《流畅的python》学习笔记及书评
《流畅的python》学习笔记
写在前面

-
读后感 优点:
-
翻译满昏!绝对满昏!💯,你看下面黄色部分,这翻译绝了,感觉我才是文化沙漠,什么“亲者快,仇者痛”,我这辈子没见过这么高级的用法。

-
我被作者举的例子惊到了(见2.4),真的很有水平,翻译和作者本身都很厉害
比如下面这一句
t = (1, 2, [30, 40]) t[2] += [50, 60]这两行代码的执行结果:
- 抛出异常:
因为 tuple 不支持对它的元素赋值,所以会抛出 TypeError 异常。 t[2]的值发生了修改:t = (1, 2, [30, 40, 50, 60])
- 抛出异常:
-
在讲排序的时候,讲到
sorted和list.sort背后使用的排序算法是Timsort,这个算法的作者是Tim Peters- 这个算法的相关代码在Google对Sun的侵权案中,当作了呈堂证供。
- 这个算法的作者也是
import this,python之禅的作者。 - 我靠,太离谱了,世界线收束,鸡皮疙瘩都起来了。
-
每一章的小结真的写的太好了,方便回顾这一章讲了啥,也方便自己查漏补缺。
-
延伸阅读也是惊艳啊,作者很明显博览群书,基础扎实。
-
作者吹了一波《Python Cookbook(第三版)》和《Python Cookbook(第二版)》,我准备去学习学习!
-
作者每章的小结写的很不错,每次因为知识点需要复查书籍的时候,可以先看对应章节的 本章小结 ,再查。
-
-
读后感 缺点:
-
读到11章和12章的时候,就开始有点吃力了,不知道是不是我的知识储备不够。一些抽象的知识点作者和翻译都有点力不从心(作为读者的角度),就是好像作者想把这个点用比喻的方式说清楚,但是又很难把他心中的理解表达出来,甚至很多地方都是直接进行教条化的描述,对于翻译来说,就更困难了。
【对不起,我面向对象学的太差了呜呜呜】
比如 P540 中:优先使用对象组合,而不是类继承,还有,组合和委托可以代替混入,把行为提供给不同的类,但是不能取代接口继承去定义类型层次结构。
对于 组合、委托、混入、继承等名词的解释不够到位,这几个名词,我就对继承还可以有深入的理解,其他的三个名词出现的时候,一脸懵逼
-
从16章协程开始,我就开始绝望了起来,有点整不明白,咬牙硬吃到18章asyncio的一些知识点的时候,就是懵懵懂懂的,在 yield 和 yield from 中学傻了。在18.5章的时候,不知道为什么突然出现了个semaphore,十分突兀,就开始不知所云了起来。
-
-
传送门:
1. Python数据模型
-
collections.nametuple:用来构建只有少数属性但是没有方法的对象,比如数据库条目。 -
__getitem__:方法可以实现切片效果def __getitem__(self, position): return self._cards[position]
1.1 特殊方法
-
如何使用特殊方法
-
首先,特殊方法的存在是为了被python解析器调用的,而不是被我们调用的
-
其次,
my_object.__len__()这种写法应该修正为len(my_object),在执行len(my_object)的时候,如果my_object是一个自定义类的对象,那么python会自己去调用其中的,由我们自己实现的__len__方法 -
如果是python内置的类型,如列表list、字符串str、字节序列bytearray等,Cpython会抄近道,
__len__实际上会直接返回PyVarObject里的ob_size属性。其中PyVarObject表示内存中长度可变的内置对象的C语言结构体。直接读取这个值比调用一个方法要快很多。
-
很多时候,特殊方法的调用是隐式的,比如
for i in x这个语句,背后其实调用的是iter(x),而这个函数的背后则是x.__iter__()方法。(前提是这个方法在x中被实现了) -
不要想当然的随意添加特殊方法,说不定以后python会用到这个名字。
-
-
repr:能把一个对象用字符串的形式表达出来以便辨认,「字符串表示形式」。__repr__所返回的字符串应该准确、无歧义,并且尽可能表达出如何用代码创建出这个被打印的对象。__repr__和__str__的区别在于,后者是在str()函数被使用,或者是在用print函数打印一个对象的时候才能被调用的,并且它返回的字符串对终端用户更友好。如果你只想实现这两个特殊方法中的一个,
__repr__是更好的选择,因为如果一个对象没有__str__函数,而 Python 又需要调用它的时候,解释器会用__repr__作为替代。 -
bool(x)的背后是调用x.__bool__()的结果;如果不存在__bool__方法,那么bool(x)会尝试调用x.__len__()。若返回 0,则 bool 会返回 False;否则返回True。 -
跟运算符无关的特殊方法
- 字符串/字节序列表示形式:
__repr__、__str__、__format__、__bytes__ - 数值转换:
__abs__、__bool__、__complex__、__int__、__float__、__hash__、__index__ - 集合模拟:
__len__、__getitem__、__setitem__、__delitem__、__contains__ - 迭代枚举:
__iter__、__reversed__、__next__ - 可调用模拟:
__call__ - 上下文管理器:
__enter__、__exit__ - 实例创建和销毁:
__new__、__init__、__del__ - 属性管理:
__getattr__、__getattribute__、__setattr__、__delattr__、__dir__ - 属性描述符:
__get__、__set__、__delete__ - 跟类相关的服务:
__prepare__、__instancecheck__、__subclasscheck__
- 字符串/字节序列表示形式:
-
跟运算符相关的特殊方pos法
- 一元运算符:
__neg__(-)、__pos__(+)、__abs__(abs()) - 众多比较运算符:
__lt__(<)、__le__(<=)、__eq__(==)、__ne__(!=)、__gt__(>)、__ge__(>=) - 算数运算符:
__add__(+)、__sub__(-)、__mul__(*)、__truediv__(/)、__floordiv__(//)、__mod__(%)、__divmod__(divmod())、__pow__(**或pow())、__round__(round()) - 反向算数运算符:
__radd__、__rsub__、__rmul__、__rtruediv__、__rfloordiv__、__rmod__、__rdivmod__ - 增量赋值算数运算符:
__iadd__、__isub__、__imul__、__itruediv__、__ifloordiv__、__imod__、__ipow__ - 位运算符:
__invert__(~)、__lshift__(<<)、__rshift__(>>)、__and__(&)、__or__(|)、__xor__(^) - 反向位运算符:
__rlshift__、__rrshift__、__rand__、__rxor__、__ror__ - 增量赋值位运算符:
__ilshift__、__irshift__、__iand__、__ixor__、__ior__
- 一元运算符:
-
为什么len不是一个普通方法:「实用胜于纯粹」,如果 x 是一个内置类型的实例,那么
len(x)的速度会非常快。背后的原因是 CPython 会直接从一个 C 结构体里读取对象的长度,完全不会调用任何方法。获取一个集合中元素的数量是一个很常见的操作,在
str、list、memoryview等类型上,这个操作必须高效。
换句话说,len 之所以不是一个普通方法,是为了让 Python 自带的数据结构可以走后门,abs 也是同理。但是多亏了它是特殊方法,我们也可以把 len 用于自定义数据类型
2. 序列构成的数组
2.1 内置序列类型
-
容器序列:list、tuple、collections.deque。可以存放不同类型的数据。
-
扁平序列:str、bytes、bytearray、memoryview、array.array。只能容纳一种类型。
-
容器序列存放的是它们所包含的任意类型的对象的引用,而扁平序列里存放的是值而不是引用。换句话说,扁平序列其实是一段连续的内存空间。由此可见扁平序列其实更加紧凑,但是它里面只能存放诸如字符、字节和数值这种基础类型。
-
可变序列:list、bytearray、array.array、collections.deque、memoryview
-
不可变序列:tuple、str、bytes
-
可变序列(MutableSequence)和不可变序列(Sequence)的差异

2.2 列表推导和生成器表达式
-
Python 会忽略代码里 []、{} 和 () 中的换行,因此如果你的代码里有多行的列表、列表推导、生成器表达式、字典这一类的,可以省略不太好看的续行符 \。
-
列表推导不会再有变量泄漏的问题
x = 'ABC' dummy = [ord(x) for x in x] print(x, dummy) # ABC [65, 66, 67] -
生成器表达式的语法跟列表推导差不多,只不过把方括号换成圆括号而已。
2.3 元组不仅仅是不可变的列表
-
除了用作不可变的列表,它还可以用于没有字段名的记录。
-
元组其实是对数据的记录:元组中的每个元素都存放了记录中一个字段的数据,外加这个字段的位置。正是这个位置信息给数据赋予了意义。
-
在元组拆包中使用
*也可以帮助我们把注意力集中在元组的部分元素上。用*来处理剩下的元素a, b, *rest = range(5) print(a, b, rest) # 0 1 [2, 3, 4] -
在平行赋值中,
*前缀只能用在一个变量名前面,但是这个变量可以出现在赋值表达式的任意位置a, *body, c, d = range(5) print(a, body, c, d) # 0 [1, 2] 3 4 -
collections.namedtuple:创建一个具名元组需要两个参数,一个是类名,另一个是类的各个字段的名字。后者可以是由数个字符串组成的可迭代对象,或者是由空格分隔开的字段名组成的字符串。_fields:一个包含这个类所有字段名称的元组。_make():通过接受一个可迭代对象来生成这个类的一个实例,它的作用等价于类(*参数元组)是一样的。_asdict():把具名元组以collections.OrderedDict的形式返回,我们可以利用它来把元组里的信息友好地呈现出来。
-
方法和属性 列表 元组 数组 双向队列 描述 s.__add__(s2)√ √ √ × s+s2,拼接s.__iadd__(s2)√ × √ √ s+=s2,就地拼接s.append(e)√ × √ √ 在尾部添加一个新元素 s.appendleft(e)× × × √ 添加一个元素到最左侧(到第一个元素之前) s.byteswap× × √ × 翻转数组内每个元素的字节序列,转换字节序列 s.clear()√ × × √ 删除所有元素 s.__contains__(e)√ √ √ × s是否包含e s.copy()√ × × × 列表的浅复制 s.__copy__()× × √ √ 对 copy.copy(浅复制)的支持s.count(e)√ √ √ √ e在s中出现的次数 s.__deepcopy__()× × √ × 对 copy.deepcopy(深复制)的支持s.__delitem__(p)√ × √ √ 把位于p的元素删除 s.extend(it)√ × √ √ 把可迭代对象it追加给s s.extendleft(i)× × × √ 将可迭代对象i中的元素添加到头部 s.frombytes(b)× × √ × 将压缩成机器值得字节序列读出来添加到尾部 s.fromfile(f,n)× × √ × 将二进制文件f内含有机器值读出来添加到尾部,最多添加n项 s.fromlist(l)× × √ × 将列表里的元素添加到尾部,如果其中任何一个元素导致了 TypeError异常,那么所有的添加都会取消s.__getitem__()√ √ √ √ s[p],获取位置p的元素s.__getnewargs__()× √ × × 在pickle中支持更加优化的序列化 s.index(e)√ √ √ × 在s中找到元素e第一次出现的位置 s.insert(p,e)√ × √ × 在位置p之前插入元素e s.itemsize× × √ × 数组中每个元素的长度是几个字节 s.__iter__()√ √ √ √ 获取s的迭代器 s.__len__()√ √ √ √ len(s),元素的数量s.__mul__()√ √ √ × s*n,n个s的重复拼接s.__imul__()√ × √ × s*=n,就地重复拼接s.__rmul__()√ √ √ × n*s,反向拼接*s.pop([p])√ × √ √ 删除最后或者是(可选的)位于p的元素,并返回它的值(注意,在双向队列中不接受参数) s.popleft()× × × √ 移除第一个元素并返回它的值 s.remove(e)√ × √ √ 删除s中第一次出现的e s.reverse()√ × √ √ 就地把s的元素倒序排列 s.__reversed__√ × × √ 返回s的倒序迭代器 s.rotate(n)× × × √ 把n个元素从队列的一段移到另一端 s.__setitem__(p,e)√ × √ √ s[p]=e,把元素e放在位置p,替代已经在那个位置的元素s.sort([key],[reverse])√ × × × 就地对s中的元素进行排序,可选的参数有键(key)和是否倒序(reverse) s.tobytes()× × √ × 把所有元素的机器值用bytes对象的形式返回 s.tofile(f)× × √ × 把所有元素以机器值的形式写入一个文件 s.tolist()× × √ × 把数组转换成列表,列表里的元素类型是数字对象 s.typecode× × √ × 返回只有一个字符的字符串,代表数组元素在C语言中的类型
2.4 切片
-
为什么切片和区间会忽略最后一个元素:
在切片和区间操作里不包含区间范围的最后一个元素是 Python 的风格,这个习惯符合 Python、C 和其他语言里以 0 作为起始下标的传统。这样做带来的好处如下。
- 当只有最后一个位置信息时,我们也可以快速看出切片和区间里有几个元素:
range(3)和my_list[:3]都返回 3 个元素。 - 当起止位置信息都可见时,我们可以快速计算出切片和区间的长度,用后一个数减去第一个下标(stop - start)即可。
- 这样做也让我们可以利用任意一个下标来把序列分割成不重叠的两部分,只要写成
my_list[:x]和my_list[x:]就可以了。
- 当只有最后一个位置信息时,我们也可以快速看出切片和区间里有几个元素:
-
slice(a, b, c):对seq[start:stop:step]进行求值的时候,Python 会调用seq.__getitem__(slice(start, stop, step))。 -
slice(start, stop, step):使用方法a = slice(6, 40) item[a] -
多维切片:如果要得到
a[i, j]的值,Python 会调用a.__getitem__((i, j)) -
x[i, ...]:x[i, :, :, :]的缩写 -
给切片赋值:如果把切片放在赋值语句的左边,或把它作为
del操作的对象,我们就可以对序列进行 嫁接 、 切除 或 就地修改 操作。- 如果赋值的对象是一个切片,那么赋值语句的右侧必须是个可迭代对象。
- 即便只有单独一个值,也要把它转换成可迭代的序列。
2.5 增量赋值
-
+和*的陷阱:如果要生成二维序列:- 不能:
[['_']*3]*3 - 而要:
[['_']*3 for i in range(3)]
- 不能:
-
a += b- 如果a实现了
__iadd__方法,就相当于调用了a.extend(b) - 如果a没有实现
__iadd__的话,a += b就跟a = a + b一样了。首先计算a + b,得到一个新的对象,然后赋值给a。 - 也就是说,在这个表达式中,变量名会不会被关联到新的对象,完全取决于这个类型有没有实现
__iadd__方法。
- 如果a实现了
-
对不可变序列进行重复拼接操作的话,效率会很低,因为每次都有一个新对象,而解释器需要把原来对象中的元素先赋值到新的对象里,然后再追加新的元素。
str是一个例外,因为对字符串做+=实在是太普遍了,所以CPython对它做了优化,为str初始化内存的时候,程序会为它留出额外的可扩展空间,因此进行增量操作的时候,并不会涉及复制原有字符串到新位置这类操作。
2.6 排序
-
Python中的排序算法:Timesort 是稳定的,意思是就算两个元素比不出大小,在每次排序的结果里他们的相对位置是固定的。
-
list.sort:就地排序列表,也就是说不会把原列表复制一份,返回值为None -
sorted:会新建一个列表作为返回值 -
key参数能让你对一个混有数字字符和数值的列表进行排序。l = [28, 14, '28', 5, '9', '1', 0, 6, '23', 19] sorted(l, key=int) # [0, '1', 5, 6, '9', 14, 19, '23', 28, '28'] -
sorted和list.sort背后的排序算法是 Timsort,它是一种自适应算法,会根据原始数据的顺序特点交替使用插入排序和归并排序,以达到最佳效率。这样的算法被证明是很有效的,因为来自真实世界的数据通常是有一定的顺序特点的。 -
用
bisect来管理 已排序 的序列:二分法bisect函数其实是bisect_right函数的别名,后者还有个姊妹函数叫bisect_leftbisect_left返回的插入位置是原序列中跟被插入元素相等的元素的位置,也就是新元素会被放置于它相等的元素的前面bisect_right返回的则是跟它相等的元素之后的位置
-
利用
bisect进行评价分组def grade(score, breakpoints=[60, 70, 80, 90], grades='FDCBA'): i = bisect.bisect(breakpoints, score) return grades[i] [grade(score) for score in [33, 99, 77, 70, 89, 90, 100]] # ['F', 'A', 'C', 'C', 'B', 'A', 'A'] -
bisect.insort(seq, item)把变量item插入到序列seq中,并能保持seq的升序顺序。
2.7 数组、内存视图、NumPy和队列
- 如果我们需要一个只包含数字的列表,那么
array.array比list更高效。通过array.tofile和array.fromfile进行文件的保存和读取。 memoryview:是一个内置类,它能让用户在不复制内容的情况下操作同一个数组的不同切片。memoryview.cast的概念跟数组模块类似,能用不同的方式读写同一块内存数据,而且内容字节不会随意移动。memoryview.cast会把同一块内存里的内容打包成一个全新的memoryview对象给你。numpy:- 将一维数组转化为二维:
array.shape=(x, y) - 将数组转置:
array.T、array.transpose()
- 将一维数组转化为二维:
collections.deque类(双向队列)是一个线程安全、可以快速从两端添加或者删除元素的数据类型。dq = deque(range(10), maxlen=10),maxlen是一个可选参数,带别找个队列可以容纳的元素的数量。dq.rotate(n):队列的旋转操作接受一个参数n,当n>0时,队列的最右边的n个元素会被移动到队列的左边。当n<0时,最左边的n个元素会被移动到右边。append和popleft都是原子操作,也就说是 deque 可以在多线程程序中安全地当作先进先出的栈使用,而使用者不需要担心资源锁的问题。- 其他队列的实现:
queue提供了Queue、LifoQueue、PriorityQueue。在满员的时候,这些类不会扔掉旧的元素来腾出位置。相反,如果队列满了,它就会被锁住,直到另外的线程移除了某个元素而腾出了位置。这一特性让这些类很适合用来控制活跃线程的数量。multiprocessing实现了自己的Queue,跟queue.Queue相似,是涉及给进程间通信用的。multiprocessing.JoinableQueue可以让任务管理变得更方便。asyncio里面有Queue、LifoQueue、PriorityQueue、JoinableQueue,这些类受到queue和multiprocessing模块的影响,但是为异步编程里的任务管理提供了专门的便利。heapq没有队列类,而是提供了heappush和heappop方法,让用户可以把可变序列当作堆队列或者优先队列来使用。
- 列表倾向于存放有通用特性的元素;元组则恰恰相反,经常用来存放不同类型的元素。
3. 字典和集合
3.1 泛映射类型和字典推导
-
collections.abc模块中有Mapping和MutableMapping这两个抽象基类,它们的作用是为 dict 和其他类似的类型定义形式接口
-
可散列的数据类型(hashable)
如果一个对象是可散列的,那么在这个对象的生命周期中,它的散列值是不变的,而且这个对象需要实现
__hash__()方法。另外可散列对象还要有__eq__()方法,这样才能跟其他键做比较。如果两个可散列对象是相等的,那么它们的散列值一定是一样的。简单来说,如果一个对象是可散列的数据类型的话,那它应是不可变的。
-
list等可变对象是不可散列的,因为随着数据的改变他们的哈希值会变化导致进入错误的哈希表。
-
元组的话,只有当一个元组包含的所有元素都是可散列类型的情况下,它才是可散列的。
-
一般用户自定义的类型的对象都是可散列的,散列值就是它们的
id()函数的返回值,所以所有这些对象在比较的时候都是不相等的。如果一个对象实现了__eq__()方法,并且在方法中用到了这个对象的内部状态的话,那么只有当所有这些内部状态都是不可变的情况下,这个对象才是可散列的。 -
Python 里所有的不可变类型都是可散列的,这个说法其实是不准确的,比如虽然元组本身是不可变序列,它里面的元素可能是其他可变类型的引用。 -
字典推导:
{code: country.upper() for country, code in country_code.items() if code < 66}
3.2 常见的映射方法
dict、collections.defaultdict和collections.OrderedDict的方法列表
| 方法 | dict | defaultdict | OrderedDIct | 描述 |
|---|---|---|---|---|
d.clear() |
√ | √ | √ | 移除所有元素 |
d.__contains__(k) |
√ | √ | √ | 检查k是否在d中 |
d.copy() |
√ | √ | √ | 浅复制 |
d.__copy()__ |
× | √ | × | 用于支持copy.copy |
d.default_factory |
× | √ | × | 在__missing__函数中被调用的函数,用以给未找到的元素设置值 |
d.__delitem__(k) |
√ | √ | √ | del d[k],移除键位k的元素 |
d.fromkeys(it, [initial]) |
√ | √ | √ | 将迭代器it里的元素设置为映射里的键,如果initial参数,就把它作为这些键对应的值(默认是None) |
d.get(k, [default]) |
√ | √ | √ | 返回键k对应的值,如果字典里没有键k,则返回None或者default |
d.__getitem__(k) |
√ | √ | √ | 让字典d能用d[k]的形式返回键k对应的值 |
d.items() |
√ | √ | √ | 返回d里所有的键值对 |
d.__iter__() |
√ | √ | √ | 获取键的迭代器 |
d.keys() |
√ | √ | √ | 获取所有的键 |
d.__len__() |
√ | √ | √ | 可以用len(d)的形式得到字典里键值对的数量 |
d.__missing__(k) |
× | √ | × | 当__getitem__找不到对应键的时候,这个方法会被调用 |
d.move_to_end(k, [last]) |
× | × | √ | 把键位k的元素移动到最靠前或者最靠后的位置(last的默认值是True) |
d.pop(k, [default]) |
√ | √ | √ | 返回键k所对应的值,然后移除这个键值对。如果没有这个键,返回None或者default |
d.popitem() |
√ | √ | √ | 随机返回一个键值对并从字典里移除它 |
d.__reversed__() |
× | × | √ | 返回倒序的键的迭代器 |
d.setdefault(k, [default]) |
√ | √ | √ | 若字典里有键k,则把它对应的值设置位default,然后返回这个值;若无,则让d[k]=default,然后返回default |
d.__setitem__ |
√ | √ | √ | 实现d[k]=v操作,把k对应的值设为v |
d.update(m, [**kwargs]) |
√ | √ | √ | m可以是映射或者键值对迭代器,用来更新d里对应的条目 |
d.values |
√ | √ | √ | 返回字典里的所有值 |
-
用setdefault处理找不到的键
-
使用
d.get(k, default)来代替d[k],可以防止报错 -
字典处理优化
-
好的方法
my_dict.setdefault(key, []).append(new_value) -
差的方法
if key not in my_dict: my_dict[key] = [] my_dict[key].append(new_value) -
二者的效果是一样的,只不过后者至少要进行两次键查询——如果键不存在的话,就是三次,用
setdefault只需要一次就可以完成整个操作。
-
-
3.3 映射的弹性键查询
-
场景:有时候为了方便起见,就算某个键在映射里不存在,我们也希望在通过这个键读取值的时候能得到一个默认值。
-
方法:
-
collections.defaultdict类- 把list构造方法作为
default_factory来创建一个defaultdict - 如果在创建
defaultdict的时候没有指定default_factory,查询不存在的键会触发KeyError defaultdict里的default_factory只会在__getitem__里被调用,在其他的方法里完全不会发挥作用。比如dd[k]会创建默认值并返回该默认值,dd.get(k)就会返回None- 所有这一切的背后是基于特殊方法
__missing__实现的,它会在defaultdict遇到找不到的键的时候调用default_factory,而实际上这个特性是所有映射类型都可以选择去支持的
"""创建一个从单词到其出现情况的映射""" import sys import re from collections import defaultdict WORD_RE = re.compile(r'\w+') # index = {} index = defaultdict(list) with open(sys.argv[1], encoding='utf-8') as fp: for line_no, line in enumerate(fp, 1): for match in WORD_RE.finditer(line): word = match.group() column_no = match.start() + 1 location = (line_no, column_no) ''' 这其实是一种很不好的实现,这样写只是为了证明论点 occurrences = index.get(word, []) occurrences.append(location) index[word] = occurrences ''' ''' 下面是好的实现,用到了setdefault函数 index.setdefault(word, []).append(location) ''' ''' 通过collections.defaultdict实现,取得key没有的时候,新建这个key,并赋予默认值''' index[word].append(location) # 以字母顺序打印出结果 for word in sorted(index, key=str.upper): print(word, index[word]) - 把list构造方法作为
-
自定义一个
dict子类,然后在子类中实现__missing__方法-
像
k in my_dict.keys()这种操作在Python3中是很快的,而且即便映射类型对象很庞大也没关系。这是因为dict.keys()的返回值是一个视图。 -
视图就像一个集合,而且跟字典类似的是,在视图里查找一个元素的速度很快。
class StrKeyDict0(dict): def __missing__(self, key): if isinstance(key, str): raise KeyError(key) return self[str(key)] def get(self, key, default=None): try: return self[key] except KeyError: return default def __contains__(self, key): return key in self.keys() or str(key) in self.keys()
-
-
3.4 字典的变种
-
collections.OrderedDict:这个类型在添加键的时候会保持顺序,因此键的迭代次序总是一致的。OrderedDict的popitem方法默认删除并返回的是字典里的最后一个元素,但是如果像my_odict.popitem(last=False)这样调用它,那么它删除并返回第一个被添加进去的元素。 -
collections.ChainMap:该类型可以容纳数个不同的映射对象,然后在进行键查找操作的时候,这些对象会被当作一个整体被逐个查找,直到键被找到为止。这个功能在给有嵌套作用域的语言做解释器的时候很有用,可以用一个映射对象来代表一个作用域的上下文。 -
collections.Counter:这个映射类型会给键准备一个整数计数器。每次更新一个键的时候都会增加这个计数器。所以这个类型可以用来给可散列表对象计数,或者是当成多重集来用——多重集合就是集合里的元素可以出现不止一次。 -
my_dict.most_common(n):统计字典中出现次数最多的数据ct = Counter({'a': 10, 'b': 2, 'r': 2, 'c': 1, 'd': 1, 'z': 3}) ct.most_common(2) # [('a', 10), ('z', 3)] -
colllections.UserDict:这个类其实就是把标准dict用纯 Python 又实现了一遍。跟OrderedDict、ChainMap和Counter这些开箱即用的类型不同,UserDict是让用户继承写子类的。- 更倾向于从
UserDict而不是从dict继承的主要原因是,后者有时会在某些方法的实现上走一些捷径,导致我们不得不在它的子类中重写这些方法,但是 UserDict 就不会带来这些问题。
- 更倾向于从
-
不可变映射类型:
types.MappingProxyType。如果给这个类一个映射,它会返回一个只读的映射视图。虽然是个只读视图,但是它是动态的。这意味着如果对原映射做出了改动,我们通过这个视图可以观察到,但是无法通过这个视图对原映射做出修改。
3.5 集合
-
集合可以去重
-
集合中的元素必须是可散列的,set 类型本身是不可散列的,但是frozenset 可以。因此可以创建一个包含不同 frozenset 的 set。
-
求交集:
&,intersection -
空集:
set(),而不是{},因为{}是一个空字典 -
除了空集,集合的字符串表示形式总是以
{...}的形式出现。 -
{1, 2, 3}的速度快于set([1, 2, 3]),因为后者的话,Python必须先从set这个名字来查询构造方法,然后新建一个列表,最后再把这个列表传入到构造方法里。但是如果是像{1, 2, 3这样的字面量,Python 会利用一个专门的叫作 BUILD_SET 的字节码来创建集合。 -
MutableSet和它的超类的UML类图

-
集合的数学运算:这些方法或者会生成新集合,或者会在条件允许的情况下就地修改集合
数学符号 Python运算符 方法 描述 $S \cap Z$ s&zs.__and__(z)s和z的交集 $S \cap Z$ z&ss.__rand__(z)反向&操作 $S \cap Z$ z&ss.intersection(it, ...)把可迭代的it和其他所有参数转化为集合,然后求它们与s的交集 $S \cap Z$ s&=zs.__iand__(z)把s更新为s和z的交集 $S \cap Z$ s&=zs.intersection_update(it, ...)把可迭代的it和其他所有参数转化为集合,然后求得它们与s的交集,然后把s更新成这个交集 $S \cup Z$ `s z` s.__or__(z)$S \cup Z$ `z s` s.__ror__(z)$S \cup Z$ `z s` s.union(it, ...)$S \cup Z$ `s =z` s.__ior__(z)$S \cup Z$ `s =z` s.update(it, ...)$S \setminus Z$ s-zs.__sub__(z)s和z的差集,或者叫作相对补集 $S \setminus Z$ z-ss.__rsub__(z)-的反向操作 $S \setminus Z$ z-ss.difference(it, ...)把可迭代的it和其他所有参数转化为集合,然后求它们和s的差集 $S \setminus Z$ s-=zs.__isub__(z)把s更新为它与z的差集 $S \setminus Z$ s-=zs.difference_update(it, ...)把可迭代的it和其他所有参数转化为集合,求它们和s的差集,然后把s更新成这个差集 $S \setminus Z$ s-=zs.symmetric_difference(it)求s和set(it)的对称差集 $S \bigoplus Z$ s^zs.__xor__(z)求s和z的对称差集 $S \bigoplus Z$ z^ss.__rxor__(z)^的反向操作 $S \bigoplus Z$ z^ss.symmetric_difference_update(it, ...)把可迭代的it和其他所有参数转化为集合,然后求它们和s的对称差集,最后把s更新成该结果 $S \bigoplus Z$ s^=zs.__ixor__(z)把s更新成它与z的对称差集 -
集合的比较运算符,返回值是布尔类型
数学符号 Python运算符 方法 描述 s.isdisjoint(z)查看s和z是否不相交(没有共同元素) $e \in S$ e in ss.__contains__(e)元素e是否属于s $S \subseteq Z$ s <= zs.__le__(z)s是否为z的子集 $S \subseteq Z$ s <= zs.issubset(it)把可迭代的it转化为集合,然后查看s是否为它的子集 $S \subset Z$ s < zs.__lt__(z)s是否为z的真子集 $S \supseteq Z$ s >= zs.__ge__(z)s是否为z的父集 $S \supseteq Z$ s >= zs.issuperset(it)把可迭代的it转化为集合,然后查看s是否为它的父集 $S \supset Z$ s > zs.__gt__(z)s是否为z的真父集 -
集合类型的其他方法
方法 set frozenset 描述 s.add(e)√ × 把元素e添加到s中 s.clear()√ × 移除掉s中的所有元素 s.copy()√ √ 对s浅复制 s.discard(e)√ × 如果s里有e这个元素的话,把它移除 s.__iter__()√ √ 返回s的迭代器 s.__len__()√ √ len(s) s.pop()√ × 从s中移除一个元素并返回它的值,若s为空,则抛出KeyError异常 s.remove(e)√ × 从s中移除e元素,若e元素不存在,则抛出KeyError异常
3.6 dict和set的背后
-
如果两个对象在比较的时候相等,那么它们的散列值必须相等。
-
散列函数用于将键值经过处理后转化为散列值。具有以下特性:
- 散列函数计算得到的散列值是非负整数
