mysql 数据库以及sql 的优化
使用案例
表结构说明
- 用户账号表(account),主要存储用户账号、密码、注册时间等信息,1万条数据
- 用户基本信息表(userinfo),主要存储用户个人信息,包括年龄、性别等,关联 account 表,关联字段 account_id,1万条数据
- 订单表(orderinfo),主要存储用户订单信息,关联account 表,关联字段 account_id,10万条数据
业务需求说明
统计出年龄大于 30 岁,性别为女(0)的用户所下订单的总数量。 当然用其他方式可以实现,但这里不考虑非数据库处理的其他方式
分析:
数量需要查询order表,但是 年龄在userinfo 表,他们没有直接的关联关系,他们和account表有关联
所以这里一定是 from account 表 ,然后left join 其他的表
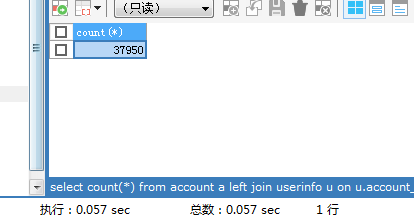
SELECT COUNT(*) FROM account a LEFT JOIN userinfo u ON u.account_id = a.id LEFT JOIN orderinfo o ON o.account_id = a.id WHERE u.age > 30 AND u.sex = 0 AND o.id IS NOT NULL;
没有添加索引的时候查询结果 需要25秒
使用sql 优化 分析

考虑添加索引,添加索引在 where 条件 以及order by 等字段上
userinfo 和 order 和 account 有关联,那么我们考虑先在 userinfo 上加
添加索引
ALTER TABLE userinfo ADD INDEX index_account_id (`account_id`);
注意:这里是` 不是单引号
查询索引
SHOW INDEX FROM userinfo;
再次查询 结果变成了5秒
然后再order 上加索引
ALTER TABLE orderinfo ADD INDEX index_account_id (`account_id`);
最后查询结果是非常快的了
那么为什么没有在age 和 sex 上加索引呢
唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件,也就是区分度太低,
比如性别,比如查看性别的区分度可以用这个语句:
2、较频繁的作为查询条件的字段应该创建索引
SELECT count(*), sex FROM userinfo GROUP BY sex; +----------+------+ | count(*) | sex | +----------+------+ | 5000 | 0 | | 5000 | 1 | +----------+------+
可以看到,一共有两个性别,每个5000,即使加了索引,每次也需要扫描一半的数据。
3、更新非常频繁的字段不适合创建索引;
4、不会出现在 WHERE 子句中的字段不该创建索引
SQL 优化 explain
参考:https://www.cnblogs.com/fengzheng/p/8916125.html
尽量去避免聚合操作
聚合操作如count,group等,是数据库性能的大杀手,经常会出现大面积的表扫描和索表的情况,所以大家能看到很多平台都把数量的计算给隐藏了,商品查询不去实时显示count的结果。如淘宝,就不显示查询结果的数量,只是显示前100页。
避免聚合操作的方法就是将实时的count计算结果用字段去存储,去累加这个结果。当然,也可以考虑用spark等实时计算框架去处理,
程序的优化很多时候都是一些细节的问题,更应该注意平时的积累,阿里SQL的规范有很多可以吸取的地方

 浙公网安备 33010602011771号
浙公网安备 33010602011771号