BERT
-
什么是BERT
BERT的全称是Bidirectional Encoder Representation from Transformers,是Google2018年提出的预训练模型,其结构采用Transformer的Encoder部分,主要创新点都在pre-train方法上,即用了Masked LM和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。
BERT虽然从结构上看创新性并不高,但其效果非常好,基本刷新了很多NLP的任务的最好性能,有些任务还被刷爆了,这个才是关键。另外一点是Bert具备广泛的通用性,就是说绝大部分NLP任务都可以采用类似的两阶段模式直接去提升效果。这些将NLP也带入了类似CV领域的预训练+微调时代,BERT也成为了如今最热门的NLP模型。
-
从Word Embedding到Bert
-
预训练
预训练(pre-train)是CV领域十分常用的方法,当设计好网络结构以后,可以先在其他数据集如ImageNet上进行训练保存模型参数。运用到具体任务时,可以选择固定住浅层模型参数,而只训练顶层参数(Frozen);也可以所有岑参数一起训练(Fine-tune)。
这样做的优点是:如果当前任务的训练集合数据量较少的话,利用预训练出来的参数来训练当前任务可以极大加快任务训练的收敛速度,并且可以提高模型效果。
预训练之所以在CV领域可行是因为对于CV领域常用的层级的CNN结构来说,不同层级的神经元学习到了不同类型的图像特征,由底向上特征形成层级结构,所以预训练好的网络参数,尤其是底层的网络参数抽取出特征跟具体任务越无关,越具备任务的通用性,所以这是为何一般用底层预训练好的参数初始化新任务网络参数的原因。而高层特征跟任务关联较大,实际可以不用使用,或者采用Fine-tuning用新数据集合清洗掉高层无关的特征抽取器。
-
Word Embedding
之前章节介绍的Word Embedding实际上也可以归为预训练的范畴,先使用特定任务在大规模语料上进行训练,然后将训练的中间产物即词向量矩阵保存下来供下游任务使用。