- 如果 key1 == key2,则 hash(key1) == hash(key2)
- 如果 key1 != key2,则 hash(key1) != hash(key2)
-
散列冲突:简单来说,指的是 key1 != key2 的情况下,通过散列函数处理,hash(key1) == hash(key2),这个时候,我们说发生了散列冲突。设计再好的散列函数也无法避免散列冲突,原因是散列值是非负整数,总量是有限的,但是现实世界中要处理的键值是无限的,将无限的数据映射到有限的集合,肯定避免不了冲突。
-
从字典中取值的算法流程图

-
用元组取代字典就能节省空间的原因有两个:
- 是避免了散列表所耗费的空间
- 无需把记录中字段的名字在每个元素里都存一遍
-
在用户自定义的类型中,
__slots__属性可以改变实例属性的存储方式,由dict变成tuple -
使用散列表给dict带来的优势和限制都有哪些
-
键必须是可散列的
-
字典在内存上的开销巨大
-
键查询很快
-
键的次序取决于添加顺序
-
往字典里添加新键可能会改变已有键的顺序
无论何时往字典里添加新的键,Python 解释器都可能做出为字典扩容的决定。扩容导致的结果就是要新建一个更大的散列表,并把字典里已有的元素添加到新表里。这个过程中可能会发生新的散列冲突,导致新散列表中键的次序变化。
-
-
集合的特点:
- 集合里的元素必须是可散列的
- 集合很消耗内存
- 可以很高效地判断元素是否存在于某个集合
- 元素的次序取决于被添加到集合里的次序
- 往集合里添加元素,可能会改变集合里已有元素的次序
4. 文本和字节序列
4.1 字符和字节
-
把码位转换成字节序列的过程是编码;把字节序列转换成码位的过程是解码。
-
把字节序列变成人类可读的文本字符串就是解码(
decode),而把字符串变成用于存储或传输的字节序列就是编码(encode)。 -
bytes对象可以从str对象使用给定的编码构造,各个元素是range(256)内的整数。bytes对象的切片还是bytes对象,即使是只有一个字符的切片。 -
bytearray对象没有字面量句法,而是以bytearray()和字节序列字面量参数的形式显示。bytearray对象的切片还是bytearray对象。 -
这里比较特殊,因为
my_bytes[0]获取的是一个整数,而my_bytes[:1]返回的是一个长度为1的bytes对象。 -
虽然二进制序列其实是整数序列,但是它们的字面量表示法表明其中有ASCII 文本。因此,各个字节的值可能会使用下列三种不同的方式显示。
- 可打印的 ASCII 范围内的字节(从空格到 ~),使用 ASCII 字符本身。
- 制表符、换行符、回车符和
\对应的字节,使用转义序列\t、\n、\r和\\。 - 其他字节的值,使用十六进制转义序列(例如,
\x00是空字节)。
-
二进制序列有个类方法是
str没有的,名为fromhex,它的作用是解析十六进制数字对(数字对之间的空格是可选的),构建二进制序列:bytes.fromhex('31 4B CE A9') # b'1K\xce\xa9' -
使用缓冲类对象构建二进制序列是一种低层操作,可能涉及类型转换:
import array
numbers = array.array('h', [-2, -1, 0, 1, 2])
octets = bytes(numbers)
# b'\xfe\xff\xff\xff\x00\x00\x01\x00\x02\x00'
-
使用缓冲类对象创建
bytes或bytearray对象时,始终复制源对象中的字节序列。与之相反,memoryview对象允许在二进制数据结构之间共享内存。 -
memoryview对象的切片是一个新memoryview对象,而且不会
复制字节序列 -
如果使用
mmap模块把图像打开为内存映射文件,那么会复制少量字节
4.2 编码和解码
-
某些编码(如
ASCII和多字节的GB2312)不能表示所有Unicode字符 -
UTF 编码的设计目的就是处理每一个
Unicode码位 -
典型编码:
- latin1(即 iso8859_1):一种重要的编码,是其他编码的基础,例如 cp1252 和Unicode(注意,latin1 与 cp1252 的字节值是一样的,甚至连码位也相同)。
- cp1252:Microsoft 制定的 latin1 超集,添加了有用的符号,例如弯引号和€(欧元);有些 Windows 应用把它称为“ANSI”,但它并不是 ANSI 标准。
- cp437:IBM PC 最初的字符集,包含框图符号。与后来出现的 latin1 不兼容。
- gb2312:用于编码简体中文的陈旧标准;这是亚洲语言中使用较广泛的多字节编码之一。
- utf-8:目前 Web 中最常见的 8 位编码;与 ASCII 兼容(纯 ASCII 文本是有效的 UTF-8 文本)。
- utf-16le:UTF-16 的 16 位编码方案的一种形式;所有 UTF-16 支持通过转义序列(称为“代理对”,surrogate pair)表示超过 U+FFFF 的码位。
-
UnicodeEncodeError:多数非 UTF 编解码器只能处理 Unicode 字符的一小部分子集。把文本转换成字节序列时,如果目标编码中没有定义某个字符,那就会抛出
UnicodeEncodeError 异常,除非把 errors 参数传给编码方法或函数,对错误进行特殊处理。无法编码时:
error='ignore'处理方式悄无声息地跳过无法编码的字符;这样做通常很是不妥。- 编码时指定
error='replace',把无法编码的字符替换成 '?';数据损坏了,但是用户知道出了问题。 error='xmlcharrefreplace'把无法编码的字符替换成 XML 实体。- 编解码器的错误处理方式是可扩展的。你可以为 errors 参数注册额外的字符串,方法是把一个名称和一个错误处理函数传给
codecs.register_error函数。
-
UnicodeDecodeError:把二进制序列转换成文本时,遇到无法转换的字节序列时会抛出UnicodeDecodeError;另一方面,很多陈旧的 8 位编码——如 'cp1252'、'iso8859_1' 和'koi8_r'——能解码任何字节序列流而不抛出错误,例如随机噪声。因此,如果程序使用错误的 8 位编码,解码过程悄无声息,而得到的是无用输出。 -
乱码字符称为鬼符(gremlin)或 mojibake(文字化け,“变形文本”的日文)。
-
使用预期之外的编码加载模块时抛出的SyntaxError
- Python 3 为所有平台设置的默认编码都是 UTF-8
- Python 3 允许在源码中使用非 ASCII 标识符
-
Chardet:识别所支持的30中编码。解决问题:如何找出字节序列的编码? -
二进制序列编码文本通常不会明确指明自己的编码,但是 UTF 格式可以在文本内容的开头添加一个字节序标记。
-
BOM:字节序标记,byte-order-mark,指明编码时使用 Intel CPU 的小字节序
-
在小字节序设备中,各个码位的最低有效字节在前面:字母 'E' 的码位是 U+0045(十进制数 69),在字节偏移的第 2 位和第 3 位编码为 69 和0。
-
在大字节序 CPU 中,编码顺序是相反的;'E' 编码为 0 和 69。
-
为了避免混淆,UTF-16 编码在要编码的文本前面加上特殊的不可见字符 ZERO WIDTH NO-BREAK SPACE(U+FEFF)。在小字节序系统中,这个字符编码为 b'\xff\xfe'(十进制数 255, 254)。因为按照设计,U+FFFE 字符不存在,在小字节序编码中,字节序列 b'\xff\xfe' 必定是 ZERO WIDTH NO-BREAK SPACE,所以编解码器知道该用哪个字节
序。 -
UTF-16 有两个变种:UTF-16LE,显式指明使用小字节序;UTF-16BE,显式指明使用大字节序。如果使用这两个变种,不会生成 BOM。
-
与字节序有关的问题只对一个字(word)占多个字节的编码(如 UTF-16 和 UTF-32)有影响。UTF-8 的一大优势是,不管设备使用哪种字节序,生成的字节序列始终一致,因此不需要 BOM。
-
尽管如此,某些Windows 应用(尤其是 Notepad)依然会在 UTF-8 编码的文件中添加
BOM;而且,Excel 会根据有没有 BOM 确定文件是不是 UTF-8 编码,否则,它假设内容使用 Windows 代码页(codepage)编码。UTF-8 编码的 U+FEFF 字符是一个三字节序列:b'\xef\xbb\xbf'。因此,如果文件以这三个字节开头,有可能是带有 BOM 的 UTF-8 文件。然而,Python 不会因为文件以 b'\xef\xbb\xbf' 开头就自动假定它是 UTF-8编码的。
4.3 处理文本文件
-
处理文本的最佳实践是 Unicode三明治 。
- 要尽早把输入(例如读取文件时)的字节序列解码成字符串。
- 在程序的业务逻辑中只能处理字符串对象。在其他处理过程中,一定不能编码或解码。
- 对输出来说,则要尽量晚地把字符串编码成字节序列。

-
如果打开文件是为了写入,但是没有指定编码参数,会使用区域设置中的默认编码,而且使用那个编码也能正确读取文件。
-
如果脚本要生成文件,而字节的内容取决于平台或同一平台中的区域设置,那么就可能导致兼容问题。
-
探索编码默认值
import sys, locale expressions = """ locale.getpreferredencoding() type(my_file) my_file.encoding sys.stdout.isatty() sys.stdout.encoding sys.stdin.isatty() sys.stdin.encoding sys.stderr.isatty() sys.stderr.encoding sys.getdefaultencoding() sys.getfilesystemencoding() """ my_file = open('dummy', 'w') for expression in expressions.split(): value = eval(expression) print(expression.rjust(30), '->', repr(value))输出:
locale.getpreferredencoding() -> 'cp936' type(my_file) -> <class '_io.TextIOWrapper'> my_file.encoding -> 'cp936' sys.stdout.isatty() -> False sys.stdout.encoding -> 'UTF-8' sys.stdin.isatty() -> False sys.stdin.encoding -> 'cp936' sys.stderr.isatty() -> False sys.stderr.encoding -> 'UTF-8' sys.getdefaultencoding() -> 'utf-8' sys.getfilesystemencoding() -> 'utf-8' -
如果打开文件时没有指定
encoding参数,默认值由locale.getpreferredencoding()提供 -
如果设定了
PYTHONIOENCODING环境变量,sys.stdout/stdin/stderr的编码使用设定的值;否则,继承自所在的控制台;如果输入/输出重定向到文件,则由locale.getpreferredencoding()定义 -
Python在二进制数据和字符串之间转换时,内部使用
sys.getdefaultencoding()获得的编码;Python3很少如此,但仍有发生。这个设置不能修改。 -
sys.getfilesystemencoding()用于编解码文件名(不是文件内容)。把字符串参数作为文件名传给open()函数时就会使用它;如果传入的文件名参数是字节序列,那就不经改动直接传给 OS API。
4.4 规范化Unicode字符串
-
因为 Unicode 有组合字符(变音符号和附加到前一个字符上的记号,打印时作为一个整体),所以字符串比较起来很复杂。
s1 = 'café' s2 = 'cafe\u0301' s1, s2 len(s1), len(s2) s1 == s2 # ('café', 'café') # (4, 5) # False -
在Unicode 标准中,'é' 和 'e\u0301' 这样的序列叫“标准等价物”(canonical equivalent),应用程序应该把它们视作相同的字符。但是,Python 看到的是不同的码位序列,因此判定二者不相等。
-
这个问题的解决方案是使用
unicodedata.normalize函数提供的Unicode 规范化。这个函数的第一个参数是这 4 个字符串中的一个:'NFC'、'NFD'、'NFKC' 和 'NFKD'。from unicodedata import normalize len(normalize('NFC', s1)), len(normalize('NFC', s3)) # (4, 4) len(normalize('NFD', s1)), len(normalize('NFD', s3)) # (5, 5) normalize('NFC', s1) == normalize('NFC', s2) # True normalize('NFD', s1) == normalize('NFD', s3) # True -
西方键盘通常能输出组合字符,因此用户输入的文本默认是 NFC 形式。不过,安全起见,保存文本之前,最好使用
normalize('NFC', user_text)清洗字符串。 -
NFC 也是 W3C 的“Character Model for the World Wide Web: String Matching and Searching”规范推荐的规范化形式。
-
使用 NFC 时,有些单字符会被规范成另一个单字符。这两个字符在视觉上是一样的,但是比较时并不相等,因此要规范化,防止出现意外。
-
在另外两个规范化形式(NFKC 和 NFKD)的首字母缩略词中,字母 K 表示 “compatibility”(兼容性)。这两种是较严格的规范化形式,对“兼容字符”有影响。虽然 Unicode 的目标是为各个字符提供 “规范的” 码位,但是为了兼容现有的标准,有些字符会出现多次。
微符号是一个 “兼容字符”。
-
使用 NFKC 和 NFKD 规范化形式时要小心,而且只能在特殊情况中使用,例如搜索和索引,而不能用于持久存储,因为这两种转换会导致数据损失。
-
大小写折叠:
str.casefold(),就是把所有文本变成小写,再做些其他转换,与str.lower()基本一致,但是存在例外:微符号 'μ' 会变成小写的希腊字母“μ”(在多数字体中二者看起来一样);德语 Eszett(“sharp s”,ß)会变成“ss” -
去掉变音符号的优势:
- 搜索方便:人们有时很懒,或者不知道怎么正确使用变音符号,而且拼写规则会随时间变化,因此实际语言中的重音经常变来变去。
- URL可读性:去掉变音符号还能让 URL 更易于阅读,至少对拉丁语系语言是如此。
-
变音符号对排序有影响的情况很少发生,只有两个词之间唯有变音符号不同时才有影响。此时,带有变音符号的词排在常规词的后面。
-
在 Python 中,非 ASCII 文本的标准排序方式是使用
locale.strxfrm
函数,根据 locale 模块的文档,这个函数会“把字符串转换成适合所在区域进行比较的形式”。 -
PyUCA:Unicode 排序算法(Unicode Collation Algorithm,UCA)的纯 Python 实现。PyUCA 没有考虑区域设置。如果想定制排序方式,可以把自定义的排序表路径传给 Collator() 构造方法。PyUCA 默认使用项目自带的
allkeys.txt。import pyuca coll = pyuca.Collator() fruits = ['caju', 'atemoia', 'cajá', 'açaí', 'acerola'] sorted_fruits = sorted(fruits, key=coll.sort_key) sorted_fruits -
Unicode 标准提供了一个完整的数据库(许多格式化的文本文件),不仅包括码位与字符名称之间的映射,还有各个字符的元数据,以及字符之间的关系。
Unicode 数据库记录了字符是否可以打印、是不是字母、是不是数字,或者是不是其他数值符号。unicodedata 模块中有几个函数用于获取字符的元数据。例如,字符在标准中的官方名称是不是组合字符(如结合波形符构成的变音符号等),以及符号对应的人类可读数值(不是码位)。
-
import unicodedata import re re_digit = re.compile(r'\d') sample = '1\xbc\xb2\u0969\u136b\u216b\u2466\u2480\u3285' for char in sample: print( 'U+%04x' % ord(char), char.center(6), 're_dig' if re_digit.match(char) else '-', 'isdig' if char.isdigit() else '-', 'isnum' if char.isnumeric() else '-', format(unicodedata.numeric(char), '5.2f'), unicodedata.name(char), sep='\t' )
4.5 支持字符串和字节序列的双模式API
-
可以使用正则表达式搜索字符串和字节序列,但是在后一种情况中,ASCII 范围外的字节不会当成数字和组成单词的字母。
- 字符串模式 r'\d+' 能匹配泰米尔数字和 ASCII 数字。
- 字节序列模式 rb'\d+' 只能匹配 ASCII 字节中的数字。
- 字符串模式 r'\w+' 能匹配字母、上标、泰米尔数字和 ASCII 数字。
- 字节序列模式 rb'\w+' 只能匹配 ASCII 字节中的字母和数字。
-
字符串正则表达式有个 re.ASCII 标志,它让\w、\W、\b、\B、\d、\D、\s 和 \S 只匹配 ASCII 字符。
-
为了便于手动处理字符串或字节序列形式的文件名或路径名,os 模块提供了特殊的编码和解码函数。
-
fsencode(filename):如果 filename 是 str 类型(此外还可能是 bytes 类型),使用sys.getfilesystemencoding()返回的编解码器把 filename 编码成字节序列;否则,返回未经修改的 filename 字节序列。 -
fsdecode(filename):如果 filename 是 bytes 类型(此外还可能是 str 类型),使用sys.getfilesystemencoding()返回的编解码器把 filename 解码成字符串;否则,返回未经修改的 filename 字符串。 -
surrogateescape:在 Unix 衍生平台中,这些函数使用 surrogateescape 错误处理方式以避免遇到意外字节序列时卡住。Windows 使用的错误处理方式是 strict。这种错误处理方式会把每个无法解码的字节替换成 Unicode 中 U+DC00 到 U+DCFF 之间的码位(Unicode 标准把这些码位称为“Low Surrogate Area”),这些码位是保留的,没有分配字符,供应用程序内部使用。编码时,这些码位会转换成被替换的字节值。
-
在 Python 3.3 之前,编译 CPython 时可以配置在内存中使用 16 位或 32 位存储各个码位。16 位是“窄构建”(narrow build),32 位是“宽构建”(wide build)。如果想知道用的是哪个,要查看
sys.maxunicode的值:65535 表示“窄构建”,不能透明地处理U+FFFF 以上的码位。“宽构建”没有这个限制,但是消耗的内存更多:每个字符占 4 个字节,就算是中文象形文字的码位大多数也只占 2 个字节。这两种构建没有高下之分,应该根据自己的需求选择。 -
灵活的字符串表述类似于 Python 3 对 int 类型的处理方式:如果一个整数在一个机器字中放得下,那就存储在一个机器字中;否则解释器切换成变长表述,类似于 Python 2 中的 long 类型。
-
5. 一等函数
- 在 Python 中,函数是一等对象。一等对象的定义:
- 在运行时创建
- 能赋值给变量或数据结构中的元素
- 能作为参数传给函数
- 能作为函数的返回结果
- 人们经常将“把函数视作一等对象”简称为“一等函数”。这样说并不完美,似乎表明这是函数中的特殊群体。在 Python 中,所有函数都是一等对象。
5.1 把函数视作对象
-
__doc__是函数对象众多属性中的一个,显示函数的备注 -
help(f):输出的文本来自函数对象的__doc__属性 -
函数对象的 一等 本性:
- 把 factorial 函数赋值给变量 fact,然后通过变量名调用
- 把它作为参数传给map 函数,返回一个可迭代对象,里面的元素是把第一个参数
(一个函数)应用到第二个参数(一个可迭代对象)中各个元素上得到的结果
-
高阶函数:higher-order function,接受函数为参数,或者把函数作为结果返回的函数
这样的函数例如:map,sorted,reduce,filter,apply(已移除)
map、filter 和 reduce 这三个高阶函数还能见到,不过多数使用场景下都有更好的替代品。
-
列表推导 或 生成器表达式 具有map和filter两个函数的功能,且更易于阅读
list(map(fact, range(6))) [fact(n) for n in range(6)]list(map(factorial, filter(lambda n: n % 2, range(6)))) [fact(n) for n in range(7) if n % 2 != 0] -
reduce 是内置函数,最常用于求和,现在最好使用内置的 sum 函数,在可读性和性能方面,这是一项重大改善
sum 和 reduce 的通用思想是把某个操作连续应用到序列的元素上,累计之前的结果,把一系列值归约成一个值。
from functools import reduce from operator import add reduce(add, range(100)) sum(range(100)) -
all 和 any 也是内置的归约函数
all(iterable):如果 iterable 的每个元素都是真值,返回 True;all([])返回True。any(iterable):只要 iterable 中有元素是真值,就返回 True;any([])返回False。
-
-
匿名函数:lambda 关键字在 Python 表达式内创建匿名函数。
lambda 句法只是语法糖:与 def 语句一样,lambda 表达式会创建函数对象。这是 Python 中几种可调用对象的一种。
-
调用类的时候会运行类的
__new__方法创建一个实例,然后运行__init__方法,初始化实例,最后把实例返回给调用方。- 因为Python没有new运算符,所以调用类相当于调用函数。
- 如果类定义了
__call__方法,那么它的实例可以作为函数调用。
-
生成器函数:使用
yield关键字的函数或方法。调用生成器函数返回的是生成器对象。(生成器函数还可以作为协程) -
Python 中有各种各样可调用的类型,因此判断对象能否调用,最安全的方法是使用内置的
callable()函数[callable(obj) for obj in (abs, str, 13)] # [True, True, False] -
任何 Python 对象都可以表现得像函数。为此,只需实现实例方法
__call__ -
函数内省:除了
__doc__,函数对象还有其他属性:dir(factorial)['__annotations__', '__call__', '__class__', '__closure__', '__code__', '__defaults__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__get__', '__getattribute__', '__globals__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__kwdefaults__', '__le__', '__lt__', '__module__', '__name__', '__ne__', '__new__', '__qualname__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__']-
与用户定义的常规类一样,函数使用
__dict__属性存储赋予它的用户属性。这相当于一种基本形式的注解。 -
列出 常规对象没有 而 函数对象有 的属性:
class C: pass obj = C() def func(): pass str(sorted(set(dir(func)) - set(dir(obj))))['__annotations__', '__call__', '__closure__', '__code__', '__defaults__', '__get__', '__globals__', '__kwdefaults__', '__name__', '__qualname__'] -
名称 类型 说明 __annotations__dict 参数和返回值的注解 __call__method-wrapper 实现()运算符;即可调用对象协议 __closure__tuple 函数闭包,即自由变量的绑定(通常是None) __code__code 编译成字节码的函数元数据和函数定义体 __defaults__tuple 形式参数的默认值 __get__method-wrapper 实现只读描述符协议 __globals__dict 函数所在模块中的全局变量 __kwdefaults__dict 仅限关键字形式参数的默认值 __name__str 函数名称 __qualname__str 函数的限定名称,如 Random.choice
-
5.2 函数的参数和注解
-
仅限关键字参数:keyword-only argument,调用函数时使用
*和**展开可迭代对象,映射到单个参数。 -
在传参的时候,将字典加上
**作为参数传递,实现的是字典中所有元素作为单个参数传入,同名的键回绑定到对应的具名参数上,余下的则被**attrs捕获。 -
仅限关键字参数:它一定不会捕获未命名的定位参数。
此种参数只能由关键字提供,绝对不会被位置参数自动填充。
- 定义函数时若想指定仅限关键字参数,要把它们放到前面有
*的参数后面。 - 如果不想支持数量不定的定位参数,但是想支持仅限关键字参数,在签名中放
一个* - 允许常规参数出现在可变参数之后:此时这个常规参数就是一个仅限关键字参数。强制性的,它只能通过关键字传参
- 仅限关键字参数不需要有默认值, 由于Python需要将所有的参数都绑定一个值,而且将值绑定到关键字参数的唯一方法是通过这个关键字,因此这种参数是 需要关键字的参数 。所以这些参数必须通过调用方提供,且必须通过关键字提供值。
- 语法上的更改是允许省略可变参数的参数名。这意味着对于一个有仅限关键字参数的函数来说,它不会再接受一个可变参数。
- 定义函数时若想指定仅限关键字参数,要把它们放到前面有
-
获取关于参数的信息
-
使用HTTP微框架Bobo中有个使用函数内省的好例子。
启动方式:
bobo -f hello.pyimport bobo @bobo.query('/') def hello(person): return "Hello %s" % person
-
函数对象有个
__defaults__属性,它的值是一个元组,里面保存着定位参数和关键字参数的默认值。仅限关键字参数的默认值在__kwdefaults__属性中。然而,参数的名称在__code__属性中,它的值是一个 code 对象引用,自身也有很多属性。
-
-
inspect.signature函数返回一个inspect.Signature对象,它有一个parameters属性,这是一个有序映射,把参数名和inspect.Parameter对象对应起来。各个Parameter属性也有自己的属性,例如name、default和kind。特殊的inspect._empty值表示没有默认值,考虑到None是有效的默认值(也经常这么做),而且这么做是合理的。kind的属性的值,为_ParameterKind类中的5个值之一:POSITIONAL_OR_KEYWORD:可以通过定位参数和关键字参数传入的形参(多数 Python 函数的参数属于此类)。VAR_POSITIONAL:定位参数元组。VAR_KEYWORD:关键字参数元组。KEYWORD_ONLY:仅限关键字参数(Python 3 新增)。POSITIONAL_ONLY:仅限定位参数;目前,Python 声明函数的句法不支持,但是有些使用 C 语言实现且不接受关键字参数的函数(如 divmod)支持。
-
函数注解
- 函数声明中的各个参数可以在 : 之后增加注解表达式。如果参数有默认值,注解放在参数名和 = 号之间。
- 如果想注解返回值,在 ) 和函数声明末尾的 : 之间添加 -> 和一个表达式。那个表达式可以是任何类型。
- 注解中最常用的类型是类(如 str 或 int)和字符串(如 'int > 0')
- 注解不会做任何处理,只是存储在函数的
__annotations__属性中 - Python 对注解所做的唯一的事情是,把它们存储在函数的
__annotations__属性里。仅此而已,Python 不做检查、不做强制、不做验证,什么操作都不做。换句话说,注解对 Python 解释器没有任何意义。 - 函数注解的最大影响或许不是让 Bobo 等框架自动设置,而是为 IDE 和
lint 程序等工具中的静态类型检查功能提供额外的类型信息。
5.3 支持函数式编程的包
-
operator模块
-
使用reduce函数和一个匿名函数计算阶乘
def fact(n): return reduce(lambda a,b: a*b, range(1, n+1)) -
operator 模块为多个算术运算符提供了对应的函数,从而避免编写
lambda a, b: a*b这种平凡的匿名函数def fact2(n): return reduce(mul, range(1, n+1)) -
使用 itemgetter 排序一个元组列表
-
itemgetter 使用
[]运算符,因此它不仅支持序列,还支持映射和任何实现__getitem__方法的类。 -
itemgetter(1)的作用与lambda fields:fields[1]一样
metro_data = [ ('Tokyo', 'JP', 36.933, (35.689722, 139.691667)), ('Delhi NCR', 'IN', 21.935, (28.613889, 77.208889)), ('Mexico City', 'MX', 20.142, (19.433333, -99.133333)), ('New York-Newark', 'US', 20.104, (40.808611, -74.020386)), ('Sao Paulo', 'BR', 19.649, (-23.547778, -46.635833)), ] from operator import itemgetter for city in sorted(metro_data, key=itemgetter(2)): print(city) -
-
如果把多个参数传给 itemgetter,它构建的函数会返回提取的值构成的元组:
cc_name = itemgetter(1, 0) for city in metro_data: print(cc_name(city)) -
attrgetter 与 itemgetter 作用类似,它创建的函数根据名称提取对象的属性
from collections import namedtuple LatLong = namedtuple('LatLong', 'lat long') Metropolis = namedtuple('Metropolis', 'name cc pop coord') metro_areas = [Metropolis(name, cc, pop, LatLong(lat, long)) for name, cc, pop, (lat, long) in metro_data] metro_areas metro_areas[0].coord.lat from operator import attrgetter name_lat = attrgetter('name', 'coord.lat') for city in sorted(metro_areas, key=attrgetter('coord.lat')): print(name_lat(city)) -
attrgetter 与 itemgetter 个人总结:
- itemgetter:偏向于数组的切片操作
- attrgetter:偏向于类的属性获取操作
-
methodcaller 的作用与 attrgetter 和 itemgetter 类似,它会自行创建函数,methodcaller 创建的函数会在对象上调用参数指定的方法:
from operator import methodcaller s = 'The tiem has come' upcase = methodcaller('upper') upcase(s) hiphenate = methodcaller('replace', ' ', '-') hiphenate(s) -
methodcaller还可以冻结某些参数,也就是部分应用(partial application),这与
functoosl.partial函数的作用类似。
-
-
使用
functools.partial冻结参数-
functools.partial 这个高阶函数用于部分应用一个函数。部分应用是指,基于一个函数创建一个新的可调用对象,把原函数的某些参数固定。使用这个函数可以把接受一个或多个参数的函数改编成需要回调的API,这样参数更少。
from operator import mul from functools import partial triple = partial(mul, 3) triple(7) list(map(triple, range(1, 10))) -
固定nfc函数,标准化字符串编码处理
import unicodedata, functools nfc = functools.partial(unicodedata.normalize, 'NFC') s1 = 'café' s2 = 'cafe\u0301' s1, s2 s1 == s2 nfc(s1) == nfc(s2) -
functools.partialmethod函数的作用与partial一样,不过是用于处理方法的。- 对于类方法,partial就没办法了,所以新引用了
partialmethod - 参考链接
- Python functools 模块
- 对于类方法,partial就没办法了,所以新引用了
-
functools 模块中的 lru_cache 函数令人印象深刻,它会做备忘(memoization),这是一种自动优化措施,它会存储耗时的函数调用结果,避免重新计算。
-
6. 使用一等函数实现涉及模式
-
实现“策略” 模式:
- 经典“策略”模式
- 使用函数实现“策略”模式
-
策略对象通常是很好的享元:
- 享元:flyweight,享元是可共享的对象,可以同时再多个上下文中使用
- 可以避免运行时消耗
- 函数比用户定义的类的实例轻量,而且无需使用“享元”模式,因为各个策略函数在 Python 编译模块时只会创建一次。普通的函数也是“可共享的对象,可以同时在多个上下文中使用”。
-
在 Python 中,模块也是一等对象,而且标准库提供了几个处理模块的函数
globals():返回一个字典,表示当前的全局符号表。这个符号表始终针对当前模块(对函数或方法来说,是指定义它们的模块,而不是调用它们的模
块)。
-
命令模式
- 可以通过把函数作为参数传递而简化。
- “命令”模式的目的是解耦调用操作的对象(调用者)和提供实现的对象(接收者)。
- 这个模式的做法是,在二者之间放一个 Command 对象,让它实现只有一个方法(execute)的接口,调用接收者中的方法执行所需的操作。这样,调用者无需了解接收者的接口,而且不同的接收者可以适应不同的 Command 子类。调用者有一个具体的命令,通过调用 execute 方法执行。
class MacroCommand: """一个执行一组命令的命令""" def __init__(self, commands): self.commands = list(commands) def __call__(self): for command in self.commands: command() -
