


ai白皮书阅读
https://www.aliyun.com/reports/2025-ai-supercompany
应用运行时 (第8章)
- 模型运行时
- 智能体运行时

讲的是复杂的需求超越了 无状态 api服务的调用,需要有状态、沙箱化的环境
讲的是服务器的租用模式、函数式计算服务的区别。
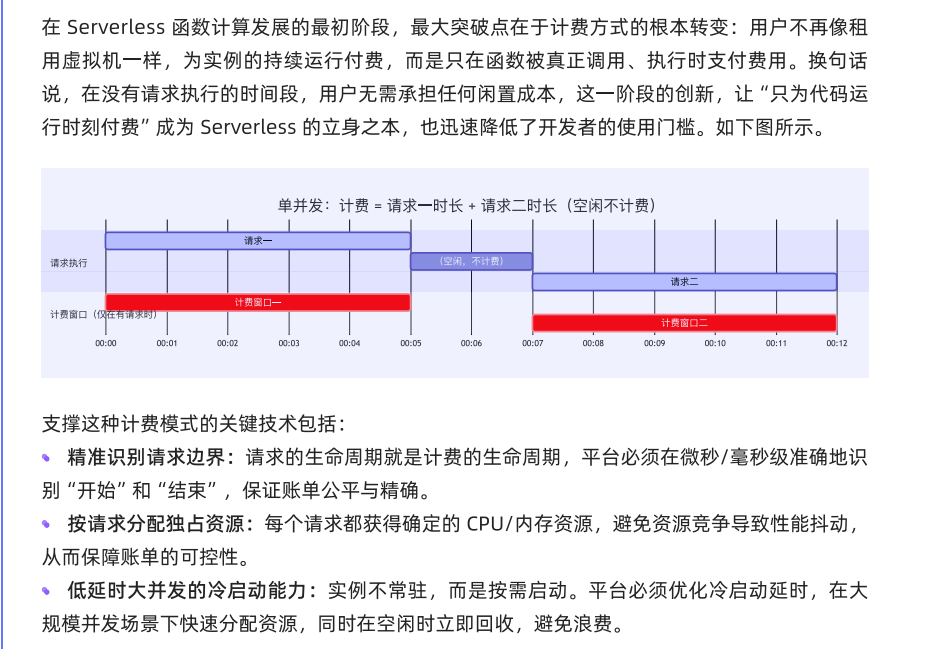
函数式计算收费架构。
ai可观测性 (第9章)
- 基于网关的可观测性
- 推理引擎可观测性
ai评估-9 (第10章)
提高ai的输出质量方法的探究:
- 基于评估降低ai不确定性
- ai评估体系
- 基于LLM的自动化评估 (LLM as judge )
- 自动化评估落地实践
第10章--探究AI风险
- 确保用户无法篡改指令
问题总结
- 向量数据库的原理是什么,有什么局限性?
- 知识图谱和向量数据库是怎么做到互补的?
- vda、asr、tts、sadtalker 这些术语分别是什么?
- spec coding: 目前司内关于从 Vibe Coding 到 Spec Coding 的探讨较多,跨境、通讯均有关于 spec coding 的实践,发布到 Km 上。我们团队有必要使用 spec coding 吗?如果有必要,使用哪种方法 or 规范?如果没有必要,谈谈你的看法
向量数据库的原理是什么,有什么局限性?
向量数据库是专为处理高维向量数据而设计的数据库系统,它通过特定的索引和搜索算法,能够快速找到与给定目标最相似的数据点。下面这个表格清晰地对比了它的核心原理与主要局限性。
数据处理:
- 可以将文本,图片统一转化为高维向量,计算向量的相似度
- 向量相似度搜索的局限性: 难以直接处理精确的关键字匹配、布尔逻辑查询等传统搜索任务
- 使用近似最近邻(ANN)算法,牺牲少量精度以换取检索速度的巨大提升
- 维度灾难问题: 高维数据下计算和存储成本高,且可能影响结果区分度
- 支持将向量与元数据(如价格、标签)结合,进行混合查询
- 将向量搜索与业务规则、元数据过滤深度结合的灵活性和表达能力仍显不
什么时候使用向量数据库:
应用核心需求是语义相似性搜索、推荐系统或AI推理,那么向量数据库是强有力的工具。但如果你的业务仅需精确匹配查询或处理高度结构化的数据,传统关系型数据库或搜索引擎可能更简单高效。
知识图谱和向量数据库是怎么做到互补的?
