机器学习模型评估指标
1. 分类模型
对于二分类模型,主要评估指标有 AUC、Precision、Recall、F-measure、Accuracy。下面对每个指标进行详细的解释
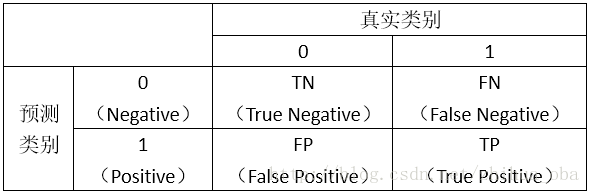
TP: 预测为正类,实际为正类
FP:预测为正类,实际为负类
TN:预测为负类,实际为负类
FN:预测为负类,实际为正类
对应的
TPR = TP/(TP+FN) 真是正样本中预测为正样本的比例
FPR = FP / (FP+TN) 真是负样本中预测为正样本的比例
FNR = FN /(TP+FN)
TNR = TN/(TN+FP)
准确率 Accuracy
准确率就是预测正确的正负样本占总样本的数量
Accuracy = (TP + TN) /(TP + FP + TN + FN)
精确率(Precision)
precision 预测为正的正样本中占所以预测为正的比例
Precision = TP /(TP + FP)
召回率(recall)
所以的正样本中,能够预测为正本的比例
recall = TP/(TP + FN)
F-measure
F值是精确率和召回率的调和值,多数推荐系统使用F 值昨为评估指标
F-measure = 2 * (precision * recall) /(precision + recall)
ROC 曲线
ROC 曲线的横纵坐标分别为FPR,TPR
ROC 曲线的画法
假设已经得出一系列样本被划分为正类的概率,然后按照大小排序,假设“Score”表示每个测试样本属于正样本的概率。从高到低,依次将“Score”值作为阈值threshold,当测试样本属于正样本的概率大于或等于这个threshold时,我们认为它为正样本,否则为负样本。
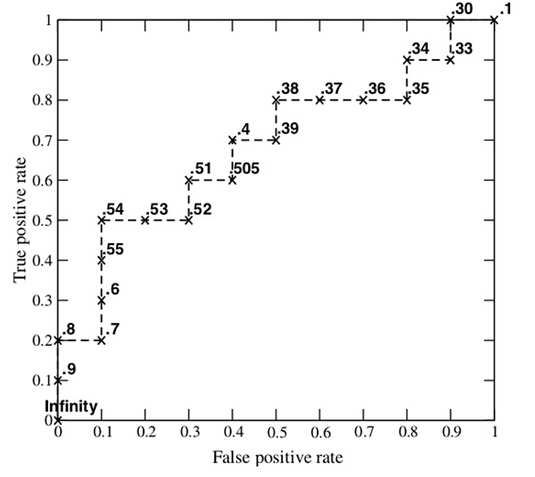
AUC(Area under Curve):Roc曲线下的面积,介于0.1和1之间。Auc作为数值可以直观的评价分类器的好坏,值越大越好。
AUC值是一个概率值,当你随机挑选一个正样本以及负样本,当前的分类算法根据计算得到的Score值将这个正样本排在负样本前面的概率就是AUC值,AUC值越大,当前分类算法越有可能将正样本排在负样本前面,从而能够更好地分类。
ROC ,AUC 的优点
为什么还要使用ROC和AUC呢?因为ROC曲线有个很好的特性:当测试集中的正负样本的分布变换的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现样本类不平衡,即正负样本比例差距较大,而且测试数据中的正负样本也可能随着时间变化。
2. 回归模型
回归模型的指标主要有MSE RMSE

 浙公网安备 33010602011771号
浙公网安备 33010602011771号