Kafka从入门到放弃(三)—— 详说消费者
之前介绍了Kafka以及生产者,包括它的一些特性和参数,这回写一下消费者。
之前没看得可以点击链接阅读。
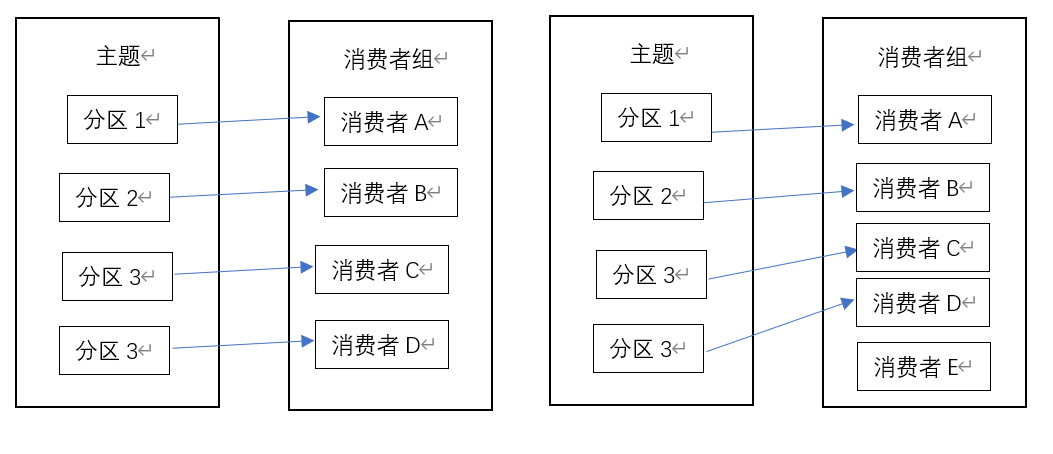
消费者与消费者组
在Kafka中消费者是消费消息的对象。假设目前有一个消费者正在消费消息,但生产数据的速度突然上升,这时候消费者会有点力不从心,跟不上消息生产的速度,这时候咋办呢?
我们对消费者进行横向扩展,加几个消费者,达到负载均衡的作用。但是要做点限制吧,不然几个消费者消费同一个分区的消息,不仅没办法提高消费能力,还会造成重复消费。因此让他们分别消费不同的分区。
在Kafka中的消费者组就是如此,一个消费者组内的消费者订阅同一个Topic的数据,但消费不同分区的数据,提高了消费能力。
但是消费者组里的消费者数量建议不要超过分区数量,不然就浪费资源。

