


pandas 行索引
pandas索引修改

>>> df.index = pd.Index(list('ABCD'))
>>> df.columns = pd.Index(list('abcd'))
>>> df
a b c d
A 0.776520 0.093637 0.819028 0.304640
B 0.130550 0.682061 0.102499 0.782682
C 0.995216 0.959426 0.337403 0.897070
D 0.253985 0.161841 0.536915 0.269828
pandas 行索引改为日期
import pandas as pd
# 示例数据(假设已有 'date' 列)
data = {
'date': ['2023-01-01', '2023-01-02', '2023-01-03'],
'value': [100, 200, 300]
}
df = pd.DataFrame(data)
# 将 'date' 列转换为 datetime 类型,并设为索引
df['date'] = pd.to_datetime(df['date'])
df.set_index('date', inplace=True)
print(df)
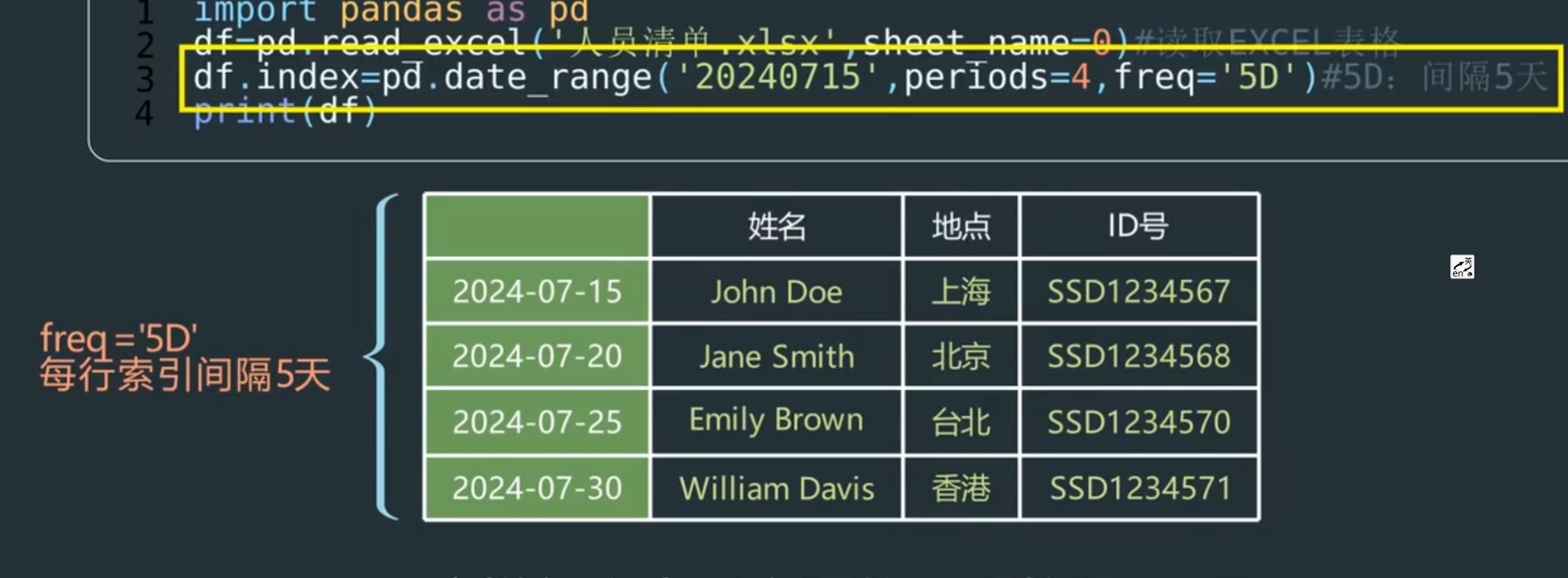
import pandas as pd
# calling DataFrame constructor
df = pd.DataFrame()
# Create 6 dates
df['time'] = pd.date_range('2/5/2019', periods = 6, freq ='2H')
print(df['time']) # print dataframe
# Extract features - year, month, day, hour, and minute
df['year'] = df['time'].dt.year
df['month'] = df['time'].dt.month
df['day'] = df['time'].dt.day
df['hour'] = df['time'].dt.hour
df['minute'] = df['time'].dt.minute
# Show six rows
df.head(6)
rename
dataframe[column_name].rename('industry')
dataframe.rename(columns={ 'name':'industry'})
dataframe 筛选行