复习
- 一等对象:指的是满足下述条件的程序实体
- 在运行时创建
- 能赋值给变量或数据结构中的元素
- 能作为参数传给函数
- 能作为函数的返回结果
- 整数、字符串和字典都是一等对象。在面向对象编程中,函数也是对象,并满足以上条件,所以函数也是一等对象,称为"一等函数"
- 普通函数 & 高阶函数:接受函数为参数的函数为高阶函数,其余为普通函数
- 《设计模式:可复用面向对象软件的基础》书中的两个设计原则:
- 对接口编程,而不是对实现编程
- 优先使用对象组合,而不是类继承
- 一等对象:指的是满足下述条件的程序实体
7. 函数装饰器和闭包
- 函数装饰器用于在源码中“标记”函数,以某种方式增强函数的行为。这是一项强大的功能,但是若想掌握,必须理解闭包。
- 除了在装饰器中有用处之外,闭包还是回调式异步编程和函数式编程风格的基础。
7.1 装饰器基础
-
装饰器是可调用的对象,其参数是另一个函数(被装饰的函数)。装饰器可能会处理被装饰的函数,然后把它返回,或者将其替换成另一个函数或可调用对象。
下述两个代码等价:
-
装饰器
@decorate def target(): print('running target()') -
另一种写法
def target(): print('running target()') target = decorate(target)
-
-
两种写法的最终结果一样:上述两个代码片段执行完毕后得到的 target 不一定是原来那个 target 函数,而是 decorate(target) 返回的函数。
-
装饰器通常把函数替换成另一个函数
def deco(func): def inner(): print('running inner()') return inner @deco def target(): print('running target()') target() # running inner() target # <function __main__.deco.<locals>.inner()> -
严格来说,装饰器只是语法糖。
-
装饰器的特性:
- 一大特性是,能把被装饰的函数替换成其他函数。
- 第二个特性是,装饰器在加载模块时立即执行。
-
Python何时执行装饰器:在被装饰的函数定义之后立即运行
registry = [] def register(func): print('running register(%s)' % func) registry.append(func) return func @register def f1(): print('running f1()') @register def f2(): print('running f2()') def f3(): print('running f3()') def main(): print('running main()') print('registry ->', registry) f1() f2() f3() if __name__ == '__main__': main()running register(<function f1 at 0x00000246ABFAC708>) running register(<function f2 at 0x00000246AC0D4CA8>) running main() registry -> [<function f1 at 0x00000246ABFAC708>, <function f2 at 0x00000246AC0D4CA8>] running f1() running f2() running f3() -
如果导入上述代码:
import registration,函数的装饰器再导入模块时立即执行,而被装饰的函数只再明确调用时运行。 -
装饰器在真实代码中的常用方式:
- 装饰器通常在一个模块中定义,然后应用到其他模块中的函数上
- 大多数装饰器会在内部定义函数,然后将其返回
-
register 装饰器原封不动地返回被装饰的函数,但是这种技术并非没有用处。
- 很多 Python Web 框架使用这样的装饰器把函数添加到某种中央注册处,例如把 URL 模式映射到生成 HTTP 响应的函数上的注册处。
- 这种注册装饰器可能会也可能不会修改被装饰的函数。
-
使用装饰器改进“策略”模式
- 多数装饰器会修改被装饰的函数
- 通常,它们会定义一个内部函数,然后将其返回,替换被装饰的函数
- 使用内部函数的代码几乎都要靠闭包才能正确运作
7.2 闭包
-
变量作用域规则
- Python 不要求声明变量,但是假定在函数定义体中赋值的变量是局部变量
- 如果在函数中赋值时想让解释器把 b 当成全局变量,要使用
global声明 - 通过
from dis import dis查看程序的字节码
-
假如有个名为 avg 的函数,它的作用是计算不断增加的系列值的均值;例如,整个历史中某个商品的平均收盘价。每天都会增加新价格,因此平均值要考虑至目前为止所有的价格
-
avg使用方法:
>>> avg(10) 10.0 >>> avg(11) 10.5 >>> avg(12) 11.0 -
实现方式:
-
计算移动平均的类
class Averager(): def __init__(self): self.series = [] def __call__(self, new_value): self.series.append(new_value) total = sum(self.series) return total/len(self.series) -
计算移动平均值的高阶函数
def make_averager(): series = [] def averager(new_value): series.append(new_value) total = sum(series) return total/len(series) return averager -
注意:这两个示例有共通之处:调用
Averager()或make_averager()得到一个可调用对象 avg,它会更新历史值,然后计算当前均值-
在
averager函数中,series时自由变量(free variable),这是一个技术术语,指:未在本地作用域中绑定的变量
-
averager 的闭包延伸到那个函数的作用域之外,包含自由变量 series 的绑定
-
审查返回的 averager 对象,我们发现 Python 在
__code__属性(表示编译后的函数定义体)中保存局部变量和自由变量的名称avg.__code__.co_varnames # ('new_value', 'total') avg.__code__.co_freevars # ('series',) -
series 的绑定在返回的 avg 函数的
__closure__属性中。avg.__closure__中的各个元素对应于avg.__code__.co_freevars中的一个名称。这些元素是 cell 对象,有个cell_contents属性,保存着真正的值avg.__closure__ # (<cell at 0x00000246AC517108: list object at 0x00000246AC124A88>,) avg.__closure__[0].cell_contents # [10, 11, 12]
-
-
-
-
闭包是一种函数,它会保留定义函数时存在的自由变量的绑定,这样调用函数时,虽然定义作用域不可用了,但是仍能使用那些绑定。
-
注意,只有嵌套在其他函数中的函数才可能需要处理不在全局作用域中的外部变量。
-
nonlocal声明
-
上面的操作时引入了list(可变对象) series,用来保存每一次的值,然后这个series 是 所谓的 自由变量
-
但是对数字、字符串、元组等不可变类型来说,只能读取,不能更新,就不是所谓的 自由变量了,因此不会保存在闭包中。
-
nonlocal声明可以把变量标记为自由变量,即使在函数中为变量赋予新值了,也会变成自由变量。 -
如果为
nonlocal声明的变量赋予新值,闭包中保存的绑定会更新。 -
优化后的闭包
def make_averager(): count = 0 total = 0 def averager(new_value): nonlocal count, total count += 1 total += new_value return total/count return averager -
nonlocal是python3的特性,在python2中需要把内部函数需要修改的变量存储为可变对象(如字典或简单的实例)的元素或属性,并且把那个对象绑定给一个自由变量。
-
7.3 装饰器
-
实现一个简单的装饰器:定义了一个装饰器,它会在每次调用被装饰的函数时计时,然后把经过的时间、传入的参数和调用的结果打印出来。
import time def clock(func): def clocked(*args): # 记录初始时间t0 t0 = time.perf_counter() # 调用原来的 factorial 函数,保存结果 result = func(*args) # 计算经过的时间 elapsed = time.perf_counter() - t0 # 格式化收集的数据,然后打印出来 name = func.__name__ arg_str = ', '.join(repr(arg) for arg in args) print('[%0.8fs] %s(%s) -> %r' % (elapsed, name, arg_str, result)) # 返回第 2 步保存的结果 return result return clocked @clock def snooze(seconds): time.sleep(seconds) @clock def factorial(n): return 1 if n < 2 else n * factorial(n - 1) if __name__ == '__main__': print('*' * 40, 'Calling snooze(.123)') snooze(.123) print('*' * 40, 'Calling factorial(6)') print('6! = ', factorial(6))**************************************** Calling snooze(.123) [0.12354480s] snooze(0.123) -> None **************************************** Calling factorial(6) [0.00000040s] factorial(1) -> 1 [0.00003500s] factorial(2) -> 2 [0.00004590s] factorial(3) -> 6 [0.00005500s] factorial(4) -> 24 [0.00006390s] factorial(5) -> 120 [0.00007470s] factorial(6) -> 720 6! = 720 -
这是装饰器的典型行为:把被装饰的函数替换成新函数,二者接受相同的参数,而且(通常)返回被装饰的函数本该返回的值,同时还会做些额外操作。
装饰器:动态地给一个对象添加一些额外的职责
——《设计模式:可复用面向对象软件的基础》
-
上述实现的clock装饰器有几个缺点:
- 不支持关键字参数
- 遮盖了被装饰函数的
__name__和__doc__属性
-
使用
functools.wraps装饰器把相关属性从func复制到clocked中,同时还可以正确处理关键字参数import time from functools import wraps def clock(func): @wraps(func) def clocked(*args, **kwargs): t0 = time.perf_counter() result = func(*args, **kwargs) elapsed = time.perf_counter() - t0 name = func.__name__ arg_lst = [] if args: arg_lst.append(', '.join(repr(arg) for arg in args)) if kwargs: pairs = ['%s=%r' % (k, w) for k, w in sorted(kwargs.items())] arg_lst.append(', '.join(pairs)) arg_str = ', '.join(arg_lst) print('[%0.8fs] %s(%s) -> %r' % (elapsed, name, arg_str, result)) return result return clocked -
标准库中的装饰器
- python 内置了三个用于装饰方法的函数:property、classmethod、staticmethod
- functools:wraps、lru_cache、singledispatch
-
使用
functools.lru_cache做备忘,memoization,这是一项优化技术,它把耗时的函数的结果保存起来,避免传入相同的参数时重复计算。- LRU:Least Recently Used,表明缓存不会无限制增长,一段时间不用的缓存条目会被扔掉。
- 注意,必须像常规函数哪一行调用
lru_cache:@functools.lru_cache(),这是因为lru_cache可以接受配置参数。 - 除了优化递归算法之外,
lru_cache在从Web中获取信息的应用中也能发挥巨大作用。
-
functools.lru_cache(maxsize=128, typed=False)- maxsize 参数指定存储多少个调用的结果。缓存满了之后,旧的结果会被扔掉,腾出空间。为了得到最佳性能,maxsize 应该设为 2 的幂。
- typed 参数如果设为 True,把不同参数类型得到的结果分开保存,即把通常认为相等的浮点数和整数参数(如 1 和 1.0)区分开。
- lru_cache 使用字典存储结果,而且键根据调用时传入的定位参数和关键字参数创建,所以被 lru_cache 装饰的函数,它的所有参数都必须是可散列的。
-
单分派泛函数
-
因为 Python 不支持重载方法或函数,所以我们不能使用不同的签名定义htmlize 的变体,也无法使用不同的方式处理不同的数据类型。
-
在Python 中,一种常见的做法是把 htmlize 变成一个分派函数,使用一串 if/elif/elif,调用专门的函数,如htmlize_str、htmlize_int,等等。这样不便于模块的用户扩展,还显得笨拙:时间一长,分派函数 htmlize 会变得很大,而且它与各个专门函数之间的耦合也很紧密。
-
functools.singledispatch装饰器可以把整体方案拆分成多个模块,甚至可以为你无法修改的类提供专门的函数。 -
使用
@singledispatch装饰的普通函数会变成泛函数(generic function):根据第一个参数的类型,以不同方式执行相同操作的一组函数。这才称得上是单分派。如果根据多个参数选择专门的函数,那就是多分派了。
-
singledispatch 创建一个自定义的htmlize.register 装饰器,把多个函数绑在一起组成一个泛函数
from functools import singledispatch from collections import abc import numbers import html @singledispatch def htmlize(obj): content = html.escape(repr(obj)) return '<pre>{}</pre>'.format(content) @htmlize.register(str) def _(text): content = html.escape(text).replace('\n', '<br>\n') return '<p>{0}</p>'.format(content) @htmlize.register(numbers.Integral) def _(n): return '<pre>{0} (0x{0:x})</pre>' @htmlize.register(tuple) @htmlize.register(abc.MutableSequence) def _(seq): inner = '</li>\n<li>'.join(htmlize(item) for item in seq) return '<ul>\n<li>' + inner + '</li>\n</ul>' -
numbers.Integral是int的虚拟超类 -
可以叠放多个
register装饰器,让同一个函数支持不同类型 -
只要可能,注册的专门函数应该处理抽象基类(如 numbers.Integral和 abc.MutableSequence),不要处理具体实现(如 int 和 list)。这样,代码支持的兼容类型更广泛。
-
使用抽象基类检查类型,可以让代码支持这些抽象基类现有和未来的具体子类或虚拟子类
-
@singledispatch不是为了把 Java 的那种方法重载带入Python -
在一个类中为同一个方法定义多个重载变体,比在一个函数中使用一长串 if/elif/elif/elif 块要更好。
-
但是这两种方案都有缺陷,因为它们让代码单元(类或函数)承担的职责太多。
-
@singledispath的优点是支持模块化扩展:各个模块可以为它支持的各个类型注册一个专门函数。 -
装饰器是函数,因此可以组合起来使用(即,可以在已经被装饰的函数上应用装饰器)
-
-
叠放装饰器
下述代码等价
@d1 @d2 def f(): print('f') f = d1(d2(f)) -
参数化装饰器
registry = set() def register(active=True): def decorate(func): print('running register(active=%s )->decorate(%s)' % (active, func)) if active: registry.add(func) else: registry.discard(func) return func return decorate @register(active=False) def f1(): print('running f1()') @register() def f2(): print('running f2()') def f3(): print('running f3()')- 这里decorate时装饰器,必须返回一个函数
- register是装饰器工厂函数,因此返回的是一个装饰器decorate
- 即使不传入参数,register也必须作为函数调用:
@register() - 如果不使用 @ 句法,那就要像常规函数那样使用 register;若想把 f 添加到 registry 中,则装饰 f 函数的句法是
register()(f);不想添加(或把它删除)的话,句法是register(active=False)(f)
-
参数化clock装饰器
import time DEFAULT_FMT = '[{elapsed:0.8f}s] {name}({args}) -> {result}' def clock(fmt=DEFAULT_FMT): def decorate(func): def clocked(*_args): t0 = time.time() _result = func(*_args) elapsed = time.time() - t0 name = func.__name__ args = ", ".join(repr(arg) for arg in _args) result = repr(_result) print(fmt.format(**locals())) return _result return clocked return decorate if __name__ == '__main__': @clock() def snooze(seconds): time.sleep(seconds) for i in range(3): snooze(.123)[0.12328148s] snooze(0.123) -> None [0.12369442s] snooze(0.123) -> None [0.12362432s] snooze(0.123) -> None- clock:参数化装饰器工厂函数
- decorate:真正的装饰器
- clocked:包装被装饰的函数
_result:被装饰函数返回的真正结果_args:clocked的参数,args用于显示的字符串- result:
_result的字符串表现形式,用于显示
-
装饰器的参数
@clock('{name}: {elapsed}s') def snooze(seconds): time.sleep(seconds) for i in range(3): snooze(.123)snooze: 0.12300252914428711s snooze: 0.12314867973327637s snooze: 0.1238546371459961s@clock('{name}({args}) dt={elapsed:0.3f}s') def snooze(seconds): time.sleep(seconds) for i in range(3): snooze(.123)snooze(0.123) dt=0.124s snooze(0.123) dt=0.123s snooze(0.123) dt=0.123s
8. 对象引用、可变性和垃圾回收
8.1 变量不是盒子
-
如果把变量想象为盒子,那么无法解释 Python 中的赋值;应该把变量视作便利贴
-
对引用式变量来说,说把变量分配给对象更合理
-
==运算符比较两个对象的值(对象中保存的数据),而is比较对象的标识 -
元组的相对不可变性:元组的不可变性其实是指
tuple数据结构的物理内容(即保存的引用)不可变,与引用的对象无关。元组里面有一个list,这个list就可以append,但是id还是不变。
这也是有些元组不可散列的原因。
-
str、bytes 和 array.array 等单一类型序列是扁平的,它们保存的不是引用,而是在连续的内存中保存数据本身(字符、字节和数字)。
-
浅复制(copy.copy)和深复制(copy.deepcopy)的区别:深复制中副本不共享内部对象的引用
8.2 函数的参数作为引用
-
不要使用可变类型作为参数的默认值
-
不可以默认值为类似于
[],因为如果不传参的话,这个[]就是类的内部变量,多个实例会共用这个变量 -
这也是为什么通常使用 None 作为接收可变值的参数的默认值的原因。
-
-
防御可变参数
- 类中的操作可能会修改传入类的可变参数
- 修正的方法:初始化时,把参数值的副本赋值给成员变量
8.3 del、垃圾回收和弱引用
注意,这一章节的一些代码要在cmd中才能实现,jupyterlab中的实验结果与书中给的结果不一致。
-
del 语句删除名称,而不是对象
-
del 命令可能会导致对象被当作垃圾回收,但是仅当删除的变量保存的是对象的最后一个引用,或者无法得到对象时。
-
重新绑定也可能会导致对象的引用数量归零,导致对象被销毁。
-
弱引用:正是因为有引用,对象才会在内存中存在。当对象的引用数量归零后,垃圾回收程序会把对象销毁。但是,有时需要引用对象,而不让对象存在的时间超过所需时间。这经常用在缓存中。
- 弱引用不会增加对象的引用数量。引用的目标对象称为所指对象(referent)。因此我们说,弱引用不会妨碍所指对象被当作垃圾回收。
- 弱引用在缓存应用中很有用,因为我们不想仅因为被缓存引用着而始终保存缓存对象。
-
weakref.ref 类其实是低层接口,供高级用途使用,多数程序最好使用 weakref 集合和 finalize。也就是说,应该使用
WeakKeyDictionary、WeakValueDictionary、WeakSet和finalize(在内部使用弱引用),不要自己动手创建并处理 weakref.ref 实例。 -
WeakValueDictionary
- WeakValueDictionary 类实现的是一种可变映射,里面的值是对象的弱引用。
- 被引用的对象在程序中的其他地方被当作垃圾回收后,对应的键会自动从 WeakValueDictionary 中删除。
- 因此,WeakValueDictionary 经常用于缓存。
-
与 WeakValueDictionary 对应的是 WeakKeyDictionary,后者的键是弱引用
-
WeakSet 类:保存元素弱引用的集合类。元素没有强引用时,集合会把它删除
- 如果一个类需要知道所有实例,一种好的方案是创建一个WeakSet 类型的类属性,保存实例的引用。
- 如果使用常规的 set,实例永远不会被垃圾回收,因为类中有实例的强引用,而类存在的时间与 Python 进程一样长,除非显式删除类。
-
弱引用的局限
- 不是每个 Python 对象都可以作为弱引用的目标(或称所指对象)。基本的 list 和 dict 实例不能作为所指对象,但是它们的子类可以
- set 实例可以作为所指对象
- 用户定义的类型也没问题
- 但是,int 和 tuple 实例不能作为弱引用的目标,甚至它们的子类也不行
- 这些局限基本上是 CPython 的实现细节,在其他 Python 解释器中情况可能不一样。这些局限是内部优化导致的结果
-
Python对不可变类型施加的把戏
-
对元组 t 来说,
t[:]不创建副本,而是返回同一个对象的引用。此外,tuple(t)获得的也是同一个元组的引用。(str、bytes 和 frozenset 实例也有这种行为)- frozenset 实例不是序列,因此不能使用
fs[:](fs 是一个 frozenset 实例),但是,fs.copy()具有相同的效果:返回同一个对象的引用,而不是创建一个副本
- frozenset 实例不是序列,因此不能使用
-
字符串字面量可能会创建共享的对象
s1 = 'ABC' s2 = 'ABC' s2 is s1 # True- 共享字符串字面量是一种优化措施,称为驻留(interning)。CPython 还会在小的整数上使用这个优化措施,防止重复创建“热门”数字
- CPython 不会驻留所有字符串和整数
-
-
杂谈
- java的
==运算符比较的是对象(不是基本类型)的引用,而不是对象的值。否则的话要用到.equals方法,如果调用方法的变量为null,会得到一个 空指针异常 - 在python中,
==比较对象的值,is比较引用 - 最重要的是,python支持重载运算发,
==能正确处理标准库中的所有对象,包括None,与java的null不同
- java的
9. 符合Python风格的对象
9.1 对象的表示形式
-
获取对象的字符串表示形式的标准方式
repr():开发者理解的方式返回对象的字符串表示形式str():用户理解的方式返回对象的字符串表示形式
-
在 Python 3 中,
__repr__、__str__和__format__都必须返回 Unicode 字符串(str 类型)。只有__bytes__方法应该返回字节序列(bytes 类型) -
定义
__iter__方法,把类的实例编程可迭代的对象,这样才能拆包。x, y = my_vector这一行也可以写成
yield self.x; yield self.y -
eval()函数用来执行一个字符串表达式,并返回表达式的值。 -
classmethod:第一个参数是类本身,最常见的用途是定义备选构造方法
-
staticmethod:第一个参数不是特殊的值,其实静态方法就是普通的函数,只是碰巧在类的定义体中,而不是在模块层定义
-
作者对staticmethod的态度是:”不是特别有用“,因为如果想定义不需要与类进行交互的函数,只需要在模块中定义就好了。
9.2 格式化显示
-
内置的
format()函数和str.format()方法把各个类型的格式化方式委托给相应的.__format__(format_spec)方法-
format(my_obj, format_spec)里的第二个参数 -
str.format()方法的格式字符串,{}里代换字段中冒号后面的部分
-
-
{0.mass:5.3e}这样的格式字符串其实包含两部分- 冒号左边的
.mass在代换字段句法中是字段名 - 冒号后面的
5.3e是格式说明符 - 格式说明符使用的表示法叫 格式规范微语言 ,Format Specification Mini-Language
- 冒号左边的
-
格式规范微语言为一些内置类型提供了专用的表示代码
- b 和 x 分别表示二进制和十六进制的 int 类型
- f 表示小数形式的 float 类型
- % 表示百分数形式
-
格式规范微语言是可扩展的,因为各个类可以自行决定如何解释format_spec 参数
-
如果类没有定义
__format__方法,从 object 继承的方法会返回str(my_object) -
在格式规范微语言中,整数使用的代码有
bcdoxXn,浮点数使用的代码有eEfFgGn%,字符串使用的代码有s -
使用两个前导下划线(尾部没有下划线,或者有一个下划线),把属性标记为私有的
-
@property装饰器把读值方法标记为属性 -
要想创建可散列的类型,不一定要实现特性,也不一定要保护实例属性。只需正确地实现
__hash__和__eq__方法即可 -
如果定义的类型有标量数值,可能还要实现
__int__和__float__方法(分别被int()和float()构造函数调用),以便在某些情况下用于强制转换类型。此外,还有用于支持内置的complex()构造函数的__complex__方法from array import array import math class Vector2d: typecode = 'd' def __init__(self, x, y): self.__x = float(x) self.__y = float(y) @property def x(self): return self.__x @property def y(self): return self.__y def __iter__(self): return (i for i in (self.x, self.y)) def __repr__(self): class_name = type(self).__name__ return '{}({!r}, {!r})'.format(class_name, *self) def __str__(self): return str(tuple(self)) def __bytes__(self): return (bytes([ord(self.typecode)]) + bytes(array(self.typecode, self))) def __eq__(self, other): return tuple(self) == tuple(other) def __abs__(self): return math.hypot(self.x, self.y) def __bool__(self): return bool(abs(self)) @classmethod def frombytes(cls, octets): typecode = chr(octets[0]) memv = memoryview(octets[1:]).cast(typecode) return cls(*memv) def angle(self): return math.atan2(self.y, self.x) def __hash__(self): return hash(self.x) ^ hash(self.y) def __format__(self, fmt_spec=''): if fmt_spec.endswith('p'): fmt_spec = fmt_spec[: -1] coords = (abs(self), self.angle()) outer_fmt = '<{}, {}>' else: coords = self outer_fmt = '({}, {})' components = (format(c, fmt_spec) for c in coords) return outer_fmt.format(*components)
9.3 Python的私有属性和受保护的属性
-
私有属性需要在前面加两根下划线,Python 会把属性名存入实例的
__dict__属性中,而且会在前面加上一个下划线和类名- 父类:_Dog__mood
- 子类:_Beagle__mood
- 这个语言特性叫 名称改写 (name mangling)
-
Python的私有属性是可以被修改的,通过上述名称修改
-
受保护属性:
- Python 解释器不会对使用单个下划线的属性名做特殊处理,不过这是很多 Python 程序员严格遵守的约定,他们不会在类外部访问这种属性。
- 不过在模块中,顶层名称使用一个前导下划线的话,的确会有影响:对
from mymod import *来说,mymod 中前缀为下划线的名称不会被导入。然而,依旧可以使用from mymod import _privatefunc将其导入。
-
使用
__slots__类属性节省空间-
为了使用底层的散列表提升访问速度,字典会消耗大量内存。如果要处理数百万个属性不多的实例,通过
__slots__类属性,能节省大量内存,方法是让解释器在元组中存储实例属性,而不用字典。 -
定义
__slots__的方式是,创建一个类属性,使用__slots__这个名字,并把它的值设为一个字符串构成的可迭代对象,其中各个元素表示各个实例属性。__slots__ = ('__x', '__y') -
在类中定义
__slots__属性的目的是告诉解释器:“这个类中的所有实例属性都在这儿了!”这样,Python 会在各个实例中使用类似元组的结构存储实例变量,从而避免使用消耗内存的__dict__属性。如果有数百万个实例同时活动,这样做能节省大量内存。 -
如果类中定义了
__slots__属性,而且想把实例作为弱引用的目标,那么要把'__weakref__'添加到__slots__中。
-
-
如果使用得当,
__slots__能显著节省内存- 每个子类都要定义
__slots__属性,因为解释器会忽略继承的__slots__属性 - 实例只能拥有
__slots__中列出的属性,除非把'__dict__'加入__slots__中(这样做就失去了节省内存的功效) - 如果不把
'__weakref__'加入__slots__,实例就不能作为弱引用的目标
- 每个子类都要定义
-
覆盖类属性
- 类属性可用于为实例属性提供默认值
- 如果为不存在的实例属性赋值,会新建实例属性
- 假如我们为
typecode实例属性赋值,那么同名 类属性 不受影响 - 然而,自此之后,实例读取的
self.typecode是实例属性typecode,也就是把同名类属性遮盖了 - Python风格的修改方法:
- 类属性是公开的,因此会被子类继承
- 于是经常会创建一个子类,只用于定制类的数据属性
-
总结:
- 所有用于获取字符串和字节序列表示形式的方法:
__repr__、__str__、__format__和__bytes__。 - 把对象转换成数字的几个方法:
__abs__、__bool__和__hash__。 - 用于测试字节序列转换和支持散列(连同
__hash__方法)的__eq__运算符。
- 所有用于获取字符串和字节序列表示形式的方法:
10. 序列的修改、散列和切片
-
reprlib.repr:展示变量的程序员能明白的语句 -
协议和鸭子类型
- 在 Python 中创建功能完善的序列类型无需使用继承,只需实现符合序列协议的方法
- 在面向对象编程中,协议是非正式的接口,只在文档中定义,在代码中不定义
- 例如,Python 的序列协议只需要
__len__和__getitem__两个方法 - 协议是非正式的,没有强制力,因此如果你知道类的具体使用场景,通常只需要实现一个协议的部分。
-
slice.indices:indices 方法开放了内置序列实现的棘手逻辑,用于优雅地处理缺失索引和负数索引,以及长度超过目标序列的切片。这个方法会“整顿”元组,把 start、stop 和 stride 都变成非负数,而且都落在指定长度序列的边界内。 -
__getattr__():对my_obj.x表达式,Python 会检查my_obj实例有没有名为x的属性;如果没有,到类(my_obj.__class__)中查找;如果还没有,顺着继承树继续查找。如果依旧找不到,调用my_obj所属类中定义的__getattr__方法,传入self和属性名称的字符串形式(如 'x') -
不建议只为了避免创建实例属性而使用
__slots__属性。__slots__属性只应该用于节省内存,而且仅当内存严重不足时才应该这么做。 -
归约函数(reduce、sum、any、all)把序列或有限的可迭代对象变成一个聚合结果
