().settings(settings).build().addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName(server),port));
new XContentFactory();
XContentBuilder builder = XContentFactory.jsonBuilder()
.startObject()
.startObject(mappingType)
.startObject("properties")
.startObject("name").field("type","string")
.field("index","no").endObject()
//.field("searchAnalyzer","ik").endObject()
.startObject("nickname").field("type","string")
.field("index","not_analyzed").endObject()
.startObject("nativeplace").field("type","string")
.field("index","no").endObject()
.startObject("birthday").field("type","date")
.field("format","yyyy-MM-dd")
.field("index","not_analyzed").endObject()
.endObject()
.endObject()
.endObject();
System.out.println(builder.toString());
PutMappingRequest mapping = Requests.putMappingRequest(indices).type(mappingType).source(builder);
client.admin().indices().putMapping(mapping).actionGet();
client.close();
}catch (Exception e){
e.printStackTrace();
}
}
}
// [user] IndexNotFoundException[no such index]
/**
* 问题分析
* 这是因为Elasticsearch默认安装时禁用了自动创建索引的功能。在action.auto_create_index选项中没有配置test_*样式的索引自动创建条目。
*
* 解决方法
* 关闭已经运行的Elasticsearch;
* 在$ES_HOME\config中打开elasticsearch.xml配置文件
* 在action.auto_create_index选项后增加“,test_”的内容,以匹配索引的自动创建;或者直接将action.auto_create_index的值修改为“”。
* 重新启动elasticsearch。
*
* 如何修改自动创建索引auto_create_index参数?
* 执行以下命令修改。
* PUT /_cluster/settings
* {
* "persistent" : {
* "action": {
* "auto_create_index": "false"
* }
* }
* }
* 注意 auto_create_index参数的默认值为false,表示不允许自动创建索引。一般建议您不要调整该值,会引起索引太多、索引Mapping和Setting不符合预期等问题。
*
*手动修改/etc/elasticsearch/elasticsearch.yml文件
*
* #添加权限(默认为true)
* action.auto_create_index:true
* 或者在kibana中执行命令
*
* PUT _cluster/settings
* {
* "persistent": {
* "action.auto_create_index": "true"
* }
* }
以 Java Application 的方式,运行CreateMapping.java文件 (在运行 CreateMapping.java 之前,需要创建好索引)
*/
{
"state": "open",
"settings": {
"index": {
"creation_date": "1612976023621",
"number_of_shards": "5",
"number_of_replicas": "1",
"uuid": "nqcY1Ir9REidAxdOLt8oXA",
"version": {
"created": "2030499"
}
}
},
"mappings": {
"userinfo": {
"properties": {
"birthday": {
"format": "yyyy-MM-dd",
"type": "date"
},
"name": {
"index": "no",
"type": "string"
},
"nickname": {
"index": "not_analyzed",
"type": "string"
},
"nativeplace": {
"index": "no",
"type": "string"
}
}
}
},
"aliases": [ ]
}
ela添加数据
- 了解创建数据的流程
- 通过 java 创建 elasticsearch 单条数据
- 通过 java 创建 elasticsearch 多条数据
通过调用 Es java api 后与 Es 服务交互,Es 将数据散布到多个物理 Lucene 索引上,这些 Lucene 索引称为分片,es 默认是 5 个分片,如果是集群状态分片将会分配到多个节点上
package com.syl.es;
import java.net.InetAddress;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.elasticsearch.action.bulk.BulkRequestBuilder;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.client.Client;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.common.xcontent.XContentBuilder;
import org.elasticsearch.common.xcontent.XContentFactory;
public class AddData {
/**
* @param args
*/
public static void main(String[] args) {
//调用添加数据方法
add();
}
/**
* 添加索引数据
*/
public static void add(){
//索引服务的地址
String elasticServer= "192.168.154.129";
//索引服务的端口
Integer elasticServerPort = 9300;
Client client=null;
try{
//初始化连接
Settings settings = Settings.settingsBuilder()
.build();
client = TransportClient.builder().settings(settings).build()
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName(elasticServer), elasticServerPort));
BulkRequestBuilder bulkRequest = client.prepareBulk();
//设置字段的值
XContentBuilder docBuilder = XContentFactory.jsonBuilder().startObject();
docBuilder.field("name", "张中国");
docBuilder.field("nickname", "张中");
docBuilder.field("nativeplace", "上海静安寺");
docBuilder.field("address", "上海静安寺1街坊10栋");