筛选列数据
import numpy as np
# 添加缺失值
df.loc[2, 'Age'] = np.nan
# 筛选 Age 等于 25 或 NaN 的行
filtered_df = df[df['Age'].eq(25) | df['Age'].isna()]
参数说明
| 方法 | 参数 | 作用 |
|---|---|---|
eq() |
other |
判断元素是否等于 other |
ne() |
other |
判断元素是否不等于 other |
isin() |
values |
判断元素是否在 values 列表中 |
str.contains() |
pat |
判断字符串是否包含子串 pat |
query() |
expr |
使用字符串表达式筛选数据 |
总结
- 精确匹配:优先使用
eq()或== - 多条件筛选:用
&(与)、|(或)连接条件,注意括号 - 缺失值处理:结合
isna()或fillna() - 灵活查询:
query()适合复杂逻辑表达式
通过组合这些方法,可以高效完成数据筛选任务。
根据平均值筛选
df=df[df.最高.lt( df.最高.mean() -23)]
print(df)
字符串筛选
df = df[df.loc[:'书名'].str.len() < 15]

索引切片
df = df[:3]
# 选择最后4行
df = df[-4:]
# 每隔2行选, 返回奇数行
df = df[1::2]

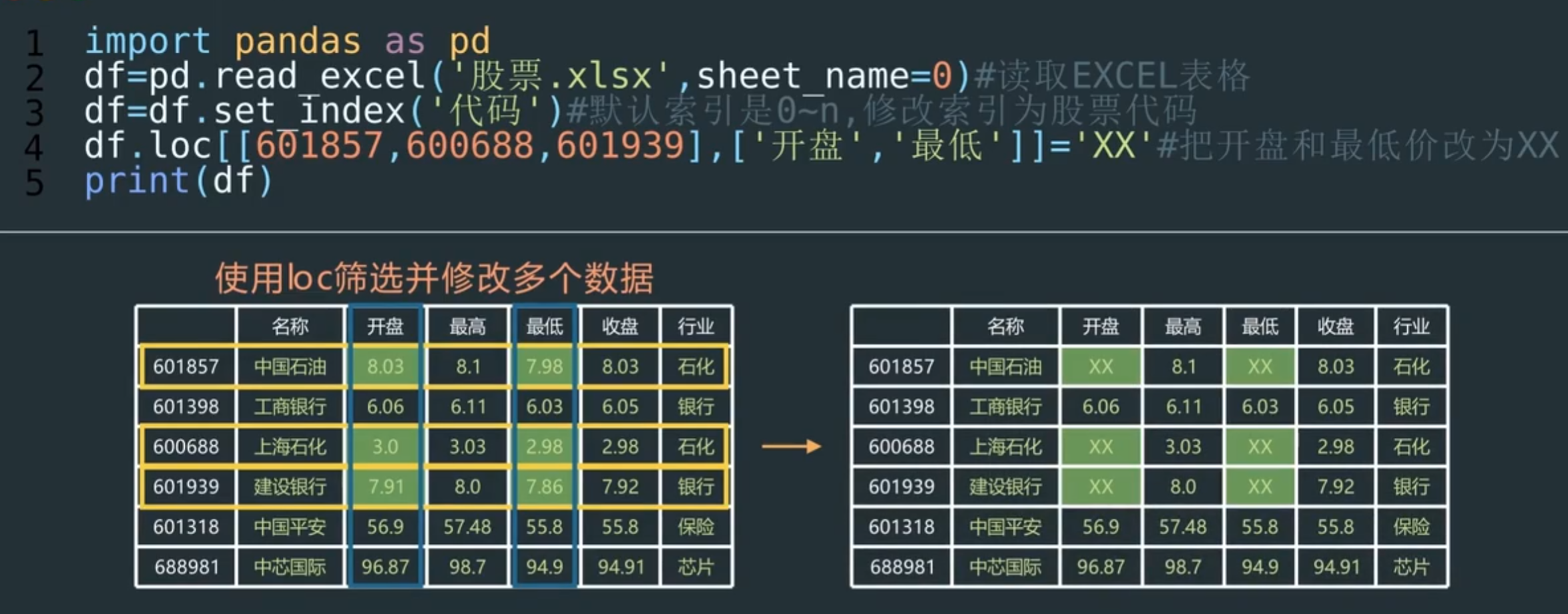
loc修改单个数据
df.loc[601857,'行业'] = '加油站'


