五、RDD操作综合实例
A.分步骤实现
1.准备文本文件
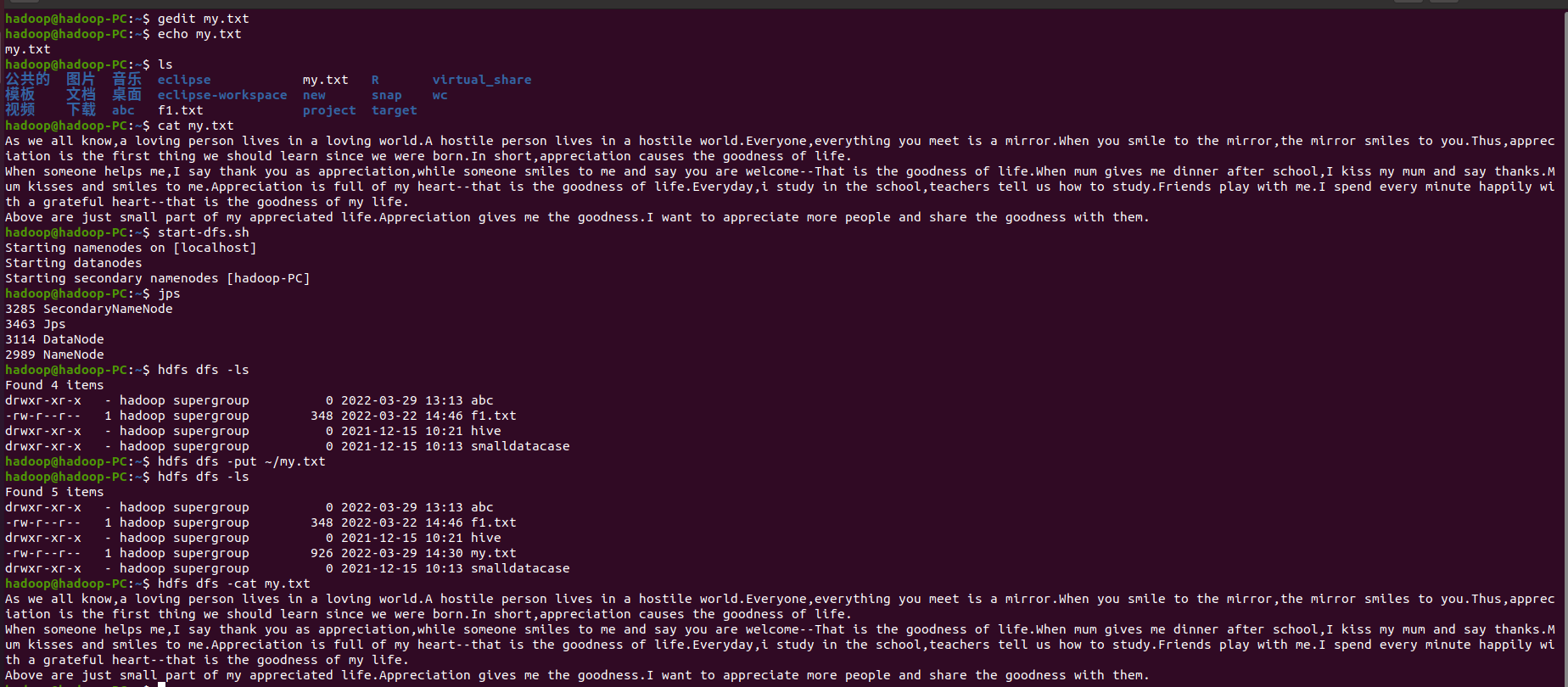
2.读文件
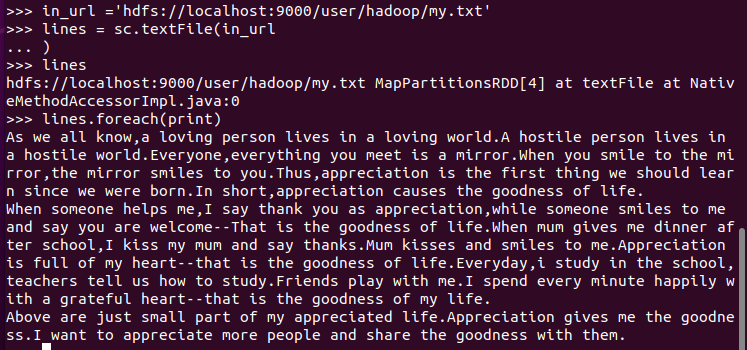
3.分词
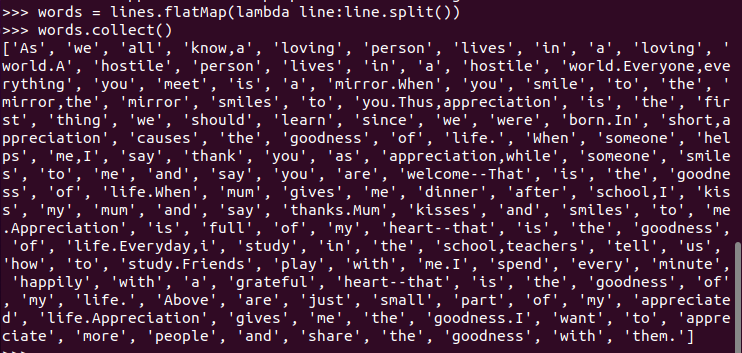
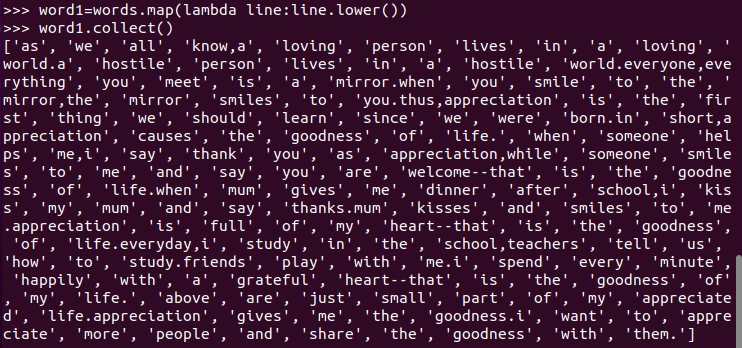
4.排除大小写lower(),map()
标点符号re.split(pattern,str),flatMap()
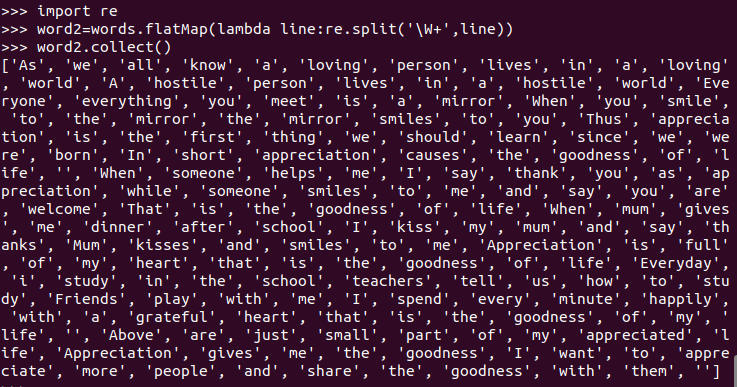
停用词,可网盘下载stopwords.txt,filter()

