今日内容概要
- 模板层之标签
- 自定义过滤器、标签及inclusion_tag(了解)
- 模板层的继承与导入
- 模型层之前期准备
- 模型层之ORM常见关键字
今日内容详细
1.if判断
{% if 条件1(可以自己写也可以是传递过来的数据) %}
条件1成立执行的操作
{% elif 条件2(可以自己写也可以是传递过来的数据) %}
条件2成立执行的操作
{% else %}
条件1条件2都不成立执行的操作
{% endif %}
2.for循环
{% for 变量名 in 数据 %}
要执行的操作
{% endfor %}
for循环中还有一些方法 可以结合if判断使用
{% for 变量名 in 数据 %}
{% if forloop.first %}
如果是第一次循环执行的操作
{% elif forloop.last %}
如果是最后一次循环执行的操作
{% else %}
中间循环执行的操作
{% endif %}
{% empty %}
如果数据无法被循环取值执行的操作(如空列表 空字符串 空字典等)
{% endfor %}
在django模板语法中取值的操作>>>:只支持句点符
句点符既可以点索引也可以点键
如传过来的d1是
{'name':'jason','hobby':[{'a1':'read'},{'a2':'play'}]}
{{ d1.hobby.1.a2 }} 取到的就是play
对于复杂数据获取之后需要反复使用的可以起别名 方便后续使用
{% with d1.hobby.1.a2 as h %}
<p>{{ h }}</p>
{% endwith %}
自定义过滤器、标签及inclusion_tag(了解)
'''
如果想要自定义一些模板语法 需要先完成下列步骤
1.在应用下创建一个名字必须叫templatetags的目录 其他名字不行
2.在上述目录中关键一个任意名称的py文件
3.在新建的py文件中先编写两行固定的代码
from django import template
register = template.Library()
'''
1.自定义过滤器(最大只能接受两个参数)
@register.filter(name='myadd') # name参数填写的就是自定义过滤器的名字
def func(a, b): # 函数的名字可以随便起
return a + b
html页面中的用法
{% load mydemo %} # 需要先加载自己创建的py文件名
<p>{{ 10|myadd:10 }}</p> # 20
2.自定义标签(参数没有限制)
@register.simple_tag(name='mytag')
def func2(a, b, c, d, e): # 函数名同样可以任意起
return f'{a}-{b}-{c}-{d}-{e}'
{% load mydemo %}
<p>{% mytag 'jason' 'kevin' 'oscar' 'tony' 'ben' %}</p>
# 自定义标签需要使用{%%}语法 不同于自定义过滤器
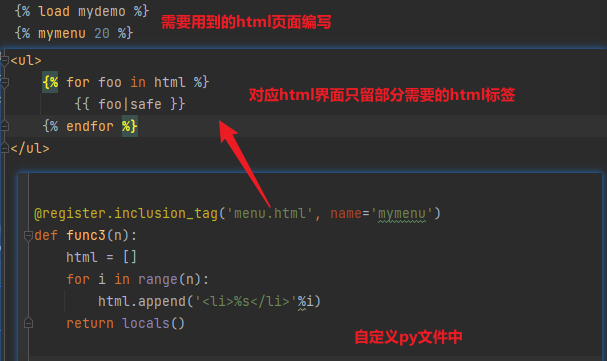
3.自定义inclusion_tag(局部的html代码)
@register.inclusion_tag('menu.html', name='mymenu')
def func3(n):
html = []
for i in range(n):
html.append('<li>第%s</li>' %i)
return locals()
{% load mydemo %}
{% mymenu 20 %}
具体流程看下图
![]()
模板的继承与导入
1.模板的继承
多个页面有很多相似的地方 有两种方式可以采用
方式1:传统的复制粘贴 将相似的html标签复制到不同的文件中
方式2:模板的继承
1.在母板中使用block划定子板以后可以修改的区域
语法格式
{% block 区域名称 %}
供后续页面可以修改的标签
{% endblock %}
2.子板继承母板
语法格式
{% extends 'home.html' %}
{% block 区域名称 %}
子板自己的内容 母板中的内容不再使用
{% endblock %}
ps:母版中至少应该有三个区域
页面内容区 css样式区 js代码区
补充:子板中也可以继续使用母板中的内容
{{ block.super }}
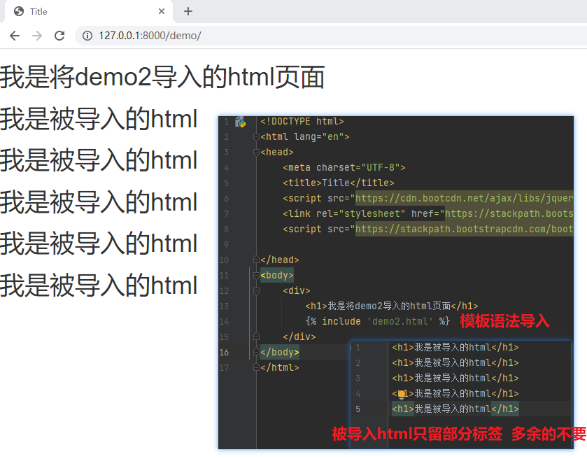
2.模板的导入(了解)
将某个html页面的部分提前写好 之后很多html页面都想使用就可以导入
在导入的html页面写上模板语法
{% include 'demo2.html' %}
![]()
模型层之前期准备
1.自带的sqlite3数据库对时间字段不敏感 有时候会显示错乱 所以我们得习惯切换成其他常见的数据库 比如MySQL 执行orm时并不会自动帮你创建库 所以需要自己先提前创建好
2.单独测试django某个功能层
默认不允许单独测试某个py文件 如果想要测试某个py文件(主要就是models.py)
两种方式:
方式1:pycharm提供的python console
方式2:自己搭建(自带的test或者自己创建的py文件)
拷贝manage.py中的前四行代码
自己再加两行
import django
