

05 HDFS Java API应用实例
一、在Ubuntu系统中安装和配置idea
去官网地址下载 https://www.jetbrains.com/idea/download/#section=linux
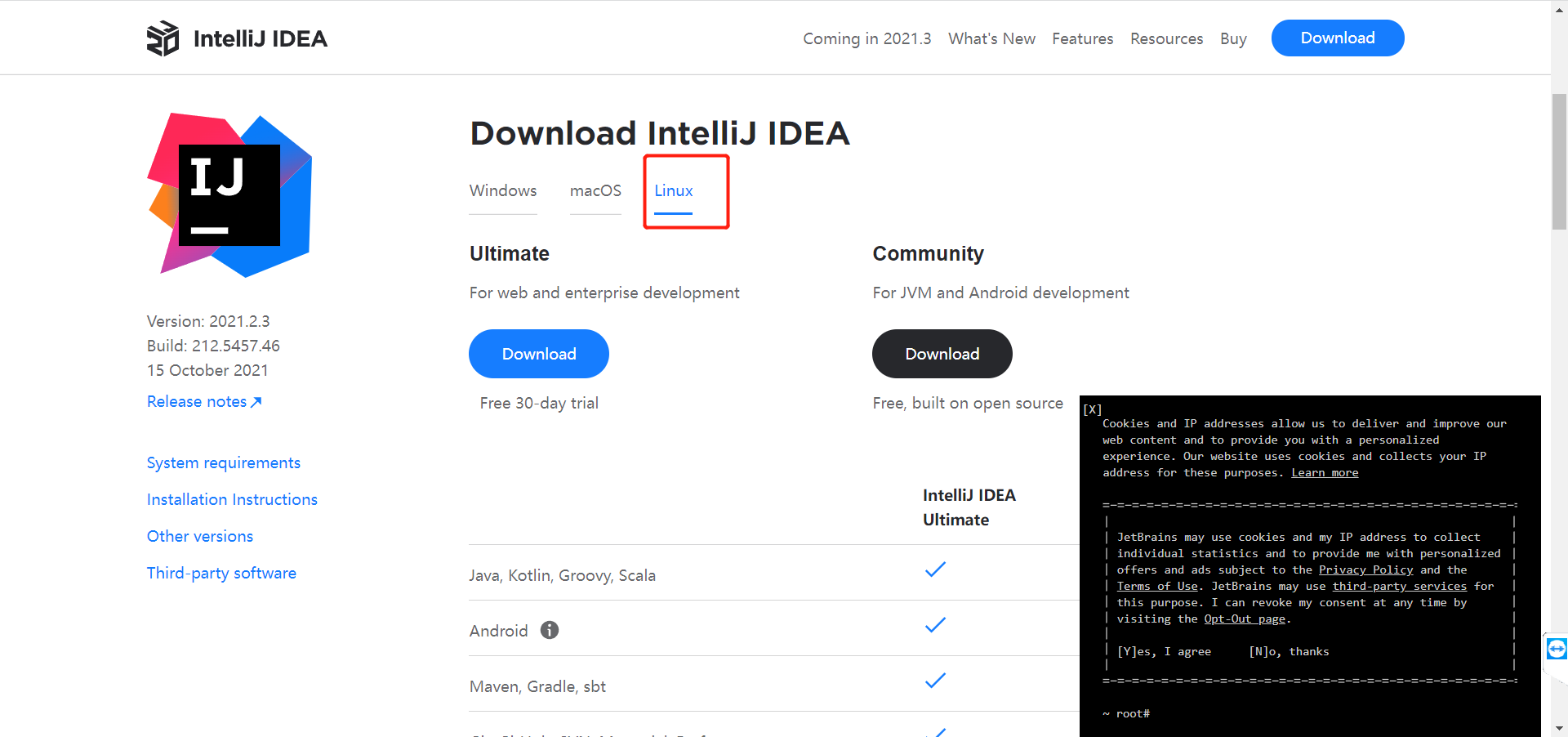
选择这个版本下载
把Idea放到你想要放的位置,如:
sudo cp ideaIU-2021.2.3.tar.gz /usr/local/
解压(注意: 不同版本下载下来的压缩包名字是不一样的, 即ideaIU-2021.2.3.tar.gz不一定都一样)
sudo tar -zxvf ideaIU-2021.2.3.tar.gz
给解压下来的新文件夹改名字(注意,你解压出来的文件夹的名字不一定是idea2021.2.3)
mv idea-2021.2.3 idea2021