docBuilder.field("birthdate", "1980-02-14");
//添加索引数据并且设置id为1
System.out.println(docBuilder.toString());
bulkRequest.add(client.prepareIndex("user", "userInfo", "1")
.setSource(docBuilder));
BulkResponse bulkResponse = bulkRequest.execute().actionGet();
System.out.println(bulkResponse.hasFailures());
//判断添加是否成功
if (bulkResponse.hasFailures()) {
System.out.println("error!!!");
}
//关闭连接
client.close();
}catch (Exception e) {
e.printStackTrace();
}
System.out.println("do end!!");
}
}
{
"_index": "user",
"_type": "userInfo",
"_id": "1",
"_version": 1,
"_score": 1,
"_source": {
"name": "张中国",
"nickname": "张中",
"nativeplace": "上海静安寺",
"address": "上海静安寺1街坊10栋",
"birthdate": "1980-02-14"
}
}
批量添加数据
/**
* 批量添加索引数据
*/
public static void batchAdd (){
//初始化数据
List dataList = new ArrayList();
Map dataMap1=new HashMap();
dataMap1.put("name","张中国1");
dataMap1.put("nickname", "张中1");
dataMap1.put("nativeplace", "上海静安寺1");
dataMap1.put("address", "上海静安寺1街坊10栋1");
dataMap1.put("birthdate", "1980-02-15");
Map dataMap2=new HashMap();
dataMap2.put("name","张中国2");
dataMap2.put("nickname", "张中2");
dataMap2.put("nativeplace", "上海静安寺2");
dataMap2.put("address", "上海静安寺1街坊10栋2");
dataMap2.put("birthdate", "1980-02-16");
dataList.add(dataMap1);
dataList.add(dataMap2);
//索引服务的地址
String elasticServer= "192.168.154.129";
//索引服务的端口
Integer elasticServerPort = 9300;
Client client=null;
try{
//初始化连接
Settings settings = Settings.settingsBuilder().build();
client = TransportClient.builder().settings(settings).build()
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName(elasticServer), elasticServerPort));
BulkRequestBuilder bulkRequest = client.prepareBulk();
int y=dataList.size();
//添加数据
for(int i=0;i<y;i++){
Map<String, Object> m = (Map)dataList.get(i);
bulkRequest.add(client.prepareIndex("user", "userInfo", i+5+"")
.setSource(m));
if (i % 10000 == 0) {
bulkRequest.execute().actionGet();
}
}
bulkRequest.execute().actionGet();
//关闭连接
client.close();
}catch (Exception e) {
e.printStackTrace();
}
System.out.println("do end!!");
}
elasticsearch查询数据
- 了解搜索数据的几种情况
- 通过 java 查询全部数据
- 通过 java 查询部分数据
- 通过调用 api 了解模糊搜索
不了解 elasticsearch 的人都以为 Es 只能进行模糊搜索,其实不仅能进行模糊搜索还能进行全匹配搜索。在集群模式 elasticsearch 的搜索把多个节点的数据汇集到一个节点最终显示给调用端,索引数据必须指定_index(database)及 index 下面的 type(table)。
查询所有
package com.syl.es;
import java.net.InetAddress;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.Client;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.MatchQueryBuilder;
import org.elasticsearch.index.query.MatchQueryBuilder.Operator;
import org.elasticsearch.index.query.QueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHits;
public class QueryData1 {
/**
* @param args
*/
public static void main(String[] args) {
//调用搜索全部数据方法
searchAll();
}
/**
* 搜索全部数据
*/
public static void searchAll(){
//索引服务的地址
String elasticServer= "192.168.154.129";
//索引服务的端口
Integer elasticServerPort = 9300;
Client client=null;
try{
//初始化连接
Settings settings = Settings.settingsBuilder().build();
client = TransportClient.builder().settings(settings).build()
.addTransportAddress(new InetSocketTransportAddress(
InetAddress.getByName(elasticServer), elasticServerPort));
//搜索全部数据
QueryBuilder bqb=QueryBuilders.matchAllQuery();
System.out.println(bqb.toString()+"====================");
SearchResponse response = client.prepareSearch("user").setTypes("userInfo") //set index set type
.setQuery(bqb.toString())
.execute()
.actionGet();
SearchHits hits = response.getHits();
System.out.println(hits.getTotalHits() +" "+ hits.getHits().length);
for (int i = 0; i < hits.getHits().length; i++) {
System.out.println("===searchAll()====="+hits.getAt(i).getId()+"-------"
