RabbitMQ简介、单机以及集群的搭建
消息队列应用场景
解耦
将各服务直接解耦。有订单服务,订单服务创建订单时需要减库存、需要扣金额和需要发送优惠券。在没用消息队列前,订单创建完毕时,需要在订单服务中调用库存服务、金额服务以及优惠券服务,如果之后还需要在订单服务执行完毕之后执行一些某些操作还得需要在订单服务中继续添加,这样耦合度较高,并不利于后期维护。如果使用了消息队列之后,当订单创建后,直接将消息发送到队列中,其余服务监听该队列即可,一旦队列中有消息直接拿取消息直接消费即可,如果又添加新服务也一样,继续监听该队列即可,这样就做到了应用之间的解耦。
削峰
将大量请求存储到消息队列中,每次消费时,慢慢从消息队列中获取消息,这样一来就避免了大量请求打到服务器中,使服务器瘫痪的问题。
异步
异步与同步的区别是同步在上一个请求执行完毕才能执行下一个请求,而异步则是在上一步未执行完毕则可以执行下一个请求。
缺点
- 系统复杂性变高: 引入消息队列之后系统复杂度会变高且还会出现一些问题,比如如何保证消费端消信息、幂等性等等。
- 可用性降低:如果消息队列宕机了会印象到当前服务,使得系统可用性降低。
- 消息一致性:服务1发送消息到服务2,服务1执行成功,但是服务2执行失败,应该如何处理。
常用的消息队列
Kafka
优点:高性能、高吞吐量和高可用
缺点:数据格式单一以及容易使消息丢失
用于日志分析和大数据场景
RabbitMQ
优点:消息可靠性高、功能全面
缺点:基于Erlang 无法灵活定制。如果队列累计消息较多会影响性能、吞吐量较低。
用于本地服务之前的调用。
RocketMQ
优点:高吞吐量、高可用、高性能、功能全面
缺点:开源版本不如商业版本且客户端只支持Java语言。
用于大部分场景。
环境搭建
单机
- 修改hostname以及/etc/hosts映射
hostnamectl set-hostname fedora02
2. 查看安装RabbitMQ所需Earlang版本
https://www.rabbitmq.com/which-erlang.html
