
Python总结
一、并发编程总结点:
1. GIL锁及互斥锁
锁:目的都是用于保护数据,只是保护数据不同则加不同的锁。
GIL:全局解释权锁 只有在Cpython解释器中才会存在。在任意时刻只有一个线程在解释器中运行-- 解释器层面。
互斥锁:互相排斥,将某个程序并行变为串行,保证了某个数据安全不错乱--自己开发程序中数据。
当程序拿到GIL锁之后才会执行程序,如果某个程序有互斥锁,则判断当前线程是否有此锁权限,如果有则执行程序,否则会放出权限或等待
GIL 与Lock是两把锁,保护的数据不一样,前者是解释器级别的(当然保护的就是解释器级别的数据,比如垃圾回收的数据),后者是保护用户自己开发的应用程序的数据,很明显GIL不负责这件事,只能用户自定义加锁处理,即Lock,如下图
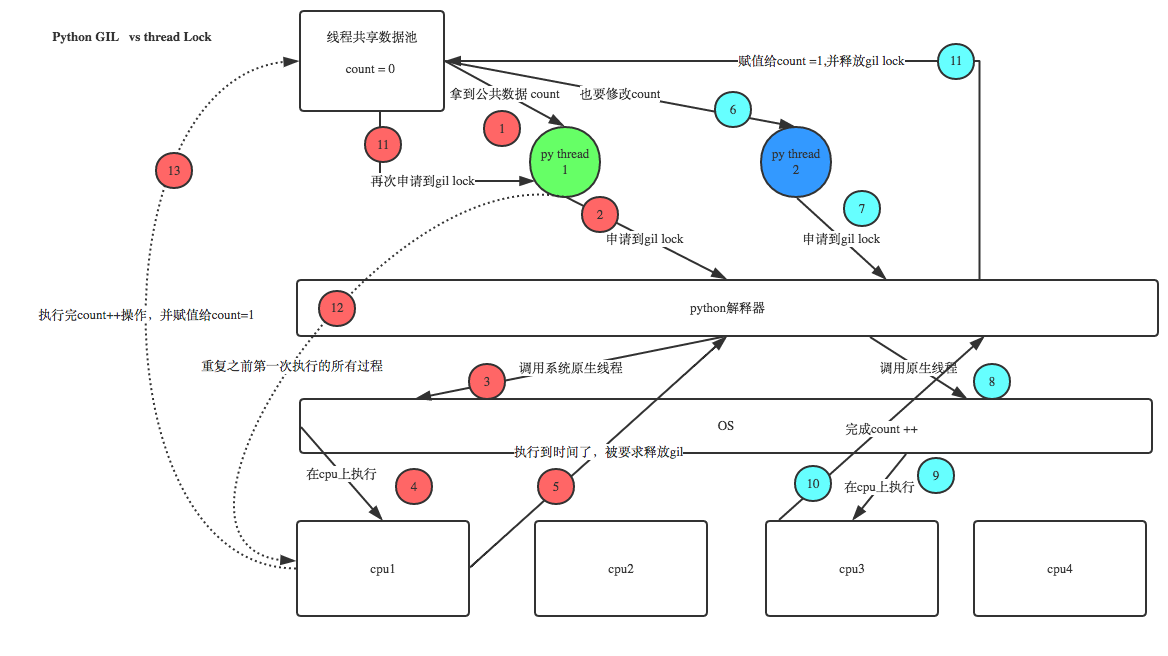
互斥锁示例:
import threading R=threading.Lock() R.acquire() # #R.acquire()如果这里还有一个acquire,你会发现,程序就阻塞在这里了,因为上面的锁已经被拿到了并且还没有释放的情况下,再去拿就阻塞住了 ''' 对公共数据的操作 ''' R.release()
2. 死锁与递归锁
死锁: 是指两个或两个以上的进程或线程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力 作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程
1 # ------死锁 ------- 2 from threading import Thread, Lock, RLock 3 import time 4 5 mutexA = Lock() 6 mutexB = Lock() 7 8 9 # mutexA = mutexB = RLock() 10 class MyThread(Thread): 11 12 def run(self): 13 self.func1() 14 self.func2() 15 16 def func1(self): 17 mutexA.acquire() 18 19 print('%s 拿到A锁>>>' % self.name) 20 mutexB.acquire() 21 print('%s 拿到B锁>>>' % self.name) 22 mutexB.release() 23 mutexA.release() 24 25 def func2(self): 26 