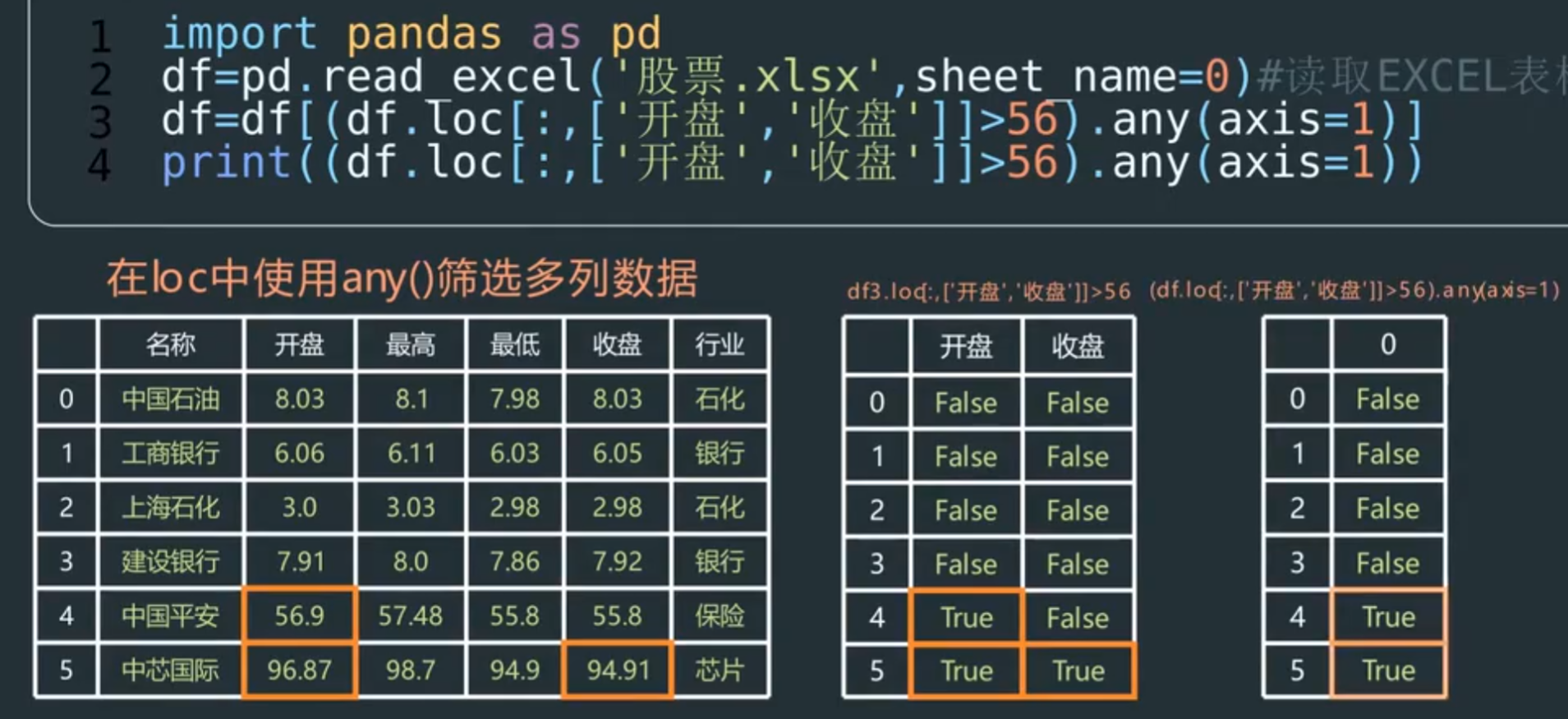
any函数
lambda表达式 和 iloc

# 筛选第0列值大于1的行
filtered_df = df[df.apply(lambda row: row.iloc[0] > 1, axis=1)]
import pandas as pd
df = pd.DataFrame({
'A': [1, 2, 3],
'B': [4, 5, 6],
'C': [7, 8, 9]
})
# 遍历每行每列
for i in range(len(df)): # 行索引
for j in range(len(df.columns)): # 列索引
value = df.iloc[i, j] # 用iloc定位
print(f"行[{i}], 列[{j}]: {value}")