Word Embedding最明显的问题就是其无法解决多义词问题,比如多义词play,其上下文可以是运动相关的,也可以是游戏相关的,但是Word Embedding在对play这个单词进行编码的时候,是区分不开这两个含义的,因为它们尽管上下文环境中出现的单词不同,但是在用语言模型训练的时候,不论什么上下文的句子经过Word Embedding,都是预测相同的单词bank,而同一个单词占的是同一行的参数空间,这导致两种不同的上下文信息都会编码到相同的Word Embedding空间里去。
称Word Embedding这种一旦训练好了之后不管输入的是哪种上下文,其词向量都不会改变的Embedding方法为静态Embedding。
-
ELMO
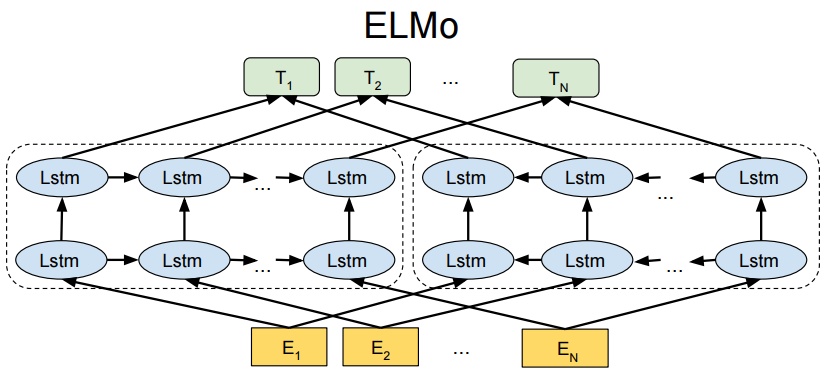
ELMO(Embedding from Language Models)的出发点就是要解决Word Embedding的多义词问题,其出发点是根据上下文对Embedding做出动态调整。其结构如下:
![yPK5ut.jpg]()
ELMO的网络结构采用了双层双向LSTM,采用了典型的两阶段过程,第一个阶段是利用语言模型进行预训练;第二个阶段是在做下游任务时,从预训练网络中提取对应单词的网络各层的Word Embedding作为新特征补充到下游任务中。
预训练阶段,使用单词的上下文来预测当前位置的单词,其损失函数为:
\[J=\sum_{sentence}\sum_{w_t \in sentence}\log P(w_t|w_1,...,w_{t-1})+\log P(w_t|w_{t+1},...,w_T) \]其中sentence为语料库中的句子,\(w_t\)为其第t个单词,T为句子长度。ELMO的损失函数是前向语言模型和后向语言模型的和,两个方向是分开的。
将ELMO应用到具体的下游任务时,将句子输入ELMO,将嵌入层、第一层LSTM、第二层LSTM的向量加权求和(权重可学习)即可得到应用于下游任务的Embedding。因为ELMO在预训练之后参数是固定的,只负责给下游任务提供相应特征,所以这种预训练模式成为Feature-based Pre-Training。
由于ELMO在Embedding的时候考虑了上下文,所以对解决多义词问题起到了一定作用,但ELMO也存在以下缺点:
- 使用双向LSTM作为特征抽取器,无法并行且特征抽取能力不强;
- 训练的时候前后向语言模型是分开的,只在给下游任务提供Embedding时进行融合,这种方法可能存在问题。