mutexB.acquire() 27 28 print('%s 拿到B锁???' % self.name) 29 time.sleep(0.5) 30 mutexA.acquire() 31 print('%s 拿到A锁???' % self.name) 32 mutexA.release() 33 mutexB.release() 34 35 36 if __name__ == '__main__': 37 for i in range(10): 38 t = MyThread() 39 t.start() 40 # 上述程序形成死锁现象:数据分析,数据库出现比较多,双方拿着对方想要抢的锁 41 # 解决方法,递归锁,在Python中为了支持在同一线程中多次请求同一资源,python提供了可重入锁RLock。 42 # 这个RLock内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,从而使得资源可以被多次require。直到一个线程所有的acquire都被release,其他的线程才能获得资源。上面的例子如果使用RLock代替Lock,则不会发生死锁:
递归锁:在Python中为了支持在同一线程中多次请求同一资源,python提供了可重入锁RLock。
1 from threading import Thread,RLock 2 import time 3 4 mutexA=mutexB=RLock() #一个线程拿到锁,counter加1,该线程内又碰到加锁的情况,则counter继续加1,这期间所有其他线程都只能等待,等待该线程释放所有锁,即counter递减到0为止 5 6 class MyThread(Thread): 7 def run(self): 8 self.func1() 9 self.func2() 10 def func1(self): 11 mutexA.acquire() 12 print('\033[41m%s 拿到A锁\033[0m' %self.name) 13 14 mutexB.acquire() 15 print('\033[42m%s 拿到B锁\033[0m' %self.name) 16 mutexB.release() 17 18 mutexA.release() 19 20 def func2(self): 21 mutexB.acquire() 22 print('\033[43m%s 拿到B锁\033[0m' %self.name) 23 time.sleep(2) 24 25 mutexA.acquire() 