移动文件夹, 这里我移动到了我的桌面
mv idea2021 /home/hadoop/桌面
赋权限
sudo chmod 777 idea2021 -R
去到自己的idea安装目录下面启动idea
注意: idea是一门付费软件,笔者不方便提供永久使用的方法,大家可以自己去找激活码来使用 (有付费能力的当我没说哈)
./idea2021/bin/idea.sh
二、利用hadoop 的java api,向HDFS写一个文件。
像创建一个文件夹用于存放idea创建的项目,这是个人习惯,也可以不创建
sudo mkdir /usr/local/workspace
修改权限
sudo chmod 777 /usr/local/workspace -R
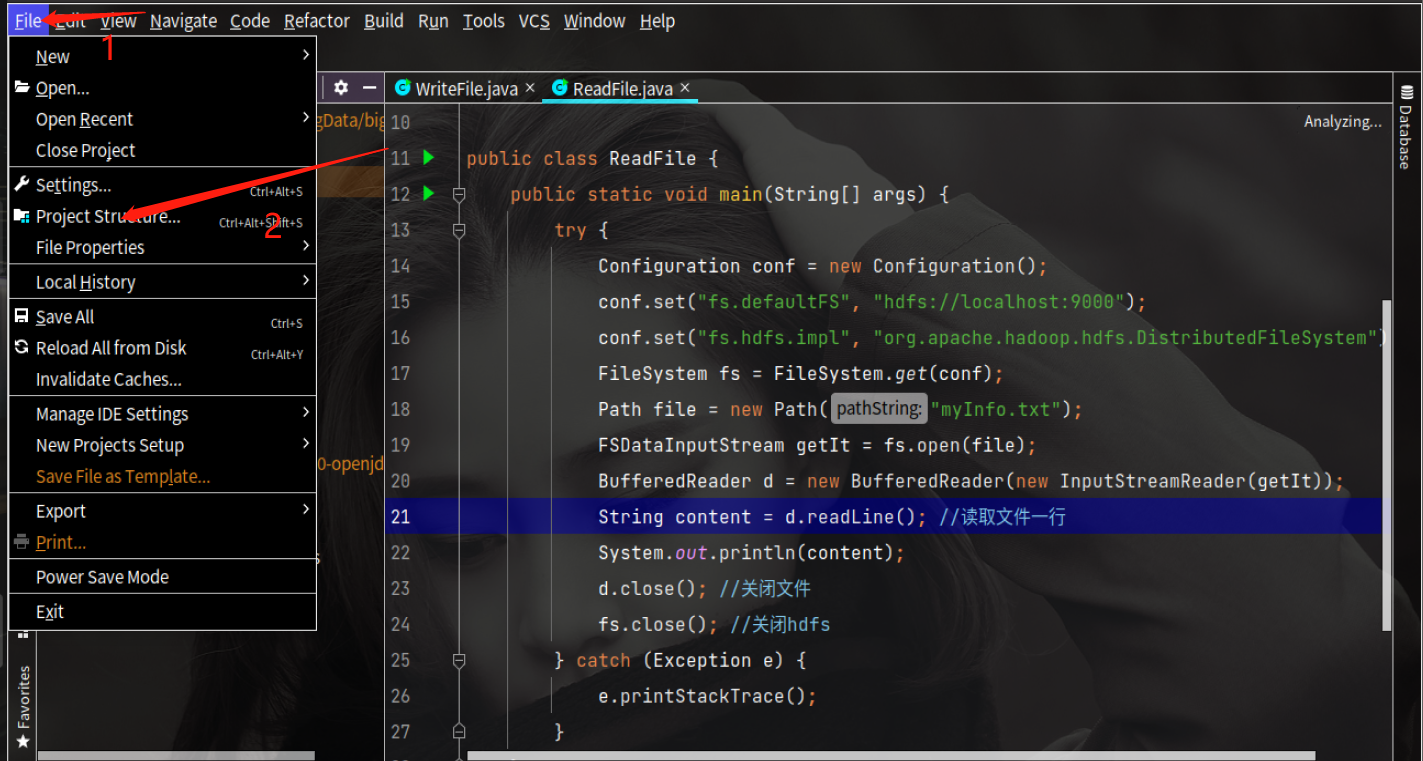
创建项目