简单的说 向量数据库是关注具体细节的搜索逻辑, 而知识图谱这是关注全局的关联逻辑, 比如有一些需要推理的场景, 语义相似度搜索就不适合了,
知识图谱是将知识实体的关系构建出图的结构,基于这种关联结构,可以构建出实体之间的关联关系, 可以弥补向量数据库集中于语义搜索的不足。
查了一下相关的概念:
- VectorRAG (向量 RAG) 将文本嵌入为向量,基于向量相似度(如余弦相似度)检索语义上相似的文档块或上下文,可能无法找到特定实体,容易在抽取式问题中丢失关键上下文信息,上下文质量不一致
- GraphRAG (图 RAG) 使用查询在知识图谱 (KG) 中搜索相关的节点(实体)和边(关系),提取子图作为上下文。擅长精确的事实检索、推理和处理实体关系,在抽取式问答中表现优异。构建和维护高质量知识图谱成本高,在需要泛化和抽象的摘要式问题中表现不佳。
- HybridRAG (混合 RAG) 将 VectorRAG 和 GraphRAG 的检索结果结合起来,取长补短。 这样做,架构更复杂,开发成本和定制化要求高
vda、asr、tts、sadtalker 这些术语分别是什么?
- VDA: Video Depth Anything 视觉位移分析:高精度测量物体位移和形变。视频深度估计:为视频的每一帧生成深度图(距离信息)
- ASR: Automatic Speech Recognition 自动语音识别:将人类的语音信号转换为对应的文本
- TTS: Text-to-Speech 语音合成:将文本信息转换成可听的、自然流畅的语音
- SadTalker: 英文可以翻译为数字人视频生成, 让一张静态人物图片根据一段输入的音频,生成一段开口说话的视频,并模拟口型、表情和头部微动作
这些技术的使用场景?
在实际应用中,这些技术常常组合使用,创造出更强大的应用。例如,在一个完整的数字人交互场景中:
- ASR 负责将用户的语音转化为文本 (输入)
- 大语言模型 (LLM) 对文本进行理解并生成回答内容 (处理)
- TTS 技术将回答文本合成为语音音频 (输出)
- SadTalker 这类技术则是根据TTS的语音输出构建出数字人视频。
网上看到的一个游戏 (Whispers from the Star),应该是用了这类技术
https://www.bilibili.com/vid eo/BV1W8RDYoETv/?vd_source=5680f9cc1e793f7b70191c94d5552ecb
Vibe Coding 和 spec coding 是什么?
这2种都是对AI编程的模式的命名总结。
Vibe Coding: 灵感即代码,用户提示词作为唯一的输入让AI进行开发
Spec Coding: 规范(spec)驱动编程

它为 AI 编程工具(Claude Code、Cursor、Codex、OpenCode、windsurf 等)提供一种标准化的方式:
- 让 AI 生成、跟踪、验证、归档 功能变更;
- 把“功能需求 → 任务分解 → 实现 → 验收” 全流程结构化;
- 实现 AI 与人协同开发 的一致性。
🧠 核心理念:
- “让 AI 先写清楚规范(spec)再写代码” 而不是盲目凭 prompt 去写。
spec coding解决了什么问题?
Spec coding 的出现,主要是为了解决当前直接使用 AI 编程助手时的一个核心问题:不可预测性和上下文丢失。
• 没有 Spec (传统AI编程):你在聊天窗口中向AI描述一个需求(如“添加用户个人资料搜索功能”),AI直接生成代码。但需求细节、讨论过程和最终决定都散落在聊天历史中,难以回顾、评审和保持一致。下次再让AI修改相关功能时,它可能已经忘记了之前的约定。
• 使用 Spec coding(规范驱动):你会先命令AI“创建一个 Spec 提案来添加搜索功能”。AI会在 规范对应的目录下生成结构化的文件,包括清晰的规范描述(如“系统必须允许按角色和团队过滤用户档案”)和实现任务列表。所有的意图都被锁定在规范文件中,而不是聊天记录里。之后的实现和未来的修改都基于这个单一、明确的规范来源。
为什么用 spec coding ,传统的 vibe coding 有什么弊端?
