玩转obsidian+dataview
 obsidian非常好用,但是当我想研究dataview的时候却总是望而却步,这个看起来也太麻烦了吧,社区的一些文档和案例看着就让人发怵啊,救命救命。其实真正沉下心来,稍微看看,好家伙,我成了!
obsidian非常好用,但是当我想研究dataview的时候却总是望而却步,这个看起来也太麻烦了吧,社区的一些文档和案例看着就让人发怵啊,救命救命。其实真正沉下心来,稍微看看,好家伙,我成了!
玩转obsidian+dataview
我不会设置仅粉丝可见,不需要你关注我,仅仅希望我的踩坑经验能帮到你。如果有帮助,麻烦点个 👍 吧,这会让我创作动力+1 😁。我发现有的时候会自动要求会员才能看,可以留言告诉我,不是我干的!😠
写在前面
-
摘要
obsidian非常好用,但是当我想研究dataview的时候却总是望而却步,这个看起来也太麻烦了吧,社区的一些文档和案例看着就让人发怵啊,救命救命。其实真正沉下心来,稍微看看,好家伙,我成了!
-
参考链接:
- 这里有基础、有案例,慢慢看,沉住气:https://pkmer.cn/Pkmer-Docs/10-obsidian/obsidian社区插件/dataview/dataview/
dataview基础
先说说我的需求,obsidian有个东西很好用,叫 日记,我只需要在日历上点一下,就可以自动创建一个md,文件名就是年-月-日,nice啊家人们。那我想啊,直接把文件名、总结的内容(几句话吧)、标签做成一个表格,岂不美哉。我啪的一下就写出来了,很快啊。
TABLE WITHOUT ID
file.link as 文件名,
info as 内容,
file.tags as 标签
FROM "我的日记"
WHERE contains(file.name, "2025")
SORT file.name desc
-
输出一个表,不要给我自动带ID,其实这个ID就是文件名的超链接
-
下面三条就是每列的内容和标题
-
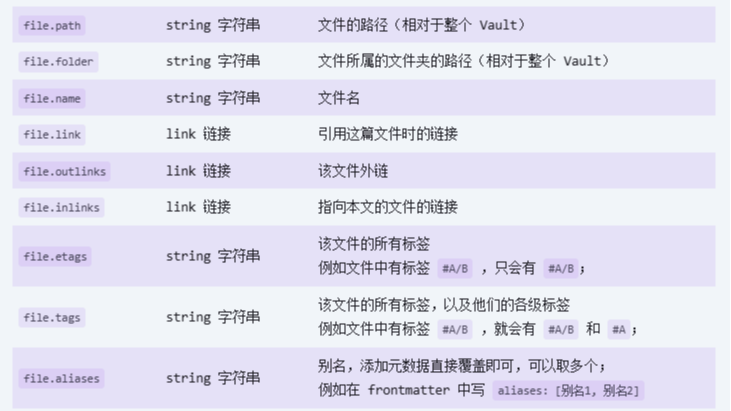
file.link:这是基础的参数,file.xxx,这个link,emm,后面的tags也是一样,就是每个文档都有的。![在这里插入图片描述]()
-
info:这个是我自定义的字段,写在文档开头的yaml,只要你懂obsidian的yaml语法,很多玩意儿都是用yaml标注的。--- tags: - 标签1 - 标签2 info: 这篇文章写的不错,对吗,这不对 ---写这个
info干嘛呢,因为 dataview 只能从 yaml 中拿东西,或者从 file.xxx 这种默认的参数里拿东西,总之能拿到的东西是有限的,所以我得自己定义一个字段,方便取数据。
-
-
FROM:这个是我放日记的文件夹,好说,如果你有点SQL基础,这就太简单了。 -
WHERE:过滤条件嘛,我只拿2025年的文档,如果你有SQL基础。。。 -
SORT:排序嘛,我想逆序显示,当然,如果你有SQL基础。。。
就这么多,完了家人们,这就完事儿了。快试试看 🎉
dataviewjs进阶
这个方便吗,不太方便! info 字段还得我自己总结,这对吗?太不对了!我要自动生成 info !查了一圈,普通的 dataview 能干的太有限了,高级功能得自己写js(记得打开dataview的配置-dataviewjs开启)
稍微操作一下,这不就写完了吗?我用deepseek了吗?我没用,我用的 GPT-4.1 嘿嘿~ 这种小事,我稍微改改不就完事儿了吗~ 完美!🎉
// 1. 抓取目标文件夹下、文件名包含 “2025” 的页,并按文件名倒序
const pages = dv
.pages('"我的日记"')
.where(p => p.file.name.includes("2025"))
.sort(p => p.file.name, 'desc');
// 2. 定义表头
const columns = ["日期", "内容", "标签"];
// 3. 并行读取并解析所有文件
const rows = await Promise.all(
pages.map(async page => {
// 3.1 读取整个文件文本
const text = await dv.io.load(page.file.path);
// 3.2 抽出所有一级 H2 标题
const headers = Array.from(text.matchAll(/^##\s+(.*)$/gm), m => m[1]);