-
GPT
GPT(Generative Pre-Training)是由Open AI提出的生成式预训练语言模型,其采用了Transformer的Decoder作为网络结构,这更适合NLG任务,但对于NLU任务由于其丢掉了下文信息,因此效果会打折扣。
-
BERT
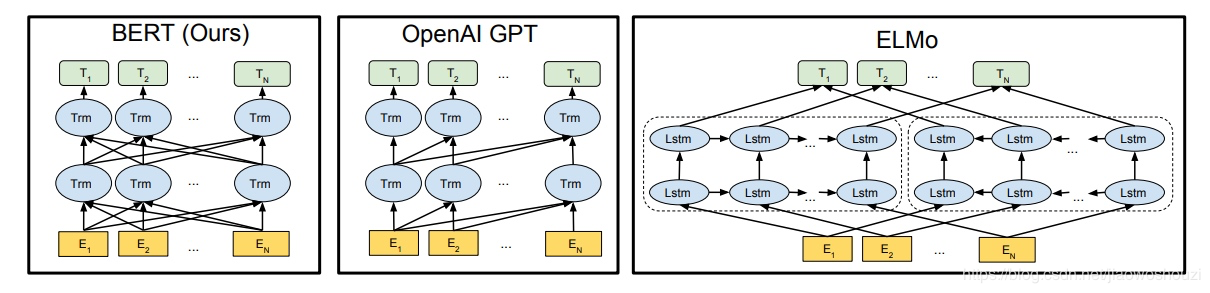
BERT(Bidirectional Encoder Representation from Transformers)与GPT最大的不同就是其采用的是Transformer的Encoder部分,能够同时使用上下文信息。其与GPT、ELMO的对比图如下:
![yPgjzQ.png]()
BERT的一大创新点就是其采用了Masked LM和Next Sentence Prediction两种预训练任务,将在第三小节具体介绍。
-
-
BERT的具体内容
-
Embedding
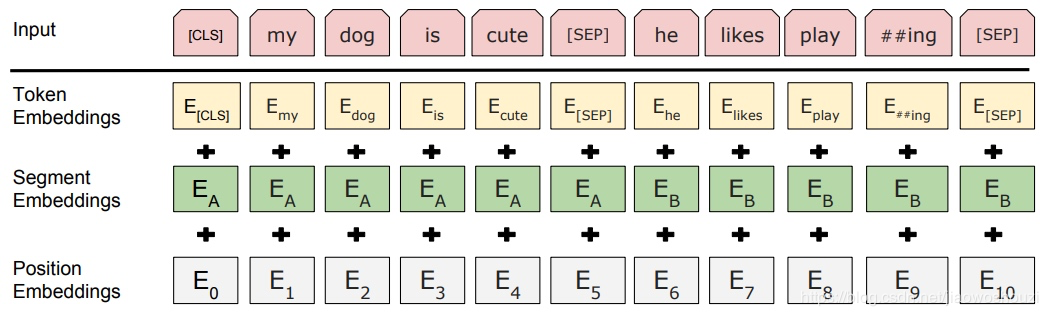
BERT的Embedding由三种Embedding求和而成:
![yPRg3D.png]()
- Token Embeddings是词向量,第一个单词是CLS标志,可以用于之后的分类任务;
- Segment Embeddings用来区别两种句子,因为预训练不光做LM还要做以两个句子为输入的分类任务;
- Position Embeddings和之前文章中的Transformer不一样,不是固定的三角函数而是由网络自己学习出来的。
同时BERT的分词方法也与传统的方法有所区别,采用的是WordPiece分词方法,具体可以参考:https://zhuanlan.zhihu.com/p/198964217。
-
Masked LM
MLM可以理解为完形填空,作者会随机mask每一个句子中15%的词,用其上下文来做预测,例如:my dog is hairy → my dog is [MASK]
此处将hairy进行了mask处理,然后采用非监督学习的方法预测mask位置的词是什么,但是该方法有一个问题,因为是mask15%的词,其数量已经很高了,这样就会导致某些词在fine-tuning阶段从未见过,为了解决这个问题,作者做了如下的处理:
-