-
functools.reduce()的关键思想是,把一系列值归约成单个值。reduce()函数的第一个参数是接受两个参数的函数,第二个参数是一个可迭代的对象。import functools functools.reduce(lambda a, b: a * b, range(1, 6)) # 120 -
reduce(function, iterable, initializer):使用的时候最好提供第三个参数,这样能避免异常。如果序列为空,initializer是返回的结果;否则,在归约中使用它作为第一个参数,因此应该使用恒等值。比如,对 +、| 和 ^ 来说,initializer应该是 0;而对 * 和 & 来说,应该是 1。 -
zip:使用 zip 函数能轻松地并行迭代两个或更多可迭代对象,它返回的元组可以拆包成变量,分别对应各个并行输入中的一个元素。- zip 有个奇怪的特性:当一个可迭代对象耗尽后,它不发出警告就停止
itertools.zip_longest函数的行为有所不同:使用可选的fillvalue(默认值为 None)填充缺失的值,因此可以继续产出,直到最长的可迭代对象耗尽
from array import array import reprlib import math import numbers import functools import operator import itertools class Vector: typecode = 'd' def __init__(self, components): self._components = array(self.typecode, components) def __iter__(self): return iter(self._components) def __repr__(self): components = reprlib.repr(self._components) components = components[components.find('['):-1] return 'Vector({})'.format(components) def __str__(self): return str(tuple(self)) def __bytes__(self): return (bytes([ord(self.typecode)]) + bytes(self._components)) def __eq__(self, other): return tuple(self) == tuple(other) def __abs__(self): return math.sqrt(sum(x * x for x in self)) def __bool__(self): return bool(abs(self)) def __len__(self): return len(self._components) # def __getitem__(self, index): # return self._components[index] def __getitem__(self, index): cls = type(self) # 如果传入的参数是切片,就返回改切片生成的Vector类 if isinstance(index, slice): return cls(self._components[index]) # 如果传入的参数是数,就返回列表中的元素 elif isinstance(index, numbers.Integral): return self._components[index] # 否则就报错啦 else: msg = '{cls.__name__} indices must be integers' raise TypeError(msg.format(cls=cls)) shortcut_names = 'xyzt' def __getattr__(self, name): cls = type(self) if len(name) == 1: pos = cls.shortcut_names.find(name) if 0 <= pos < len(self._components): return self._components[pos] msg = '{.__name__!r} object has no attribute {!r}' raise AttributeError(msg.format(cls, name)) def __setattr__(self, name, value): cls = type(self) if len(name) == 1: if name in cls.shortcut_names: error = 'readonly attribute {attr_name!r}' elif name.islower(): error = "can't set attributes 'a' to 'z' in {cls_name!r}" else: error = '' if error: msg = error.format(cls_name=cls.__name__, attr_name=name) raise AttributeError(msg) super().__setattr__(name, value) def __eq__(self, other): # return tuple(self) == tuple(other) # 为了提高比较的效率,使用zip函数 # if len(self) != len(other): # return False # for a, b in zip(self, other): # if a != b: # return False # return True # 过用于计算聚合值的整个 for 循环可以替换成一行 all 函数调用: # 如果所有分量对的比较结果都是 True,那么结果就是 True。 return len(self) == len(other) and all(a == b for a, b in zip(self, other)) def __hash__(self): # 创建一个生成器表达式,惰性计算各个分量的散列值 # hashes = (hash(x) for x in self._components) # 这里换成map方法 hashes = map(hash, self._components) # 把hashes提供给reduce函数,第三个参数0是初始值 return functools.reduce(operator.xor, hashes, 0) def angle(self, n): r = math.sqrt(sum(x * x for x in self[n:])) a = math.atan2(r, self[n-1]) if (n == len(self) - 1) and (self[-1] < 0): return math.pi * 2 - a else: return a def angles(self): return (self.angle(n) for n in range(1, len(self))) def __format__(self, fmt_spec=''): if fmt_spec.endswith('h'): # 超球面坐标 fmt_spec = fmt_spec[:-1] coords = itertools.chain([abs(self)], self.angles()) outer_fmt = '<{}>' else: coords = self outer_fmt = '({})' components = (format(c, fmt_spec) for c in coords) return outer_fmt.format(', '.join(components)) @classmethod def frombytes(cls, octets): typecode = chr(octets[0]) memv = memoryview(octets[1:]).cast(typecode) return cls(memv)
11. 接口:从协议到抽象基类
鸭子类型:“当看到一只鸟走起来像鸭子、游泳起来像鸭子、叫起来也像鸭子,那么这只鸟就可以被称为鸭子。”
程序设计中,鸭子类型(英语:duck typing)是 动态类型 的一种风格。在这种风格中,一个对象有效的语义,不是由继承自特定的类或实现特定的接口,而是由"当前方法" (计算机科学)和属性的集合决定。
在鸭子类型中,关注点在于对象的行为,能做什么;而不是关注对象所属的类型。
-
Python文化中的接口和协议
- 受保护的属性和私有属性不在接口中
- 接口 的补充定义:对象公开方法的子集,让对象在系统中扮演特定的角色
- 协议与继承没有关系。一个类可能会实现多个接口,从而让实例扮演多个角色。
- 协议是接口,但不是正式的,因此协议不能像正式接口那样施加限制
- 一个类可能只实现部分接口,这是允许的
- 对 Python 程序员来说,“X 类对象”、“X 协议”和“X 接口”都是一个意思
- 序列协议是 Python 最基础的协议之一。即便对象只实现了那个协议最基本的一部分,解释器也会负责任地处理。
-
Python喜欢序列
-
定义为抽象基类的Sequence正式接口
classDiagram Container <|-- Sequence Iterable <|-- Sequence Sized <|-- Sequence class Container { __contains__ } class Iterable { __iter__ } class Sized { __len__ } class Sequence { __getitem__ __contains__ __iter__ __reversed__ index count } -
定义
__getitem__方法,只实现序列协议的一部分,这样足够访问元素、迭代和使用 in 运算符了class Foo: def __getitem__(self, pos): return range(0, 30, 10)[pos]- 虽然没有
__iter__方法,但是 Foo 实例是可迭代的对象,因为发现有__getitem__方法时,Python 会调用它,传入从 0 开始的整数索引,尝试迭代对象 - 鉴于序列协议的重要性,如果没有
__iter__和__contains__方法,Python 会调用__getitem__方法,设法让迭代和 in 运算符可用。
- 虽然没有
-
shuffle 函数要调换集合中元素的位置,只实现了
__getitem__即是只实现了不可变的序列协议,可变的序列还必须提供__setitem__方法。 -
猴子补丁:在运行时修改类或模块,而不改动源码
-
协议是动态的:
random.shuffle函数不关心参数的类型,只要那个对象实现了部分可变序列协议即可。即便对象一开始没有所需的方法也没关系,后来再提供也行。 -
“鸭子类型”:对象的类型无关紧要,只要实现了特定的协议即可。
-
-
Alex Martelli的水禽
-
用isinstance检查对象的类型,而不是
type(foo) is bar。 -
白鹅类型,goose typing,指只要
cls是抽象基类,即cls的元类是abc.ABCMeta,就可以使用isinstance(obj, cls) -
Python 的抽象基类还有一个重要的实用优势:可以使用
register类方法在终端用户的代码中把某个类“声明”为一个抽象基类的“虚拟”子类 -
无需注册,
abc.Sized也能把Struggle识别为自己的子类,只要实现了特殊方法__len__即可。要使用正确的句法和语义实现,前者要求没有参数,后者要求返回一个非负整数,指明对象的长度。如果不使用规范的语法和语义实现特殊方法,如__len__,会导致非常严重的问题class Struggle: def __len__(self): return 23 from collections import abc isinstance(Struggle(), abc.Sized) -
在 Python 3.4 中没有能把字符串和元组或其他不可变序列区分开的抽象基类,因此必须测试 str:
isinstance(x, str)。 -
EAFP和LBYL
-
EAFP:Easier to Ask for Forgiveness than Permission,请求宽恕比许可更容易
-
操作前不检查,出了问题由异常处理来处理
-
代码表现:try...except...
try: x = test_dict["key"] except KeyError: # key 不存在 -
-
LBYL:Look Before You Leap,三思而后行
- 操作前先检查,再执行
- 代码表现:if...else...
if "key" in test_dict: x = test_dict["key"] else: # key 不存在 -
EAFP 的异常处理往往也会影响一点性能,因为在发生异常的时候,程序会进行保留现场、回溯traceback等操作,但在异常发生频率比较低的情况下,性能相差的并不是很大。
-
而 LBYL 则会消耗更高的固定成本,因为无论成败与否,总是执行额外的检查。
-
相比之下,如果不引发异常,EAFP 更优一些,
-
Python 的动态类型(duck typing)决定了 EAFP,而 Java等强类型(strong typing)决定了 LBYL
-
-
定义抽象基类的子类
-
导入时,Python不会检查抽象方法的实现,在运行时实例化类的时候才会真正检查。因此,如果没有正确实现某个抽象方法,Python会抛出TypeError异常。
-
MutableSequence 抽象基类和 collections.abc 中它的超类的UML类图(箭头由子类指向祖先;以斜体显示的名称是抽象类和抽象方法)

-
-
标准库中的抽象基类
-
collections.abc模块中各个抽象基类的 UML 类图
-
Iterable、Container 和 Sized
- 各个集合应该继承这三个抽象基类,或者至少实现兼容的协议。
- Iterable 通过
__iter__方法支持迭代 - Container 通过
__contains__方法支持 in 运算符 - Sized 通过
__len__方法支持len()函数
-
Sequence、Mapping 和 Set
- 这三个是主要的不可变集合类型,而且各自都有可变的子类
-
MappingView
- 映射方法 .items()、.keys() 和 .values() 返回的对象分别是 ItemsView、KeysView 和 ValuesView 的实例
-
Callable 和 Hashable
- 这两个抽象基类与集合没有太大的关系,只不过因为
collections.abc是标准库中定义抽象基类的第一个模块,而它们又太重要了,因此才把它们放到collections.abc模块中 - 这两个抽象基类的主要作用是为内置函数
isinstance提供支持,以一种安全的方式判断对象能不能调用或散列 - 若想检查是否能调用,可以使用内置的 callable() 函数;但是没有类似的 hashable() 函数,因此测试对象是否可散列,最好使用
isinstance(my_obj, Hashable)
- 这两个抽象基类与集合没有太大的关系,只不过因为
-
Iterator
- Iterable 的子类
-
-
抽象基类的金字塔
- numbers包定义的是 数字塔
- Number
- Complex
- Real
- Rational
- Integral
- 检查一个数是不是整数:
isinstance(x, numbers.Integral),这样代码就可以接受int、bool - 检查一个数是不是浮点数:
isinstance(x, number.Real),这样代码就可以接受bool、int、float、fractions.Fraction,还有外部库如Numpy - deciaml.Decimal没有注册为numbers.Real的虚拟子类,是因为,如果你的程序需要Decimal的精度,要防止与其他低精度数字类型混合,尤其是浮点数
- numbers包定义的是 数字塔
-
定义并使用一个抽象基类
-
抽象方法示例:
import abc class Tombola(abc.ABC): @abc.abstractmethod def load(self, iterable): """从可迭代对象中添加元素""" @abc.abstractmethod def pick(self): """随机删除元素,然后将其返回 如果实例为空,这个方法应该抛出 LookupError """ def loaded(self): """如果至少有一个元素,返回True,否则返回False""" return bool(self.inspect()) def inspect(self): """返回一个有序元组,由当前元素构成""" items = [] while True: try: items.append(self.pick()) except LookupError: break self.load(items) return tuple(sorted(items)) -
抽象方法可以有实现代码。即便实现了,子类也必须覆盖抽象方法,但是在子类中可以使用 super() 函数调用抽象方法,为它添加功能,而不是从头开始实现
-
IndexEror和KeyError是LookupError的子类
- IndexError:尝试从序列中获取索引超过最后位置的元素时抛出
- KeyError:使用不存在的键从映射中获取元素时,抛出 KeyError 异常
-
-
抽象基类语法详解
-
可以通过装饰器堆叠的方式,声明抽象类方法、抽象静态方法、抽象属性等。
class MyABC(abc.ABC): @classmethod @abc.abstractmethod def an_abstract_classmethod(cls, ...): pass -
与其他方法描述符一起使用时,
abstractmethod()应该放在 最里层 -
唯一推荐使用的抽象基类方法装饰器是@abstractmethod,其他装饰器已经废弃了
-
-
定义Tombola抽象基类的子类
-
就算iterable参数始终传入列表,
list(iterable)会创建参数的副本,这依然是好的做法 -
白鹅类型 的重要动态特性:使用register方法声明虚拟子类
-
鸭子类型与继承毫无关系。
- 鸭子类型的定义是:
“当看到一只鸟走起来像鸭子、游泳起来像鸭子、叫起来也像鸭子,那么这只鸟就可以被称为鸭子。” - 言简意赅的理解是:
“对象的类型无关紧要,只要实现了特定的协议即可。忽略对象真正的类型,转而关注对象有没有实现所需的方法、签名和语义。” - 最直接的结果就是:
- 一个用户定义的类型,不需要真正的继承自抽象基类,但是却可以当作其子类一样来使用。
- 比如用户实现了序列协议,就可以当作内置序列类型来用,对其使用
len()等函数,调用__len__()等用于内置类型的方法。 - 比如用户实现了
__getitem__方法,Python就可以直接去迭代这个类型。 - Python内置库和第三方的库,虽然是针对Python的类型设计的,但是都可以直接用于用户自定义的类型上。
而白鹅类型与此恰好相反。
- 白鹅类型的定义是:
使用抽象基类明确声明接口,子类显示地继承抽象基类,抽象基类会检查子类是否符合接口定义。 - 这样做的劣势是:
子类为了经过抽象基类的接口检查,必须实现一些接口,但是这些接口你可能用不到。 - 这样做的优势是:
一些直接继承自抽象基类的接口是可以拿来即用的。
- 鸭子类型的定义是:
-
-
Tombola的虚拟子类
@Tombola.register class TomboList(list): def pick(self): if self: position = randrange(len(self)) return self.pop(position) else: raise LookupError('pop from empty TomboList') load = list.extend def loaded(self): return bool(self) def inspect(self): return tuple(sorted(self)) # Tombola.register(TomTomboList)- 白鹅类型的一个基本特性:即便不继承,也有办法把一个类注册为抽象基类的虚拟子类。
- 注册虚拟子类的方式是在抽象基类上调用 register 方法
- 这么做之后,注册的类会变成抽象基类的虚拟子类,而且 issubclass 和isinstance 等函数都能识别
- 但是注册的类不会从抽象基类中继承任何方法或属性
- 虚拟子类不会继承注册的抽象基类,而且任何时候都不会检查它是否符合抽象基类的接口,即便在实例化时也不会检查。为了避免运行时错误,虚拟子类要实现所需的全部方法。
load = list.extend,load跟list的extend一样。
-
类的继承关系在一个特殊的类属性中指定——
__mro__,即方法解析顺序(Method Resolution Order)- 这个属性的作用很简单,按顺序列出类及其超类,Python 会按照这个顺序搜索方法
- 它只列出了“真实的”超类,利用
@类名.register集成的不在其中,所以也没有从中继承任何方法
-
Tombola子类的测试方法
__subclasses__():这个方法返回类的直接子类列表,不含虚拟子类_abc_registry:只有抽象基类有这个数据属性,其值是一个 WeakSet 对象,即抽象类注册的虚拟子类的弱引用
-
问题:报错没有找到
_abc_registry,-
这是因为,python3.7版本没有,需要用3.4才行,参考链接
-
并且在3.7的版本中是不能获取到这个属性的
-
-
Python使用register的方式
- 虽然现在可以把 register 当作装饰器使用了,但更常见的做法还是把它当作函数使用,用于注册其他地方定义的类
-
鹅的行为有可能像鸭子
-
即便不注册,抽象基类也能把一个类识别为虚拟子类
-
比如一个类实现了
__len__()方法:class Struggle: def __len__(self): return 23 -
然后可以看到这个类是Sized抽象基类的虚拟子类
from collections import abc isinstance(Struggle(), abc.Sized) # True issubclass(Struggle, abc.Sized) # True -
这是因为
abc.Sized实现了一个特殊的类方法:__sunclasshook__
-
-
__subclasshook__在白鹅类型中添加了一些鸭子类型的踪迹。- 我们可以使用抽象基类定义正式接口,可以始终使用 isinstance 检查
- 也可以完全使用不相关的类,只要实现特定的方法即可(或者做些事情让
__subclasshook__信服) - 当然,只有提供
__subclasshook__方法的抽象基类才能这么做。
-
在你我自己编写的抽象基类中实现
__subclasshook__方法,可靠性很低- 程序员最好让 Spam 继承 Tombola,至少也要注册(Tombola.register(Spam))
- 自己实现的
__subclasshook__方法还可以检查方法签名和其他特性,但我觉得不值得这么做
-
强类型和弱类型
- 如果一门语言很少隐式转换类型,说明它是强类型语言;如果经常这么做,说明它是弱类型语言
- Java、C++ 和 Python 是强类型语言
- PHP、JavaScript 和 Perl 是弱类型语言
-
静态类型和动态类型
- 在编译时检查类型的语言是静态类型语言,在运行时检查类型的语言是动态类型语言
- 静态类型需要声明类型(有些现代语言使用类型推导避免部分类型声明)
- Fortran 和 Lisp 是最早的两门语言,现在仍在使用,它们分别是静态类型语言和动态类型语言
-
小结
- 强类型能及早发现缺陷
- 静态类型使得一些工具(编译器和 IDE)便于分析代码、找出错误和提供其他服务(优化、重构,等等)
- 动态类型便于代码重用,代码行数更少,而且能让接口自然成为协议而不提早实行
- Python 是动态强类型语言
-
猴子补丁
- 猴子补丁的名声不太好。如果滥用,会导致系统难以理解和维护。补丁通常与目标紧密耦合,因此很脆弱。另一个问题是,打了猴子补丁的两个库可能相互牵绊,因为第二个库可能撤销了第一个库的补丁。
- 猴子补丁也有它的作用,例如可以在运行时让类实现协议。适配器设计模式通过实现全新的类解决这种问题。
- Python 不允许为内置类型打猴子补丁,这一局限能减少外部库打的补丁有冲突的概率
-
不把隐喻当作设计范式,而代之以“习惯用法的界面”
-
12. 继承的优缺点
-
子类化内置类型很麻烦
- 内置类型不会调用用户定义的类覆盖的特殊方法
- 内置类型的方法不会调用子类覆盖的方法
- 直接子类化内置类型(如 dict、list 或 str)容易出错,因为内置类型的方法通常会忽略用户覆盖的方法
- 不要子类化内置类型,用户自己定义的类应该继承 collections 模块中的类,例如UserDict、UserList 和 UserString,这些类做了特殊设计,因此易于扩展
- 如果子类化使用Python 编写的类,如 UserDict 或 MutableMapping,就不会受此影响
-
多重继承和方法解析顺序
- “菱形问题”:不相关的祖先类实现同名方法引起的冲突
- Python 会按照特定的顺序遍历继承图,这个顺序叫方法解析顺序(Method Resolution Order, MRO)
- 直接在类上调用实例方法时,必须显式传入 self 参数,因为这样访问的是未绑定方法(unbound method)
- 使用 super() 最安全,也不易过时。调用框架或不受自己控制的类层次结构中的方法时,尤其适合使用 super()
- 使用 super() 调用方法时,会遵守方法解析顺序
- 方法解析顺序不仅考虑继承图,还考虑子类声明中列出超类的顺序,先声明的先调用你敢信?没事多看看
__mro__属性吧,按这个顺序调用。
-
多重继承的真实应用(以Tkinter为例)
- Toplevel 是所有图形类中唯一没有继承 Widget 的,因为它是顶层窗口,行为不像小组件,例如不能依附到窗口或窗体上
- Toplevel 继承自 Wm,后者提供直接访问宿主窗口管理器的函数,例如设置窗口标题和配置窗口边框
- Widget 直接继承自 BaseWidget,还继承了 Pack、Place 和Grid。后三个类是几何管理器,负责在窗口或窗体中排布小组件。各个类封装了不同的布局策略和小组件位置 API
-
处理多重继承
-
下面是避免把类图搅乱的一些建议
-
把接口继承和实现继承区分开
- 继承接口,创建子类型,实现“是什么”关系
- 继承实现,通过重用避免代码重复
-
使用抽象基类显式表示接口
-
通过混入重用代码
- 如果一个类的作用是为多个不相关的子类提供方法实现,从而实现重用,但不体现“是什么”关系,应该把那个类明确地定义为混入类(mixin class)
- 从概念上讲,混入不定义新类型,只是打包方法,便于重用
- 混入类绝对不能实例化,而且具体类不能只继承混
入类 - 混入类应该提供某方面的特定行为,只实现少量关系非常紧密的方法
-
在名称中明确指明混入
因为在 Python 中没有把类声明为混入的正规方式,所以强烈推荐在名称中加入 ...Mixin 后缀
-
抽象基类可以作为混入,反过来则不成立
-
不要子类化多个具体类
- 具体类可以没有,或最多只有一个具体超类
- 具体类的超类中除了这一个具体超类之外,其余的都是抽象基类或混入
-
为用户提供聚合类
- 如果抽象基类或混入的组合对客户代码非常有用,那就提供一个类,使用易于理解的方式把它们结合起来。Grady Booch 把这种类称为聚合类(aggregate class)
- 例如
tkinter.Widget类中继承了多个抽象基类/混入:class Widget(BaseWidget, Pack, Place, Grid):pass - Widget 类的定义体是空的,但是这个类提供了有用的服务:把四个超类结合在一起,这样需要创建新小组件的用户无需记住全部混入,也不用担心声明 class 语句时有没有遵守特定的顺序
-
“优先使用对象组合,而不是类继承”
组合和委托可以代替混入,把行为提供给不同的类,但是不能取代接口继承去定义类型层次结构
- 依赖、关联、聚合、组合
- 混入,python多继承和混入类,混入类就是多重继承的一种实现技巧,为了防止类的指数增长,为了使具体类具有多个独立、解耦的功能(个人想法)
-
-
KISS 原则:KISS 原则是用户体验的高层境界,简单地理解这句话,就是要把一个产品做得连白痴都会用,因而也被称为“懒人原则”。
- Keep it Simple and Stupid
-
内置类型:dict、list 和 str 类型
- 是 Python 的底层基础,速度必须快,与这些内置类型有关的任何性能问题几乎都会对其他所有代码产生重大影响
- CPython 走了捷径,故意让内置类型的方法行为不当,即不调用被子类覆盖的方法
- 解决这一困境的可能方式之一是,为这些类型分别提供两种实现:一种供内部使用,为解释器做了优化;另一种供外部使用,便于扩展(UserDict、UserList 和 UserString)
-
多重分派:
- 分派就是指根据变量的类型选择相应的方法,单分派指的是指根据第一个参数类型去选择方法。
- 函数func()的结果只跟第一个参数的类型有关,跟后面的参数没有关系,这就是单分派。
- 使用函数的所有参数,而非只用第一个,来决定调用哪个方法被称为多重分派。
-
13. 正确重载运算符
-
运算符重载基础
- Python 施加了一些限制,做好了灵活性、可用性和安全性方面的平衡:
- 不能重载内置类型的运算符
- 不能新建运算符,只能重载现有的
- 某些运算符不能重载——is、and、or 和 not(不过位运算符 &、| 和 ~ 可以)
- Python 施加了一些限制,做好了灵活性、可用性和安全性方面的平衡:
-
一元运算符
-
常见的运算符和对应的特殊方法:
-:__neg__,取负算术运算符+:__pos__,取正算术运算符~:__invert__,按位取反- 定义为 $~x == -(x+1)$
- 如果x是2,那么~x == -3
abs():__abs__,取绝对值
-
x 和 +x 何时不相等
-
jupyter和ipython中无法重现例子,但是cmd可以

-
Counter的例子
- Counter 相加时,负值和零值计数会从结果中剔除
- 而一元运算符 + 等同于加上一个空 Counter,因此它产生一个新的 Counter 且仅保留大于零的计数器
- 什么意思呢,就是说,如果使用Counter对序列进行计数之后,然后给部分key负值为0或者负值,然后在前面使用+算术运算符,就会导致负值和0对应的
key:value键值对剔除。
-
-
-
重载向量加法运算符+
__radd__和__rsub__中的r:reflected(反射),reverse(反向),两种皆可,推荐使用反向- r这种特殊的方法,是一种后备机制,如果左操作数没有实现对应的方法,或者实现了,但是返回的是
NotImplemented表明它不知道如何处理右操作数,那么Python会调用r的方法。
-
重载标量乘法运算符*
Vector([1, 2, 3]) * x:计算标量积(scalar product),结果是一个新Vector实例,各个分量都会乘以x,这也叫元素级乘法(elementwise multiplication)- 在Numpy库中,点积使用
numpy.dot()计算 - Python3.5起,引入
@用作中缀点击运算符 __mul__和__rmul__方法- decimal.Decimal 没有把自己注册为 numbers.Real 的虚拟子类。因此,Vector 类不会处理decimal.Decimal 数字。
-
中缀运算符方法的名称
运算符 正向方法 反向方法 就地方法 说明 + __add____radd____iadd__加法或拼接 - __sub____rsub____isub__减法 * __mul____rmul____imul__乘法或重复复制 / __truediv____rtruediv____itruediv__除法 // __floordiv____rfloordiv____ifloordiv__整除 % __mod____rmod____imod__取模 divmod() __divmod____rdivmod____idivmod__返回由整除的商和模数组成的元组 **, pow() __pow____rpow____ipow__取幂 @ __matmul____rmatmul____imatmul__矩阵乘法 & __add____radd____iadd__位与 | __or____ror____ior__位或 ^ __xor____rxor____ixor__位异或 << __lshift____rlshift____ilshift__按位左移 >> __rshift____rrshift____irshift__按位右移 -
众多比较运算符
- ==、!=、>、<、>=、<=
- 正向和反向调用使用的是同一系列方法
- 而正向的
__gt__方法调用的是反向的__lt__方法,并把参数对调 - 对 == 和 != 来说,如果反向调用失败,Python 会比较对象的 ID,而不抛出 TypeError
- 众多比较运算符:正向方法返回
NotImplemented的话,调用反向方法
-
众多比较运算符
分组 中缀运算符 正向方法调用 反向方法调用 后备机制 相等性 a == b a.__eq__(b)b.__eq__(a)返回 id(a) == id(b)a != b a.__ne__(b)b.__ne__(a)返回 not(a == b)排序 a > b a.__gt__(b)b.__lt__(a)抛出TypeError a < b a.__lt__(b)b.__gt__(a)抛出TypeError a >= b a.__ge__(b)b.__le__(a)抛出TypeError a < b a.__le__(b)b.__ge__(a)抛出TypeError -
增量赋值运算符
- 如果一个类没有实现上表列出的就地运算符,增量赋值运算符只是语法糖:a += b 的作用与 a = a + b 完全一样
- 如果实现了就地运算符方法,例如
__iadd__,计算 a += b 的结果时会调用就地运算符方法。这种运算符的名称表明,它们会就地修改左操作数,而不会创建新对象作为结果 - 不可变类型,一定不能实现就地特殊方法
-
如果操作数的类型不同,我们要检测出不能处理的操作数。本章使用两种方式处理这个问题:
- 一种是鸭子类型,直接尝试执行运算,如果有问题,捕获 TypeError 异常
- 鸭子类型更灵活,但是显式检查更能预知结果
- 另一种是显式使用 isinstance 测试,
__mul__方法就是这么做的- 如果选择使用 isinstance,要小心,不能测试具体类,而要测试
numbers.Real抽象基类,例如isinstance(scalar, numbers.Real) - 这在灵活性和安全性之间做了很好的折中
- 如果选择使用 isinstance,要小心,不能测试具体类,而要测试
- 一种是鸭子类型,直接尝试执行运算,如果有问题,捕获 TypeError 异常
-
在可接受的类型方面,+ 应该比 += 严格
- 对序列类型来说,+ 通常要求两个操作数属于同一类型
- 而 += 的右操作数往往可以是任何可迭代对象
14. 可迭代的对象、迭代器和生成器
- 迭代器模式(Iterator pattern):迭代是数据处理的基石。扫描内存中放不下的数据集时,我们要找到一种惰性获取数据项的方式,即按需一次获取一个数据项。
- 迭代器:用于从集合中取出元素
- 生成器:用于“凭空”生成元素
- 在 Python社区中,大多数时候都把迭代器和生成器视作同一概念
-
单词序列
-
第一版Sentence
import re import reprlib RE_WORD = re.compile('\w+') class Sentence: def __init__(self, text): self.text = text self.words = RE_WORD.findall(text) def __getitem__(self, index): return self.words[index] def __len__(self): return len(self.words) def __repr__(self): return 'Sentence(%s)' % reprlib.repr(self.text) -
序列可以迭代的原因:iter函数,解释器需要迭代对象 x 时,会自动调用 iter(x)。
-
内置的 iter 函数有以下作用:
- 检查对象是否实现了
