C语言博客作业--结构体
一、PTA实验作业
题目1:6-4 结构体数组按总分排序
1. 本题PTA提交列表

2. 设计思路(伪代码或流程图)
struct student
{
int num;
char name[15];
float score[3];
float sum;
};//该结构体表示学生的编号,名字,三门课程的成绩和总分
void calc(struct student *p,int n)
定义变量i表示循环次数及数组下标
for i=0 to n-1
(p+i)->sum=(p+i)->score[0]+(p+i)->score[1]+(p+i)->score[2];
end for
void sort(struct student *p,int n)
定义变量i代表循环次数,定义k代表循环次数和数组下标
定义结构体变量temp来作为两个结构体交换值的中间变量
for i=0 to n-1
for k=n-1 to i-1
如果后一个同学的总分((p+k)->sum)大于前一个同学的总分((p+k-1)->sum)
则交换两个同学的位置,即交换值
end for
.代码截图

4.本题调试过程碰到问题及PTA提交列表情况说明。
- 1.数据类型定义错误:习惯性把中间变量定义成整数型,然而实际上它是结构体类型,因为Dev-C的提示还算清楚:
![]()
![]()
所以很快就改正了 - 2.冒泡法排序错误:因为之前都是从小排到大,但是这次是从大到小,所以冒泡应该是从最后一个开始冒到第一个,思路是挺清晰的但是在写的时候还是出错了,得到了错误的答案
![]()
后来觉得有点混乱于是就重新写了一段冒泡法排序从大到小的代码:![]()
然后再对照发现是循环结束条件出错,改正后便得到了正确的答案![]()
- 3.信心满满去提交竟然是编译错误
![]()
但是devc都没有编译错误哎呦喂,再看一遍题目后发现这是函数补充题你干嘛要把所有代码复制过去是不是傻...然后只留下函数代码就得到正确的答案啦啦啦~




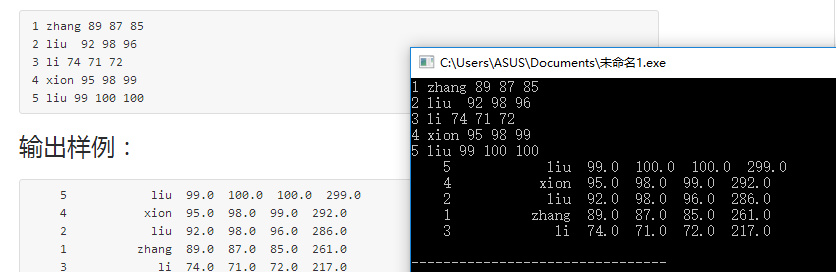

题目2:7-2 时间换算
1. 本题PTA提交列表

2. 设计思路
struct time{
int h;
int m;
int s;
};//该结构体表示小时,分钟和秒数
定义结构体变量begin表示开始的时间
定义整数型变量past存放过去的秒数
定义整数型变量flag1代表分钟增加量,并赋初值0
定义整数型变量flag2代表小时增加量,并赋初值0
按格式依次输入 小时:分钟:秒钟
输入past的值
if(一开始的秒数加上past大于等于60)
{
flag1=1
秒数 = 一开始的秒数+past-60
}
else{
秒数 = 一开始的秒数+past
}
if(一开始的分钟加上flag1等于60){
flag2=1;
分钟=0;
}
else{
分钟=一开始的分钟+flag1
}
if(一开始的小时数加上flag2等于24){
小时=0;
}
else{
小时=一开始的小时+flag2
}
按格式依次输出 小时:分钟:秒钟
3.代码截图


4.本题调试过程碰到问题及PTA提交列表情况说明。
- 答案错误:
![]()
- 错误分析:只考虑了特殊的情况(即m=59进1和h=23进1的情况)忘记考虑一般情况下m和h的改变(即图中注释的代码)
- 加上一般情况m和h的改变就正确啦~~哦对了这题我后面对输出格式的讨论导致代码超级长,本来有考虑去用字符数组来存放h m s,虽然这样就不存在h m s小于10时没法输出两位数的情况,但是不好做计算阿...嗯我会去学习这题别人更加简便的做法期待
- 补充:我懂啦~~~我这种去处理格式问题简直是太太太麻烦了,直接利用%02d就好啦~
%02d:2代表宽度, 0代表如果整数不够2列就补上0
eg:printf("%02d" ,3)-> 03