80%是采用[mask],my dog is hairy → my dog is [MASK]
-
10%是随机取一个词来代替mask的词,my dog is hairy -> my dog is apple
-
10%保持不变,my dog is hairy -> my dog is hairy
注意:这里的10%是15%需要mask中的10%
关于为什么使用[MASK]标记而不是直接留空,即在Self-Attention时不与该处词交互,个人认为是这样做会导致在训练时要将该位置的词像[PAD]符号那样MASK掉,使得输入的Attention mask序列中间有空缺,而测试的时候没有,这样带来的前后不一致可能比引入[MASK]符号带来的前后不一致要大。
BERT的这一做法成为DAE(Denoise Auto Encoder),即去噪自编码。
-
-
Next Sentence Prediction
选择一些句子对A与B,其中50%的数据B是A的下一条句子,剩余50%的数据B是语料库中随机选择的,学习其中的相关性,添加这样的预训练的目的是目前很多NLP的任务比如QA和NLI都需要理解两个句子之间的关系,从而能让预训练的模型更好的适应这样的任务。
-
-
BERT的优缺点
BERT优点
- Transformer Encoder因为有Self-attention机制,因此BERT自带双向功能,特征抽取能力和并行能力强。
- 为了获取比词更高级别的句子级别的语义表征,BERT加入了Next Sentence Prediction来和Masked-LM一起做联合训练。
- 为了适配多任务下的迁移学习,BERT设计了更通用的输入层和输出层,为下游任务引入了很通用的求解框架,不再为任务做模型定制。
BERT缺点
- Bert用于下游任务微调时, [MASK] 标记不会出现,它只出现在预训练任务中。这就造成了预训练和微调之间的不匹配,微调不出现[MASK]这个标记,模型好像就没有了着力点、不知从哪入手。所以只将80%的替换为[mask],但这也只是缓解、不能解决。
- [MASK]标记在实际预测中不会出现,训练时用过多[MASK]影响模型表现。每个batch只有15%的token被预测,所以BERT收敛得比left-to-right模型要慢(它们会预测每个token)。