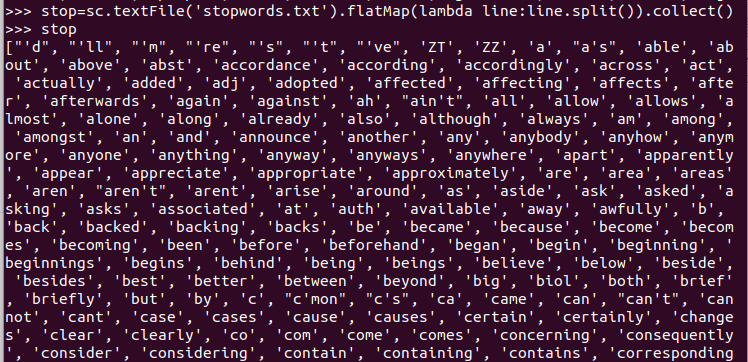
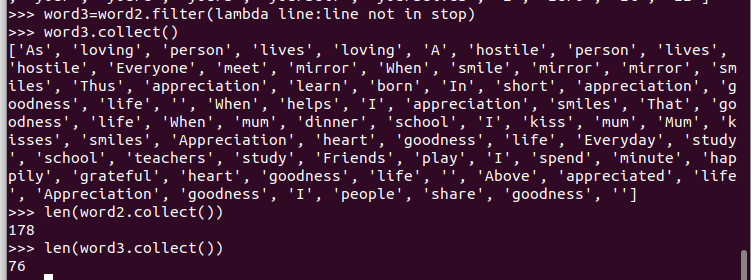
长度小于2的词filter()