pandas 文本操作

import pandas as pd
# 示例数据
data = {'Name': ['Alice', 'Bob', 'Charlie', 'David'],
'Email': ['alice@gmail.com', 'bob@yahoo.com', 'charlie@hotmail.com', 'david@gmail.com']}
df = pd.DataFrame(data)
# 筛选Email中包含"gmail"的行
gmail_users = df[df['Email'].str.contains('gmail')]
print(gmail_users)
import pandas as pd
# 示例数据
data = {'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eva123']}
df = pd.DataFrame(data)
# 检测Name是否以"A"开头
df['Starts_with_A'] = df['Name'].str.match('^A')
print(df)

is操作符
总结:Pandas is 函数速查表
| 函数 | 作用 | 常用场景 |
|---|---|---|
isna() / isnull() |
检测缺失值 | 数据清洗时过滤缺失值 |
notna() / notnull() |
检测非缺失值 | 筛选有效数据 |
isin() |
判断是否在列表中 | 分类筛选、数据匹配 |
is_monotonic_increasing |
检查是否单调递增 | 时间序列验证 |
str.isnumeric() |
检测字符串是否全为数字 | 数据格式校验 |
is_unique |
检查值是否唯一 | 主键/索引验证 |
is_sparse |
检测稀疏数据 | 内存优化场景 |
is_categorical() |
检测分类数据 | 分类变量处理 |

~ 取反操作符
df[~ df['op']== 'add']
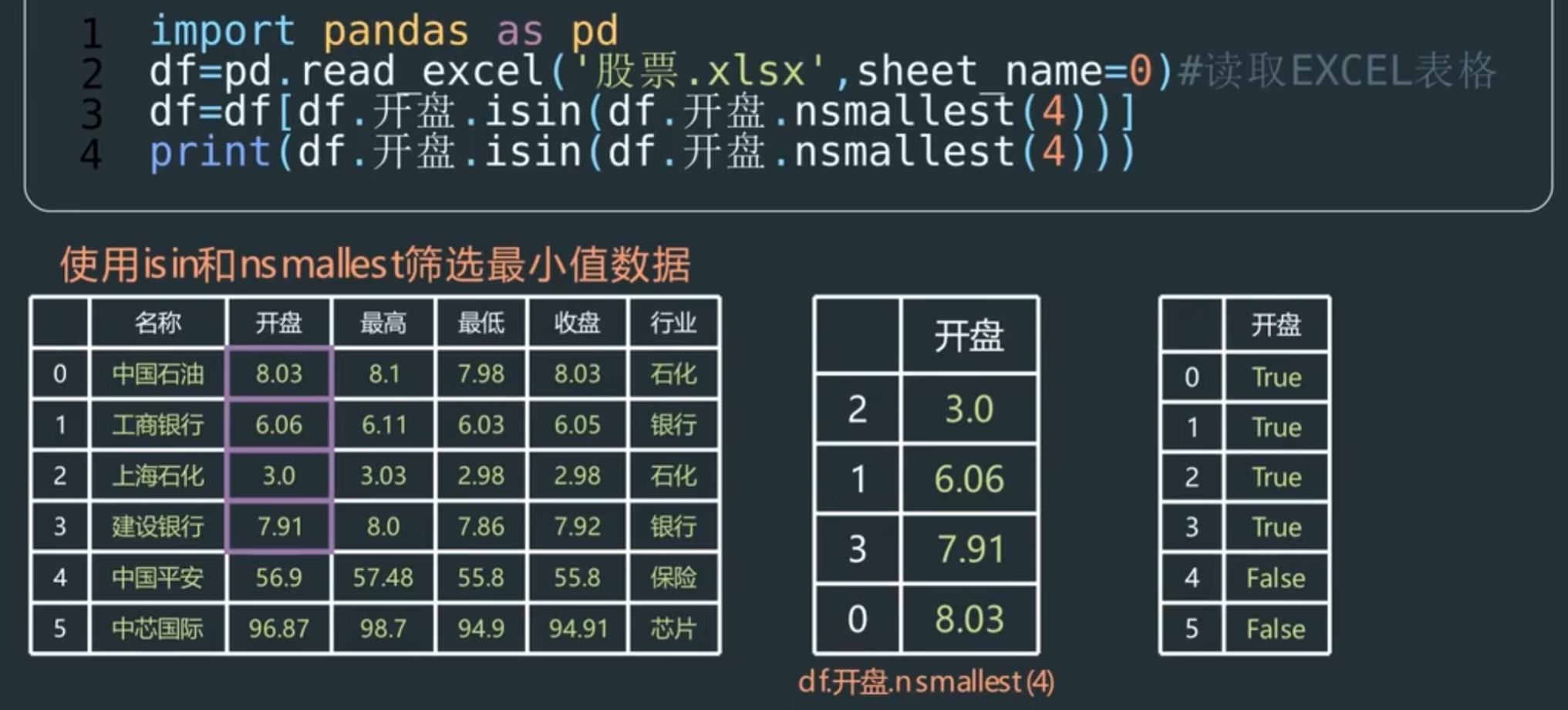
nsmallest 最小值
apply函数