- BERT对硬件资源的消耗巨大(大模型需要16个tpu,历时四天;更大的模型需要64个tpu,历时四天。
-
基于BERT的其他预训练模型
-
XLNet
XLNet主要是为了解决上述BERT缺点的第一条,使用自回归代替自编码。自回归即使用前向语言模型或者后向语言模型来预测当前位置的词,但其有单向的缺点;自编码即BERT所使用的Masked LM的训练方式,其能使用到双向信息但是会造成预训练与微调时的不一致。
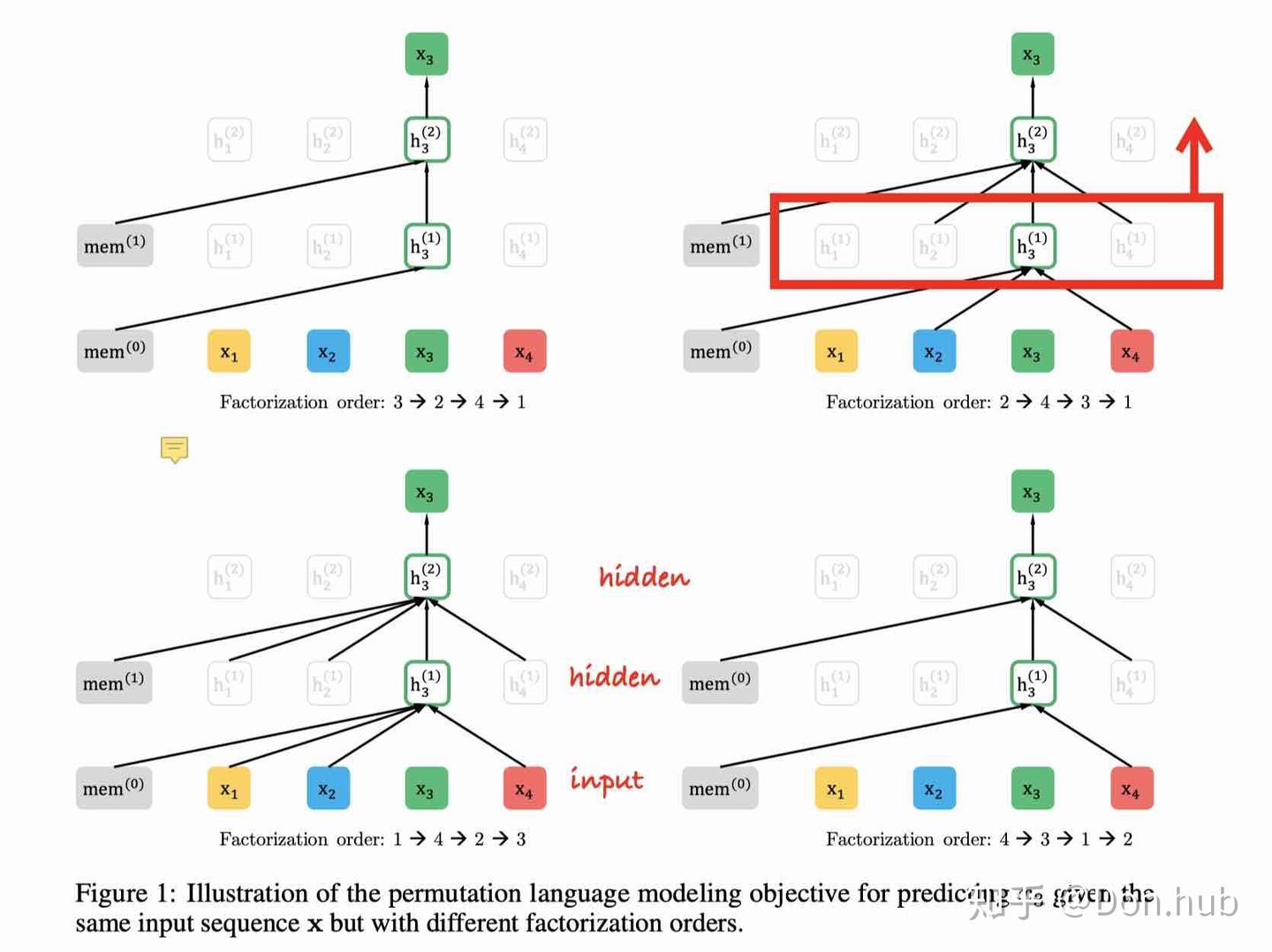
XLNet使用排列的方式来解决这一问题,例如对于序列[1,2,3,4],其全排列有4!种,XLNet希望最大化每种排列下每个词由前向或者后向语言模型所预测的概率:
\[E_{z\sim Z_T}[\sum_{t=1}^T\log P(x_{z_t}|x_{z<t})] \]其中\(z\sim Z_T\)为一个序列的全排列集合,z为其中一种,T为序列长度,\(x_{z_t}\)为当前排列的第t个词,\(x_{z<t}\)为第t个词前面的词(或者后面的词)。
下图展示不同排列时数字3所能使用的前向信息:
![yipfMQ.jpg]()
但由于全排列数太多,所以XLNet采用了抽样全排列,且对于一种排列只预测序列中的后几个单词(前面的单词信息太少)。同时,每个Batch中一半序列做前向预测,一半序列做后向预测。
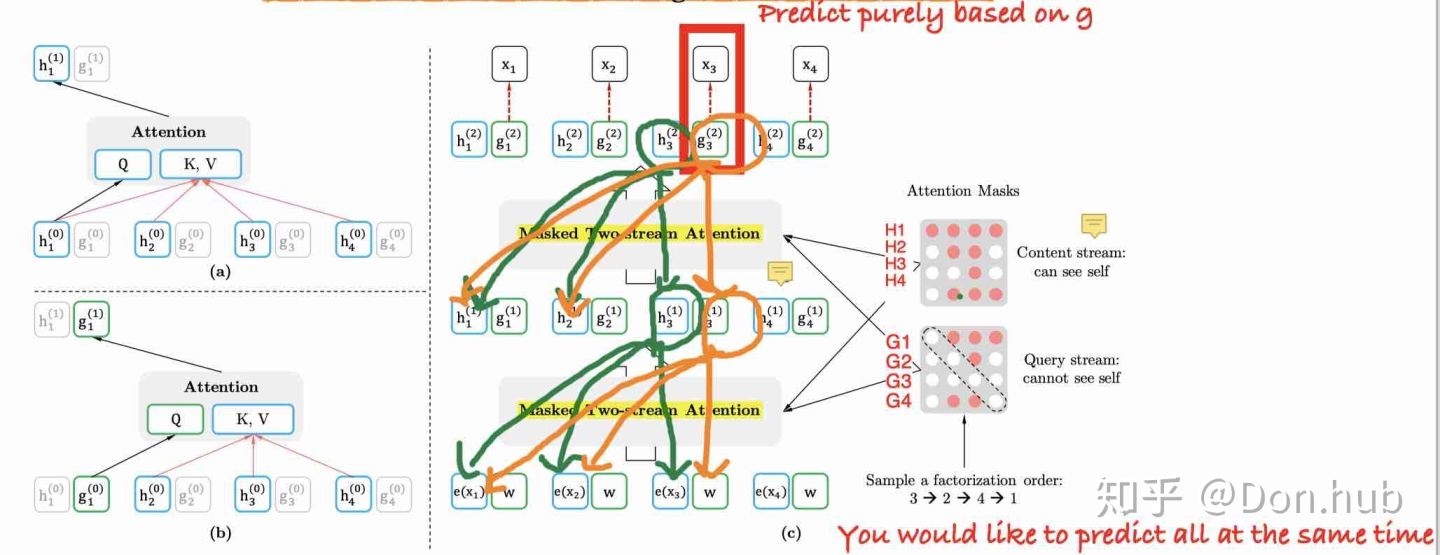
同时XLNet对Transformer的结构做了改动,使用了两路输入context stream和query stream,其中:
- context stream 就和普通的self-attention一样编码的是内容信息,但是是基于lookahead的mask 策略,即只能看到自己以及之前位置的内容信息。
- query stream 编码的是位置信息,可以看到自己的位置信息,还有之前的内容信息但是不能看到自己的内容信息。
下图很好的展示了这一过程:
![yiCs9f.jpg]()
其中绿色部分为context stream,橙色部分为query stream。可以看到,XLNet是通过修改Attention mask来实现并行预测的。
同时,XLNet去掉了下一句预测(NSP)任务。
-
RoBERTa
- 去掉下一句预测(NSP)任务。