题目3:7-6 通讯录的录入与显示
1. 本题PTA提交列表
2. 设计思路
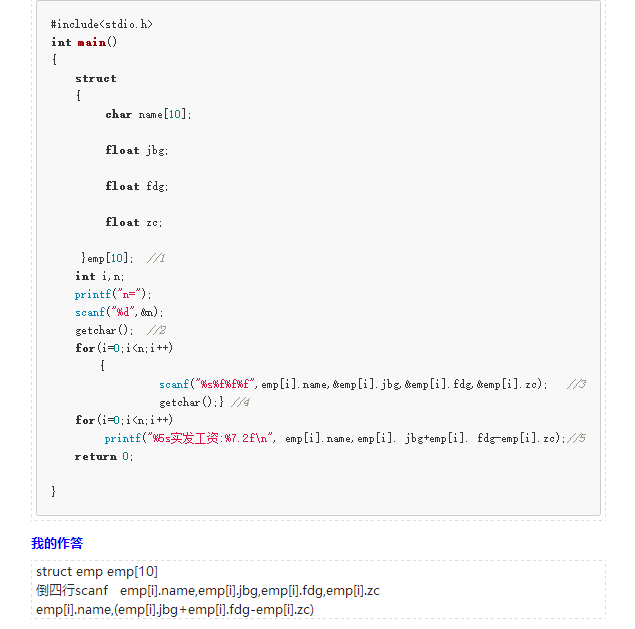
struct information{
char name[11];
char birth[12];
char sex;
char fix[18];
char mobile[18];
};//该结构体表示通讯录信息中的名字,出生日期,性别,固定电话和移动电话号码
定义变量i表示循环次数和数组下标
定义变量k表示录入k条记录
定义变量search代表要查询的个数,定义变量x代表要查询信息的编号
输入k的值
定义结构体数组变量a[k]
for i=0 to k-1
依次输入名字,出生日期,性别,固定电话和移动电话号码存在a[i]中
输入search的值
for i=0 to search-1
输入x的值
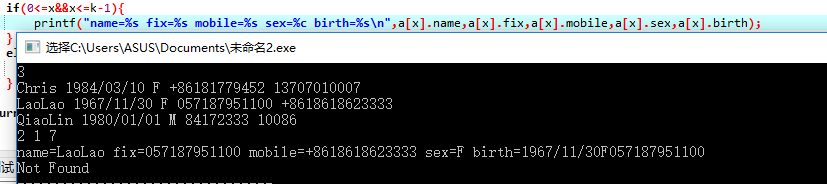
if(0<=x<=k-1){
依次输出a[x]中的名字,固定电话,移动电话,性别和出生日期
}
else{
输出Not Found
}
end for
3.代码截图
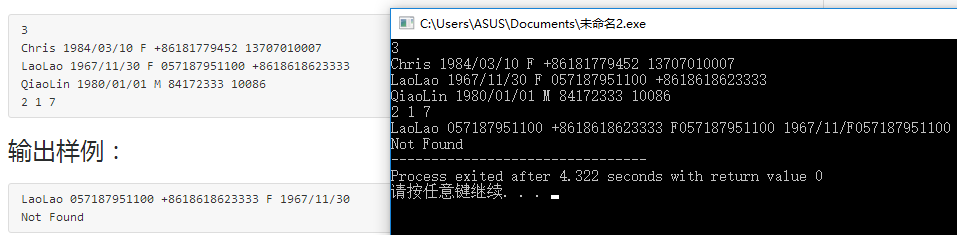
4.本题调试过程碰到问题及PTA提交列表情况说明。
- 答案错误:
![]()
发现性别和生日莫名多了一串数字 - 解决方法:抖机灵把存放性别的数组改成字符变量,然后把%s->%c 嗯然后就得到了性别输出是正确的啦
![]()
- 但是生日的问题还没有解决阿...一番思考后问了同学后得知我存放生日的数组太小了,因为我刚刚好数了十个字符然后大小就给了10...于是这个数组就没地方放结束符'\0'啊... 又错在这个地方!!牢记(加红):记得字符数组的大小要比有效字符数量多1来存放结束符'\0'阿!!!
- 格式错误
- Not Found后也应该加上'\n'
- 部分正确
![]()
- 同样的字符数组的大小问题,应该把name的数组的大小也应该改成10+1=11