django.setup()
3.django中orm底层还是SQL语句 我们其实是可以查看的
如果我们手上的是一个QuerySet对象 那么我们可以直接点query查看SQL语句
如果想查看所有orm底层的SQL语句也可以在配置文件中添加日志记录
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
ORM常用关键字
1.create() 创建数据并直接获取当前创建的数据对象
res = models.User.objects.create(name='jason', age=18)
res = models.User.objects.create(name='kevin', age=28)
print(res) # 返回创建成功对象的本身
2.filter() 根据条件筛选数据 结果是QuerySet [数据对象1, 数据对象2...]
# 不写参数查全部
res = models.User.objects.filter()
res = models.User.objects.filter(name='jason')
# 括号内支持多个条件但是默认是and关系 找不到返回空QuerySet []
res = models.User.objects.filter(name='jason', age=28)
3.first() last() QuerySet支持索引取值但是只支持正数 并且orm不建议使用索引
res = models.User.objects.filter()[1]
res = models.User.objects.filter(pk=100)[0] # 当数据不存在时索引取会报错
res = models.User.objects.filter(pk=100).first() # 当数据不存时不会报错 而是返回一个None
res = models.User.objects.filter().last() # 取最后一个 first取第一个
4.update() 更新数据(批量更新)
models.User.objects.filter().update(age=18) # 不做筛选就是批量更新
models.User.objects.filter(pk=1).update(age=18) # 单个更新
5.delete() 删除数据(批量删除)
models.User.objects.filter().delete() # 不做筛选就是批量删除
models.User.objects.filter(pk=1).delete() # 单个删除
6.all() 查所有数据 结果是QuerySet [数据对象1, 数据对象2...]
res = models.User.objects.all()
7.values() 根据指定字段获取数据 结果是QuerySet[{},{}...]
res = models.User.objects.all().values() # 不写参数获取所有字段数据
res = models.User.objects.filter().values('name')
res = models.User.objects.filter().values('name','age')# 也可以多个
res = models.User.objects.values()
8.values_list() 根据指定字段获取数据 结果是QuerySet [(),()...]
res = models.User.objects.all().values_list('name','age')
9.distinct() 去重 数据一定要一模一样才可以 如果有主键肯定不行
res = models.User.objects.values('name', 'age').distinct()
10.order_by 根据指定条件排序 默认是升序 字段前面加符号就是降序
res = models.User.objects.all().order_by('age')
res = models.User.objects.all().order_by('-age') # 降序
11.get() 根据条件筛选数据并直接获取到数据对象 一旦条件不存在会直接报错 不建议使用
res = models.User.objects.get(pk=1)
res = models.User.objects.get(pk=100, name='jason') # 会直接报错
12.exclude() 取反操作
res = models.User.objects.exclude(pk=1) # 取除了pk=1的数据
13.reverse() 颠倒顺序(被操作的对象必须是已经排序过的才可以)
res = models.User.objects.all().order_by('age').reverse()
14.count() 统计结果集中数据的个数
res = models.User.objects.all().count()
15.exists() 判断结果集中是否含有数据 如果有则返回True 没有则返回False
res = models.User.objects.filter(pk=100).exists()



 浙公网安备 33010602011771号
浙公网安备 33010602011771号