传统的vibe coding 需要用户编写大量的prompts, 然后让ai去理解 prompt的意思,然后开发, 如果会有大量的幻觉,上下文丢失的问题写出来的代码质量也不高。
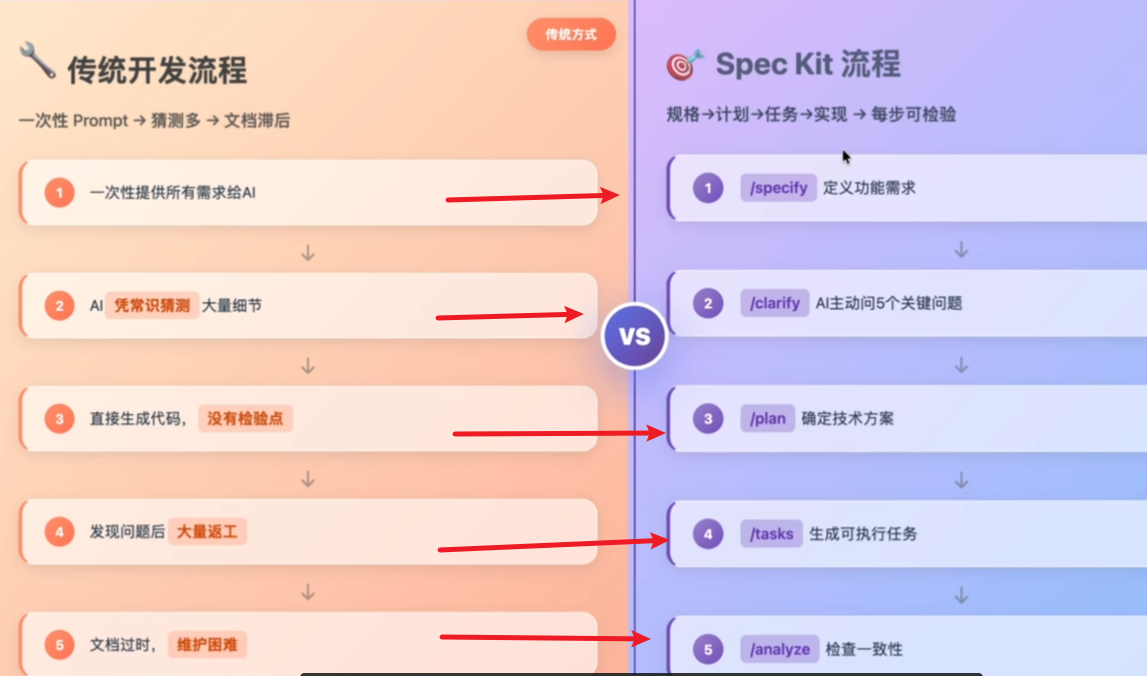
spec coding的步骤:
/specify定义功能需求/clarifyAi主动问几个关键的问题/plan定好技术方案/tasks生成可以执行的任务/analyze一致性分析
发现一个开源的项目叫做 OpenSpec ,
https://github.com/Fission-AI/OpenSpec
- Spec Coding(规范驱动开发):这是一种理念和方法论。它强调在编写代码之前,先编写清晰、明确的规范(Specifications)来描述软件应该做什么。这确保了所有参与者(包括人类和AI)对目标有共同的理解。
- OpenSpec:这是一个具体的框架和CLI工具,它实现并强制执行了 spec coding 的工作流。它提供了一套完整的结构、命令和约定,让团队能够轻松地将 spec coding 的理念应用到日常开发中,尤其是与AI编程助手协作时。
OpenSpec 为 spec coding 理念提供了以下具体的实现:
-
标准化的文件结构:它创建了明确的目录(openspec/specs/ 用于存储当前规范,openspec/changes/ 用于管理变更提案),这强制规定了规范应该放在哪里、如何组织。
-
定义好的工作流程:它将 spec coding 的循环“编写规范 -> 实现 -> 更新规范”具体化为一个可操作的四步流程:
- 起草提案:为每个新功能或修改创建一个包含规范变更(Delta)的提案。
- 评审对齐:人类和AI基于提案中的规范进行讨论,直到达成一致。
- 实现任务:AI根据已达成一致的规范(而不是模糊的聊天记录)来编写代码。
- 归档更新:将已完成的变更合并回主规范库,使规范始终保持最新。
-
工具集成:它通过生成特定的配置文件,将这套工作流直接集成到各种流行的AI编程助手(如 GitHub Copilot, Cursor, Claude Code 等)中,让开发者可以通过简单的斜杠命令(如 /openspec-proposal)来触发整个流程。
-
变更跟踪:它通过“Delta”格式清晰地记录规范的每一次变更(新增、修改、删除),使得规范的演进过程可追溯、可审计。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号