+ "------"+hits.getAt(i).getSource());
}
//关闭连接
client.close();
}catch (Exception e) {
e.printStackTrace();
}
}
}
查询指定size的数据
/**
* 搜索指定数量数据
*/
public static void searchSize(){
//索引服务的地址
String elasticServer= "192.168.154.129";
//索引服务的端口
Integer elasticServerPort = 9300;
Client client=null;
try{
//初始化连接
Settings settings = Settings.settingsBuilder().build();
client = TransportClient.builder().settings(settings).build()
.addTransportAddress(new InetSocketTransportAddress(
InetAddress.getByName(elasticServer), elasticServerPort));
//搜索数据
QueryBuilder bqb=QueryBuilders.matchAllQuery();
SearchResponse response = client.prepareSearch("user").setTypes("userInfo")
.setQuery(bqb.toString())
.setFrom(0).setSize(2)//设置条数
.execute()
.actionGet();
SearchHits hits = response.getHits();
System.out.println(hits.getTotalHits() +" "+ hits.getHits().length);
//打印搜索结果
for (int i = 0; i < hits.getHits().length; i++) {
System.out.println("====searchSize()==="+hits.getAt(i).getId()+"------"
+ "-------"+hits.getAt(i).getSource());
}
//关闭连接
client.close();
}catch (Exception e) {
e.printStackTrace();
}
}
模糊查询
/**
* 模糊搜索索引数据
*/
public static void searchMatchQuery(){
//索引服务的地址
String elasticServer= "127.0.0.1";
//索引服务的端口
Integer elasticServerPort = 9300;
Client client=null;
try{
//初始化连接
Settings settings = Settings.settingsBuilder().build();
client = TransportClient.builder().settings(settings).build()
.addTransportAddress(new InetSocketTransportAddress(
InetAddress.getByName(elasticServer), elasticServerPort));
//设置查询条件
BoolQueryBuilder bqb=QueryBuilders.boolQuery();
float BOOST = (float) 1.2;
MatchQueryBuilder titleSearchBuilder = QueryBuilders.matchQuery("name", "张中国");
titleSearchBuilder.boost(BOOST);
titleSearchBuilder.operator(Operator.AND);
bqb.must(titleSearchBuilder);
//模糊搜索数据
SearchResponse response = client.prepareSearch("user").setTypes("userInfo")
.setQuery(bqb.toString())
.setFrom(0).setSize(60).setExplain(true) //setExplain 按查询匹配度排序
.execute()
.actionGet();
SearchHits hits = response.getHits();
System.out.println(hits.getTotalHits() +" "+ hits.getHits().length);
//打印搜索结果
for (int i = 0; i < hits.getHits().length; i++) {
System.out.println("===searchMatchQuery()==="+hits.getAt(i).getId()+"--" +
"-----------"+hits.getAt(i).getSource());
}
//关闭连接
client.close();
}catch (Exception e) {
e.printStackTrace();
}
}
修改数据
- 了解 elasticsearch 的修改的底层逻辑
- java 实现 elasticsearch 修改单条数据
- java 实现 elasticsearch 批量修改多条数据
- elasticsearch 修改在内部,修改标记旧文档为删除(增加了一个 version 版本号)并添加了一个完整的新文档。旧版本文档不会立即消失,但你也不能去访问它。
- elasticsearch 会在你继续索引更多数据时清理被删除的文档,或者进行强制清除命令把这种过期的旧数据删除掉。因为这种过期旧数据太多在一定程度上将会影响查询效率。
- 有时候我们修改的内容非常多,达到索引的 80% 上时,会考虑索引重建即 reindex,索引重建有点相当于删除表重新添加数据的感觉。
package com.syl.es;
import java.net.InetAddress;
import java.text.SimpleDateFormat;
import java.util.Date;
import org.elasticsearch.action.update.UpdateResponse;
import org.elasticsearch.client.Client;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.common.xcontent.XContentBuilder;
import org.elasticsearch.common.xcontent.XContentFactory;
public class UpdateData {
/**
* @param args
*/
public static void main(String[] args) {
updateEs();
}
/**
* 更新索引
*/
public static void updateEs(){
//索引服务的地址
String elasticServer= "192.168.154.129";
//索引服务的端口
Integer elasticServerPort = 9300;
Client client=null;
try{
//初始化连接
Settings settings = Settings.settingsBuilder().build();
client = TransportClient.builder().settings(settings).build()
.addTransportAddress(new InetSocketTransportAddress(
InetAddress.getByName(elasticServer), elasticServerPort));
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd");
//设置更新的字段
XContentBuilder jsonBuilder = XContentFactory.jsonBuilder()