__iter__方法,如果实现了就调用它,获取一个迭代器 - 如果没有实现
__iter__方法,但是实现了__getitem__方法,Python 会创建一个迭代器,尝试按顺序(从索引 0 开始)获取元素 - 如果尝试失败,Python 抛出 TypeError 异常,通常会提示“C object is not iterable”(C 对象不可迭代),其中 C 是目标对象所属的类
- 检查对象是否实现了
-
这是鸭子类型(duck typing)的极端形式:不仅要实现特殊的
__iter__方法,还要实现__getitem__方法,而且__getitem__方法的参数是从 0 开始的整数(int),这样才认为对象是可迭代的 -
白鹅类型(goose typing)理论中,可迭代对象的定义简单一些,不过没那么灵活:如果实现了
__iter__方法,那么就认为对象是可迭代的。此时,不需要创建子类,也不用注册,因为 abc.Iterable 类实现了__subclasshook__方法 -
检查对象 x 能否迭代,最准确的方法是:
- 调用 iter(x) 函数,如果不可迭代,再处理 TypeError 异常。
- 这比使用 isinstance(x, abc.Iterable) 更准确
- 因为 iter(x) 函数会考虑到遗留的
__getitem__方法,而 abc.Iterable 类则
不考虑
-
-
可迭代的对象与迭代器的对比
- 可迭代的对象和迭代器之间的关系:Python 从可迭代的对象中获取迭代器
- StopIteration 异常表明迭代器到头了
- 标准的迭代器接口有两个方法:
__next__:返回下一个可用的元素,如果没有元素了,抛出 StopIteration异常__iter__:返回 self,以便在应该使用可迭代对象的地方使用迭代器,例如在 for 循环中
- 在
Iterator(Iterable)源码中,根据__subclasshook__(cls, C)函数识别C是不是Iterator的子类。这种方法是通过在C.__mro__中找是否同时存在__next__和__iter__方法 - 检查对象 x 是否为迭代器最好的方式是调用
isinstance(x, abc.Iterator) - 代器是这样的对象:
- 实现了无参数的
__next__方法,返回序列中的下一个元素; - 如果没有元素了,那么抛出 StopIteration 异常
- Python 中的迭代器还实现了
__iter__方法,因此迭代器也可以迭代
- 实现了无参数的
-
典型的迭代器
-
构建可迭代的对象和迭代器时经常会出现错误,原因是混淆了二者
- 可迭代的对象有个
__iter__方法,每次都实例化一个新的迭代器 - 而迭代器要实现
__next__方法,返回单个元素,此外还要实现__iter__方法,返回迭代器本身
- 可迭代的对象有个
-
迭代器可以迭代,但是可迭代的对象不是迭代器
-
迭代器模式可用来:
- 访问一个聚合对象的内容而无需暴露它的内部表示
- 支持对聚合对象的多种遍历
- 为遍历不同的聚合结构提供一个统一的接口(即支持多态迭代)
-
为了“支持多种遍历”,必须能从同一个可迭代的实例中获取多个独立的迭代器,而且各个迭代器要能维护自身的内部状态,因此这一模式正确的实现方式是,每次调用 iter(my_iterable) 都新建一个独立的迭代器。这就是为什么这个示例需要定义 SentenceIterator 类
-
可迭代的对象一定不能是自身的迭代器。也就是说,可迭代的对象必须实现
__iter__方法,但不能实现__next__方法 -
另一方面,迭代器应该一直可以迭代。迭代器的
__iter__方法应该返回自身 -
第二版Sentence
import re import reprlib RE_WORD = re.compile('\w+') class Sentence: def __init__(self, text): self.text = text self.words = RE_WORD.findall(text) def __repr__(self): return 'Sentence(%s)' % reprlib.repr(self.text) def __iter__(self): return SentenceIterator(self.words) class SentenceIterator: def __init__(self, words): self.words = words self.index = 0 def __next__(self): try: word = self.words[self.index] except IndexError: raise StopIteration() self.index += 1 return word def __iter__(self): return self
-
-
生成器函数
-
达到 实现相同功能,但符合Python习惯 的方式:用生成器函数代替SentenceIterator 类
import re import reprlib RE_WORD = re.compile('\w+') class Sentence: def __init__(self, text): self.text = text self.words = RE_WORD.findall(text) def __repr__(self): return 'Sentence(%s)' % reprlib.repr(self.text) def __iter__(self): for word in self.words: yield word return -
这个 return 语句不是必要的;这个函数可以直接“落空”,自动返回。不管有没有 return 语句,生成器函数都不会抛出 StopIteration 异常,而是在生成完全部值之后会直接退出
-
生成器函数的工作原理
- 只要Python函数的定义体中有yield关键字,该函数就是生成器函数
- 调用生成器函数时,会返回一个生成器对象
- 也就是说,生成器函数是生成器工厂
-
描述:
- 函数返回值;
- 调用生成器函数返回生成器;
- 生成器产出或生成值
- 生成器不会以常规的方式“返回”值:生成器函数定义体中的 return 语句会触发生成器对象抛出 StopIteration 异常
-
-
惰性实现
-
惰性求值(lazy evaluation)和 及早求值(eager evaluation)是编程语言理论方面的技术术语
-
re.finditer 函数是 re.findall 函数的惰性版本,返回的不是列表,而是一个生成器,能节省大量内存
-
Sentence类第4版:
import re import reprlib RE_WORD = re.compile('\w+') class Sentence: def __init__(self, text): self.text = text def __repr__(self): return 'Sentence(%s)' % reprlib.repr(self.text) def __iter__(self): for match in RE_WORD.finditer(self.text): yield match.group()
-
-
生成器表达式
-
生成器表达式可以理解为列表推导的惰性版本:不会迫切地构建列表,而是返回一个生成器,按需惰性生成元素
-
如果列表推导是制造列表的工厂,那么生成器表达式就是制造生成器的工厂
-
生成器表达式会产出生成器
import re import reprlib RE_WORD = re.compile('\w+') class Sentence: def __init__(self, text): self.text = text def __repr__(self): return 'Sentence(%s)' % reprlib.repr(self.text) def __iter__(self): return (match.group() for match in RE_WORD.finditer(self.text)) -
生成器表达式是语法糖:完全可以替换成生成器函数,不过有时使用生成器表达式更便利
-
-
何时使用生成器表达式
- 如果函数或构造方法只有一个参数,传入生成器表达式时不用写一对调用函数的括号,再写一对括号围住生成器表达式,只写一对括号就行了
- 如果生成器表达式后面还有其他参数,那么必须使用括号围住,否则会抛出 SyntaxError 异常
-
等差数列生成器
-
类生成器
class ArithmeticProgression: def __init__(self, begin, step, end=None): self.begin = begin self.step = step self.end = end def __iter__(self): result = type(self.begin + self.step)(self.begin) forever = self.end is None index = 0 while forever or result < self.end: yield result index += 1 result = self.begin + self.step * index -
函数生成器
def aritpro_gen(begin, step, end=None): result = type(begin + step)(begin) forever = end is None index = 0 while forever or result < end: yield result index += 1 result = begin + step * index -
使用itertools模块生成等差数列
import itertools gen = itertools.count(1, .5) next(gen) -
itertools.takewhile-
它会生成一个使用另一个生成器的生成器
-
在指定的条件计算结果为 False 时停止
-
可以把这两个函数结合在一起使用
gen = itertools.takewhile(lambda n: n < 3, itertools.count(1, .5))
-
-
生成器工厂,返回的是一个生成器
import itertools def aritpro_gen(begin, step, end=None): first = type(begin + step)(begin) ap_gen = itertools.count(first, step) if end is not None: ap_gen = itertools.takewhile(lambda n: n < end, ap_gen) return ap_gen
-
-
标准库中的生成器函数,参考链接
-
下面大多数函数都接受一个断言参数(predicate),这个参数是个布尔函数,有一个参数,会应用到输入中的每个元素上,用于判断元素是否包含在输出中。
用于过滤的生成器函数
模块 函数 说明 itertools compress(it, selector_it) 并行处理两个可迭代的对象;如果 selector_it 中的元素是真值,产出 it 中对应的元素 itertools dropwhile(predicate, it) 处理 it,跳过 predicate 的计算结果为真值的元素,然后产出剩下的各个元素(不再进一步检查) (内置) filter(predicate, it) 把 it 中的各个元素传给 predicate,如果predicate(item) 返回真值,那么产出对应的元素;如果 predicate 是 None,那么只产出真值元素 itertools filterfalse(predicate, it) 与 filter 函数的作用类似,不过 predicate 的逻辑是相反的:predicate 返回假值时产出对应的元素 itertools islice(it, stop) 或islice(it, start, stop, step=1) 产出 it 的切片,作用类似于 s[:stop] 或s[start:stop:step],不过 it 可以是任何可迭代的对象,而且这个函数实现的是惰性操作 itertools takewhile(predicate, it) predicate 返回真值时产出对应的元素,然后立即停止,不再继续检查 -
上述函数测试
-
compress(it, selector_it)按照真值表筛选元素
import itertools temp = [1, 0, -1, 2, 4, 9] temp_select = [x > 2 for x in temp] it = itertools.compress(temp, temp_select) list(it) # [4, 9] -
dropwhile(predicate, it)按照真值函数丢弃掉列表和迭代器前面的元素
import itertools x = itertools.dropwhile(lambda e: e < 5, range(10)) list(x) # [5, 6, 7, 8, 9] -
filter(predicate, it)过滤函数为True的元素
x = filter(lambda e: e < 5, range(10)) list(x) # [0, 1, 2, 3, 4] -
filterfalse(predicate, it)保留对应真值为False的元素
import itertools x = itertools.filterfalse(lambda e: e < 5, (1, 5, 3, 6, 9, 4)) list(x) # [5, 6, 9] -
islice(it, stop) 或 islice(it, start, stop, step=1)对迭代器进行切片
import itertools x = itertools.islice(range(10), 0, 9, 2) list(x) # [0, 2, 4, 6, 8] -
takewhile(predicate, it)与dropwhile相反,保留元素直至真值函数值为假(有顺序,一旦为假,后面的就不管了)
import itertools x = itertools.takewhile(lambda x: x.lower() in 'aeiou', 'Aardvark') list(x) # ['A', 'a']
-
-
下一组是用于映射(map)的生成器函数:在输入的单个可迭代对象(map 和starmap 函数处理多个可迭代的对象)中的各个元素上做计算,然后返回结果
-
生成器函数会从输入的可迭代对象中的各个元素中产出一个元素
-
如果输入来自多个可迭代的对象,第一个可迭代的对象到头后就停止输出
-
用于映射的生成器函数
模块 函数 说明 itertools accumulate(it, [func]) 产出累积的总和;如果提供了 func,那么把前两个元素传给它,然后把计算结果和下一个元素传给它,以此类推,最后产出结果 (内置) enumerate(iterable, start=0) 产出由两个元素组成的元组,结构是 (index, item),其中 index 从 start 开始计数,item 则从 iterable 中获取 (内置) map(func, it1, [it2, ..., itN]) 把 it 中的各个元素传给func,产出结果;如果传入 N 个可迭代的对象,那么 func 必须能接受 N 个参 数,而且要并行处理各个可迭代的对象 itertools starmap(func, it) 把 it 中的各个元素传给 func,产出结果;输入的 可迭代对象应该产出可迭代的元素 iit,然后以 func(*iit) 这种形式调用 func
-
-
上述函数测试
-
accumulate(it, [func])简单来说就是累加
import itertools sample = [5, 4, 2, 8, 7, 6, 3, 0, 9, 1] print(list(itertools.accumulate(sample))) # [5, 9, 11, 19, 26, 32, 35, 35, 44, 45] print(list(itertools.accumulate(sample, min))) # [5, 4, 2, 2, 2, 2, 2, 0, 0, 0] print(list(itertools.accumulate(sample, max))) # [5, 5, 5, 8, 8, 8, 8, 8, 9, 9] import operator print(list(itertools.accumulate(sample, operator.mul))) # [5, 20, 40, 320, 2240, 13440, 40320, 0, 0, 0] print(list(itertools.accumulate(range(1, 11), operator.mul))) # [1, 2, 6, 24, 120, 720, 5040, 40320, 362880, 3628800] -
enumerate(iterable, start=0)生成编号
print(list(enumerate('albatroz', 1))) # [(1, 'a'), (2, 'l'), (3, 'b'), (4, 'a'), (5, 't'), (6, 'r'), (7, 'o'), (8, 'z')] -
map(func, it1, [it2, ..., itN])import itertools print(list(map(operator.mul, range(11), range(1, 12, 1)))) # [0, 2, 6, 12, 20, 30, 42, 56, 72, 90, 110]import itertools print(list(map(lambda a,b : (a, b), range(11), [2, 4, 8]))) # [(0, 2), (1, 4), (2, 8)] -
starmap(func, it)类似map,
itertools模块的starmap()函数实际上是map()函数的*a版本,参考链接import itertools print(list(itertools.starmap(operator.mul, enumerate('albatroz', 1)))) # ['a', 'll', 'bbb', 'aaaa', 'ttttt', 'rrrrrr', 'ooooooo', 'zzzzzzzz'] sample = [5, 4, 2, 8, 7, 6, 3, 0, 9, 1] print(list(itertools.starmap(lambda a, b: b / a, enumerate(itertools.accumulate(sample), 1)))) # [5.0, 4.5, 3.6666666666666665, 4.75, 5.2, 5.333333333333333, 5.0, 4.375, 4.888888888888889, 4.5]
-
-
这一组是用于合并的生成器函数,这些函数都从输入的多个可迭代对象中产出元素。chain 和 chain.from_iterable 按顺序(一个接一个)处理输入的可迭代对象,而 product、zip 和 zip_longest 并行处理输入的各个可迭代对象
合并多个可迭代对象的生成器函数
模块 函数 说明 itertools chain(it1, ..., itN) 先产出 it1 中的所有元素,然后产出 it2 中的所有元素,以此类推,无缝连接在一起 itertools chain.from_iterable(it) 产出 it 生成的各个可迭代对象中的元素,一个接一个,无缝连接在一起;it 应该产出可迭代的元素,例如可迭代的对象列表 itertools product(it1, ..., itN, repeat=1) 计算笛卡儿积:从输入的各个可迭代对象中获取元素,合并成由 N 个元素组成的元组,与嵌套的 for 循环效果一样;repeat 指明重复处理 (内置) zip(it1, ..., itN) 并行从输入的各个可迭代对象中获取元素,产出由 N 个元素组成的元组,只要有一个可迭代的对象到头了,就默默地停止 itertools zip_longest(it1, ..., itN, fillvalue=None) 并行从输入的各个可迭代对象中获取元素,产出由 N 个元素组成的元组,等到最长的可迭代对象到头后才停止,空缺的值使用 fillvalue 填充 -
上述函数测试
-
chain(it1, ..., itN)list(itertools.chain('ABC', range(2))) # ['A', 'B', 'C', 0, 1] -
chain.from_iterable(it)chain.from_iterable 函数从可迭代的对象中获取每个元素,然后按顺序把元素连接起来,前提是各个元素本身也是可迭代的对象
list(itertools.chain(enumerate('ABC'))) # [(0, 'A'), (1, 'B'), (2, 'C')]list(itertools.chain.from_iterable(enumerate('ABC'))) # [0, 'A', 1, 'B', 2, 'C'] -
zip(it1, ..., itN)和zip_longest(it1, ..., itN, fillvalue=None)list(zip('ABC', range(5))) # [('A', 0), ('B', 1), ('C', 2)]list(itertools.zip_longest('ABC', range(5))) # [('A', 0), ('B', 1), ('C', 2), (None, 3), (None, 4)]list(itertools.zip_longest('ABC', range(6), fillvalue='?')) # [('A', 0), ('B', 1), ('C', 2), ('?', 3), ('?', 4)] -
product(it1, ..., itN, repeat=1)计算笛卡儿积的惰性方式
list(itertools.product('ABC', range(2))) # [('A', 0), ('A', 1), ('B', 0), ('B', 1), ('C', 0), ('C', 1)] print(list(itertools.product('AK', suits))) # [('A', 'spades'), ('A', 'hearts'), ('A', 'diamonds'), ('A', 'clubs'), ('K', 'spades'), ('K', 'hearts'), ('K', 'diamonds'), ('K', 'clubs')] list(itertools.product('ABC')) # [('A',), ('B',), ('C',)] print(list(itertools.product('ABC', repeat=2))) # [('A', 'A'), ('A', 'B'), ('A', 'C'), ('B', 'A'), ('B', 'B'), ('B', 'C'), ('C', 'A'), ('C', 'B'), ('C', 'C')] print(list(itertools.product('AB', repeat=3))) # [('A', 'A', 'A'), ('A', 'A', 'B'), ('A', 'B', 'A'), ('A', 'B', 'B'), ('B', 'A', 'A'), ('B', 'A', 'B'), ('B', 'B', 'A'), ('B', 'B', 'B')] print(list(itertools.product('AB', range(2), repeat=2))) # [('A', 0, 'A', 0), ('A', 0, 'A', 1), ('A', 0, 'B', 0), ('A', 0, 'B', 1), ('A', 1, 'A', 0), ('A', 1, 'A', 1), ('A', 1, 'B', 0), ('A', 1, 'B', 1), ('B', 0, 'A', 0), ('B', 0, 'A', 1), ('B', 0, 'B', 0), ('B', 0, 'B', 1), ('B', 1, 'A', 0), ('B', 1, 'A', 1), ('B', 1, 'B', 0), ('B', 1, 'B', 1)]
-
-
有些生成器函数会从一个元素中产出多个值,扩展输入的可迭代对象
把输入的各个元素扩展成多个输出元素的生成器函数
模块 函数 说明 itertools combinations(it, out_len) 把 it 产出的 out_len 个元素组合在一起,然后产出 itertools combinations_with_replacement(it, out_len) 把 it 产出的 out_len 个元素组合在一起,然后产出,包含相同元素的组合 itertools count(start=0, step=1) 从 start 开始不断产出数字,按 step 指定的步幅增加 itertools cycle(it) 从 it 中产出各个元素,存储各个元素的副本,然后按顺序重复不断地产出各个元素 itertools permutations(it, out_len=None) 把 out_len 个 it 产出的元素排列在一起,然后产出这些排列;out_len的默认值等于 len(list(it)) itertools repeat(item, [times]) 重复不断地产出指定的元素,除非提供 times,指定次数 -
上述函数测试
-
count(start=0, step=1)ct = itertools.count() next(ct), next(ct), next(ct) # (0, 1, 2) list(itertools.islice(itertools.count(1, .3), 3)) # [1, 1.3, 1.6] -
cycle(it)cy = itertools.cycle('ABC') list(itertools.islice(cy, 7)) # ['A', 'B', 'C', 'A', 'B', 'C', 'A'] -
repeat(item, [times])repeat 函数的常见用途:为 map 函数提供固定参数,这里提供的是
乘数 5rp = itertools.repeat(7) next(rp), next(rp), next(rp) # (7, 7, 7) list(itertools.repeat(8, 4)) # [8, 8, 8, 8] list(map(operator.mul, range(11), itertools.repeat(5))) # [0, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50] -
combinations(it, out_len)- combinations、combinations_with_replacement 和 permutations 生成器函数,连同 product 函数,称为组合学生成器(combinatoric generator)
- itertools.product 函数和其余的组合学函数有紧密的联系
# 两两组合,不包括自己,顺序无关,相当于排列组合中的组合 list(itertools.combinations('ABC', 2)) # [('A', 'B'), ('A', 'C'), ('B', 'C')] # 两两组合,包括自己,顺序无关 list(itertools.combinations_with_replacement('ABC', 2)) # [('A', 'A'), ('A', 'B'), ('A', 'C'), ('B', 'B'), ('B', 'C'), ('C', 'C')] # 两两组合,不包括自己,顺序有关 list(itertools.permutations('ABC', 2)) # [('A', 'B'), ('A', 'C'), ('B', 'A'), ('B', 'C'), ('C', 'A'), ('C', 'B')] # 两两组合,笛卡尔积,包括自己,顺序有关 print(list(itertools.product('ABC', repeat=2))) # [('A', 'A'), ('A', 'B'), ('A', 'C'), ('B', 'A'), ('B', 'B'), ('B', 'C'), ('C', 'A'), ('C', 'B'), ('C', 'C')]
-
-
最后一组生成器函数用于产出输入的可迭代对象中的全部元素,不过会以某种方式重新排列
用于重新排列元素的生成器函数
模块 函数 说明 itertools groupby(it, key=None) 产出由两个元素组成的元素,形式为 (key, group),其中 key 是分组标准,group 是生成器,用于产出分组里的元素 (内置) reversed(seq) 从后向前,倒序产出 seq 中的元素;seq 必须是序列,或者是实现了 __reversed__特殊方法的对象itertools tee(it, n=2) 产出一个由 n 个生成器组成的元组,每个生成器用于单独产出输入的可迭代对象中的元素 -
上述函数测试
-
groupby(it, key=None)itertools.groupby假定输入的可迭代对象要使用分组标准排序;即使不排序,至少也要使用指定的标准分组各个元素import itertools print(list(itertools.groupby('LLLLAAGGG'))) # [('L', <itertools._grouper object at 0x0000018A1AF32948>), ('A', <itertools._grouper object at 0x0000018A1AF32248>), ('G', <itertools._grouper object at 0x0000018A1AF32708>)] for char, group in itertools.groupby('LLLLAAAGG'): print(char, '->', list(group)) # L -> ['L', 'L', 'L', 'L'] # A -> ['A', 'A', 'A'] # G -> ['G', 'G'] animals = ['duck', 'eagle', 'rat', 'giraffe', 'bear', 'bat', 'dolphin', 'shark', 'lion'] animals.sort(key=len) animals # ['rat', 'bat', 'duck', 'bear', 'lion', 'eagle', 'shark', 'giraffe', 'dolphin'] for length, group in itertools.groupby(animals, len): print(length, '->', list(group)) """ 3 -> ['rat', 'bat'] 4 -> ['duck', 'bear', 'lion'] 5 -> ['eagle', 'shark'] 7 -> ['giraffe', 'dolphin'] """ for length, group in itertools.groupby(reversed(animals), len): print(length, '->', list(group)) """ 7 -> ['dolphin', 'giraffe'] 5 -> ['shark', 'eagle'] 4 -> ['lion', 'bear', 'duck'] 3 -> ['bat', 'rat'] """ -
tee(it, n=2)输入的一个可迭代对象中产出多个生成器,每个生成器都可以产出输入的各个元素
list(itertools.tee('ABC')) # [<itertools._tee at 0x18a1b6ac808>, <itertools._tee at 0x18a1b6ac688>] g1, g2 = itertools.tee('ABC') list(g2), list(g2) # (['A', 'B', 'C'], ['A', 'B', 'C']) list(zip(*itertools.tee('ABC'))) # [('A', 'A'), ('B', 'B'), ('C', 'C')]
-
-
-
Python3.3中新出现的语法:yield from
-
下面两个代码等价
def chain(*iterrables): print(iterrables) for it in iterrables: for i in it: yield idef chain(*iterables): for i in iterables: yield from i -
可以看出,yield from i 完全代替了内层的 for 循环
-
除了代替循环之外,yield from 还会创建通道,把内层生成器直接与外层生成器的客户端联系起来。把生成器当成协程使用时,这个通道特别重要,不仅能为客户端代码生成值,还能使用客户端代码提供的值
-
-
可迭代的归约函数
-
下述函数都接受一个可迭代的对象,然后返回单个结果。这些函数叫“归约”函数、“合拢”函数或“累加”函数
-
这里列出的每个内置函数都可以使用 functools.reduce 函数实现,内置是因为使用它们便于解决常见的问题
-
对 all 和 any 函数来说,有一项重要的优化措施是 reduce 函数做不到的:这两个函数会短路(即一旦确定了结果就立即停止使用迭代器)
-
读取迭代器,返回单个值的内置函数
-
sorted 和这些归约函数只能处理最终会停止的可迭代对象。否则,这些函数会一直收集元素,永远无法返回结果
模块 函数 说明 (内置) all(it) it 中的所有元素都为真值时返回 True,否则返回 False;all([]) 返回 True (内置) any(it) 只要 it 中有元素为真值就返回 True,否则返回 False;any([]) 返回 False (内置) max(it, [key=,][default=])返回 it 中值最大的元素;key 是排序函数,与 sorted 函数中的一样;如果可迭代的对象为空,返回 default (内置) min(it, [key=,][default=])返回 it 中值最小的元素;key 是排序函数,与 sorted 函数中的一样;如果可迭代的对象为空,返回 default functools reduce(func,it,[initial]) 把前两个元素传给 func,然后把计算结果和第三个元素传给 func,以此类推,返回最后的结果;如果提供了initial,把它当作第一个元素传入 (内置) sum(it,start=0) it 中所有元素的总和,如果提供可选的 start,会把它加上(计算浮点数的加法时,可以使用 math.fsum 函数提高精度)
-
-
深入分析iter函数
-
iter 函数还有一个鲜为人知的用法
- 传入两个参数,使用常规的函数或任何可调用的对象创建迭代器
- 这样使用时,第一个参数必须是可调用的对象,用于不断调用(没有参数),产出各个值
- 第二个值是哨符,这是个标记值,当可调用的对象返回这个值时,触发迭代器抛出 StopIteration 异常,而不产出哨符
-
如何使用 iter 函数掷骰子,直到掷出 1 点为止
from random import randint def d6(): return randint(1, 6) d6_iter = iter(d6, 1) for roll in d6_iter: print(roll) -
逐行读取文件,直到遇到空行或者到达文件末尾为止:
with open('mydate.txt') as fp: for line in iter(fp.readline, '\n'): process_line(line)
-
-
案例分析:在数据库转换工具中使用生成器
-
把生成器当成协程
- 与
.__next__()方法一样,.send()方法致使生成器前进到下一个yield 语句 .send()方法还允许使用生成器的客户把数据发给自己,即不管传给.send()方法什么参数,那个参数都会成为生成器函数定义体中对应的 yield 表达式的值- 也就是说,
.send()方法允许在客户代码和生成器之间双向交换数据 - 而
.__next__()方法只允许客户从生成器中获取数据 - 像这样使用的话,生成器就变身为协程
- 虽然在协程中会使用 yield 产出值,但这与迭代无关
- 与
-
杂谈
-
设计模式在各种编程语言中使用的方式并不相同
-
yield 关键字只能把最近的外层函数变成生成器函数
-
虽然生成器函数看起来像函数,可是我们不能通过简单的函数调用把职责委托给另一个生成器函数
-
Python 新引入的 yield from 句法允许生成器或协程把工作委托给第三方完成,这样就无需嵌套 for 循环作为变通了