从https://github.com/rabbitmq/erlang-rpm/releases下载所需earlang的rpm文件
使用rpm -ivh命令安装earlang
rpm -ivh erlang-25.0-1.el9.x86_64.rpm
- 安装RabbitMQ
从https://github.com/rabbitmq/rabbitmq-server/releases下载RabbitMQ要安装的版本
noarch表示支持任意CPU并使用rpm -ivh命令安装RabbitMQ
rpm -ivh rabbitmq-server-3.10.5-1.el8.noarch_.rpm
- 启动服务
使用service rabbitmq-server start启动RabbitMQ服务。
使用service rabbitmq-server status查看RabbitMQ服务是否为active
相关命令
rabbitmq-server -deched --后台启动服务
rabbitmqctl start_app --启动服务
rabbitmqctl stop_app --关闭服务
安装web管理界面
rabbitmq-plugins enable rabbitmq_management
关闭防火墙
systemctl stop firewalld
- 创建用户
由于guest用户只允许localhost登录,所以需要创建用户并授权才能进行登录。
[root@192 ~]# rabbitmqctl add_user lyra lyra
[root@192 ~]# rabbitmqctl set_permissions -p / lyra "." "." ".*"
[root@192 ~]# rabbitmqctl set_user_tags lyra administrator
集群搭建
集群分为普通集群和镜像集群,RabbitMQ官方推荐使用镜像集群。