.startObject()
.field("name","王美丽")
.field("nickname","美丽")
.field("birthdate",df.format(new Date()))
.endObject();
//更新为1的字段数据
UpdateResponse response=client.prepareUpdate("user","userInfo","1")
.setDoc(jsonBuilder)
.get();
String _index = response.getIndex();
String _type = response.getType();
String _id = response.getId();
long _version = response.getVersion();
boolean created = response.isCreated();
System.out.println(_index+" "+_type+" "+_id+" "+_version+" "+created);
//关闭连接
client.close();
}catch (Exception e) {
e.printStackTrace();
}
}
}

批量更新
/**
* 批量更新索引数据
*/
public static void batchUpdateEs(){
String elasticServer= "192.168.154.129";
Integer elasticServerPort = 9300;
Client client=null;
try{
Settings settings = Settings.settingsBuilder().build();
client = TransportClient.builder().settings(settings).build()
.addTransportAddress(new InetSocketTransportAddress(
InetAddress.getByName(elasticServer), elasticServerPort));
//初始化数据
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd");
List dataList = new ArrayList();
Map dataMap1=new HashMap();
dataMap1.put("name","张中国");
dataMap1.put("nickname", "张中");
dataMap1.put("nativeplace", "上海静安寺");
dataMap1.put("address", "上海静安寺1街坊10栋");
dataMap1.put("birthdate", "1980-02-15");
dataMap1.put("id", "2");
Map dataMap2=new HashMap();
dataMap2.put("name","张三丰");
dataMap2.put("nickname", "张三");
dataMap2.put("nativeplace", "上海静安寺");
dataMap2.put("address", "上海静安寺1街坊10栋");
dataMap2.put("birthdate", "2018-01-23");
dataMap2.put("id", "3");
dataList.add(dataMap1);
dataList.add(dataMap2);
BulkRequestBuilder bulkRequest = client.prepareBulk();
int y=dataList.size();
//执行批量更新
for(int i=0;i<y;i++){
Map<String, Object> m =(Map<String, Object>) dataList.get(i);
XContentBuilder jsonBuilder = XContentFactory.jsonBuilder()
.startObject()
.field("name",m.get("name").toString())
.field("nickname",m.get("nickname").toString())
.field("nativeplace",m.get("nativeplace").toString())
.field("address",m.get("address").toString())
.field("birthdate",m.get("birthdate").toString())
.endObject();
bulkRequest.add(client.prepareUpdate("user", "userInfo",m.get("id").toString())
.setDoc(jsonBuilder));
if (i % 10000 == 0) {
bulkRequest.execute().actionGet();
}
}
bulkRequest.execute().actionGet();
//关闭连接
client.close();
}catch (Exception e) {
e.printStackTrace();
}
}
elasticsearch 删除数据
- 了解 elasticsearch 的删除的底层逻辑
- java 实现 elasticsearch 删除单条数据
- java 实现 elasticsearch 删除多条数据
- elasticsearch 删除在内部,删除文档的语法模式与之前基本一致,只不过要使用 DELETE 方法:DELETE /user/info/1 如果文档被找到,Elasticsearch 将返回 200 OK 状态码和以下响应体。注意_version 数字已经增加了。删除一个文档也不会立即从磁盘上移除,它只是被标记成已删除。Elasticsearch 将会在你之后添加更多索引的时候才会在后台进行删除内容的清理。
- 有时候我们删除的内容非常多,达到索引的 80% 上时,会考虑索引重建即 reindex,这时直接删除 index 是非常快的,类似于删除表的操作。
package com.syl.es;
import java.net.InetAddress;
import java.util.ArrayList;
import java.util.List;
import org.elasticsearch.action.bulk.BulkRequestBuilder;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.client.Client;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
public class DeleteData {
public static void main(String args[]){
deleteEs();
}
/**
* 删除索引数据
*/
public static void deleteEs(){
//索引服务的地址
String elasticServer= "192.168.154.129";
//索引服务的端口
Integer elasticServerPort = 9300;
Client client=null;
try{
//初始化连接
Settings settings = Settings.settingsBuilder().build();
client = TransportClient.builder().settings(settings).build()
.addTransportAddress(new InetSocketTransportAddress(
InetAddress.getByName(elasticServer), elasticServerPort));
//删除为1的索引数据
client.prepareDelete("user","userInfo","1").execute().actionGet();
//关闭连接
client.close();
}catch (Exception e) {
e.printStackTrace();
}
}
}