二、截图本周题目集的PTA最后排名。

三、阅读代码
优秀代码一:
#include <stdio.h>
#define N 10
void sort(int *a, int n);
int main()
{
int a[N] = {1,2,3,4,5,6,7,8,9,10};
int i, j;
sort(a, N);
for(i = 0; i < N; i++)
{
printf("%d ", a[i]);
}
puts("");
return 0;
}
void sort(int *a, int n)
{
int i,len;
len=n-1;
for(i=0;i<len;)
{
if((a[i]%2)==0) //判断是否为偶数
{
a[len] ^= a[i];
a[i] ^= a[len];
a[len] ^= a[i];
len--;
}
else
i++;
}
return;
}
- 代码实现的功能是:将数组s[N]中所有奇数移到所有偶数之前
- 代码优点:
- 1.不另增加存储空间,而且其中涉及到异或的一大重要的利用,即可实现两个数交换而并不需要再定义一个中间变量,可以一定程度上节省了内存空间(异或功能补充~)
- 2.思路很巧妙,从第一个数开始判断是否为奇数,若是,则按顺序判断第二个数,若不是,则将其与第len-1个数交换,交换后再次判断该数是否为偶数(而不是跳到下一个数因为你交换的数不一定是偶数阿,但是优点是你把偶数换到后面去了,无论换过来是否为奇数,但是我们知道第len-1个数是偶数,待会儿我们都可以大方跳到len-1-1个数去判断是否为奇数然后来跟前面的偶数进行交换)
- 3.整个代码的思路很清晰代码也很简洁,就利用了一个循环和一个if–else就实现了奇数排在偶数前面的功能~这种思路是我没想到的也是我觉得很优秀而且值得我学习的.
优秀代码二:
# include<stdio.h>
#define N 6
typedef struct student {
int num;
char name[20];
int score[3];
}Student,*pStudent;
void sort(pStudent pStu[],int n,int col) {
//bubble sort
int i,j;
pStudent temp;
for (i = 0; i < n - 1; i++) {
for (j = 0; j < n - 1 - i; j++) {
if (pStu[j]->score[col] > pStu[j + 1]->score[col]) {
//只交换指针,不交换原始数据
temp = pStu[j];
pStu[j] = pStu[j + 1];
pStu[j + 1] = temp;
}
}
}
}
int main()
{
Student students[N] = {
{1001,"张三",78,89,92},
{1002,"李四",67,98,87},
{1003,"王二",87,77,92},
{1004,"芳芳",56,87,88},
{1005,"珍珍",98,78,89},
{1006,"小虎",67,58,88}
};
pStudent pStu[N];
int i,col,pause;
for (i = 0; i < N; i++) {
pStu[i] = students+i;
}
//输出原始数据
printf("原始数据\n学号\t姓名\t语文\t数学\t英语\n");
for (i = 0; i < N; i++) {
printf("%d\t%s\t%d\t%d\t%d\t\n", pStu[i]->num, pStu[i]->name, pStu[i]->score[0], pStu[i]->score[1], pStu[i]->score[2]);
}
printf("-----------------------------------------\n");
printf("按某课成绩排序:1) 语文 2)数学 3)英语, 请输入1,2,3,输入0退出\n");
scanf("%d", &col);
while (col != 0) {
sort(pStu, N, col - 1);
printf("原始数据\n学号\t姓名\t语文\t数学\t英语\n");
for (i = 0; i < N; i++) {
printf("%d\t%s\t%d\t%d\t%d\t\n", pStu[i]->num, pStu[i]->name, pStu[i]->score[0], pStu[i]->score[1], pStu[i]->score[2]);
}
scanf("%d", &col);
}
return 0;
}
- 代码实现的功能: 根据用户的选择来进行某门课程成绩按从小到大排序,并按该门课成绩的排序输出对应同学全部信息
- 代码优点:
- 1.这段代码的排序用的是冒泡排序,交换的是指针,而不是原始数据。这样做的原因是交换原始数据耗费太大,而用一个指针数组排序既不更改原始数据又在时间空间上的消耗很小,这是个相当不错的想法也对我们完善自己的代码有很大的借鉴意义……
