


R函数处理异步迭代,在爬虫中的作用。
代码分析
-
函数
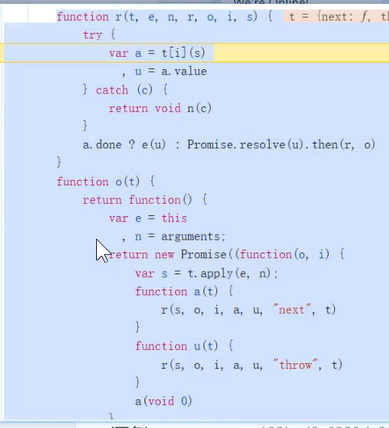
r处理异步迭代function r(t, e, n, r, o, i, s) { try { var a = t[i](s), // 调用迭代器方法,例如 next() u = a.value; // 获取迭代返回的值 } catch (c) { return void n(c); // 处理异常 } a.done ? e(u) : Promise.resolve(u).then(r, o); // 如果迭代完成,调用 e 处理最终值,否则递归处理 Promise 以执行后续操作 }
- 这里
t[i](s)可能是对 异步生成器 (async generator) 的调用,如next()或throw()。 Promise.resolve(u).then(r, o);使得代码可以顺序执行async/await逻辑。
- 这里
- 函数
o(t)返回一个新的 Promise 包装器function o(t) { return function () { var e = this, n = arguments; return new Promise(function (o, i) { var s = t.apply(e, n); function a(t) { r(s, o, i, a, u, "next", t); } function u(t) { r(s, o, i, a, u, "throw", t); } a(void 0); }); }; }
-
o(t)是一个高阶函数,返回另一个函数。- 这个返回的函数执行后,会创建一个
Promise并调用t.apply(e, n),即执行原始函数t。
-
a(t) 处理 next() 迭代,而 u(t) 处理 throw() 异常,确保 async/await 代码可以顺序执行。
爬虫相关作用
这段代码的核心功能是将异步生成器 (async generator) 包装成 Promise,从而支持 async/await 语法。这在爬虫开发中非常有用,主要体现在以下方面:
-
顺序执行异步请求
- 现代爬虫通常需要异步获取多个网页,使用
async/await让代码看起来更直观,避免回调地狱。 - 例如,爬取多个页面时:
async function crawlPages(urls) { for (const url of urls) { const data = await fetch(url).then(res => res.text()); console.log(`Fetched data from ${url}`); } }
- 现代爬虫通常需要异步获取多个网页,使用
2.处理 Promise 失败和重试
-
- 通过
catch (c) { return void n(c); },代码可以捕获爬虫请求中的错误,如网络超时、403/404 响应等。
- 通过
可以结合重试逻辑来提高爬取成功率
async function fetchWithRetry(url, retries = 3) { for (let i = 0; i < retries; i++) { try { return await fetch(url).then(res => res.text()); } catch (error) { console.log(`Retry ${i + 1} for ${url}`); } } throw new Error(`Failed to fetch ${url} after ${retries} attempts`); }
3.支持爬取数据的流式处理
- 代码涉及
Promise.resolve(u).then(r, o);,这意味着它可以在数据部分获取后立即处理,而无需等待整个任务完成。 - 这对于增量爬取(如爬取动态加载的网页内容)非常重要,例如
async function* streamCrawl(urls) { for (const url of urls) { yield await fetch(url).then(res => res.text()); } } (async () => { for await (const pageData of streamCrawl(["url1", "url2"])) { console.log(pageData); } })();
总结
这段代码的主要目的是将异步函数转换为基于 Promise 的执行流,它在爬虫领域的关键作用包括:
- 简化异步爬取任务
- 支持
async/await语法,使代码更加清晰 - 错误处理(超时、403/404 失败等)
- 支持流式爬取,提高数据处理效率
这些特性使得代码适用于爬取 API、动态网页数据提取、增量爬取等应用场景。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号