26 print('\033[44m%s 拿到A锁\033[0m' %self.name) 27 mutexA.release() 28 29 mutexB.release() 30 31 if __name__ == '__main__': 32 for i in range(10): 33 t=MyThread() 34 t.start()
3. 协程
协程:本质上就是一个线程,以前线程任务的切换是由操作系统控制的,遇到I/O自动切换,现在我们用协程的目的就 是较少操作系统切换的开销(开关线程,创建寄存器、堆栈等,在他们之间进行切换等),在我们自己的程序里面来 控制任务的切换。
协程是一种用户态的轻量级线程,即线程是由用户程序自己控制调度的
4. IO模型
1.阻塞IO
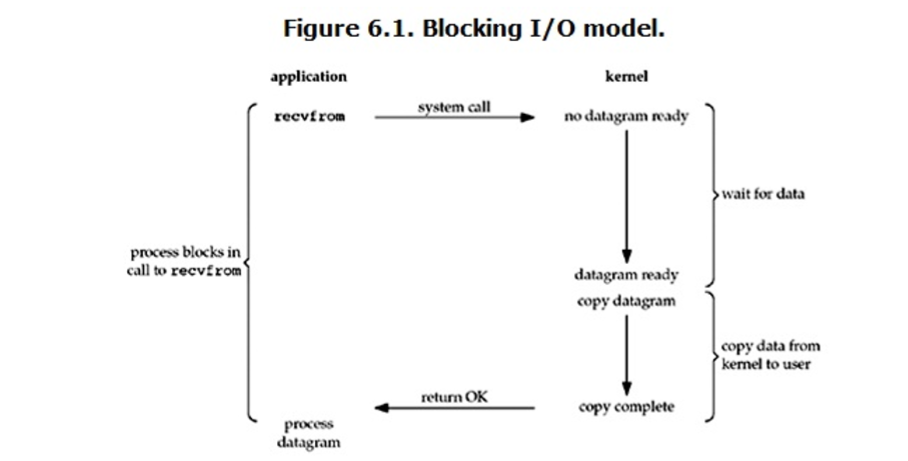
blocking IO的特点就是在IO执行的两个阶段(等待数据和拷贝数据两个阶段)都被block了
2.非阻塞IO模型
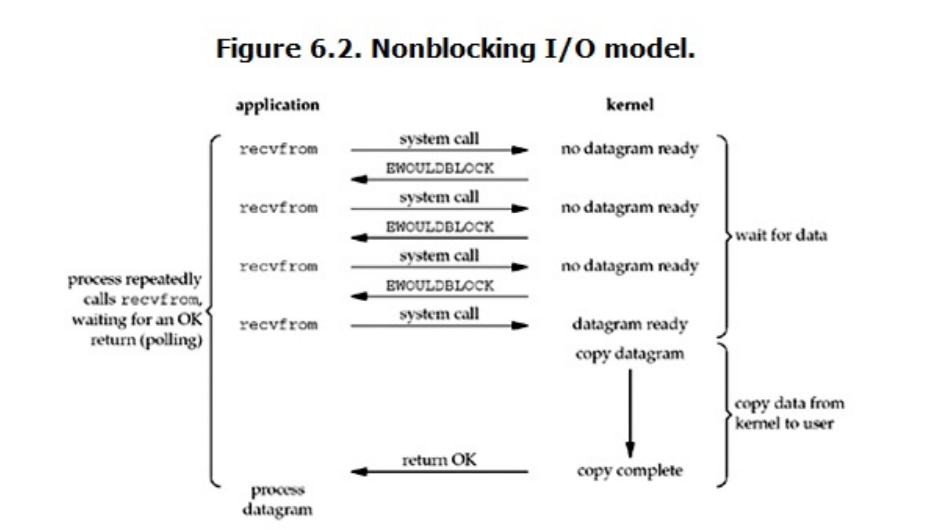
nonblocking IO的特点是用户进程需要不断的主动询问kernel数据好了没有。
3. IO多路复用
IO multiplexing就是我们说的select,poll,epoll,有些地方也称这种IO方式为event driven IO
select/epoll的好处就在于单个process就可以同时处理多个网络连接的IO。
它的基本原理就是select,poll,epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到 达了,就通知用户进程。
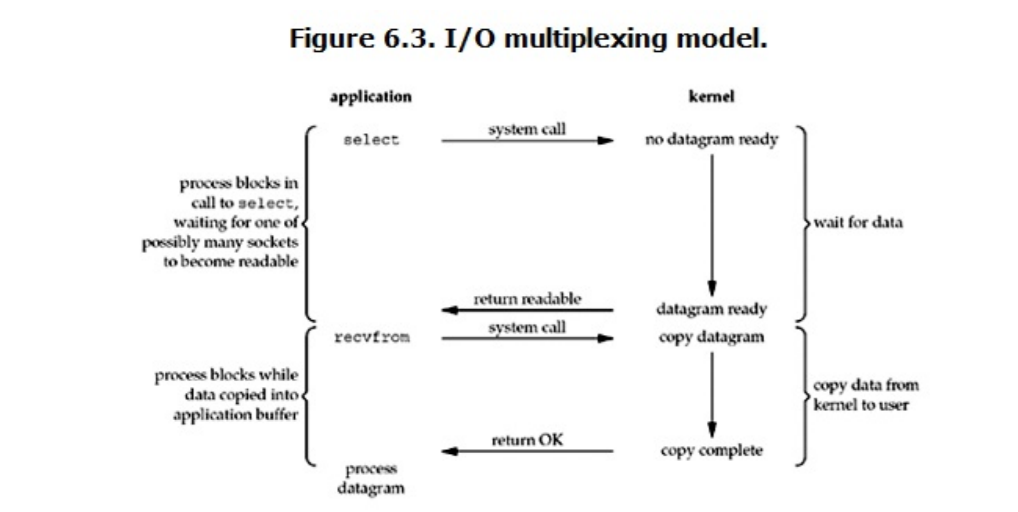
3.1.多路分离函数select
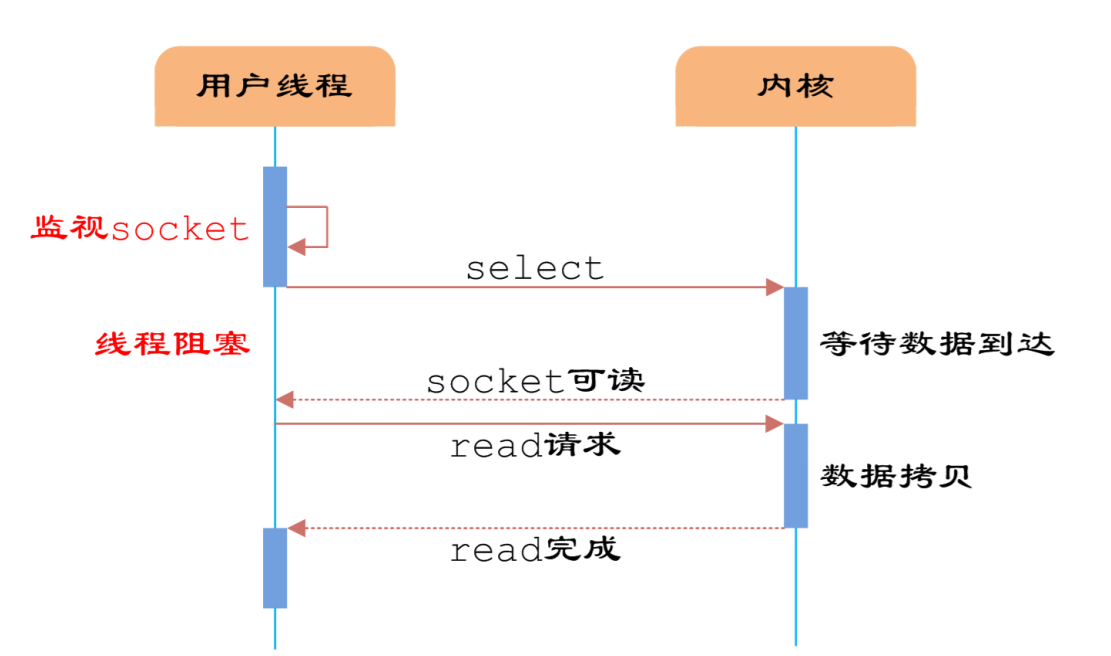
用户首先将需要进行IO操作的socket添加到select中,然后阻塞等待select系统调用返回。当数据到达时, socket被激活,select函数返回。用户线程正式发起read请求,读取数据并继续执行。
从流程上来看,使用select函数进行IO请求和同步阻塞模型没有太大的区别,甚至还多了添加监视socket,以及 调用select函数的额外操作,效率更差。 但是,使用select以后最大的优势是用户可以在一个线程内同时处理多个socket的IO请求。用户可以注册多个 socket,然后不断地调用select读取被激活的socket,即可达到在同一个线程内同时处理多个IO请求的目的。