- 2.这段代码的用户界面设计得非常好,用户使用起来可以说是相当愉快的,这是我们目前写代码需要加强的地方,不应该只注重代码功能的实现,更应该要注重用户体验……
四、本周学习总结
1.总结本周学习内容。
结构体:
-
概念:结构体时一种构造数据类型
-
用途:把不同类型的数据(如:变量、指针或数组等)组合成一个整体
-
内存:各成员所占内存空间的累加
-
关键词:struct
结构体的声明与定义变量的方法一共有三种:
- 方法1:定义结构体类型的同时定义变量
struct Person
{
int age; // 年龄
double height; // 身高
char *name; // 姓名
} p;
- 方法2:先定义结构体类型,再定义变量
struct Person
{
int age; // 年龄
double height; // 身高
char *name; // 姓名
};
struct Person p;
- 方法3:直接定义结构体变量,忽略类型名
struct
{
int age; // 年龄
double height; // 身高
char *name; // 姓名
} p;
注意:不能在结构体内部直接给成员赋值
共用体:
-
定义:构造数据类型,也叫联合体。
-
用途: 使几个不同类型的数据共占一段内存(相互覆盖)
-
关键词:union
-
基本格式
union 共用体名
{
成员表列
}变量表列;`
- 特点:
1.共用体变量任何时候只有一个变量存在。
2.共用体变量定义分配内存,长度=最长成员所在字节数
3.定义共用体变量的方式和结构体一样有三种:常规,尾部,无名。
4.当给一个成员重复赋值时或对多个成员赋值时,只承认最后一次的赋值。
结构体和共用体的区别在于:
- 结构体的各个成员会占用不同的内存,互相之间没有影响
- 共用体的所有成员占用同一段内存,修改一个成员会影响其余所有成员。
- 结构体占用的内存大于等于所有成员占用的内存的总和(成员之间可能会存在缝隙)
- 共用体占用的内存等于最长的成员占用的内存。共用体使用了内存覆盖技术,同一时刻只能保存一个成员的值,如果对新的成员赋值,就会把原来成员的值覆盖掉。
枚举体
- 关键词:enum
- 用途:列举所有选项
- 举例:day = {Sunday,Monday,Tuesday,Wednesday,Thusday,Friday,Saturday};
- 注意:
1.结尾有分号
2.如果个枚举常量没有赋值,则默认值为其下标(参考一维数组),比如此时Tuesday = 2
3.枚举定义的量属于全局常量,在其他地方不能再有与之重名的量。
typedef:
- 功能:用自定义名字为已有数据类型命名(有点伪装的意思)
- 范围:只能针对已有数据类型使用。比如:int ,char, double,…..而define什么都可以换。
- 语法格式:
typedef oldName newName;
oldName 是类型原来的名字,newName 是类型新的名字。
例如:
typedef int INTEGER;
INTEGER a, b;
a = 1;
b = 2;
INTEGER a, b;等效于int a, b;
递归函数
- 定义:递归(recursion)就是子程序(或函数)直接调用自己或通过一系列调用语句间接调用自己,是一种描述问题和解决问题的基本方法。
- 用途:递归通常用来解决结构自相似的问题。所谓结构自相似,是指构成原问题的子问题与原问题在结构上相似,可以用类似的方法解决。具体地,整个问题的解决,可以分为两部分:第一部分是一些特殊情况,有直接的解法;第二部分与原问题相似,但比原问题的规模小。实际上,递归是把一个不能或不好解决的大问题转化为一个或几个小问题,再把这些小问题进一步分解成更小的问题,直至每个小问题都可以直接解决。
- 递归有两个基本要素:
(1)边界条件:确定递归到何时终止,也称为递归出口。
(2)递归模式:大问题是如何分解为小问题的,也称为递归体。 - 在递归函数中,调用函数和被调用函数是同一个函数,需要注意的是递归函数的调用层次,如果把调用递归函数的主函数称为第0层,进入函数后,首次递归调用自身称为第1层调用;从第i层递归调用自身称为第i+1层。反之,退出第i+1层调用应该返回第i层。
- 递归函数的内部执行过程
一个递归函数的调用过程类似于多个函数的嵌套的调用,只不过调用函数和被调用函数是同一个函数。为了保证递归函数的正确执行,系统需设立一个工作栈。具体地说,递归调用的内部执行过程如下:
(1)运动开始时,首先为递归调用建立一个工作栈,其结构包括值参、局部变量和返回地址;
(2)每次执行递归调用之前,把递归函数的值参和局部变量的当前值以及调用后的返回地址压栈;
(3)每次递归调用结束后,将栈顶元素出栈,使相应的值参和局部变量恢复为调用前的值,然后转向返回地址指定的位置继续执行。
以阶乘为例说明递归的工作原理:
long ff(int n) { long f; if(n<0)
printf("n<0,input error"); else if(n==0||n==1)