def f(): def do_yield(n): yield n x=0 while True: x += 1 yield from do_yield(x) -
在协程中,yield 碰巧(通常)出现在赋值语句的右手边,因为 yield 用于接收客户传给 .send() 方法的参数
-
尽管有一些相同之处,但是生成器和协程基本上是两个不同的概念
-
生成器与迭代器的语义对比
- 第一方面是接口
- Python 的迭代器协议定义了两个方法:
__next__和__iter__ - 生成器对象实现了这两个方法,因此从这方面来看,所有生成器都是迭代器
- 由此可以得知,内置的 enumerate() 函数创建的对象是迭代器
- Python 的迭代器协议定义了两个方法:
- 第二方面是实现方式
- 生成器这种 Python 语言结构可以使用两种方式编写:含有 yield 关键字的函数,或者生成器表达式
- 调用生成器函数或者执行生成器表达式得到的生成器对象属于语言内部的 GeneratorType 类型
- 从这方面来看,所有生成器都是迭代器,因为 GeneratorType 类型的实例实现了迭代器接口
- 我们可以编写不是生成器的迭代器,方法是实现经典的迭代器模式
- 从这方面来看,enumerate 对象不是生成器
- types.GeneratorType 类型的定义:生成器-迭代器对象的类型,调用生成器函数时生成
- 第三方面是概念
- 在典型的迭代器设计模式中,迭代器用于遍历集合,从中产出元素
- 不管典型的迭代器中有多少逻辑,都是从现有的数据源中读取值
- 迭代器不能修改从数据源中读取的值,只能原封不动地产出值
- 生成器可能无需遍历集合就能生成值
- 即便依附了集合,生成器不仅能产出集合中的元素,还可能会产出派生自元素的其他值
- 在典型的迭代器设计模式中,迭代器用于遍历集合,从中产出元素
- 第一方面是接口
15. 上下文管理器和else块
- with 语句会设置一个临时的上下文,交给上下文管理器对象控制,并且负责清理上下文
- 这么做能避免错误并减少样板代码,因此 API 更安全,而且更易于使用
- 了自动关闭文件之外,with 块还有很多用途
-
先做这个,再做那个:if语句之外的else块
- else 子句不仅能在if 语句中使用,还能在 for、while 和 try 语句中使用
- else-for:仅当 for 循环运行完毕时(即 for 循环没有被 break 语句中止)才运行 else 块
- else-while:仅当 while 循环因为条件为假值而退出时(即 while 循环没有被 break 语句中止)才运行 else 块
- try-else:仅当 try 块中没有异常抛出时才运行 else 块,else 子句抛出的异常不会由前面的 except 子句处理
- 在所有情况下,如果异常或者 return、break 或 continue 语句导致控制权跳到了复合语句的主块之外,else 子句也会被跳过
- 这里在尝试理解的时候,可以把else理解为then,即,尝试运行这个,然后做那个,意思就是说,在运行for/while/try没有发生问题时,就运行else
-
上下文管理器和with块
-
with 语句的目的是简化 try/finally 模式
-
上下文管理器协议包含
__enter__和__exit__两个方法- with 语句开始运行时,会在上下文管理器对象上调用
__enter__方法 - with 语句运行结束后,会在上下文管理器对象上调用
__exit__方法
- with 语句开始运行时,会在上下文管理器对象上调用
-
执行 with 后面的表达式得到的结果是上下文管理器对象
-
不过,把值绑定到目标变量上(as 子句)是在上下文管理器对象上调用
__enter__方法的结果 -
解释器调用
__enter__方法时,除了隐式的 self 之外,不会传入任何参数 -
传给
__exit__方法的三个参数列举如下:exc_type:异常类(例如 ZeroDivisionError)exc_value:异常实例。有时会有参数传给异常构造方法,例如错误消息,这些参数可以使用 exc_value.args 获取traceback:traceback 对象
-
例子
class LookingGlass: def __enter__(self): import sys self.original_write = sys.stdout.write sys.stdout.write = self.reverse_write return 'JABBERWOCKY' def reverse_write(self, text): self.original_write(text[::-1]) def __exit__(self, exc_type, exc_value, traceback): import sys sys.stdout.write = self.original_write if exc_type is ZeroDivisionError: print(exc_type, exc_value, traceback) print('Please DO NOT divide by zero') return True
-
-
contextlib模块中的实用工具
-
closing:如果对象提供了 close() 方法,但没有实现
__enter__/__exit__协议,那么可以使用这个函数构建上下文管理器 -
suppress:构建临时忽略指定异常的上下文管理器
-
@contextmanager(用得最多):这个装饰器把简单的生成器函数变成上下文管理器,这样就不用创建类去实现管理器协议了
注意:它与迭代无关,却要使用 yield 语句
-
ContextDecorator:这是个基类,用于定义基于类的上下文管理器。这种上下文管理器也能用于装饰函数,在受管理的上下文中运行整个函数
-
ExitStack:这个上下文管理器能进入多个上下文管理器
- with 块结束时,ExitStack 按照后进先出的顺序调用栈中各个上下文管理器的
__exit__方法 - 如果事先不知道 with 块要进入多少个上下文管理器,可以使用这个类
- with 块结束时,ExitStack 按照后进先出的顺序调用栈中各个上下文管理器的
-
-
使用@contextmanager
-
@contextmanager 装饰器能减少创建上下文管理器的样板代码量
-
只需实现有一个 yield 语句的生成器,生成想让
__enter__方法返回的值 -
在使用 @contextmanager 装饰的生成器中,yield 语句的作用是把函数的定义体分成两部分:
- yield 语句前面的所有代码在 with 块开始时(即解释器调用
__enter__方法时)执行 - yield 语句后面的代码在 with 块结束时(即调用
__exit__方法时)执行
- yield 语句前面的所有代码在 with 块开始时(即解释器调用
-
使用生成器实现的上下文管理器
import contextlib @contextlib.contextmanager def looking_glass(): import sys original_write = sys.stdout.write def reverse_write(text): original_write(text[::-1]) sys.stdout.write = reverse_write yield 'JABBERWOCKY' sys.stdout.write = original_write -
其实,contextlib.contextmanager 装饰器会把函数包装成实现
__enter__和__exit__方法的类;类的名称是 _GeneratorContextManager -
这个类的
__enter__方法有如下作用:- 调用生成器函数,保存生成器对象(这里把它称为 gen)
- 调用 next(gen),执行到 yield 关键字所在的位置
- 返回 next(gen) 产出的值,以便把产出的值绑定到 with/as 语句中的目标变量上
-
with 块终止时,
__exit__方法会做以下几件事- 检查有没有把异常传给 exc_type;如果有,调用 gen.throw(exception),在生成器函数定义体中包含 yield 关键字的那一行抛出异常
- 否则,调用 next(gen),继续执行生成器函数定义体中 yield 语句之后的代码
-
处理异常的代码:
import contextlib @contextlib.contextmanager def looking_glass(): import sys original_write = sys.stdout.write def reverse_write(text): original_write(text[::-1]) sys.stdout.write = reverse_write msg = '' try: yield 'JABBERWOCKY' except Exception: msg = '出错啦' finally: sys.stdout.write = original_write if msg: print(msg) -
使用 @contextmanager 装饰器时,要把 yield 语句放在try/finally 语句中(或者放在 with 语句中),这是无法避免的,因为我们永远不知道上下文管理器的用户会在 with 块中做什么
-
用于原地重写文件的上下文管理器
-
-
在 @contextmanager 装饰器装饰的生成器中,yield 与迭代没有任何关系。在本节所举的示例中,生成器函数的作用更像是协程:执行到某一点时暂停,让客户代码运行,直到客户让协程继续做事
-
with 不仅能管理资源,还能用于去掉常规的设置和清理代码,或者在另一个过程前后执行的操作
-
@contextmanager 装饰器优雅且实用,把三个不同的 Python 特性结合到了一起:函数装饰器、生成器和 with 语句
16. 协程
- 字典为动词“to yield”给出了两个释义:产出和让步
- 对于 Python 生成器中的 yield 来说,这两个含义都成立
- yield item 这行代码会产出一个值,提供给 next(...) 的调用方;此外,还会作出让步,暂停执行生成器,让调用方继续工作,直到需要使用另一个值时再调用next()
-
生成器如何进化成协程
- 协程是指一个过程,这个过程与调用方协作,产出由调用方提供的值
.send(...):生成器的调用方可以使用 .send(...) 方法发送数据,发送的数据会成为生成器函数中 yield 表达式的值.throw(...):让调用方抛出异常,在生成器中处理.close():终止生成器
-
用作协程的生成器的基本行为
-
协程使用生成器函数定义:定义体中有 yield 关键字
-
协程可以身处四个状态中的一个
-
当前状态可以使用
inspect.getgeneratorstate(...)函数确定- GEN_CREATED:等待开始执行
- GEN_RUNNING:解释器正在执行
- GEN_SUSPENDED:在 yield 表达式处暂停
- GEN_CLOSED:执行结束
-
仅当协程处于暂停状态时才能调用 send 方法
-
如果协程还没激活(即,状态是 'GEN_CREATED')
- 始终要调用
next(my_coro)激活协程 - 也可以调用
my_coro.send(None),效果一样
- 始终要调用
-
我对yield在协程中使用的理解
def simple_coro2(a): print('-> Started: a =', a) b = yield a print('-> Received: b =', b) c = yield a + b print('-> Received: c =', c)- 拿这个例子为例
b = yield a:也就是说,程序运行到这一行的时候,先执行yield a,相当于return a,前面的b = yield是等待赋值- 然后使用
my_cc.send(28),就是给b赋值了,这一行才算运行结束 - 所以这一行的运行,夹在了两个
next(my_cc)中

-
-
示例:使用协程计算移动平均值
def averager(): total = 0.0 count = 0 average = None while True: term = yield average total += term count += 1 average = total/count- 使用协程之前必须预激
-
预激协程的装饰器
-
为了简化协程的用法,有时会使用一个预激装饰器
from functools import wraps def coroutine(func): """装饰器:向前执行到第一个yield表达式,预激func""" @wraps(func) def primer(*args, **kwargs): gen = func(*args, **kwargs) next(gen) return gen return primer -
需要在协程的函数前面加这个装饰器
@coroutine def averager(): total = 0.0 count = 0 average = None while True: term = yield average total += term count += 1 average = total/count -
这样该协程的初始化的状态就是 GEN_SUSPENDED
from inspect import getgeneratorstate getgeneratorstate(coro_avg) # 'GEN_SUSPENDED' -
很多框架都提供了处理协程的特殊装饰器
- 不是所有装饰器都用于预激协程
- 有些会提供其他服务,例如勾入事件循环
- 比如说,异步网络库 Tornado 提供了 tornado.gen 装饰器
-
使用 yield from 句法调用协程时,会自动预激
-
Python 3.4 标准库里的 asyncio.coroutine 装饰器不会预激协程,因此能兼容 yield from 句法
-
-
终止协程和异常处理
-
协程中未处理的异常会向上冒泡,传给 next 函数或 send 方法的调用方(即触发协程的对象)
-
终止协程的一种方式:发送某个哨符值,让协程退出
-
内置的 None 和 Ellipsis 等常量经常用作哨符值
-
客户代码可以在生成器对象上调用两个方法,显式地把异常发给协程
- generator.throw(exc_type[, exc_value[, traceback]]):致使生成器在暂停的 yield 表达式处抛出指定的异常
- generator.close():致使生成器在暂停的 yield 表达式处抛出 GeneratorExit 异常
-
学习在协程中处理异常的测试代码
class DemoException(Exception): """为这次演示定义的异常类型""" def demo_exc_handling(): print('-> coroutine started') while True: try: x = yield except DemoException: print('*** DemoException handled. Continuing...') else: print('-> coroutine received: {!r}'.format(x)) raise RuntimeError('This line should never run.')- 最后一行代码不会执行,因为只有未处理的异常才会中止那个无限循环,而一旦出现未处理的异常,协程会立即终止
- 激活和关闭 demo_exc_handling,没有异常
- 把 DemoException 异常传入 demo_exc_handling 不会导致协程中止
- 如果无法处理传入的异常,协程会终止
-
使用 try/finally 块在协程终止时执行操作
class DemoException(Exception): """为这次演示定义的异常类型""" def demo_exc_handling(): print('-> coroutine started') try: while True: try: x = yield except DemoException: print('*** DemoException handled. Continuing...') else: print('-> coroutine received: {!r}'.format(x)) finally: print('-> coroutine ending...') raise RuntimeError('This line should never run.') -
Python 3.3 引入 yield from 结构的主要原因
- 与把异常传入嵌套的协程有关
- 让协程更方便地返回值
-
-
让协程返回值
-
定义一个求平均值的协程,让它返回一个结果
from collections import namedtuple Result = namedtuple('Result', 'count average') def averager(): total = 0.0 count = 0 average = None while True: term = yield if term is None: break total += term count += 1 average = total/count return Result(count, average) -
最后发送None的时候,协程结束,返回结果。抛出异常StopIteration,并将return的值保存到异常对象的value属性中
-
如何获取协程的返回值
try: coro_avg.send(None) except StopIteration as exc: result = exc.value result # Result(count=3, average=15.5) -
yield from 结构会在内部自动捕获 StopIteration 异常
-
-
使用yield from
-
yield from 可用于简化 for 循环中的 yield 表达式
-
下述:
def gen(): for c in 'AB': yield c for i in range(1, 3): yield i -
可改写为:
def gen(): yield from 'AB' yield from range(1, 3)
-
-
相关术语
- 委派生成器:包含
yield from <iterable>表达式的生成器函数 - 子生成器:从 yield from 表达式中
<iterable>部分获取的生成器 - 调用方:调用委派生成器的客户端代码
- 委派生成器:包含
-
委派生成器在 yield from 表达式处暂停时,调用方可以直接把数据发给子生成器,子生成器再把产出的值发给调用方
-
子生成器返回之后,解释器会抛出 StopIteration 异常,并把返回值附加到异常对象上,此时委派生成器会恢复

-
如果子生成器不终止,委派生成器会在 yield from 表达式处永远暂停
from collections import namedtuple Result = namedtuple('Result', 'count average') # 子生成器 def averager(): total = 0.0 count = 0 average = None while True: term = yield if term is None: break total += term count += 1 average = total/count return Result(count, average) # 委派生成器 def grouper(results, key): while True: results[key] = yield from averager() # 客户端代码,即调用方 def main(data): results = {} for key, values in data.items(): group = grouper(results, key) next(group) for value in values: group.send(value) # 重要 group.send(None) report(results) # 输出报告 def report(results): for key, result in sorted(results.items()): group, unit = key.split(';') print('{:2}{:5} averaging {:.2f}{}'.format(result.count, group, result.average, unit)) data = { 'girls;kg': [40.9, 38.5, 44.3, 42.2, 45.2, 41.7, 44.5, 38.0, 40.6, 44.5], 'girls;m': [1.6, 1.51, 1.4, 1.3, 1.41, 1.39, 1.33, 1.46, 1.45, 1.43], 'boys;kg': [39.0, 40.8, 43.2, 40.8, 43.1, 38.6, 41.4, 40.6, 36.3], 'boys;m': [1.38, 1.5, 1.32, 1.25, 1.37, 1.48, 1.25, 1.49, 1.46], } if __name__ == '__main__': main(data) -
委派生成器相当于管道,所以可以把任意数量个委派生成器连接在一起
-
一个委派生成器使用 yield from 调用一个子生成器,而那个子生成器本身也是委派生成器,使用 yield from 调用另一个子生成器,以此类推
-
最终,这个链条要以一个只使用 yield 表达式的简单生成器结束;不过,也能以任何可迭代的对象结束
-
任何 yield from 链条都必须由客户驱动,在最外层委派生成器上调用 next(...) 函数或 .send(...) 方法
-
-
yield from 的意义(6点 yield from 的行为)
- 子生成器产出的值都直接传给委派生成器的调用方(即客户端代码)
- 使用 send() 方法发给委派生成器的值都直接传给子生成器。如果发送的值是 None,那么会调用子生成器的
__next__()方法。如果发送的值不是 None,那么会调用子生成器的 send() 方法。如果调用的方法抛出 StopIteration 异常,那么委派生成器恢复运行。任何其他异常都会向上冒泡,传给委派生成器 - 生成器退出时,生成器(或子生成器)中的 return expr 表达式会触发 StopIteration(expr) 异常抛出
- yield from 表达式的值是子生成器终止时传给 StopIteration 异常的第一个参数
yield from 结构的另外两个特性与异常和终止有关
-
传入委派生成器的异常,除了 GeneratorExit 之外都传给子生成器的 throw() 方法。如果调用 throw() 方法时抛出 StopIteration 异常,委派生成器恢复运行。StopIteration 之外的异常会向上冒泡,传给委派生成器
-
如果把 GeneratorExit 异常传入委派生成器,或者在委派生成器上调用 close() 方法,那么在子生成器上调用 close() 方法,如果它有的话。
如果调用 close() 方法导致异常抛出,那么异常会向上冒泡,传给委派生成器;否则,委派生成器抛出 GeneratorExit 异常
- 通过阅读 yield from 的伪代码,我们可以看到代码里已经 预激了子生成器,这说明,用于自动预激的装饰器与 yield from 不兼容
-
使用案例:使用协程做离散时间仿真
-
在计算机科学领域,仿真是协程的经典应用
-
通过仿真系统能说明如何使用协程代替线程实现并发的活动
-
离散事件仿真:Discrete Event Simulation,DES,是一种把系统建模成一系列事件的仿真类型
-
为了实现连续仿真,在多个线程中处理实时并行的操作更自然。而协程恰好为实现离散事件仿真提供了合理的抽象
-
一个示例:说明如何在一个主循环中处理事件,以及如何通过发送数据驱动协程
sim = Simulator(taxis) sim.run(end_time)import queue class Simulator: def __init__(self, procs_map): self.events = queue.PriorityQueue() self.procs = dict(procs_map) def run(self, end_time): #1 """排定并显示事件,直到时间结束""" # 排定各辆出租车的第一个事件 for _, proc in sorted(self.procs.items()): #2 first_event = next(proc) #3 self.events.put(first_event) #4 # 这个仿真系统的主循环 sim_time = 0 #5 while sim_time < end_time: #6 if self.events.empty(): #7 print('*** end of events ***') break current_event = self.events.get() #8 sim_time, proc_id, previous_action = current_event #9 print('taxi:', proc_id, proc_id * ' ', current_event) #10 active_proc = self.procs[proc_id] #11 # 传入前一个动作,把结果加到sim_time上,获得下一次活动的时刻 next_time = sim_time + compute_duration(previous_action) #12 try: next_event = active_proc.send(next_time) #13 except StopIteration: del self.procs[proc_id] #14 else: self.events.put(next_event) #15 else: #16 msg = '*** end of simulation time: {} events pending ***' print(msg.format(self.events.qsize()))
-
-
本章小结:
- 生成器有三种不同代码编写风格:
- 传统的拉取式,迭代器
- 推送式,计算平均值
- 任务式,协程
- 假如没有协程,我们要写一个并发程序。可能有以下问题:
- 使用最常规的同步编程要实现异步并发效果并不理想,或者难度极高
- 由于GIL锁的存在,多线程的运行需要频繁的加锁解锁,切换线程,这极大地降低了并发性能
- 而协程的出现,刚好可以解决以上的问题。它的特点有:
- 协程是在单线程里实现任务的切换的
- 利用同步的方式去实现异步
- 不再需要锁,提高了并发性能
- 深入理解yield from
- 事件驱动型框架(如 Tornado 和 asyncio)的运作方式:
- 在单个线程中使用一个主循环驱动协程执行并发活动
- 使用协程做面向事件编程时,协程会不断把控制权让步给主循环,激活并向前运行其他协程,从而执行各个并发活动
- 这是一种协作式多任务:协程显式自主地把控制权让步给中央调度程序
- 而多线程实现的是抢占式多任务。调度程序可以在任何时刻暂停线程(即使在执行一个语句的过程中),把控制权让给其他线程。
- 宽泛的、不正式的对协程的定义:通过客户调用 .send(...) 方法发送数据或使用 yield from 结构驱动的生成器函数
- asyncio 库建构在协程之上,不过采用的协程定义更为严格
- 在 asyncio 库中,协程(通常)使用 @asyncio.coroutine 装饰器装饰
- 而且始终使用 yield from 结构驱动
- 而不通过直接在协程上调用 .send(...) 方法驱动
- 当然,在 asyncio 库的底层,协程使用 next(...) 函数和 .send(...) 方法驱动,不过在用户代码中只使用 yield from 结构驱动协程运行
- SimPy 是使用标准的 Python 开发的基于进程的离散事件仿真框架,事件调度程序基于 Python 的生成器实现,因此还可用于异步网络或实现多智能体系统(即可模拟,也可真正通信)
- Python 3.5 已经接受了 PEP 492,增加了两个关键字:async 和 await
- Python Async/Await入门指南
- 在3.5过后,我们可以使用async修饰将普通函数和生成器函数包装成异步函数和异步生成器
- 生成器有三种不同代码编写风格:
17. 使用期物处理并发
- 期物:future,期物指一种对象,表示异步执行的操作
- 这个概念的作用很大,是 concurrent.futures 模块和 asyncio 包的基础
-
网络下载的三种风格
-
对并发下载的脚本来说,每次下载的顺序都不同
-
拒绝服务:Denial-of-Service,DoS
-
在 I/O 密集型应用中,如果代码写得正确,那么不管使用哪种并发策略(使用线程或 asyncio 包),吞吐量都比依序执行的代码高很多
-
第一种,直接按顺序下载棋子
import os import time import sys import requests POP20_CC = ('CN IN US ID BR P1K NG BD RU JP MX PH VN ET EG DE IR TR CD FR').split() BASE_URL = 'http://flupy.org/data/flags' DEST_DIR = './downloads/' def save_flag(img, filename): path = os.path.join(DEST_DIR, filename) with open(path, 'wb') as fp: fp.write(img) def get_flag(cc): url = '{}/{cc}/{cc}.gif'.format(BASE_URL, cc=cc.lower()) resp = requests.get(url) return resp.content def show(text): print(text, end=' ') sys.stdout.flush() def download_many(cc_list): for cc in sorted(cc_list): image = get_flag(cc) show(cc) save_flag(image, cc.lower() + '.gif') return len(cc_list) def main(download_many): t0 = time.time() count = download_many(POP20_CC) elapsed = time.time() - t0 msg = '\n{} flags downloaded in {:.2f}s' print(msg.format(count, elapsed)) if __name__ == '__main__': main(download_many) # BD BR CD CN DE EG ET FR ID IN IR JP MX NG P1K PH RU TR US VN # 20 flags downloaded in 21.82s -
第二种,使用
concurrent.futures模块下载from concurrent import futures from flags import save_flag, get_flag, show, main MAX_WORKERS = 20 def download_one(cc): image = get_flag(cc) show(cc) save_flag(image, cc.lower() + '.gif') return cc def download_many(cc_list): # 设定工作的线程数:允许的最大值与要处理的数量之间的 最小值,以免创建多余的线程 workers = min(MAX_WORKERS, len(cc_list)) with futures.ThreadPoolExecutor(workers) as executor: res = executor.map(download_one, sorted(cc_list)) return len(list(res)) if __name__ == '__main__': main(download_many) # BD CD BR TR IR FR JP IN MX VNET PH NG EG CN ID DE P1K US RU # 20 flags downloaded in 1.05s- concurrent.futures 模块的主要特色是 ThreadPoolExecutor 和 ProcessPoolExecutor 类
- 这两个类实现的接口能分别在不同的线程或进程中执行可调用的对象
- 这两个类在内部维护着一个工作线程或进程池,以及要执行的任务队列
-
从 Python 3.4 起,标准库中有两个名为 Future 的类:concurrent.futures.Future 和 asyncio.Future
-
期物封装待完成的操作,可以放入队列,完成的状态可以查询,得到结果(或抛出异常)后可以获取结果(或异常)
-
通常情况下自己不应该创建期物,而只能由并发框架(concurrent.futures 或 asyncio)实例化
-
原因很简单:期物表示终将发生的事情,而确定某件事会发生的唯一方式是执行的时间已经排定
-
因此,只有排定把某件事交给 concurrent.futures.Executor 子类处理时,才会创建 concurrent.futures.Future 实例
-
客户端代码不应该改变期物的状态,并发框架在期物表示的延迟计算结束后会改变期物的状态,而我们无法控制计算何时结束
-
.done():这个方法不阻塞,返回值是布尔值,指明期物链接的可调用对象是否已经执行 -
.add_done_callback():这个方法只有一个参数,类型是可调用的对象,期物运行结束后会调用指定的可调用对象 -
.result():返回可调用对象的结果,或者重新抛出执行可调用的对象时抛出的异常- 如果期物没有运行结束,result 方法在两个 Future 类中的行为相差很大
- 对concurrency.futures.Future 实例来说,调用
f.result()方法会阻塞调用方所在的线程,直到有结果可返回。此时,result 方法可以接收可选的 timeout 参数,如果在指定的时间内期物没有运行完毕,会抛出 TimeoutError 异常 - asyncio.Future.result 方法不支持设定超时时间,在那个库中获取期物的结果最好使用 yield from 结构
-
这两个库中有几个函数会返回期物,其他函数则使用期物,以用户易于理解的方式实现自身
-
Executor.map 方法属于后者:返回值是一个迭代器,迭代器的
__next__方法调用各个期物的result 方法,因此我们得到的是各个期物的结果,而非期物本身 -
concurrent.futures.as_completed:这个函数的参数是一个期物列表,返回值是一个迭代器,在期物运行结束后产出期物 -
把download_many 函数中的 executor.map 方法换成 executor.submit 方法和 futures.as_completed 函数
def download_many(cc_list): cc_list = cc_list[:5] with futures.ThreadPoolExecutor(max_workers=3) as executor: to_do = [] for cc in sorted(cc_list): future = executor.submit(download_one, c) to_do.append(future) msg = 'Scheduled for {}: {}' print(msg.format(cc, future)) results = [] for future in futures.as_completed(to_do): res = future.result() msg = '{} result: {!r}' print(msg.format(future, res)) results.append(res) return len(results) -
GIL:Global Interpreter Lock,全局解释器锁
-
GIL 几乎对 I/O 密集型处理无害
-
-
阻塞型I/O和GIL
- CPython 解释器本身就不是线程安全的,因此有全局解释器锁(GIL),一次只允许使用一个线程执行 Python 字节码