5.统计
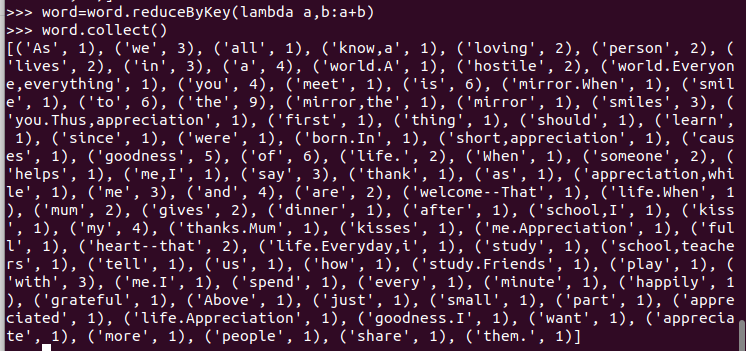
映射成键值对
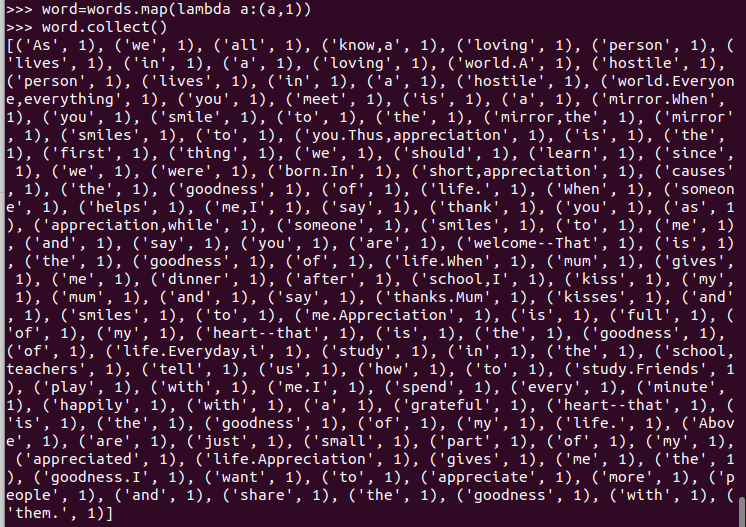
6.排序