- 动态掩码。BERT 依赖随机掩码和预测 token。原版的 BERT 实现在数据预处理期间执行一次掩码,得到一个静态掩码。 而 RoBERTa 使用了动态掩码:每次向模型输入一个序列时都会生成新的掩码模式。这样,在大量数据不断输入的过程中,模型会逐渐适应不同的掩码策略,学习不同的语言表征。
- 文本编码。使用Byte-Pair Encoding(BPE)代替Wordpiece。
-
ALBERT
-
Factorized Embedding Parameterization
对于 Bert,词向量维度 E 和隐层维度 H 是相等的。这样既会增大参数量,也会增加embedding table与transformer的耦合性。因此,作者在词表V与第一个隐层H之间增加了一个维度E,这样参数量由\(V*H\)减少为了\(V*E+E*H\),同时也对embedding table和transformer进行了解耦。
-
Cross-layer Parameter Sharing
ALBERT通过共享所有层间的参数来降低参数量,具体分为三种模式:只共享 attention 相关参数、只共享 FFN 相关参数、共享所有参数。
-
Sentence Order Prediction(SOP)
RoBERTa、XLNet等研究都证明了去除NSP的预训练语言模型反而使得下游任务效果更好,这可能是由于NSP任务相比于Masked LM过于简单。ALBert使用SOP任务代替NSP任务,由预测两个句子是否相关改为预测两个句子顺序是否正确,实验证明这样做确实会带来性能的提升。
-
-
BERT-wwm
wwm 即 Whole Word Masking(对全词进行Mask),对中文来说是对词语进行Mask而不是字,对英文来说是对词MASK而不是子词。
-
TinyBERT
TinyBERT 是华为提出的一种蒸馏 BERT 的方法,模型大小不到 BERT 的 1/7,但速度能提高 9 倍。其对BERT的Embedding、Hidden state、Attention以及最终输出分别进行蒸馏学习,具体可以参考:https://www.cnblogs.com/tfknight/p/13343346.html。
-
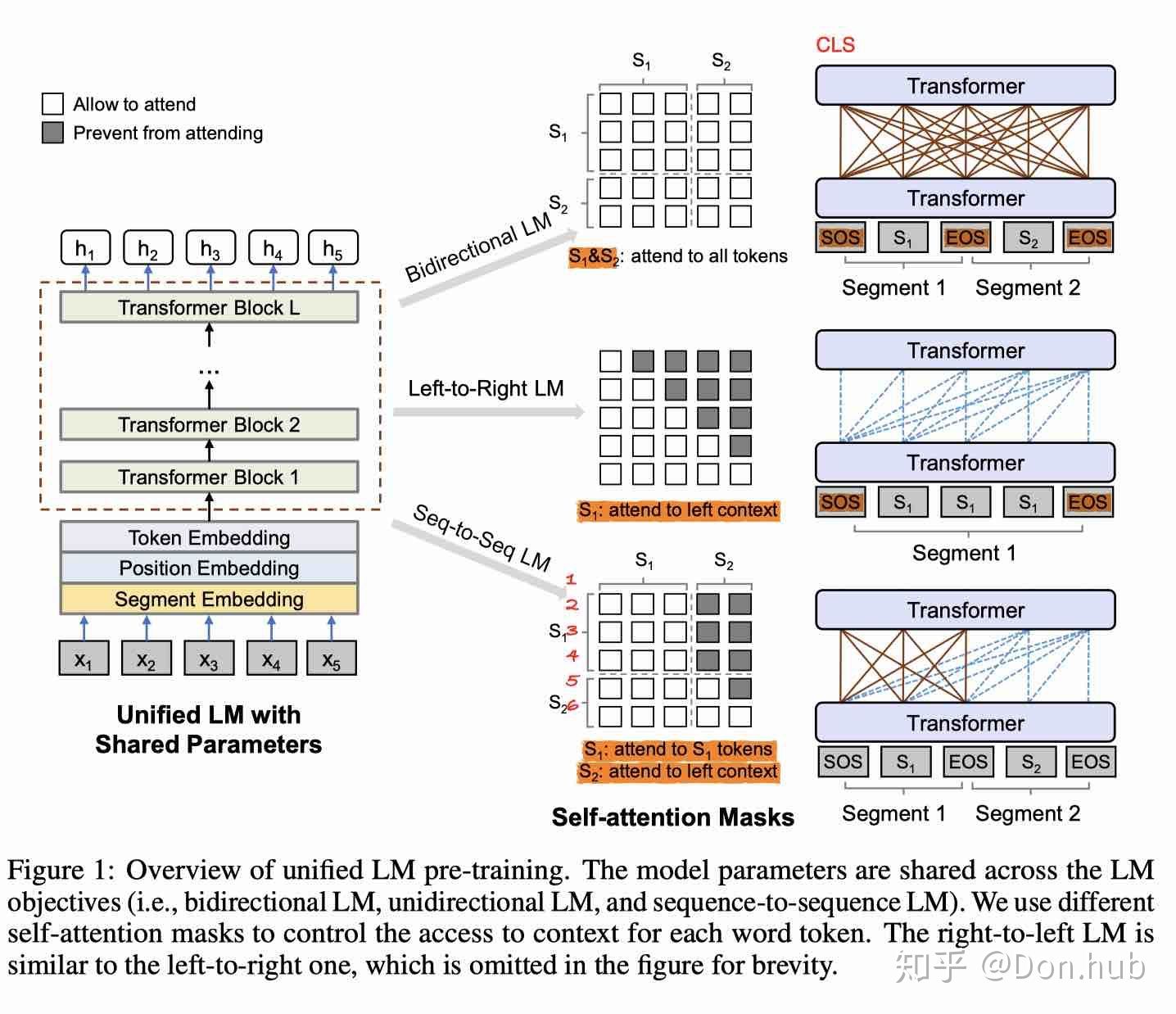
UniLM