创建项目成功后,需要添加依赖
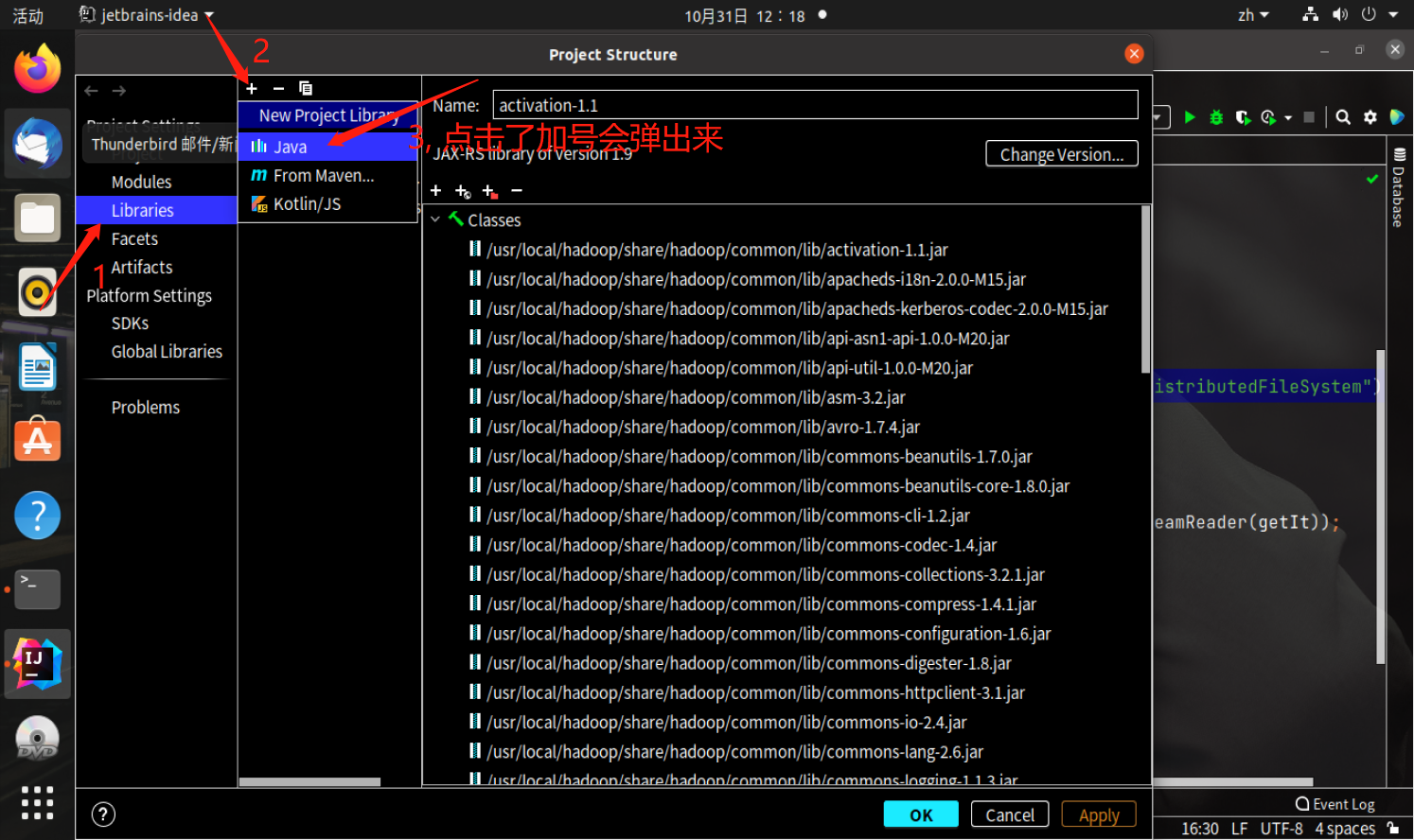
我已经添加过了的,所以有很多jar包, hdfs下的java api jar包都在这四个地方
(1)“/usr/local/hadoop/share/hadoop/common”目录下的所有JAR包,注意不包括目录
(2)“/usr/local/hadoop/share/hadoop/common/lib”目录下的所有JAR包;
(3)“/usr/local/hadoop/share/hadoop/hdfs”目录下的所有JAR包,注意不包括目录;
(4)“/usr/local/hadoop/share/hadoop/hdfs/lib”目录下的所有JAR包。
自己手动添加就行了,如下