query运算符
import pandas as pd
df = pd.DataFrame({
'A': [1, 2, 3, 4],
'B': ['x', 'y', 'z', 'x']
})
# 筛选A列大于2的行
result = df.query('A > 2')
print(result)
# 筛选B列为'x'或'y'的行
result = df.query("B in ['x', 'y']")
print(result)
query 方法支持链式操作
rolling 筛选

# 计算3日简单移动平均
df['SMA_3'] = df['Close'].rolling(window=3).mean()
print(df[['Close', 'SMA_3']])
# 标记超出3σ范围的异常点
df['Z-Score'] = (df['Close'] - df['Close'].rolling(30).mean()) / df['Close'].rolling(30).std()
df['Anomaly'] = df['Z-Score'].abs() > 3
sample随机抽取
# 从列中随机选择2列
sampled_cols = df.sample(n=2, axis=1, random_state=42)
print(sampled_cols)
isna 方法

统计 isna 的数量
df.isna().sum(axis=1)
df.notna().sum(axis=1)
常用于矩阵求和计算,以下用法分为三种情况来介绍!
格式:np.sum(a)
np.sum(a, axis=0) ------->列求和
np.sum(a, axis=1) ------->行求和
注意:特别注意后两种用法。

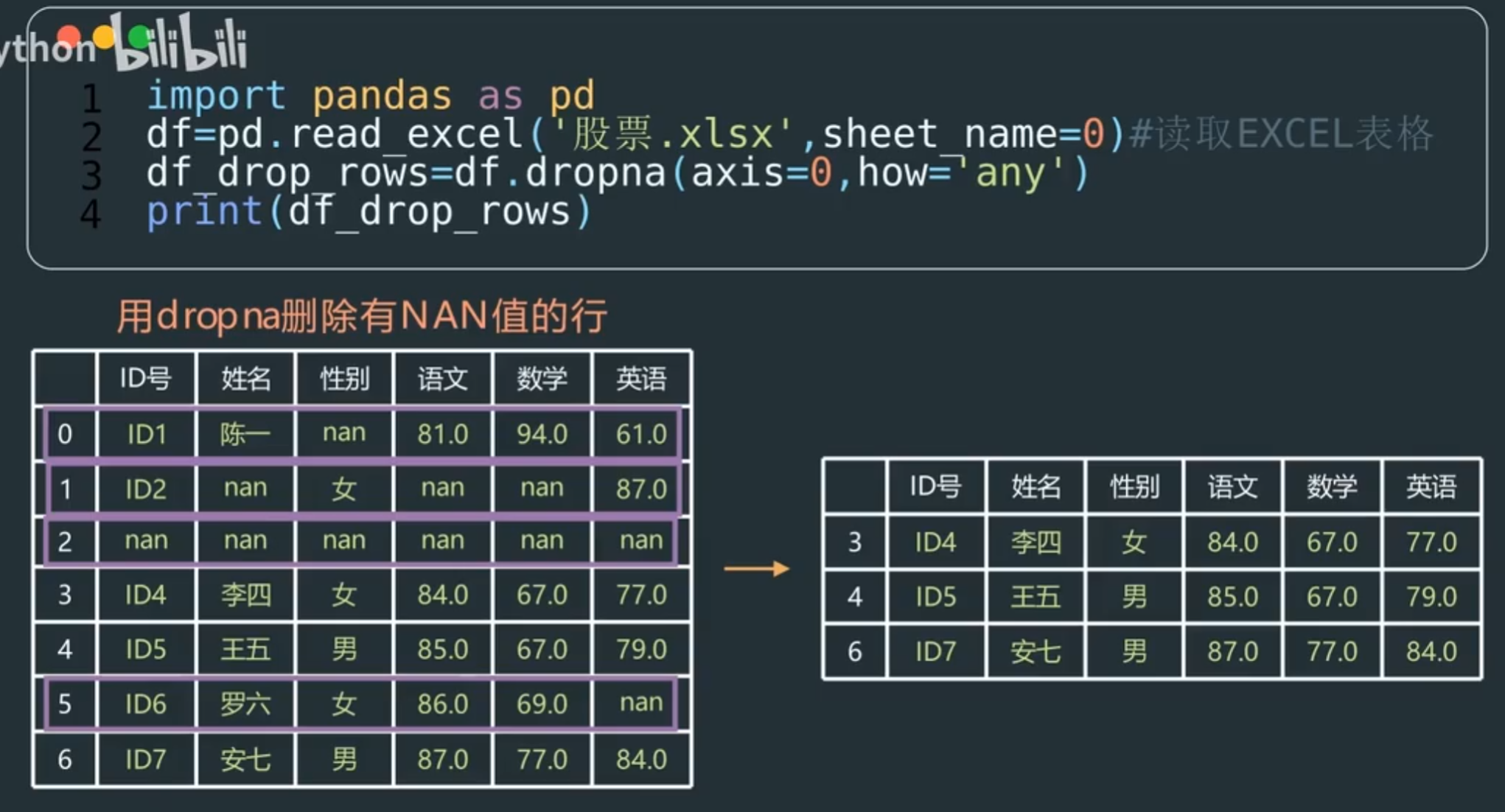
dropna/fillna/mask 方法
df.dropna(axis=0,how='any/all')

mask 可以按照条件填充
apply 及类型转化
# 转化为 str
df.id = df.id.apply(str)
df.id = df.id.astype(int)
1. 核心区别总结
| 特性 | astype() |
apply() |
|---|---|---|
| 主要用途 | 强制转换整个列的数据类型 | 对数据执行复杂的自定义转换 |