const listHTML = headers.length
? `<ul>${headers.map(h => `<li>${h}</li>`).join("")}</ul>`
: "";
// 3.3 处理标签(File.tags 是 TagRef 对象数组)
const tags = (page.file.tags ?? [])
.map(t => (typeof t === "string" ? t : t.tag))
.join(" ");
// 3.4 返回这一行
return [
page.file.link, // 文件链接
listHTML, // 用 “|” 连接所有 H2 标题
tags || "" // 如果无标签则显示一个短横
];
})
);
// 4. 渲染表格
dv.table(columns, rows);
这我就不多解释了,高低你得有js基础,看就完了,对不对。我做了一个什么功能了,注意!看3.2的部分就行,通过正则表达式取出二级标题(##的)然后做成列表,这个列表好看吗,好看个锤子,得用 ul-li 包装一下,good good,然后就完了,其他的没啥。
dataviewjs瞎搞
我这不安分的心啊,内容和标签,能不能搞在一起,三列并两列啊,我试试
// 1. 抓取目标文件夹下、文件名包含 “2025” 的页,并按文件名倒序
const pages = dv
.pages('"我的日记"')
.where(p => p.file.name.includes("2025"))
.sort(p => p.file.name, 'desc');
// 2. 定义表头
const columns = ["日期", "内容"];
// 3. 并行读取并解析所有文件
const rows = await Promise.all(
pages.map(async page => {
// 3.1 读取整个文件文本
const text = await dv.io.load(page.file.path);
// 3.2 处理标签(File.tags 是 TagRef 对象数组)
const tags = (page.file.tags ?? [])
.map(t => (typeof t === "string" ? t : t.tag))
.join(" ") || "";
// 3.3 抽出所有一级 H2 标题
const headers = Array.from(text.matchAll(/^##\s+(.*)$/gm), m => m[1]);
const listHTML = headers.length
? `<ul>${headers.map(h => `<li>${h}</li>`).join("")}</ul>`
: "";
const tph = "<div>" + listHTML + "</div>" + `<div style="color: orange; border: 1px solid green; width: fit-content;"> ${tags.replace("#", "")} </div>`
// 3.4 返回这一行
return [
page.file.link, // 文件链接
tph, // 用 “|” 连接所有 H2 标题
];
})
);
// 4. 渲染表格
dv.table(columns, rows);
这里调换了 3.2 和 3.3 的顺序,先拿到标签再拿标题,然后我一顿写 css 组装在一块儿,这不就三列并两列了吗,看着还不错,不过感觉意义不大。
我是想说,dataviewjs 实在是太自由了,踏踏开!一自摸踏踏开!随便你瞎搞,样式随便调,很棒哦~ 😄
我是英俊,记得点赞!👍
- ☁️ 我的CSDN:
https://blog.csdn.net/qq_21579045 - ❄️ 我的博客园:
https://www.cnblogs.com/lyjun/ - ☀️ 我的Github:
https://github.com/TinyHandsome - 🌈 我的bilibili:
https://space.bilibili.com/8182822 - 🍅 我的知乎:
https://www.zhihu.com/people/lyjun_ - 🐧 粉丝交流群:1060163543,神秘暗号:为干饭而来
碌碌谋生,谋其所爱。🌊 @李英俊小朋友

 浙公网安备 33010602011771号
浙公网安备 33010602011771号