7.写文件

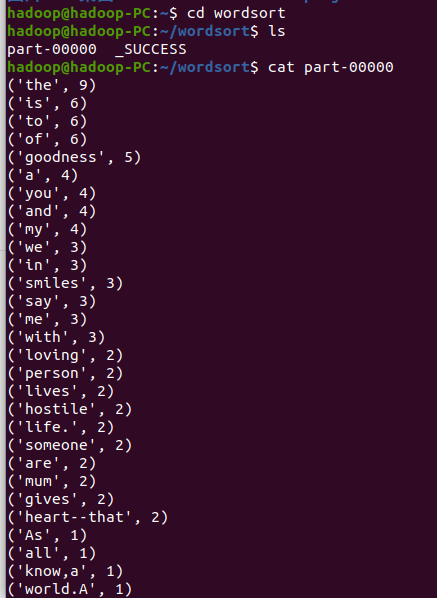
8.查看文件

B.一句话实现
文件入文件出

C.和作业2的“二、Python编程练习:英文文本的词频统计 ”进行比较,理解Spark编程的特点
spark中特征提取中包含四个方法:TF-IDF、Word2Vec、CountVectorizer以及FeatureHasher。其中,TF-IDF以及Word2Vec的使用比较广泛,这里不详细展开,TF-IDF主要用于提取文档的关键词,而Word2Vec将词语或者文章转换为词向量,通过空间距离表示文档的相似度,距离越近则越相似,其中一篇文章的词向量是文章所有词语词向量的平均值,所以使用Word2Vec尽量使用关键词转换词向量。CountVectorizer与TF相似,输出词频向量,但是CountVectorizer是可逆的,而TF是不可逆的,也就是说,CountVectorizer可以通过词频向量的索引找到对应的单词,而TF则不可以。所以在使用spark做关键词提取时,通常使用CountVectorizer和IDF,而如果只需要文档关键词的特征向量的话,则使用TF和IDF。
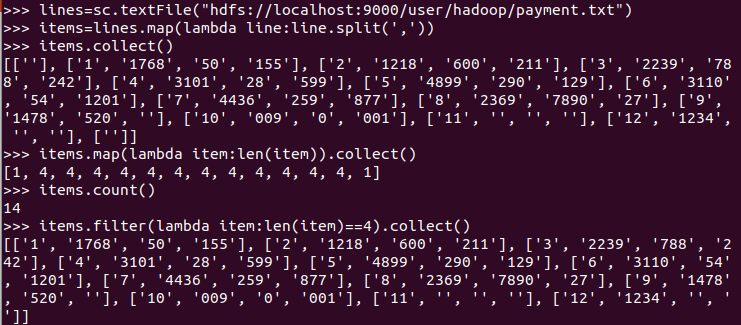
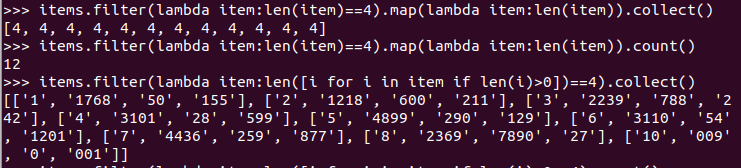
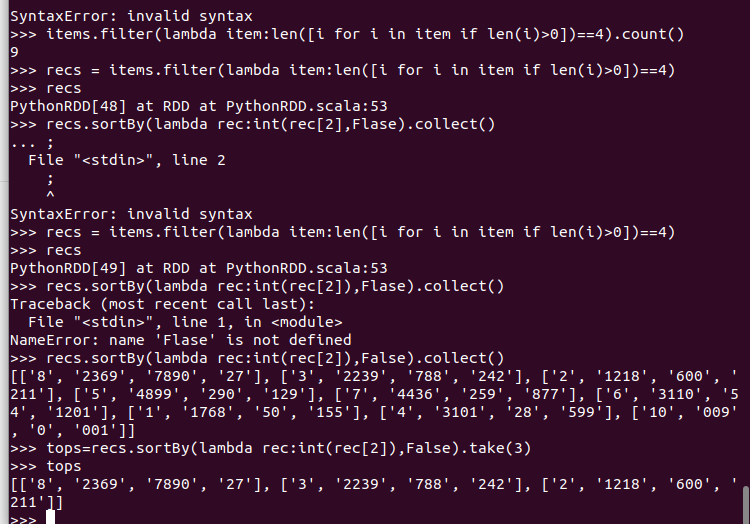
二、求TOP值

 浙公网安备 33010602011771号
浙公网安备 33010602011771号