普通集群模式下只会对元数据进行共享,比如交换机类型,队列类型等等,而不会对消息进行共享,当服务对消息进行消费时访问的节点没用所需消息时,RabbitMQ会从其他节点拉取所需需消息,如果存储消息的节点刚好宕机,则消息丢失,必须重启该节点才能进行消费,这样无法保证高可用。
二镜像集群则是普通集群的增强版本,它会在空闲时将消息以及元数据进行同步,单个节点失效并无太大影响,但是这种模式需要消耗带宽同步数据,系统性能会下降。
普通集群
-
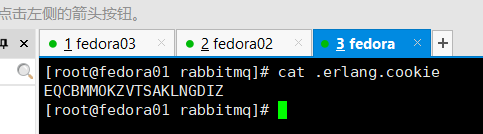
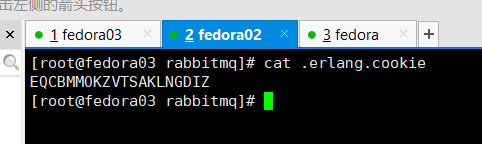
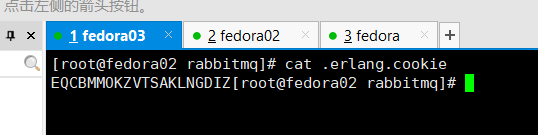
需要在/var/lib/rabbitmq/.erlang.cookie创建相同内容的文件,可以先添加写全写,之后在将权限改为400,避免之后出错,三台机器的.erlang.cookie文件如下所示。
-
需要在/etc/hosts中配置机器的映射,将ip与主机名称绑定起来,三台机器都需要该配置。
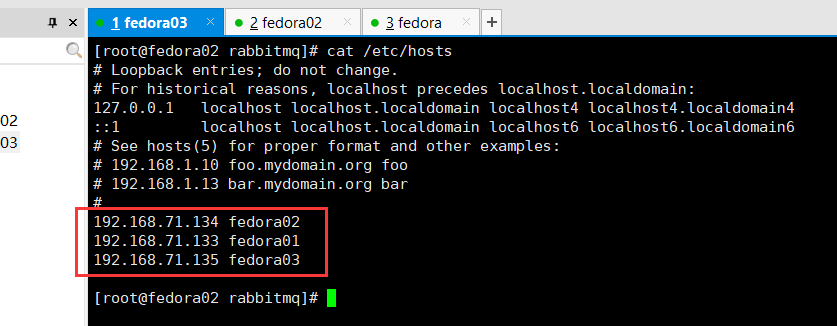
-
之后需要启动一台rabbit-server机子
这里启动的是fedora02
systemctl start rabbitmq-server.service
- 之后将其他节点服务启动,但将应用关闭,将节点加入到集群后再启动应用,加入的节点是之前启动fedora02,两台机器执行的命令相同 --ram表示
systemctl stop rabbitmq-server.service
rabbitmqctl stop_app
abbitmqctl join_cluster --ram rabbit@fedora02
rabbitmqctl stop_app
之后三台机器组成一个集群,在web页面可以看到以下信息

节点Info为ram性能会高,但是机器宕机元数据会消失,官方推荐使用disc。之前abbitmqctl join_cluster --ram/disc 节点加入集群时可以指定使用ram还是disc方式。