f=1; //为什么f=1,就不再继续递归调用?
else
f=ff(n-1)*n;//这一步到底是怎么工作的? return(f); }
求3!=?
一层执行到[f=ff(3-1)3];停止,执行二层ff(3-1),也就是ff(2)
二层执行到[f=ff(2-1)2];停止,执行三层ff(2-1),也就是f(1)
三层执行到else if(n0||n1) f=1;然后return(f)到二层的ff(2-1)的位置,二层继续执行
二层执行[f=12]然后就return(f)到一层ff(3-1)的位置,一层继续执行
一层执行[f=23]; 然后就return(f)到了最初调用ff(3)的main函数里,所以就得到y=6
大体过程就是这样的
这里每次一层都相当于一个不同的函数,你可以给他们起名为ff1,ff2,ff3.....这样就不混了。只要注意一点,调用一次,不是在代码本身上执行,而是会复制出一份在执行,虽然不太恰当,但足以说明问题。
再补充一个我觉得可以帮助我们深入理解递归函数的调用过程的例子:
/*递归例子*/
#include<stdio.h>
void up_and_down(int);
int main(void)
{
up_and_down(1);
return 0;
}
void up_and_down(int n)
{
printf("Level %d:n location %p/n",n,&n); /* 1 */
if(n<4)
up_and_down(n+1);
printf("Level %d:n location %p/n",n,&n); /* 2 */
}
输出结果
Level 1:n location 0240FF48
Level 2:n location 0240FF28
Level 3:n location 0240FF08
Level 4:n location 0240FEE8
Level 4:n location 0240FEE8
Level 3:n location 0240FF08
Level 2:n location 0240FF28
Level 1:n location 0240FF48
- 首先, main() 使用参数 1 调用了函数 up_and_down() ,于是 up_and_down() 中形式参数 n 的值是 1, 故打印语句 /1/ 输出了 Level1 。然后,由于 n 的数值小于 4 ,所以 up_and_down() (第 1 级)使用参数 n+1 即数值 2 调用了 up_and_down()( 第 2 级 ). 使得 n 在第 2级调用中被赋值 2, 打印语句/2/输出的是 Level2 。与之类似,下面的两次调用分别打印出 Level3 和 Level4 。
- 当开始执行第 4 级调用时, n 的值是 4 ,因此 if 语句的条件不满足。这时候不再继续调用 up_and_down() 函数。第 4 级调用接着执行打印语句/2/ ,即输出 Level4 ,因为 n 的值是 4 。现在函数需要执行 return 语句,此时第 4 级调用结束,把控制权返回给该函数的调用函数,也就是第 3 级调用函数。第 3 级调用函数中前一个执行过的语句是在 if 语句中进行第 4 级调用。因此,它继续执行其后继代码,即执行打印语句 /2/,这将会输出 Level3 .当第 3 级调用结束后,第 2 级调用函数开始继续执行,即输出Level2 .依次类推.
- 注意,每一级的递归都使用它自己的私有的变量 n .可以查看地址的值来证明.
- 递归的基本原理:
1 每一次函数调用都会有一次返回.当程序流执行到某一级递归的结尾处时,它会转移到前一级递归继续执行.
2 递归函数中,位于递归调用前的语句和各级被调函数具有相同的顺序.如打印语句 #1 位于递归调用语句前,它按照递归调用的顺序被执行了 4 次.
3 每一级的函数调用都有自己的私有变量.
4 递归函数中,位于递归调用语句后的语句的执行顺序和各个被调用函数的顺序相反.
5 虽然每一级递归有自己的变量,但是函数代码并不会得到复制.
6 递归函数中必须包含可以终止递归调用的语句.
2.罗列本周一些错题。

- 错误分析:
1.对数组名代表地址的认识不够深刻,故scanf后直接数组名即可不用再加地址符&,但是一般其他非数组的变量就必须要加上&
2.没有注意到字符数组的输入之前scanf的输入,scanf输入后会有回车,如果没有用getchar()来吃掉这个回车的话,下一个字符数组的输入就会把回车一起存到数组里去,这个是很容易出错和很容易没办法注意到的地方

- 知识点:地址实参可以传给数组来存放或者是传给某数组的地址(即数组名),也可以传给指针形参,但是不可以给整数型形参
![]()
- 解析:
A:说法正确
B:说法本身就是矛盾,单个函数访问,就不关全局变量事情。全局变量就是让多个函数可以访问。
C:静态变量不用考虑生命周期问题
D:静态变量跟动态存储区并没有关系,不存在会溢出的问题


 浙公网安备 33010602011771号
浙公网安备 33010602011771号