Unified Language Model Pre-training for Natural Language Understanding and Generation提出了采用BERT的模型,使用三种特殊的Mask的预训练目标,从而使得模型可以用于NLG,同时在NLU任务获得和BERT一样的效果。 模型使用了三种语言模型的任务:
- unidirectional prediction
- bidirectional prediction
- seuqnece-to-sequence prediction
UniLM三个任务分别如下图所示:
![yi7Vij.jpg]()
-
ERINE
ERINE是百度开源的中文预训练语言模型,与BERT的主要区别是其增加了基于phrase (在这里是短语 比如 a series of, written等)的masking策略和基于 entity(在这里是人名,位置, 组织,产品等名词 比如Apple, J.K. Rowling)的masking 策略,对比直接将知识类的query 映射成向量然后直接加起来,ERNIE 通过统一mask的方式可以潜在的学习到知识的依赖以及更长的语义依赖来让模型更具泛化性。
ERNIE 2.0构建了更多的词法级别,语法级别,语义级别的预训练任务,使用连续学习策略,首先,连续用大量的数据与先验知识连续构建不同的预训练任务。其次,不断的用预训练任务更新ERNIE 模型。
关于ERINE的更多细节可以参考:https://baijiahao.baidu.com/s?id=1648169054540877476&wfr=spider&for=pc。
-
-
参考资料
https://github.com/NLP-LOVE/ML-NLP/tree/master/NLP/16.8%20BERT
https://zhuanlan.zhihu.com/p/151412524
https://zhuanlan.zhihu.com/p/198964217
https://blog.csdn.net/fengdu78/article/details/104744679/
https://www.jianshu.com/p/56a621e33d34

 浙公网安备 33010602011771号
浙公网安备 33010602011771号