rabbitmqctl cluster_status查看集群信息
镜像模式
镜像模式是在普通模式上的基础上进行搭建的。
通过配置虚拟主机来将每个实例间的权限、策略进行隔离。
- 创建虚拟主机并设置ha-mode策略
rabbitmqctl add_vhost /mirror
rabbitmqctl set_policy ha-all --vhost "/mirror" "^" '{"ha-mode":"all"}'
也可以在web页面中进行设置
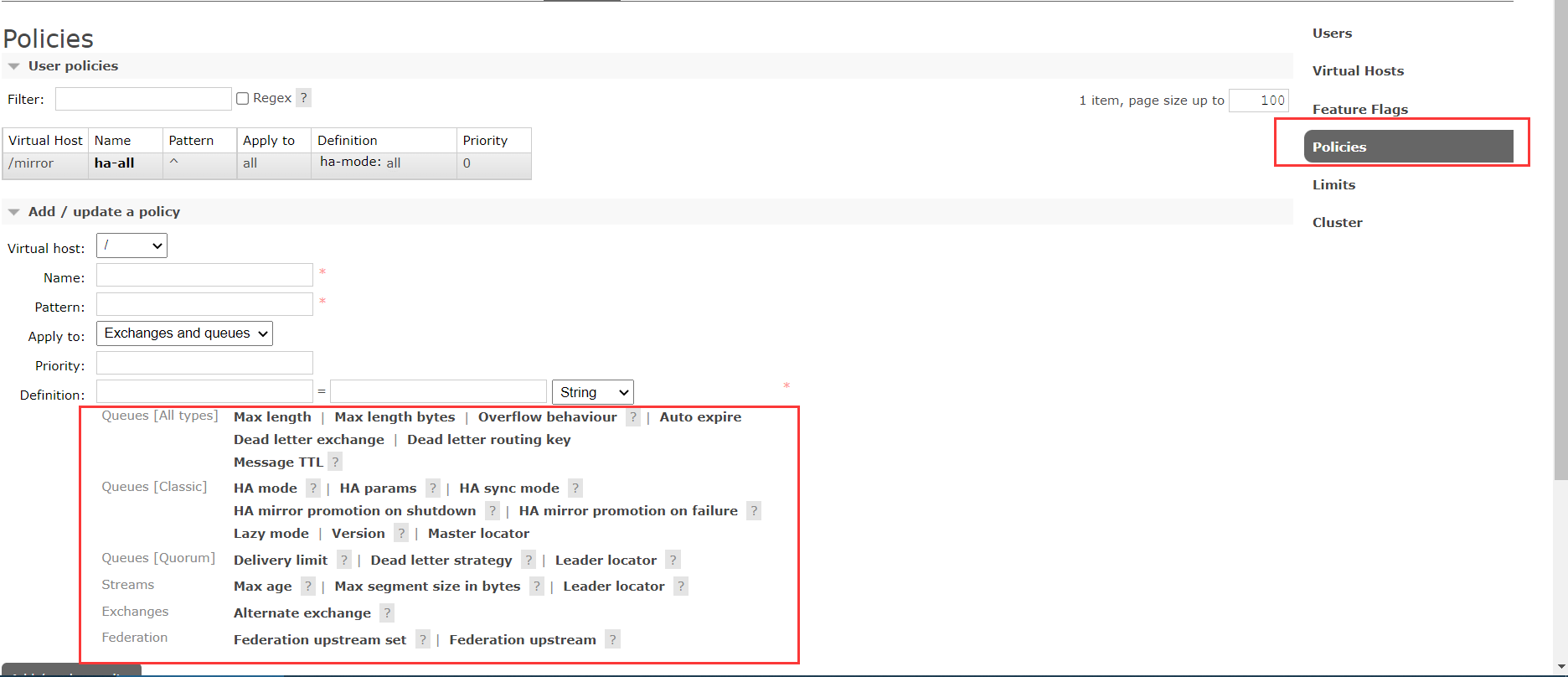
表示全部匹配ha表示匹配以ha开头。
之后将虚拟主机分配到用户中即可,然后在该虚拟主机中添加消息将会被集群中其他几个节点进行同步。
在user界面点击用户
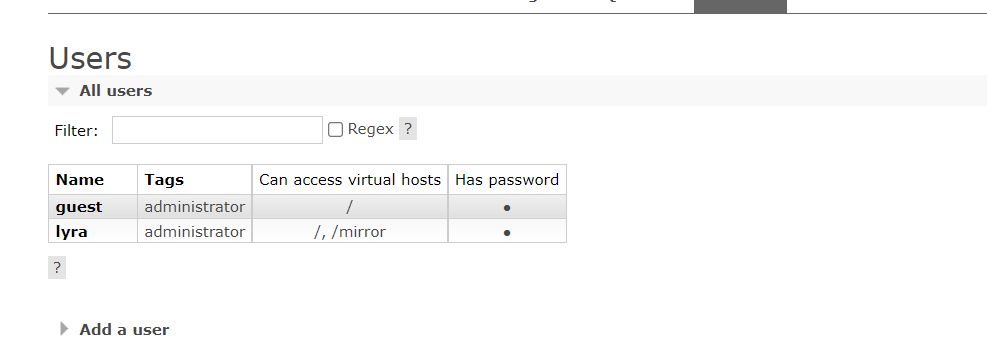
添加虚拟主机。
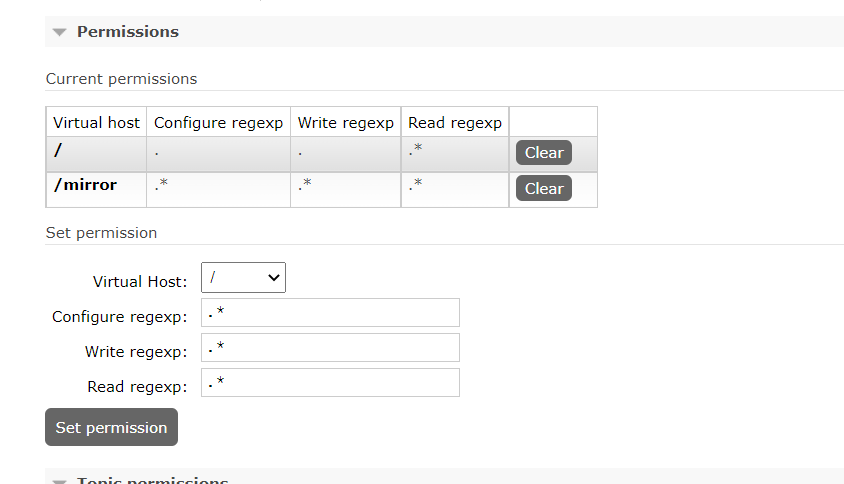
在虚拟主机中添加队列
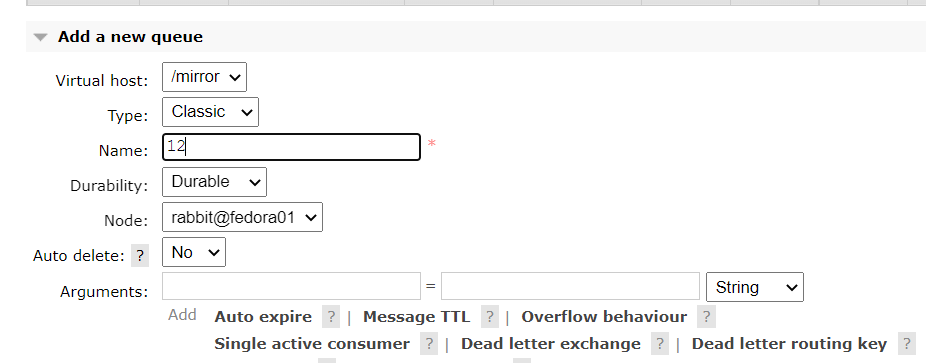
在队列中发布消息将会被集群中的其他节点同步
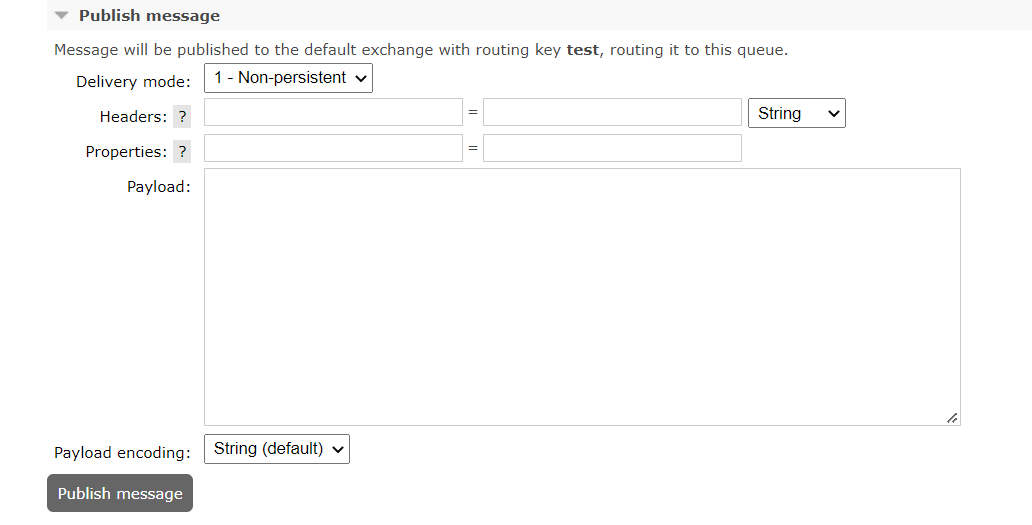
其中Ha-mode参数如果设置为all则可以保证高可用,设置为all,当新节点加入集群时,将会将消息复制到新节点中复制一份。
exactly:设置一个count,当新加入节点小于count时则会作为镜像,将消息复制到镜像中,如果大于count则不会成为镜像。
nodes:需要搭配一个字符串类型的参数。将队列镜像到指定的节点上。如果指定的
队列不在集群中,不会报错。当声明队列时,如果指定的所有镜像节点都不在线,那队列
会被创建在发起声明的客户端节点上。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号