
第五章实验作业
实验5:字符串及正则表达式
一.实验目的和要求
1.了解和熟悉字符串常用操作(拼接字符串,计算串的长度,截取字符串,分隔和合并字符串,检索字符串,字母的大小写转换,格式化字符串。
2.实现字符串编码转换。
3.使用正则表达式处理字符串解决查找符合某些复杂规则的字符串的需求。
4.使用re模块实验正则表达式操作。
二、实验环境 软件版本:Python
三,实验过程
test 1:
(1)实验代码如下:
programmer_1 = '程序员甲:搞IT太辛苦了,我想换行......怎么办?'
programmer_2 = '程序员乙:敲一下回车键'
print(programmer_1 + '\n' +programmer_2)
(2)实验结果截图如下:

test 2:
(1)实验代码如下:
programer_1 = '你知道我的生日吗?' #程序员问程序员乙的台词
print('程序员甲说:',programer_1) #输出程序员甲的台词
programer_2 = '输入你的身份证号码。' #程序员乙的台词
print('程序员乙说:',programer_2) #输出程序员乙的台词
idcard = '123456199006277890' #定义保存身份证号码的字符串
print('程序员甲说:',idcard) #程序员甲说出身份证号码
birthday = idcard + '年' + idcard[10:12] + '月' + idcard[12:14] +'日' #截取生日
print('从程序员乙说:','你是'+birthday +'出生的,所以你的生日是'+ birthday[5:])
(2)实验结果截图如下:

test 3:
(1)实验代码如下:
str1 = '@明日科技 @扎克伯格 @俞敏洪'
list1 = str1.split(' ')
print('您@的好友有:')
for item in list1:
print(item[1:])
(2)实验结果截图如下:

test 4:
(1)实验代码如下:
list_friend = ['明日科技','扎克伯格','俞敏洪','马云','马化腾'] #好友列表
str_friend = ' @'.join(list_friend) #用空格+@符进行连接
at = '@'+str_friend #由于使用join()方法时,第一个元素前不加分隔符,所以需要在前面加上@符号
print('您要@的好友:',at)
(2)实验结果截图如下:

test 5:
(1)实验代码如下:
#假设已经注册的会员名称保存在一个字符串中,以“ | ”进行分隔
username_1 = '|MingRi|mr|mingrisoft|WGH|MRSoft|'
username_2 = username_1.lower() #将会员名称全部转为小写
regname_1 = input('输入要注册的会员名称:')
regname_2 = '|' + regname_1.lower() +'|' #将要注册的会员名称全部转为小写
if regname_2 in username_2: #判断输入的会员名臣是否存在
print('会员名',regname_1,'已经存在')
else :
print('会员名',regname_1,'可以注册!')
(2)实验结果截图如下:


test 6:
(1)实验代码如下:
import math #导入Python的数学模块
# 已货币形式显示
print('1251+3950的结果时(以货币形式显示):¥{:,.2f}元'.format(1251+3950))
print('{0:.1f}用科学技术法表示:{0:E}'.format(120000,1)) #用科学技术法表示
print('Π取5位小数:{:.5f}'.format(math.pi)) #输出小数点后5位
print('{0:d}的16进制结果是:{0:#x}'.format(100)) #输出十六进制数
#输出百分比,并且不带小数
print('天才是由{:.0%}的灵感,加上{:0%}的汗水。'.format(0.01,0.99))
(2)实验结果截图如下:

test 7:
(1)实验代码如下:
import re #导入Python的re模块
pattern = r'(13[4-9]\d{8})$|(15[01289]\d{8})$'
mobile = '13634222222'
match = re.match(pattern,mobile) #进行模式匹配
if match == None : #判断是否为None,为镇表示匹配失败
print(mobile,'不是有效的中国移动手机号码 。')
else :
print(mobile,'是有效的中国移动手机号码。')
mobile = '13144222221'
match = re.match(pattern,mobile) #进行模式匹配
if match == None : #判断是否为None,为镇表示匹配失败
print(mobile,'不是有效的中国移动手机号码 。')
else :
print(mobile,'是有效的中国移动手机号码。')
(2)实验结果截图如下:

test 8:
(1)实验代码如下:
import re #导入Python的re模块
pattern = r'(黑客)|(抓包)|(监听)|(Trojan)' #模式字符串
about = '我是一名程序员,我喜欢看黑客方面的图书,想研究一下Trojan。'
match = re.search(pattern,about) #进行模式匹配
if match == None : #判断是否为None,为真表示匹配失败
print(about,'@ 安全')
else :
print(about,'@ 出现了危险词汇!')
about = '我是一名程序员,我喜欢看计算机网络方面的图书,喜欢开发网站。'
match = re.match(pattern,about) #模式匹配
(2)实验结果截图如下:
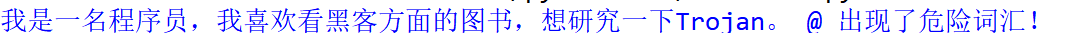
test 9:
(1)实验代码如下:
import re #导入Python的re模块
pattern = r'(黑客)|(抓包)|(监听)|(Trojan)' #模式字符串
about = '我是一名程序员,我喜欢看黑客方面的图书,想研究一下Trojan。\n'
sub = re.sub(pattern,'@_@',about) #进行模式替换
print(sub)
about = '我是一名程序员,我喜欢看计算机网络方面的图书,喜欢开发网站。'
sub = re.sub(pattern,'@_@',about) #进行模式替换
print(sub)
(2)实验结果截图如下:

test 10
(1)实验代码如下:
import re
str1 = '@明日科技 @扎克伯格 @俞敏洪'
pattern = r'\s*@'
list1 = re.split(pattern,str1)
print('您@的好友有:')
for item in list1:
if item != "":
print(item)
(2)实验结果截图如下:

shizhan 1:
(1)实验代码如下:
str1 = '马走日'
str2 = '想走田'
str3 = '车走直路炮翻山'
str4 = '士走斜线护将边'
str5 = '小卒一去不回还'
print("象棋口诀:\n"+str1+"\t,\n"+ str2 +"\t,\n"+ str3 +"\t,\n"+ str4 +"\t,\n"+str5 +"\t。\n")
(2)实验结果截图如下:

shizhan2 :
(1)实验代码如下:
cpmap = {"津A":"天津",
"吉A":"长春",
"沪A":"上海",
"京A":"北京",
"黑A":"哈尔滨"}
carlist = ["吉A﹒12344","沪A﹒55736","黑A﹒77886","京A﹒87654"]
for index,item in enumerate(carlist):
print("第%d张车牌号码:"%(index+1))
print(item)
top2 = item[:2]
print("这张车牌号码的归属地:%s"% cpmap[top2])
(2)实验结果截图如下:

shizhan 3:
(1)实验代码如下:
import random
print("-------------模拟微信抢红包--------------")
total = input("请输入要装入红包的总金额(元):")
count = int(input("请输入红包个数(个):"))
dtotal = float(total)
for i in range(1,count+1):
if i == count:
cur = dtotal
else:
cur = round(dtotal/2*random.random(),2)
dtotal = dtotal - cur
print("第%d个红包:%.2f元"%(i,cur))
(2)实验结果截图如下:

shizhan 4:
(1)实验代码如下:
template = '{:s}\t天气预报:{:s}\t温度:{:s}\t{:s}'
print(template.format('2018年4月17日','晴','20℃~7℃','微风转西风3~4级'))
print(template.format('8:00','晴','13℃','微风'))
print(template.format('12:00','晴','19℃','微风'))
print(template.format('16:00','晴','18℃','西风3~4级'))
print(template.format('20:00','晴','15℃','西风3~4级'))
print(template.format('00:00','晴','12℃','微风'))
print(template.format('04:00','晴',' 9℃','微风'))
(2)实验结果截图如下:

密码:
(1)实验代码如下:
import re
pattern = r'(\w)|(\W){8}$'
secret = 'Lyl12345'
match = re.match(pattern,secret)
if match == None :
print(secret,'不是有效的密码')
else :
print(secret,'是有效的密码')
(2)实验结果截图如下:

ID:
(1)实验代码如下:
import re
pattern = r'(^\d{18}$)|(^\d{17})(\d|X|x)$'
ID = '441873893293744456'
match = re.match(pattern,ID)
if match == None :
print(ID,'不是属于广东省的')
else :
print(ID,'是属于广东省的')
(2)实验结果截图如下:
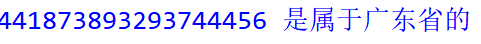
四,

 浙公网安备 33010602011771号
浙公网安备 33010602011771号