LEO & HW
Kafka中的分区是可以有多个副本的,我们把每个副本中待写入的那个offset称为LEO(Log End Offset),把最少消息的那个副本的LEO称为HW(High Watermark)
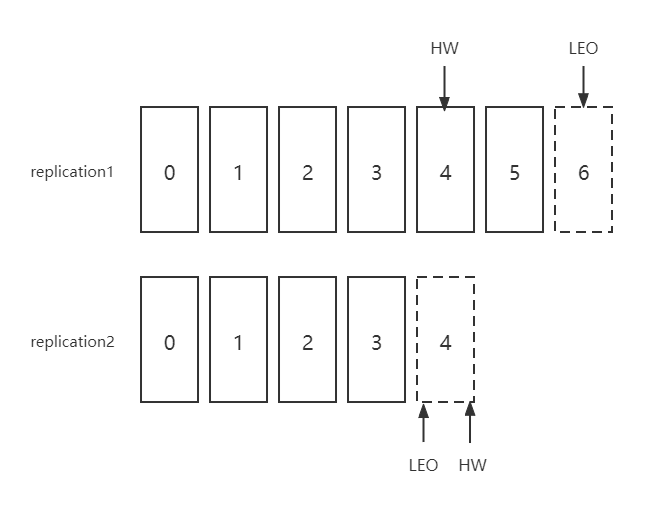
对于消费者而言,消费者所能消费的区间就是小于HW那部分,即图中 0-3 部分。这样消费者不管是哪个副本,订阅到的消息都是一致的,即使换了leader也能接着消费。
提交偏移量
假如一个消费者退出,另一个消费者接替它的任务,这时候就需要知道上一个消费者消费到了哪条数据,因此消费者需要追踪偏移量。
在Kafka中,有一个名为_consumer_offset的主题,消费者会往里面发送消息,提交偏移量,这个时候消费者也是生产者。
当消费者挂了或者有新的消费者假如消费者组,就会触发在均衡操作,即为消费者重新分配分区。
为了能够继续之前的操作,消费者需要获取每个分区最后一次提交的偏移量。
如果提交的偏移量小于处理的最后一个消息的偏移量,会造成重复消费。比如消费者提交了 6 的offset,此时又拉取了2条数据,还没等提交,消费者就挂掉了,然后就发生了再均衡。新的消费者获取到 6 的偏移量,接着处理,这就造成了重复消费。
如果提交的偏移量大于处理的最后一个消息的偏移量,会造成数据丢失。比如消费者一次性拉取了 88 条数据,并且提交了偏移量,还没处理完就宕机了,新的消费者获取 88 的偏移量,继续消费,就造成了数据丢失。
因此,如何提交偏移量对客户端影响很大,稍有不慎就会造成不好的影响。
在Kafka中,有几种提交偏移量的方式。
自动提交
这种提交方式有两个很重要的参数:
enable.auto.commit=true(是否开启自动提交,true or false)
auto.commit.interval.ms=5000(提交偏移量的时间间隔,默认5000ms)
这种方式最容易造成数据丢失以及重复消费。
通过CommitSync()方法手动提交当前偏移量
在处理完所有消息后提交,前提要把enable.auto.commit设置为false。
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for(ConsumerRecords<String, String> record: records){
System.out.println("topic=%s, offset=%s,partition=%s",
record.topic(), record.offset(),record.partition());
}
try{
consumer.commitSync();
} catch(Exception e){
log.error(e);
}
}
消费者通过poll方法轮询获取消息,poll里的参数是一个超时时间,用于控制阻塞的时间,如果没有数据则会阻塞这么久,如果设置为0则会立即放回。
使用这种方法一定要在处理完所有记录后调用CommitSync()方法,避免数据丢失。如果发生错误,会进行重试。
异步提交
CommitSync() 提交偏移量的方式会造成阻塞,即需要等客户端处理完所有消息后才提交偏移量,限制了吞吐量。因此可以使用异步提交的方式,通过调用commitAsync()方法实现。
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for(ConsumerRecords<String, String> record: records){
System.out.println("topic=%s, offset=%s,partition=%s",
record.topic(), record.offset(),record.partition());
}
consumer.commitAsync();
}
提交偏移量后就可以去做其他事了。CommitSync()方式发生错误会重试,但CommitAsync()不会。
之所以不重试,是因为有可能在收到broker响应前有其它偏移量提交了。
试想一下,如果会重试的话,当提交 66 的偏移量时发生网络问题,与此同时提交了 88 的偏移量,这时候刚好网络又通了,然后 88 的偏移量就提交成功了,然后 66 就重试,成功后又变成 66 了,就有可能造成重复消费。
之所以说这个问题,是因为异步提交支持在broker响应时回调,常被用于记录错误或生成度量指标。如果用他重试的话一定要注意提交的顺序。
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for(ConsumerRecords<String, String> record: records){
System.out.println("topic=%s, offset=%s,partition=%s",
record.topic(), record.offset(),record.partition());
}
consumer.commitAsync(new OffsetCommitCallback() {
public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception e){
if(e != null){
log.error("Error");
}
}
});
}
异步与同步组合提交
如果发生在关闭消费者或者再均衡前的最后一次提交,就需要确保其成功。
因此在消费者关闭前一般会通过组合使用的方式确保其提交成功。
try{
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for(ConsumerRecords<String, String> record: records){
System.out.println("topic=%s, offset=%s,partition=%s",
record.topic(),record.offset(),record.partition());
}
consumer.commitAsync();
}
}catch(Exception e){
log.error(e);
}finally {
try {
consumer.commitSync();
}
finally{
consumer.close();
}
}
提交特定偏移量
commitSync() 和 commitAsync() 方法一般是在处理完一个批次后提交偏移量。如果需要更频繁的提交偏移量,需要在处理的过程中间提交的话,消费者 API 允许在调用 commitSync()和 commitAsync () 方法时传进去希望提交的分区和偏移量的 map
Map<TopicPartition, OffsetAndMetadata> currentOffsets = new HashMap<TopicPartition, OffsetAndMetadata>();
int count = 0;
try {
while(true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
if (records.isEmpty()){
continue;
}
for (ConsumerRecord<String, String> record : records){
System.out.println("topic=%s, offset=%s,partition=%s",
record.topic(),record.offset(),record.partition());
currentOffsets.put(new TopicPartition(record.topic(), record.partition()), new OffsetAndMetadata(record.offset(), "no metadata"));
// 每处理完1000条消息后就提交偏移量
if (count%1000==0) {
consumer.commitAsync(currentOffsets, null);
}
count++;
}
}
} finally {
try{
consumer.commitSync();
} finally{
consumer.close();
}
}
消费者分区分配策略
分区会被分配给消费者组里的消费者进行消费,在Kafka种可以通过配置参数partition.assignment.strategy选择分区分配策略。
-
Range 范围分区
假设现在有10个分区,消费者组里有3个消费者。
分区数量 10 除以消费者数量 3 取整(10/3)得 3,设为 x;分区数量 10 模 消费者数量 3(10%3)得 1,设为 y
则前 y 个消费者分得 x+1 个分区;其余消费者分得 x 个分区。
![]()
-
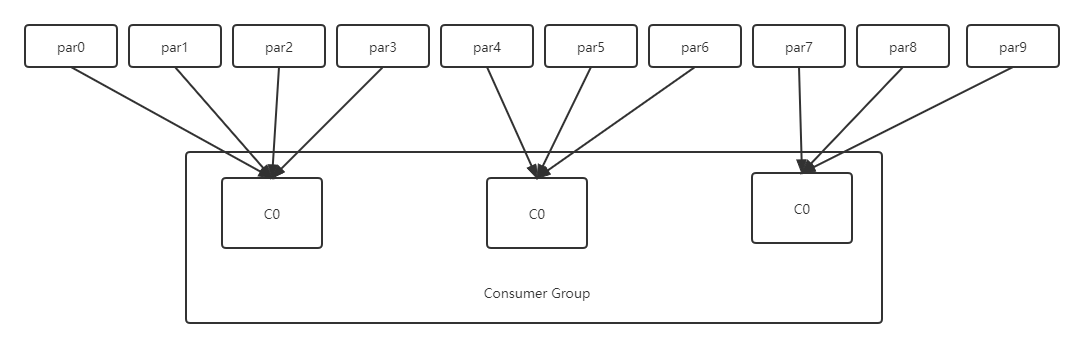
RoundRobin 轮询分区
假设有10个分区,3个消费者,第一个分区给第一个消费者,第二个给第二个消费者,第三个分区给第三个消费者,第四个给第一个消费者... 以此类推

到这,消费者的点就讲得差不多了,可能有些细节没写或者没讲明白。后面如果发现了,我另写一篇补上。如果觉得写得还行得的话,麻烦点个小赞,谢谢!
转载请注明出处:工众号“大数据的奇妙冒险”

 浙公网安备 33010602011771号
浙公网安备 33010602011771号