redis缓存解决方案
缓存设计
缓存穿透
一般来说,我们的业务处理是,先查缓存,如果缓存中没有数据的话再查DB并将DB数据进行缓存并返回给用户。我们假定有个恶意用户,疯狂查询一些不存在的数据,这些数据肯定是在缓存层找不到的,然后这些请求就会打到数据库,这下缓存层就失去了存在的意义。
解决方案:
在接收到用户请求时,如果找不到数据,依旧将空数据进行缓存,这样下次有恶意请求来的话就直接从缓存中获取到空数据进行返回即可。
@GetMapping("/test")
public String test(String name){
String s = stringRedisTemplate.opsForValue().get(name);
if (s == null) {
// 查询db 如果数据库查询不到数据依旧将空对象缓存到redis,避免缓存穿透
User user = userService.selectByName(name);
if (user == null) {
stringRedisTemplate.opsForValue().set(name, "");
} else {
s = user.toString();
stringRedisTemplate.opsForValue().set(name, s);
}
}
return s;
}
缓存击穿
大批量缓存同时失效,这时候又有大量请求发送过来,这些请求同时会打到数据库中,导致数据库压力激增。
解决方案:
让热点数据的过期时间不要设置成同一失效时间,避免缓存同时失效
if (s == null) {
// 缓存过期时间加个随机数,避免缓存同时失效
User user = userService.selectByName(name);
stringRedisTemplate.opsForValue().set(name, user.toString(), new Random().nextInt() + 5400, TimeUnit.MILLISECONDS);
}
缓存雪崩
缓存层崩溃导致所有请求都打到了DB层,最终DB层接收了大量请求最终崩溃。
解决方案:
- 缓存层添加分布式部署,例如Redis Cluster,避免一个redis挂了,整个缓存都挂了。
- 如果在特殊场景下,整个缓存层确实全部挂掉了,那么后端可以添加限流、熔断降级操作,只接收部分请求,其他请求统一拦截,避免大量请求打到DB中。
- 上线前预估系统最大接收并发数,尽量做一些基础的预案。
热点缓存key重建
一般来说,缓存+过期时间就可以解决大部分需求,但是在以下两种场景下会出现问题:
- 某个热点key失效了并且这个key并发量非常大,那么在重建key的过程中,会导致大量请求打到DB中。
- 某个冷门key没人访问,突然有一天有大批量的人访问这个key,这个也会在key重建的过程中,会导致大量请求打到数据库中。
解决方案:
添加互斥锁,只允许一个线程去访问数据库重建缓存,其他线程进入使进行睡眠等待缓存重建完毕后进行返回。
数据库缓存双写不一致
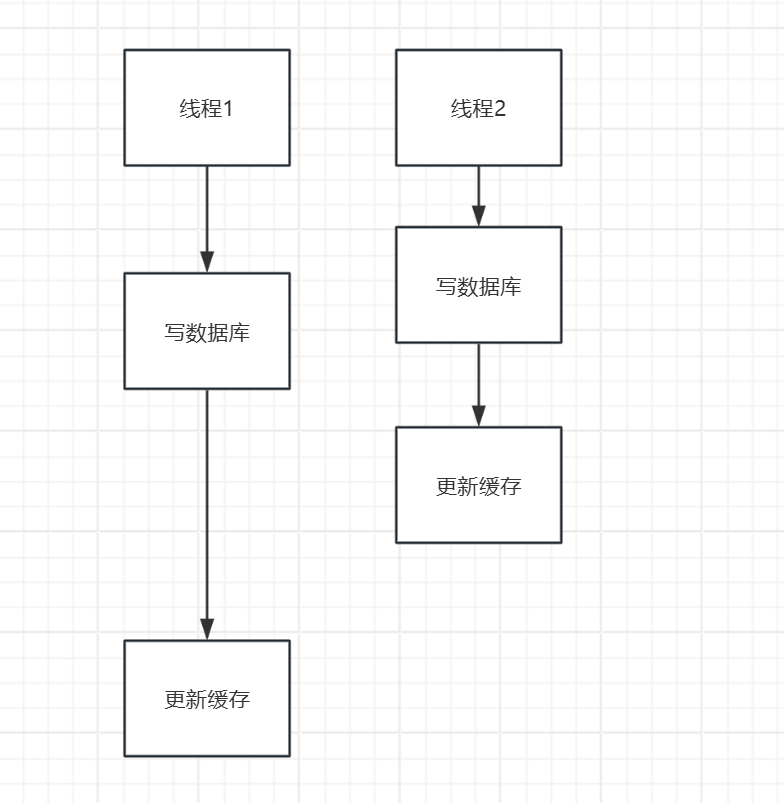
情况1的双写不一致的情况如下图所示,线程1和线程2都要写数据库更新缓存,线程1写完数据库后遇到了网络抖动或其他问题导致迟迟没有更新缓存,这时候线程2来了,写数据库和更新缓存都很顺利完成了更新,这时候线程1不卡了并更新完成缓存了,这时候就会出现线程1更新的缓存数据会把线程2的缓存数据覆盖掉,这样就出现了双写不一致的问题。
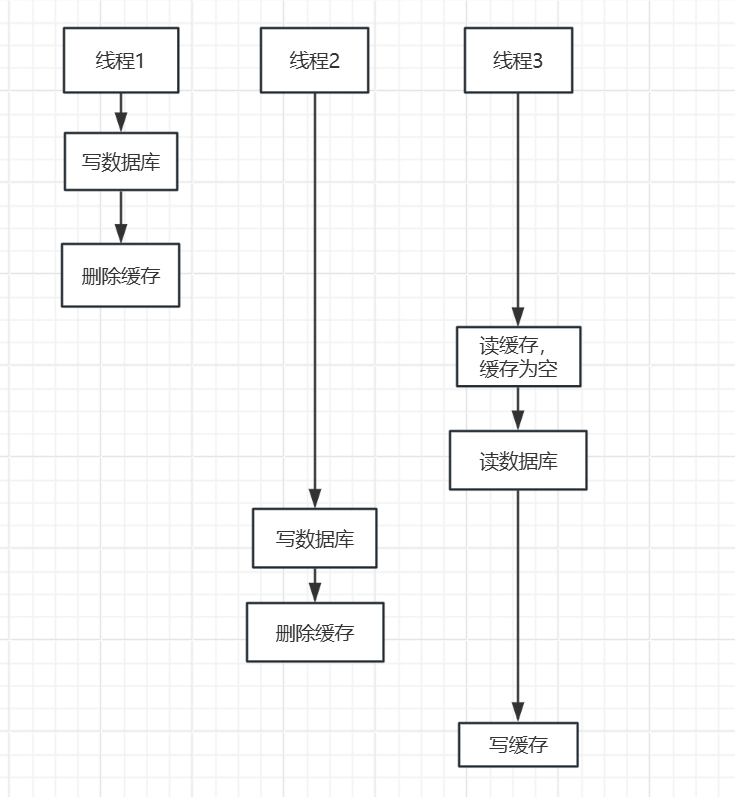
情况2的双写不一致的情况如下图所示,有三个线程,线程先进入,修改数据库后将旧缓存数据删除,这时候线程3进行了读操作,这时候缓存值因为被线程1删除了,所以缓存是空的,这时候读到的数据是线程1写入的数据库的值,这时候有出现了异常情况导致迟迟没有将缓存写入到缓存中,这时候线程2进来了,这时候没有卡,执行了写数据库和删除缓存操作,执行完成后线程3突然有不卡了,这时候督导的是线程1写入的值而不是线程2写入的值,这时候也出现了数据库双写不一致的问题。
双写不一致的情况下有些是可以容忍的,例如个人用户数据这些即便是出现了双写不一致问题也不影响整个系统的使用,这个只要等待缓存失效之后读取最新的数据更新到缓存中即可,这些数据保证最终一致性即可。
只有公共数据且并发量比较高的情况下会影响整个系统的才会要处理双写不一致,例如商品信息等等。
解决方案
串行执行
只要保证串行执行就可以解决这个问题,一个线程按先来后到进行排队,逐个处理,这个因为是单个线程单个线程执行,就不会出现同时访问一个缓存的问题,就不会出现并发问题,所以也不会出现这个双写不一致的问题。
延迟双删
更新数据库后将缓存删除,然后等待一段时间再删一次数据库,这时候就可以解决情况2的情况,等待线程3更新完数据库后再删一次缓存保证下次读出来的数据是对的。
需要注意的,延迟双删可以尽量降低缓存不一致的问题的,由于在进行第二次删除的时候依旧有可能有线程读到旧数据,将旧数据填充到缓存中。延迟双删可以降低缓存不一致的概率。
还有一个问题就是,由于每次写数据之后需要等待一段时间再删一次数据库,等待是需要时间的,这样做会降低整体系统的效率的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号