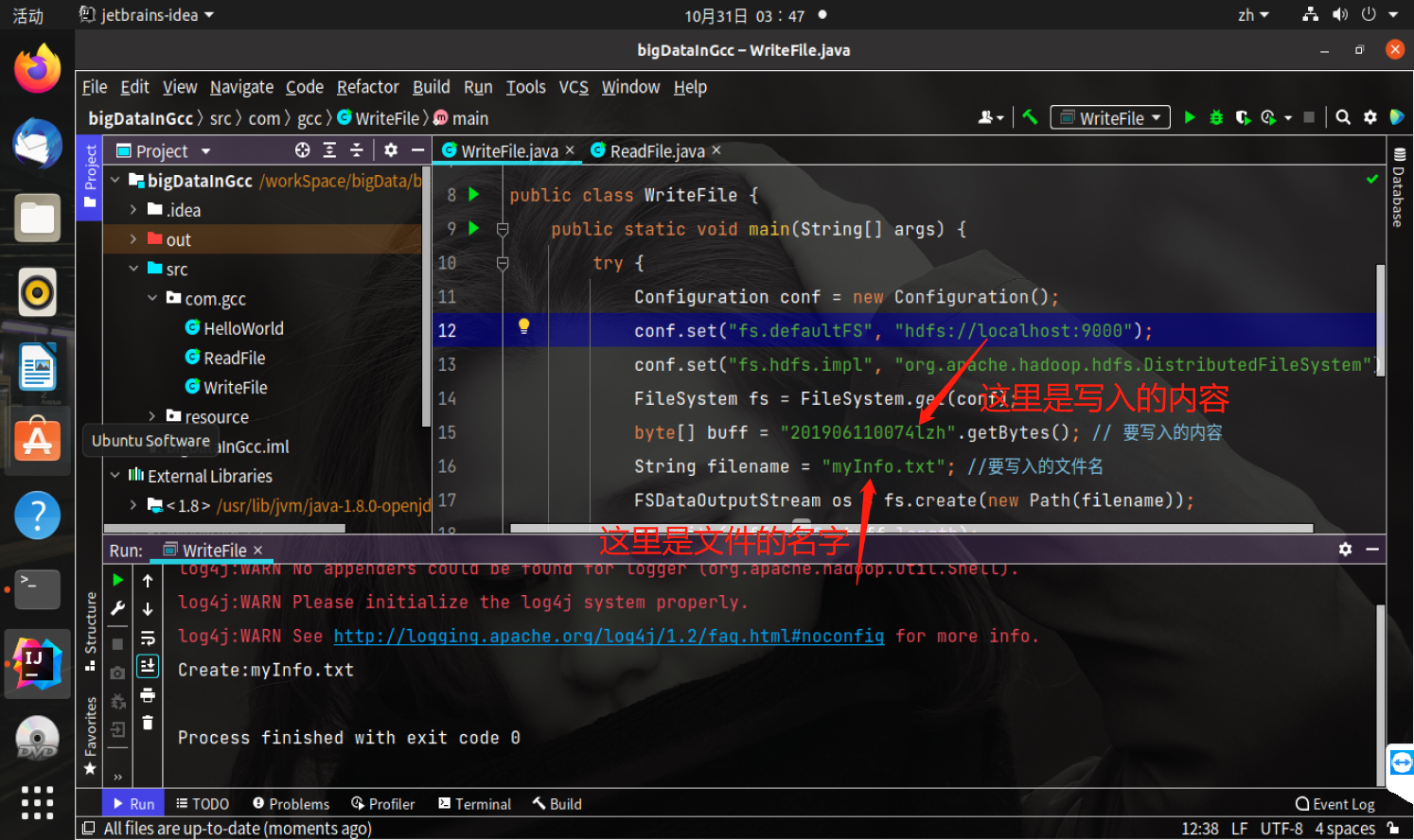
接下来在项目里面创建一个类WriteFile,代码如下
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.Path; public class WriteFile { public static void main(String[] args) { try { Configuration conf = new Configuration(); conf.set("fs.defaultFS","hdfs://localhost:9000"); conf.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem"); FileSystem fs = FileSystem.get(conf); byte[] buff = "201906110074lzh".getBytes(); // 要写入的内容 String filename = "file1.txt"; //要写入的文件名 FSDataOutputStream os = fs.create(new Path(filename)); os.write(buff,0,buff.length); System.out.println("Create:"+ filename); os.close(); fs.close(); } catch (Exception e) { e.printStackTrace(); } } }
启动hdfs
start-dfs.sh
查看当前hdfs中写入的文件
hdfs dfs -ls

启动完hdfs之后回到idea运行ReadFile这个类
再次查看
hdfs dfs -ls

可以看到多了一个叫myInfo.txt的文件,代表WriteFile这个Java类写入成功
三、从HDFS读取一个文件的内容。
同样在idea创建一个类ReadFile,代码如下(注意代码中的文件路径需要和你WriteFile里面定义的文件路径一样):
import java.io.BufferedReader; import java.io.InputStreamReader; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.fs.FSDataInputStream; public class ReadFile { public static void main(String[] args) { try { Configuration conf = new Configuration(); conf.set("fs.defaultFS","hdfs://localhost:9000"); conf.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem"); FileSystem fs = FileSystem.get(conf); Path file = new Path("file1.txt"); FSDataInputStream getIt = fs.open(file); BufferedReader d = new BufferedReader(new InputStreamReader(getIt)); String content = d.readLine(); //读取文件一行 System.out.println(content); d.close(); //关闭文件 fs.close(); //关闭hdfs } catch (Exception e) { e.printStackTrace(); } } }
运行这个类, 结果如下

可以看到输出内容为WriteFile中写入的内容
最后停止hdfs
stop-dfs.sh
到此,本次实验结束

 浙公网安备 33010602011771号
浙公网安备 33010602011771号