- 因此,一个 Python 进程通常不能同时使用多个 CPU 核心
- 编写 Python 代码时无法控制 GIL;不过,执行耗时的任务时,可以使用一个内置的函数或一个使用 C 语言编写的扩展释放 GIL
- 标准库中所有执行阻塞型 I/O 操作的函数,在等待操作系统返回结果时都会释放 GIL,这意味着在 Python 语言这个层次上可以使用多线程,而 I/O 密集型 Python 程序能从中受益
- 一个 Python 线程等待网络响应时,阻塞型 I/O 函数会释放 GIL,再运行一个线程
-
使用concurrent.futures模块启动进程
- 如果需要做 CPU 密集型处理,使用这个模块的ProcessPoolExecutor类能绕开 GIL,利用所有可用的 CPU 核心
- 对简单的用途来说,ThreadPoolExecutor和ProcessPoolExecutor这两个实现Executor接口的类唯一值得注意的区别是,
ThreadPoolExecutor.__init__方法需要max_workers参数,制定线程池中线程的数量- 在 ProcessPoolExecutor 类中,那个参数是可选的,而且大多数情况下不使用——默认值是
os.cpu_count()函数返回的 CPU 数量
-
实验Executor.map方法
- Executor.map 函数返回结果的顺序与调用开始的顺序一致
- 不过,通常更可取的方式是,不管提交的顺序,只要有结果就获取。为此,要把 Executor.submit 方法和 futures.as_completed 函数结合起来使用
- executor.submit 和 futures.as_completed 这个组合比executor.map 更灵活,因为 submit 方法能处理不同的可调用对象和参数,而 executor.map 只能处理参数不同的同一个可调用对象
- 传给 futures.as_completed 函数的期物集合可以来自多个 Executor 实例
-
显示下载进度并处理错误
- flags2系列示例处理错误的方式
- 使用
futures.as_completed函数 - 线程和多进程的替代方案
- concurrent.futures 是使用线程的最新方式
- 如果
futures.ThreadPoolExecutor类对某个作业来说不够灵活,可能要
使用 threading 模块中的组件(如 Thread、Lock、Semaphore 等)自行制定方案 - 对 CPU 密集型工作来说,要启动多个进程,规避 GIL
- 创建多个进程最简单的方式是,使用 futures.ProcessPoolExecutor 类
- 如果使用场景较复杂,需要更高级的工具。使用 multiprocessing 模块,API 与 threading 模块相仿,不过作业交给多个进程处理
- multiprocessing 模块还能解决协作进程遇到的最大挑战:在进程之间传递数据
-
小结
- 为什么尽管有 GIL,Python 线程仍然适合 I/O 密集型应用:准库中每个使用 C 语言编写的 I/O 函数都会释放 GIL,因此,当某个线程在等待 I/O 时, Python 调度程序会切换到另一个线程
- 借助
concurrent.futures.ProcessPoolExecutor类使用多进程,以此绕
开 GIL,使用多个 CPU 核心运行 - 对于 CPU 密集型和数据密集型并行处理,现在有个新工具可用——分布式计算引擎 Apache Spark,Spark 在大数据领域发展势头强劲,提供了友好的 Python API,支持把 Python 对象当作数据
lelo包:定义了一个@parallel 装饰器,可以应用到任何函数上,把函数变成非阻塞:调用被装饰的函数时,函数在一个新进程中执行python-parallelize包提供了一个 parallelize 生成器,能把 for 循环分配给多个 CPU 执行- 这两个包在内部都使用了 multiprocessing 模块
- GIL 简化了 CPython 解释器和 C 语言扩展的实现,得益于 GIL,Python 有很多 C 语言扩展
- Python 线程特别适合在 I/O 密集型系统中使用
- 在 JavaScript 中,只能通过回调式异步编程实现并发
18. 使用asyncio包处理并发
-
线程与协程对比
-
spinner_thread.py
import threading import itertools import time import sys class Signal: go = True def spin(msg, signal): write, flush = sys.stdout.write, sys.stdout.flush for char in itertools.cycle('|/-\\'): status = char + ' ' + msg write(status) flush() write('\x08' * len(status)) time.sleep(.1) if not signal.go: break write(' ' * len(status) + '\x08' * len(status)) def slow_function(): # 假装等待I/O一段时间 time.sleep(3) return 42 def supervisor(): signal = Signal() spinner = threading.Thread(target=spin, args=('thinking!', signal)) print('spinner object:', spinner) spinner.start() result = slow_function() signal.go = False spinner.join() return result def main(): result = supervisor() print('Answer:', result) if __name__ == '__main__': main() -
Python 没有提供终止线程的 API,这是有意为之的。若想关闭线程,必须给线程发送消息,这里是signal.go属性
-
spinner_asyncio.py:通过协程以动画形式显示文本式旋转指针;使用 @asyncio.coroutine 装饰器替代线程,实现相同的行为
import asyncio import itertools import sys @asyncio.coroutine #1 def spin(msg): #2 write, flush = sys.stdout.write, sys.stdout, flush for char in itertools.cycle('|/-\\'): status = char + ' ' + msg write(status) flush() write('\x08' * len(status)) try: yield from asyncio.sleep(.1) #3 except asyncio.CancelledError: #4 break write(' ' * len(status) + '\x08' * len(status)) @asyncio.coroutine def slow_function(): #5 # 假装等待I/O一段时间 yield from asyncio.sleep(3) #6 return 42 @asyncio.coroutine def supervisor(): #7 spinner = asyncio.async(spin('thinking!')) #8 print('spinner object:', spinner) #9 result = yield from slow_function() #10 spinner.cancel() #11 return result def main(): loop = asyncio.get_event_loop() #12 result = loop.run_until_complete(supervisor()) #13 loop.close() print('Answer:', result) if __name__ == '__main__': main()- 使用
yield from asyncio.sleep(.1)代替time.sleep(.1),这样的休眠不会阻塞事件循环 asyncio.async(...)函数排定 spin 协程的运行时间,使用一个Task 对象包装 spin 协程,并立即返回
- 使用
-
除非想阻塞主线程,从而冻结事件循环或整个应用,否则不要在 asyncio 协程中使用
time.sleep(...)。如果协程需要在一段时间内什么也不做,应该使用yield from asyncio.sleep(DELAY) -
两种 supervisor 实现之间的主要区别概述如下:
- asyncio.Task 对象差不多与 threading.Thread 对象等效
- Task 对象用于驱动协程,Thread 对象用于调用可调用的对象
- Task 对象不由自己动手实例化,而是通过把协程传给
asyncio.async(...)函数或 loop.create_task(...) 方法获取 - 获取的 Task 对象已经排定了运行时间(例如,由
asyncio.async函数排定);Thread 实例则必须调用 start 方法,明确告知让它运行 - 在线程版 supervisor 函数中,slow_function 函数是普通的函数,直接由线程调用。在异步版 supervisor 函数中,slow_function 函数是协程,由 yield from 驱动
- 没有 API 能从外部终止线程,因为线程随时可能被中断,导致系统处于无效状态。如果想终止任务,可以使用 Task.cancel() 实例方法,在协程内部抛出 CancelledError 异常。协程可以在暂停的yield 处捕获这个异常,处理终止请求
- supervisor 协程必须在 main 函数中由 loop.run_until_complete 方法执行
-
asyncio.Future:故意不阻塞- asyncio.Future 类与 concurrent.futures.Future 类的接口基本一致,不过实现方式不同,不可以互换
- asyncio.Future 类的 .result() 方法没有参数,因此不能指定超时时间。此外,如果调用 .result() 方法时期物还没运行完毕,那么.result() 方法不会阻塞去等待结果,而是抛出asyncio.InvalidStateError 异常
- 使用 yield from 处理期物与使用 add_done_callback 方法处理协程的作用一样:延迟的操作结束后,事件循环不会触发回调对象,
而是设置期物的返回值;而 yield from 表达式则在暂停的协程中生成
返回值,恢复执行协程 - 因为 asyncio.Future 类的目的是与 yield from 一起使用,所以通常不需要使用以下方法
- 无需调用 my_future.add_done_callback(...),因为可以直接把想在期物运行结束后执行的操作放在协程中 yield from my_future 表达式的后面。这是协程的一大优势:协程是可以暂停和恢复的函数
- 无需调用 my_future.result(),因为 yield from 从期物中产出的值就是结果(例如,result = yield from my_future)
-
从期物、任务和协程中产出
-
对协程来说,获取 Task 对象有两种主要方式:
asyncio.async(coro_or_future, *, loop=None)BaseEventLoop.create_task(coro)
-
测试脚本中试验期物和协程:
import asyncio def run_sync(coro_or_future): loop = asyncio.get_event_loop() return loop.run_until_complete(coro_or_future) a = run_sync(some_coroutine())
-
-
-
使用asyncio和aiohttp包下载
-
flags_asyncio.py:使用 asyncio 和 aiohttp 包实现的异步下载脚本
import asyncio import aiohttp # 1 from flags import BASE_URL, save_flag, show, main #2 @asyncio.coroutine #3 def get_flag(cc): url = '{}/{cc}/{cc}.gif'.format(BASE_URL, cc=cc.lower()) resp = yield from aiohttp.request('GET', url) #4 image = yield from resp.read() #5 return image @asyncio.coroutine def download_one(cc): #6 image = yield from get_flag(cc) #7 show(cc) save_flag(image, cc.lower() + '.gif') return cc def download_many(cc_list): loop = asyncio.get_event_loop() #8 to_do = [download_one(cc) for cc in sorted(cc_list)] #9 wait_coro = asyncio.wait(to_do) #10 res, _ = loop.run_until_complete(wait_coro) #11 loop.close() #12 return len(res) if __name__ == '__main__': main(download_many)- 虽然函数的名称是 asyncio.wait,但它不是阻塞型函数。wait 是一个协程,等传给它的所有协程运行完毕后结束
- wait 函数有两个关键字参数,如果设定了可能会返回未结束的期物;这两个参数是timeout 和 return_when
-
【我的理解】 协程,就是给函数加上了
@asyncio.coroutine装饰器的函数,然后里面需要等待的地方加上了yield from语句,如果去掉这些语句,就是正常调用的阻塞型流程。 -
yield from foo句法能防止阻塞,是因为当协程(即包含yield from代码的委派生成器)暂停后,控制权回到事件循环手中,再去驱动其他协程;foo期物或协程运行完毕后,把结果返回给暂停的协程,将其恢复。 -
关于 yield from 的用法的两点陈述:
- 使用 yield from 链接的多个协程最终必须由不是协程的调用方驱动,调用方显式或隐式(例如,在 for 循环中)在最外层委派生成器上调用 next(...) 函数或 .send(...) 方法
- 链条中最内层的子生成器必须是简单的生成器(只使用 yield)或 可迭代的对象
-
在 asyncio 包的 API 中使用 yield from 时,上述两点都成立,不过要注意下述细节:
-
我们编写的协程链条始终通过把最外层委派生成器传给 asyncio 包 API 中的某个函数(如 loop.run_until_complete(...))驱动。也就是说,使用 asyncio 包时,我们编写的代码不通过调用 next(...) 函数或 .send(...) 方法驱动协程——这一点由asyncio 包实现的事件循环去做
-
我们编写的协程链条最终通过 yield from 把职责委托给 asyncio 包中的某个协程函数或协程方法(例如:yield from asyncio.sleep(...)),或者其他库中实现高层协议的协程(例如:resp = yield from aiohttp.request('GET', url))
也就是说,最内层的子生成器是库中真正执行 I/O 操作的函数,而
不是我们自己编写的函数
-
-
概括起来就是:使用 asyncio 包时,我们编写的异步代码中包含由 asyncio 本身驱动的协程(即委派生成器),而生成器最终把职责委托给 asyncio 包或第三方库(如 aiohttp)中的协程。这种处理方式相当于架起了管道,让 asyncio 事件循环(通过我们编写的协程)驱动执行低层异步 I/O 操作的库函数
-
-
避免阻塞型调用
- 有两种方法能避免阻塞型调用中止整个应用程序的进程:
- 在单独的线程中运行各个阻塞型操作
- 把每个阻塞型操作转换成非阻塞的异步调用使用
- 为了降低内存的消耗,通常使用回调来实现异步调用
- 使用回调时,我们不等待响应,而是注册一个函数,在发生某件事时调用。这样,所有调用都是非阻塞的
- 只有异步应用程序底层的事件循环能依靠基础设置的中断、线程、轮询和后台进程等,确保多个并发请求能取得进展并最终完成,这样才能使用回调
- 把生成器当作协程使用是异步编程的另一种方式。对事件循环来说,调用回调与在暂停的协程上调用 .send() 方法效果差不多。各个暂停的协程是要消耗内存,但是比线程消耗的内存数量级小。而且,协程能避免可怕的“回调地狱”
- 异步和协程
- 有两种方法能避免阻塞型调用中止整个应用程序的进程:
-
改进asyncio下载版本
-
使用 asyncio.as_completed 函数
-
raise X from Y:链接原来的异常
-
Semaphore对象维护着一个内部计数器,若在对象调用 .acquire() 协程方法,计数器则递减;若在对象上调用 .release() 协程方法,计数器则递增。
-
如果计数器大于0,那么调用 .acquire() 方法不会阻塞;可是,如果计数器为0,那么 .acquire() 方法会阻塞调用这个方法的协程,直到其他协程在同一个Semaphore对象上调用 .release() 方法,让计数器递增。
-
flags2_asyncio.py
import asyncio import collections import aiohttp from aiohttp import web import tqdm from flags2_common import main, HTTPStatus, Result, save_flag # 默认设为较小的值,防止远程网站出错 # 例如503 - Service Temporarily Unavaliable DEFAULT_CONCUR_REQ = 5 MAX_CONCUR_REQ = 1000 class FetchError(Exception): #1 def __init__(self, country_code): self.country_code = country_code @asyncio.coroutine def get_flag(base_url, cc): #2 url = '{}/{cc}/{cc}.gif'.format(base_url, cc=cc.lower()) resp = yield from aiohttp.request('GET', url) if resp.status == 200: image = yield from resp.read() return image elif resp.status == 404: raise web.HTTPNotFound() else: raise aiohttp.HttpProcessingError(code=resp.status, message=resp.reason, headers=resp.headers) @asyncio.coroutine def download_one(cc, base_url, semaphore, verbose): #3 # semaphore: 信号标 try: with (yield from semaphore): #4 image = yield from get_flag(base_url, cc) #5 except web.HTTPNotFound: #6 status = HTTPStatus.not_found msg = 'not found' except Exception as exc: raise FetchError(cc) from exc #7 else: save_flag(image, cc.lower() + '.gif') #8 status = HTTPStatus.ok msg = 'OK' if verbose and msg: print(cc, msg) return Result(status, cc) @asyncio.coroutine def downloader_coro(cc_list, base_url, verbose, concur_req): #1 counter = collections.Counter() semaphore = asyncio.Semaphore(concur_req) #2 to_do = [download_one(cc, base_url, semaphore, verbose) for cc in sorted(cc_list)] #3 to_do_iter = asyncio.as_completed(to_do) #4 if not verbose: to_do_iter = tqdm.tqdm(to_do_iter, total=len(cc_list)) #5 for future in to_do_iter: #6 try: res = yield from future #7 except FetchError as exc: #8 country_code = exc.country_code #9 try: error_msg = exc.__cause__.args[0] #10 except IndexError: error_msg = exc.__cause__.__class__.__name__ #11 if verbose and error_msg: msg = '*** Error for {}: {}' print(msg.format(country_code, error_msg)) status = HTTPStatus.error else: status = res.status counter[status] += 1 #12 return counter #13 def download_many(cc_list, base_url, verbose, concur_req): loop = asyncio.get_event_loop() coro = downloader_coro(cc_list, base_url, verbose, concur_req) counts = loop.run_until_complete(coro) #14 loop.close() #15 return counts if __name__ == '__main__': main(download_many, DEFAULT_CONCUR_REQ, MAX_CONCUR_REQ) -
获取 asyncio.Future 对象的结果,最简单的方法是使用 yield from,而不是调用 future.result() 方法
-
因为失败时不能以期物为键从字典中获取国家代码,所以实现了自定义的 FetchError 异常,包装网络异常,并关联相应的国家代码,因此在详细模式中报告错误时能显示国家代码。
-
-
使用Executor对象,防止阻塞事件循环
-
asyncio 的事件循环在背后维护着一个 ThreadPoolExecutor 对象,我们可以调用 run_in_executor 方法,把可调用的对象发给它执行。
-
在 download_one函数中,save_flag函数会阻塞客户代码与 asyncio 事件循环公用的唯一线程,因此保存文件时,整个应用程序都会冻结。
-
解决方案:
-
之前的 download_one 函数中
@asyncio.coroutine def download_one(cc, base_url, semaphore, verbose): try: ... else: save_flag(image, cc.lower() + '.gif') status = HTTPStatus.ok msg = 'OK' if verbose and msg: ... -
修改之后的代码
@asyncio.coroutine def download_one(cc, base_url, semaphore, verbose): try: ... else: loop = asyncio.get_event_loop() loop.run_in_executor(None, save_flag, image, cc.lower() + '.gif') status = HTTPStatus.ok msg = 'OK' if verbose and msg: ... -
run_in_executor 方法的第一个参数是 Executor 实例,如果设为None,使用事件循环的默认 ThreadPoolExecutor 实例。
-
-
-
从回调到期物和协程
-
使用协程和yield from结构做异步编程,无需使用回调
@asyncio.coroutine def three_stages(request1): reponse1 = yield from api_call1(request1) request2 = step1(response1) response2 = yield from api_call2(request2) request3 = step2(response2) response3 = yield from api_call3(request3) step3(response3) # 必须显示调度执行 loop.create_task(three_stages(request1)) -
每次下载发起多次请求
@asyncio.coroutine def http_get(url): res = yield from aiohttp.request('GET', url) if res.status == 200: ctype = res.headers.get('Content-type', '').lower() if 'json' in ctype or url.endswith('json'): data = yield from res.json() #1 else: data = yield from res.read() #2 return data elif res.status == 404: raise web.HTTPNotFound() else: raise aiohttp.errors.HttpProcessingError(code=res.status, message=res.reason, headers=res.headers) @asyncio.coroutine def get_country(base_url, cc): url = '{}/{cc}/metadata.json'.format(base_url, cc=cc.lower()) metadata = yield from http_get(url) #3 return metadata['country'] @asyncio.coroutine def get_flag(base_url, cc): url = '{}/{cc}/{cc}.gif'.format(base_url, cc=cc.lower()) return (yield from http_get(url)) #4 @asyncio.coroutine def download_one(cc, base_url, semaphore, verbose): try: with (yield from semaphore): #5 image = yield from get_flag(base_url, cc) with (yield from semaphore): country = yield from get_country(base_url, cc) except web.HTTPNotFound: status = HTTPStatus.not_found msg = 'not found' except Exception as exc: raise FetchError(cc) from exc else: country = country.replace(' ', '_') filename = '{}-{}.gif'.format(country, cc) loop = asyncio.get_event_loop() loop.run_in_executor(None, save_flag, image, filename) status = HTTPStatus.ok msg = 'ok' if verbose and msg: print(cc, msg) return Result(status, cc)
-
-
使用asyncio包编写服务器
-
使用asyncio包编写TCP服务器
import sys import asyncio from charfinder import UnicodeNameIndex #1 CRLF = b'\r\n' PROMPT = b'?>' index = UnicodeNameIndex() #2 @asyncio.coroutine def handle_queries(reader, writer): #3 while True: #4 writer.write(PROMPT) # 不能使用yield from #5 yield from writer.drain() # 必须使用 yield from #6 data = yield from reader.readline() #7 try: query = data.decode().strip() except UnicodeDecodeError: #8 query = '\x00' client = writer.get_extra_info('peername') #9 print('Received from {}: {!r}'.format(client, query)) #10 if query: if ord(query[:1]) < 32: #11 break lines = list(index.find_description_strs(query)) #12 if lines: writer.writelines(line.encode() + CRLF for line in lines) #13 writer.write(index.status(query, len(lines)).encode() + CRLF) #14 yield from writer.drain() #15 print('Sent {} results'.format(len(lines))) #16 print('Close the client socket') #17 writer.close() #18 def main(address='127.0.0.1', port=2323): #1 port = int(port) loop = asyncio.get_event_loop() server_coro = asyncio.start_server(handle_queries, address, port, loop=loop) #2 server = loop.run_until_complete(server_coro) #3 host = server.sockets[0].getsockname() #4 print('Serving on {}. Hit CTRL-C to stop.'.format(host)) #5 try: loop.run_forever() #6 except KeyboardInterrupt: # 按CTRL-C键 pass print('Server shutting down.') server.close() #7 loop.run_until_complete(server.wait_closed()) #8 loop.close() #9 if __name__ == '__main__': main(*sys.argv[1:]) #10 -
使用aiohttp包编写Web服务器
-
asyncio.start_server 函数和 loop.create_server 方法都是协程,返回的结果都是 asyncio.Server 对象
-
只有驱动协程,协程才能做事。而驱动 asyncio.coroutine 装饰的协程有两种方法:
- 要么使用 yield from
- 要么传给 asyncio 包中某个参数为协程或期物的函数,例如 run_until_complete
-
更好地支持并发的智能客户端
-
http_charfinder.py
from aiohttp import web import asyncio, sys def home(request): #1 query = request.GET.get('query', '').strip() # 2 print('Query: {!r}'.format(query)) # 3 if query: # 4 descriptions = list(index.find_descriptions(query)) res = '\n'.join(ROW_TPL.format(**vars(descr)) for descr in descriptions) msg = index.status(query, len(descriptions)) else: descriptions = [] res = '' msg = 'Enter words describing characters.' html = template.format(query=query, result=res, message=msg) # 5 print('Sending {} results'.format(len(descriptions))) # 6 return web.Response(content_type=CONTENT_TYPE, text=html) # 7 @asyncio.coroutine def init(loop, address, port): # 1 app = web.Application(loop=loop) #2 app.router.add_route('GET', '/', home) #3 handler = app.make_handler() # 4 server = yield from loop.create_server(handler, address, port) # 5 return server.sockets[0].getsockname() # 6 def main(address='127.0.0.1', port=8889): port = int(port) loop = asyncio.get_event_loop() host = loop.run_until_complete(init(loop, address, port)) # 7 print('Serving on {}. Hit CTRL-C to stop.'.format(host)) try: loop.run_forever() # 8 except KeyboardInterrupt: # 按CTRL-C键 pass print('Server shutting down.') loop.close() # 9 if __name__ == '__main__': main(*sys.argv[1:])
-
-
-
小结:
- 尽管有些函数必然会阻塞,但是为了让程序持续运行,有两种解决方案可用:
- 使用多个线程
- 异步调用——以回调或协程的形式实现
- 异步库依赖于低层线程(直至内核级线程),但是这些库的用户无需创建线程,也无需知道用到了基础设施中的低层线程
- 使用 loop.run_in_executor 方法把阻塞的作业(例如保存文件)委托给线程池做
- 使用协程解决回调的主要问题:执行分成多步的异步任务时丢失上下文,以及缺少处理错误所需的上下文
- 智能的HTTP客户端,例如单页Web应用或智能手机应用,需要快速、轻量级的响应和推送更新。鉴于这样的需求,服务器端最好使用异步框架,不要使用传统的Web框架(如Django)。传统框架的目的是渲染完整的HTML网页,而且不支持异步访问数据库。
- Python 和 Node. js 都有一个问题,而 Go 和 Erlang 从一开始就解决了这个问题:我们编写的代码无法轻松地利用所有可用的 CPU 核心。
- 尽管有些函数必然会阻塞,但是为了让程序持续运行,有两种解决方案可用:
19. 动态属性和特性
-
引子