而 在同步阻塞模型中,必须通过多线程的方式才能达到这个目的。 然而,使用select函数的优点并不仅限于此。虽然上述方式允许单线程内处理多个IO请求,但是每个IO请求的过 程还是阻塞的(在select函数上阻塞),平均时间甚至比同步阻塞IO模型还要长。如果用户线程只注册自己感兴趣的socket或者IO请求,然后去做自己的事情,等到数据到来时再进行处理,则可以提高CPU的利用率。
3.2 poll==>时间复杂度O(n)
poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态, 但是它没有 最大连接数的限制,原因是它是基于链表来存储的.
3.3 epoll==>时间复杂度O(1)
设想一下如下场景:有100万个客户端同时与一个服务器进程保持着TCP连接。而每一时刻,通常只有几百上千个 TCP连接是活跃的(事实上大部分场景都是这种情况)。如何实现这样的高并发? 在select/poll时代,服务器进程每次都把这100万个连接告诉操作系统(从用户态复制句柄数据结构到内核态),让操作 系统内核去查询这些套接字上是否有事件发生,轮询完后,再将句柄数据复制到用户态,让服务器应用程序轮询处理 已发生的网络事件,这一过程资源消耗较大,因此,select/poll一般只能处理几千的并发连接。 epoll的设计和实现与select完全不同。epoll通过在Linux内核中申请一个简易的文件系统(文件系统一般用什么数据 结构实现?B+树)。
把原先的select/poll调用分成了3个部分:
调用epoll_create()建立一个epoll对象(在epoll文件系统中为这个句柄对象分配资源) 调用
epoll_ctl向epoll对象中添加这100万个连接的套接字 调用
epoll_wait收集发生的事件的连接
4.异步IO
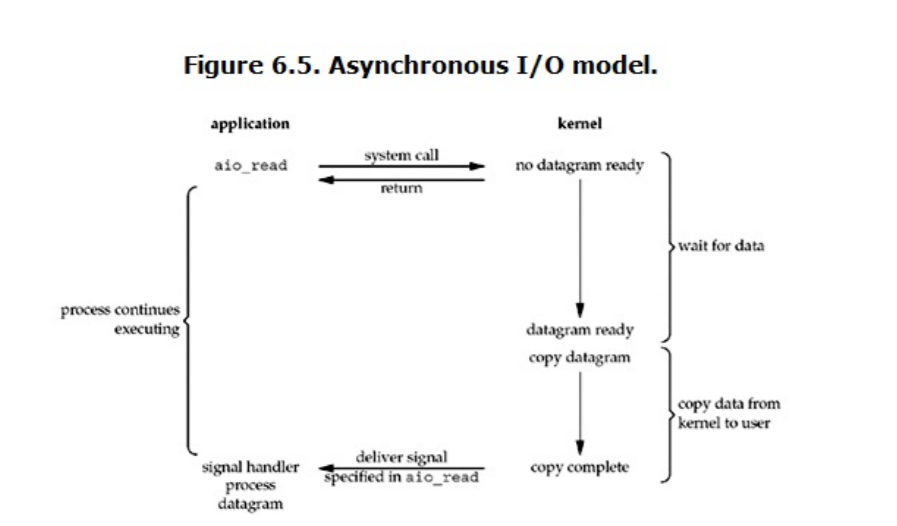
用户进程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从kernel的角度,当它受到一个 asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。然后,kernel操作系统会等待 数据(阻塞)准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal, 告诉它read操作完成了


 浙公网安备 33010602011771号
浙公网安备 33010602011771号