| 操作对象 | 整个列(向量化操作) | 可针对列、行或单个元素 |
| 性能 | 高效(底层C优化) | 较慢(Python循环) |
| 灵活性 | 仅支持预定义的类型转换 | 支持任意Python函数 |
| 适用场景 | 简单类型转换(如字符串→数值) | 需要条件判断、多列协作的复杂逻辑 |
where 方法 复杂条件修改
df1 = df.copy()
# 默认及格
df1['math_pass'] = '及格'
df1['math_pass'] = df1['math_pass'].where(df1['math'] > 60, '不及格')
cat 方法
>>>Series([‘a‘,‘b‘,‘c‘]).str.cat([‘A‘,‘B‘,‘C‘],sep=‘,‘)
merge 方法

df1 = pd.DataFrame({
'Dept': ['HR', 'IT', 'Finance'],
'EmpID': [101, 102, 103]
})
df2 = pd.DataFrame({
'Dept': ['IT', 'Finance', 'Marketing'],
'EmpID': [102, 103, 104],
'Salary': [7000, 8000, 9000]
})
# 按Dept和EmpID左连接
result = pd.merge(df1, df2, on=['Dept', 'EmpID'], how='left')
print(result)
clip 方法
import pandas as pd
data = {'value': [10, 25, 5, 30, 15]}
df = pd.DataFrame(data)
# 将'value'列的值限制在10和20之间
df['value'].clip(lower=10, upper=20, inplace=True)
print(df)
stack 方法 - 宽表转长表

df_single_level = pd.DataFrame(
[['Mostly cloudy', 10], ['Sunny', 12]],
index=['London', 'Oxford'],
columns=['Weather', 'Wind']
)
df_single_level.stack()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号