- property:特性,在不改变类接口的前提下,使用存取方法(即读值方法和设值方法)修改数据属性
- attribute:属性,在Python中,数据的属性和处理数据的方法统称属性。
- 使用点号访问属性时(如 obj.attr),Python 解释器会调用特殊的方法(如
__getattr__和__setattr__)计算属性 - 用户自己定义的类可以通过
__getattr__方法实现“虚拟属性”,当访问不存在的属性时(如 obj.no_such_attribute),即时计算属性的值
-
使用动态属性转换数据
-
使用动态属性访问JSON类数据
from collections import abc class FrozenJson: """一个只读接口,使用属性表示法访问JSON类对象""" def __init__(self, mapping): self.__data = dict(mapping) #1 def __getattr__(self, name): #2 if hasattr(self.__data, name): return getattr(self.__data, name) #3 else: return FrozenJson.build(self.__data[name]) #4 @classmethod def build(cls, obj): #5 if isinstance(obj, abc.Mapping): #6 return cls(obj) elif isinstance(obj, abc.MutableSequence): #7 return [cls.build(item) for item in obj] else: return obj -
从随机源中生成或仿效动态属性名的脚本都必须处理一个问题:原始数据中的键可能不适合作为属性名
-
处理无效属性名
from collections import abc import keyword class FrozenJson: """一个只读接口,使用属性表示法访问JSON类对象""" def __init__(self, mapping): self.__data = {} for key, value in mapping.items(): if keyword.iskeyword(key): key += '_' self.__data[key] = value def __getattr__(self, name): #2 if hasattr(self.__data, name): return getattr(self.__data, name) #3 else: return FrozenJson.build(self.__data[name]) #4 @classmethod def build(cls, obj): #5 if isinstance(obj, abc.Mapping): #6 return cls(obj) elif isinstance(obj, abc.MutableSequence): #7 return [cls.build(item) for item in obj] else: return obj -
使用
__new__方法以灵活的方式创建对象使用
__new__方法取代build方法,构建可能是也可能不是 FrozenJSON 实例的新对象from collections import abc class FrozenJSON: """一个只读接口,使用属性表示法访问JSON类对象""" def __new__(cls, arg): #1 if isinstance(arg, abc.Mapping): return super().__new__(cls) #2 elif isinstance(arg, abc.MutableSequence): #3 return [cls(item) for item in arg] else: return arg def __init__(self, mapping): self.__data = {} for key, value in mapping.items(): if keyword.iskeyword(key): key += '_' self.__data[key] = value def __getattr__(self, name): if hasattr(self.__data, name): return getattr(self.__data, name) else: return FrozenJson(self.__data[name]) #4 -
使用shelve模块调整OSCON数据源的结构
-
shelve.open 高阶函数返回一个 shelve.Shelf 实例,这是简单的键值对象数据库,背后由 dbm 模块支持,具有下述特点:
- shelve.Shelf 是 abc.MutableMapping 的子类,因此提供了处理映射类型的重要方法
- 此外,shelve.Shelf 类还提供了几个管理 I/O 的方法,如 sync 和 close;它也是一个上下文管理器
- 只要把新值赋予键,就会保存键和值
- 键必须是字符串
- 值必须是 pickle 模块能处理的对象
-
schedule1.py:访问保存在 shelve.Shelf 对象里的 OSCON 日程数据
import warnings DB_NAME = 'data/schedule1_db' CONFERENCE = 'conference.115' class Record: def __init__(self, **kwargs): self.__dict__.update(kwargs) #2 def load_db(db): raw_data = load() #3 warnings.warn('loading ' + DB_NAME) for collection, rec_list in raw_data['Schedule'].items(): #4 record_type = collection[:-1] #5 for record in rec_list: key = '{}.{}'.format(record_type, record['serial']) #6 record['serial'] = key #7 db[key] = Record(**record) #8Record.__init__方法展示了一个流行的 Python 技巧。我们知道,对象的__dict__属性中存储着对象的属性——前提是类中没有声明__slots__属性- 因此,更新实例的
__dict__属性,把值设为一个映射,能快速地在那个实例中创建一堆属性
-
-
使用特性获取链接的记录:schedule2.py
import warnings import inspect #1 import osconfeed DB_NAME = 'data/schedule2_db' #2 CONFERENCE = 'conference.115' class Record: def __init__(self, **kwargs): self.__dict__.update(kwargs) def __eq__(self, other): #3 if isinstance(other, Record): return self.__dict__ == other.__dict__ else: return NotImplemented class MissingDatabaseError(RuntimeError): """需要数据哭但没有制定数据库时抛出""" #1 class DbRecord(Record): #2 __db = None #3 @staticmethod #4 def set_db(db): DbRecord.__db = db #5 @staticmethod #6 def get_db(): return DbRecordc.__db @classmethod #7 def fetch(cls, ident): db = cls.get_db() try: return db[ident] #8 except TypeError: if db is None: #9 msg = "database not set; call '{}.set_db(my_db)'" raise MissingDatabaseError(msg.format(cls.__name__)) else: #10 raise def __repr__(self): if hasattr(self, 'serial'): #11 cls_name = self.__class__.__name__ return '<{} serial={!r}>'.format(cls_name, self.serial) else: return super().__repr__() #12 class Event(DbRecord): #1 @property def venue(self): key = 'venue.{}'.format(self.venue_serial) return self.__class__.fetch(key) #2 @property def speakers(self): if not hasattr(self, '_speaker_objs'): #3 spkr_serials = self.__dict__['speakers'] #4 fetch = self.__class__.fetch #5 self._speaker_objs = [fetch('speaker.{}'.format(key)) for key in spkr_serials] #6 return self._speaker_objs #7 def __repr__(self): if hasattr(self, 'name'): #8 cls_name = self.__class__.__name__ return '<{} {!r}>'.format(cls_name, self.name) else: return super().__repr__() #9 def load_db(db): raw_data = osconfeed.load() warnings.warn('loading ' + DB_NAME) for collection, rec_list in raw_data['Schedule'].items(): record_type = collection[:-1] #1 cls_name = record_type.capitalize() #2 cls = globals().get(cls_name, DbRecord) #3 if inspect.isclass(cls) and issubclass(cls, DbRecord): #4 factory = cls #5 else: factory = DbRecord #6 for record in rec_list: #7 key = '{}.{}'.format(record_type, record['serial']) record['serial'] = key db[key] = factory(**record) #8
-
-
使用特性验证属性
-
LineItem类第1版:表示订单中商品的类
class LineItem: def __init__(self, description, weight, price): self.description = description self.weight = weight self.price = price def subtotal(self): return self.weight * self.price -
LineItem类第2版:能验证值的特性
class LineItem: def __init__(self, description, weight, price): self.description = description self.weight = weight self.price = price def subtotal(self): return self.weight * self.price @property def weight(self): return self.__weight @weight.setter def weight(self, value): if value > 0: self.__weight = value else: raise ValueError('value must be > 0')
-
-
特性全解析
-
特性会覆盖实例属性
- 如果实例和所属的类有同名数据属性,那么实例属性会覆盖(或称遮盖)类属性——至少通过那个实例读取属性时是这样
- 属性:类变量(类属性)、成员变量(实例属性)(我的理解)
- 特性:用@property修饰的,特性是类属性(我的理解)
- 同名变量会导致,成员变量覆盖类变量,特性覆盖属性
- 删除特性后,类属性和实例属性,都会恢复
- bj.attr 这样的表达式不会从 obj 开始寻找 attr,而是从
obj.__class__开始,而且,仅当类中没有名为 attr 特性时,Python 才会在 obj 实例中寻找 - 特性 其实是 覆盖型描述符
-
特性的文档
-
控制台中的 help() 函数或 IDE 等工具需要显示特性的文档时,会从特性的
__doc__属性中提取信息 -
weight = property(get_weight, set_weight, doc='weight in kilograms')class Foo: @property def bar(self): '''The bar attribute''' return self.__dict__['bar'] @bar.setter def bar(self, value): self.__dict__['bar'] = value
-
-
-
定义一个特性工厂函数
-
bulkfood_v2prop.py
def quantity(storage_name): #1 def qty_getter(instance): #2 return instance.__dict__[storage_name] #3 def qty_setter(instance, value): #4 if value > 0: instance.__dict__[storage_name] = value #5 else: raise ValueError('value must be > 0') return property(qty_getter, qty_setter) #6 class LineItem: weight = quantity('weight') price = quantity('price') def __init__(self, description, weight, price): self.description = description self.weight = weight self.price = price def subtotal(self): return self.weight * self.price -
对 self.weight 或 nutmeg.weight 的每个引用都由特性函数处理
-
只有直接存取
__dict__属性才能跳过特性的处理逻辑
-
-
处理属性删除操作
-
使用 Python 编程时不常删除属性,通过特性删除属性更少见
-
对象的属性可以使用 del 语句删除
class BlackKnight: def __init__(self): self.members = ['an arm', 'another arm', 'a leg', 'another leg'] self.phrases = ["'Tis but a scratch.'", "It's just a flesh wound.", "I'm invinvible!", "All right, we'll call it a draw."] @property def member(self): print('next member is:') return self.members[0] @member.deleter def member(self): text = 'BLACK KNIGHT (loses {})\n-- {}' print(text.format(self.members.pop(0), self.phrases.pop(0)))
-
-
处理属性的重要属性和函数
-
影响属性处理方式的特殊属性
-
__class__:对象所属类的引用(即obj.__class__与type(obj)的作用相同)。Python 的某些特殊方法,例如__getattr__,只在对象的类中寻找,而不在实例中寻找。 -
__dict__:一个映射,存储对象或类的可写属性。有__dict__属性的对象,任何时候都能随意设置新属性。如果类有__slots__属性,它的实例可能没有__dict__属性。 -
__slots__:类可以定义这个这属性,限制实例能有哪些属性。__slots__属性的值是一个字符串组成的元组,指明允许有的属性。如果__slots__中没有'__dict__',那么该类的实例没有__dict__属性,实例只允许有指定名称的属性。__slots__属性的值虽然可以是一个列表,但是最好始终使用元组,因为处理完类的定义体之后再修改__slots__列表没有任何作用,所以使用可变的序列容易让人误解
-
-
处理属性的内置函数
dir([object]):列出对象的大多数属性- dir 函数能审查有或没有
__dict__属性的对象 - dir 函数不会列出
__dict__属性本身,但会列出其中的键 - dir 函数也不会列出类的几个特殊属性,例如
__mro__、__bases__和__name__
- dir 函数能审查有或没有
getattr(object, name[, default]):从 object 对象中获取 name 字符串对应的属性- 获取的属性可能来自对象所属的类或超类
- 如果没有指定的属性,getattr 函数抛出 AttributeError 异常,或者返回 default 参数的值
hasattr(object, name):如果 object 对象中存在指定的属性,或者能以某种方式(例如继承)通过 object 对象获取指定的属性,返回 Truesetattr(object, name, value):把 object 对象指定属性的值设为 value,前提是 object 对象能接受那个值- 这个函数可能会创建一个新属性,或者覆盖现有的属性
vars([object]):返回 object 对象的__dict__属性- 如果实例所属的类定义了
__slots__属性,实例没有__dict__属性,那么 vars 函数不能处理那个实例 - 如果没有指定参数,那么 vars() 函数的作用与 locals() 函数一样:返回表示本地作用域的字典
- 如果实例所属的类定义了
-
处理属性的特殊方法
-
使用点号或内置的 getattr、hasattr 和 setattr 函数存取属性都会触发下述列表中相应的特殊方法
-
但是,直接通过实例的
__dict__属性读写属性不会触发这些特殊方法 -
如果需要,通常会使用这种方式跳过特殊方法
-
要假定特殊方法从类上获取,即便操作目标是实例也是如此。因此,特殊方法不会被同名实例属性遮盖
-
__delattr__(self, name):只要使用 del 语句删除属性,就会调用这个方法 -
__dir__(self):把对象传给 dir 函数时调用,列出属性 -
__getattr__(self, name):仅当获取指定的属性失败,搜索过 obj、Class 和超类之后调用 -
__getattribute__(self, name):尝试获取指定的属性时总会调用这个方法,不过,寻找的属性是特殊属性或特殊方法时除外为了在获取 obj 实例的属性时不导致无限递归,
__getattribute__方法的实现要使用super().__getattribute__(obj, name) -
__setattr__(self, name, value):尝试设置指定的属性时总会调用这个方法,点号和 setattr 内置函数会触发这个方法
-
-
-
总结:
- 详解Python中的
__init__和__new__ - 在 Python 中,很多情况下类和函数可以互换。这不仅是因为 Python 没有 new 运算符,还因为有特殊的
__new__方法,可以把类变成工厂方法,生成不同类型的对象,或者返回事先构建好的实例,而不是每次都创建一个新实例 - UAP:统一访问原则,Unifrom Access Principle
- new 方法接受的参数虽然也是和 init 一样,但 init 是在类实例创建之后调用,而 new 方法正是创建这个类实例的方法
- 详解Python中的
20. 属性描述符
-
前言
- 描述符是对多个属性运用相同存取逻辑的一种方式
- 描述符是实现了特定协议的类,这个协议包括
__get__、__set__和
__delete__方法 - 除了特性之外,使用描述符的 Python 功能还有方法及 classmethod 和 staticmethod 装饰器
-
描述符示例:验证属性
-
LineItem类第3版:一个简单的描述符
-
描述符的用法是,创建一个实例,作为另一个类的类属性
-
描述符类:实现描述符协议的类
-
托管类:把描述符实例声明为类属性的类
-
描述符实例:描述符类的各个实例,声明为托管类的类属性
-
托管实例:托管类的实例
-
储存属性:托管实例中存储自身托管属性的属性
-
托管属性:托管类中由描述符实例处理的公开属性,值存储在储存属性中。也就是说,描述符实例和储存属性为托管属性建立了基础
-
代码
class Quantity: #1 def __init__(self, storage_name): self.storage_name = storage_name #2 def __set__(self, instance, value): #3 if value > 0: instance.__dict__[self.storage_name] = value #4 else: raise ValueError('value must be > 0') class LineItem: weight = Quantity('weight') #5 price = Quantity('price') #6 def __init__(self, description, weight, price): #7 self.description = description self.weight = weight self.price = price def subtotal(self): return self.weight * self.price
-
-
LineItem类第4版:自动获取储存属性的名称
-
这里可以使用内置的高阶函数 getattr 和 setattr 存取值,无需使用
instance.__dict__,因为托管属性和储存属性的名称不同,所以把储存属性传给 getattr 函数不会触发描述符,不会像前面那样出现无限递归class Quantity: __counter = 0 #1 def __init__(self): cls = self.__class__ #2 prefix = cls.__name__ index = cls.__counter self.storage_name = '_{}#{}'.format(prefix, index) #3 cls.__counter += 1 #4 def __get__(self, instance, owner): #5 return getattr(instance, self.storage_name) #6 def __set__(self, instance, value): #6 if value > 0: setattr(instance, self.storage_name, value) #7 else: raise ValueError('value must be > 0') class LineItem: weight = Quantity() #9 price = Quantity() def __init__(self, description, weight, price): self.description = description self.weight = weight self.price = price def subtotal(self): return self.weight * self.price -
为了给用户提供内省和其他元编程技术支持,通过类访问托管属性时,最好让
__get__方法返回描述符实例def __get__(self, instance, owner): #5 if instance is None: return self else: return getattr(instance, self.storage_name) #6 -
描述符的常规用法:整洁的 LineItem 类;Quantity 描述符类现在位于导入的 model_v4c 模块中
import model_v4c as model class LineItem: weight = model.Quantity() price = model.Quantity() def __init__(self, description, weight, price): self.description = description self.weight = weight self.price = price def subtotal(self): return self.weight * self.price- Django 模型的字段就是描述符
-
使用特性工厂函数实现与上述示例中的描述符类相同的功能
def quantity(): #1 try: quantity.counter += 1 #2 except AttributeError: quantity.counter = 0 #3 storage_name = '_{}:{}'.format('quntity', quantity.counter) #4 def qty_getter(instance): #5 return getattr(instance, storage_name) def qty_setter(instance, value): if value > 0: setattr(instance, storage_name, value) else: raise ValueError('value must be > 0') return property(qty_getter, qty_setter)- 不能依靠类属性在多次调用之间共享 counter,因此把它定义为 quantity 函数自身的属性
- 作者更喜欢描述符类的方式,因为:
- 描述符类可以使用子类扩展;若想重用工厂函数中的代码,除了复制粘贴,很难有其他方法
- 与使用函数属性和闭包保持状态相比,在类属性和实例属性中保持状态更易于理解
- 从某种程度上来讲,特性工厂函数模式较简单,可是描述符类方式更易扩展,而且应用也更广泛
-
-
LineItem类第5版:一种新型描述符
import abc class AutoStorage: #1 __counter = 0 def __init__(self): cls = self.__class__ prefix = cls.__name__ index = cls.__counter self.storage_name = '_{}#{}'.format(prefix, index) cls.__counter += 1 def __get__(self, instance, owner): if instance is None: return self else: return getattr(instance, self.storage_name) def __set__(self, instance, value): setattr(instance, self.storage_name, value) #2 class Validated(abc.ABC, AutoStorage): #3 def __set__(self, instance, value): value = self.validate(instance, value) #4 super().__set__(instance, value) #5 @abc.abstractmethod def validate(self, instance, value): #6 """return validated value or raise ValueError""" class Quantity(Validated): #7 """a number greater than zero""" def validate(self, instance, value): if value <= 0: raise ValueError('value must be > 0') return value class NonBlank(Validated): """a string with at least one ono-space character""" def validate(self, instance, value): value = value.strip() if len(value) == 0: raise ValueError('value cannot be empty or blank') return value #8 class LineItem: description = NonBlank() weight = Quantity() price = Quantity() def __init__(self, description, weight, price): self.description = description self.weight = weight self.price = price def subtotal(self): return self.weight * self.price-
这种描述符也叫覆盖型描述符,因为描述符的
__set__方法使用托管实例中的同名属性覆盖(即插手接管)了要设置的属性 -
上述代码的类图

-
-
-
覆盖型与非覆盖型描述符对比
-
Python 存取属性的方式特别不对等
- 通过实例读取属性时,通常返回的是实例中定义的属性
- 如果实例中没有指定的属性,那么会获取类属性
- 而为实例中的属性赋值时,通常会在实例中创建属性,根本不影响类
-
覆盖型描述符
-
实现
__set__方法的话,会覆盖对实例属性的赋值操作 -
特性也是覆盖型描述符:如果没提供设值函数,property 类中的
__set__方法会抛出 AttributeError 异常,指明那个属性是只读的 -
代码样例
def cls_name(obj_or_cls): cls = type(obj_or_cls) if cls is type: cls = obj_or_cls return cls.__name__.split('.')[-1] def display(obj): cls = type(obj) if cls is type: return '<class {}>'.format(obj.__name__) elif cls in [type(None), int]: return repr(obj) else: return '<{} object>'.format(cls_name(obj)) def print_args(name, *args): pseudo_args = ', '.join(display(x) for x in args) print('-> {}.__{}__({})'.format(cls_name(args[0]), name, pseudo_args)) class Overriding: #1 """也称数据描述符或强制描述符""" def __get__(self, instance, owner): print_args('get', self, instance, owner) #2 def __set__(self, instance, value): print_args('set', self, instance, value) class OverridingNoGet: #3 """没有``__get__``方法的覆盖性描述符""" def __set__(self, instance, value): print_args('set', self, instance, value) class NonOverriding: #4 """也称非数据描述符或遮盖型描述符""" def __get__(self, instance, owner): print_args('get', self, instance, owner) class Managed: #5 over = Overriding() over_no_get = OverridingNoGet() non_over = NonOverriding() def spam(self): #6 print('-> Managed.spam({})'.format(display(self)))
-
-
没有
__get__方法的覆盖型描述符- 实例属性会遮盖描述符,不过只有读操作是如此
- 读取时,只要有同名的实例属性,描述符就会被遮盖
-
非覆盖型描述符
- 没有实现
__set__方法的描述符是非覆盖型描述符 - obj 有个名为 non_over 的实例属性,把 Managed 类的同名描述符属性遮盖掉
- 在上述几个示例中,我们为几个与描述符同名的实例属性赋了值,结果依描述符中是否有
__set__方法而有所不同 - 依附在类上的描述符无法控制为类属性赋值的操作。其实,这意味着为类属性赋值能覆盖描述符属性
- 没有实现
-
在类中覆盖描述符
- 不管描述符是不是覆盖型,为类属性赋值都能覆盖描述符
- 这是一种猴子补丁技术
- 读写属性的另一种不对等:
- 读类属性的操作可以由依附在托管类上定义有
__get__方法的描述符处理 - 但是写类属性的操作不会由依附在托管类上定义有
__set__方法的描述符处理 - 若想控制设置类属性的操作,要把描述符依附在类的类上,即依附在元类上
- 读类属性的操作可以由依附在托管类上定义有
-
-
方法是描述符
- 在类中定义的函数属于绑定方法(bound method)
- 过托管类访问时,函数的
__get__方法会返回自身的引用 - 通过实例访问时,函数的
__get__方法返回的是绑定方法对象:一种可调用的对象,里面包装着函数,并把托管实例(例如 obj)绑定给函数的第一个参数(即 self),这与 functools.partial 函数的行为一致 - function:函数;method:方法
- 函数会变成绑定方法,这是 Python 语言底层使用描述符的最好例证
-
描述符用法建议
- 使用特性以保持简单
- 内置的 property 类创建的其实是覆盖型描述符,
__set__方法和__get__方法都实现了,即便不定义设值方法也是如此 - 特性的
__set__方法默认抛出 AttributeError: can't set attribute - 因此创建只读属性最简单的方式是使用特性,这能避免下一条所述的问题
- 内置的 property 类创建的其实是覆盖型描述符,
- 只读描述符必须有
__set__方法- 如果使用描述符类实现只读属性,要记住,
__get__和__set__两个方法必须都定义 - 否则,实例的同名属性会遮盖描述符
- 只读属性的
__set__方法只需抛出 AttributeError 异常,并提供合适的错误消息
- 如果使用描述符类实现只读属性,要记住,
- 用于验证的描述符可以只有
__set__方法- 对仅用于验证的描述符来说,
__set__方法应该检查 value 参数获得的值,如果有效,使用描述符实例的名称为键,直接在实例的__dict__属性中设置 - 这样,从实例中读取同名属性的速度很快,因为不用经过
__get__方法处理
- 对仅用于验证的描述符来说,
- 仅有
__get__方法的描述符可以实现高效缓存- 如果只编写了
__get__方法,那么创建的是非覆盖型描述符 - 这种描述符可用于执行某些耗费资源的计算,然后为实例设置同名属性,缓存结果
- 同名实例属性会遮盖描述符,因此后续访问会直接从实例的
__dict__属性中获取值,而不会再触发描述符的__get__方法
- 如果只编写了
- 非特殊的方法可以被实例属性遮盖
- 由于函数和方法只实现了
__get__方法,它们不会处理同名实例属性的赋值操作 - 特殊方法不受这个问题的影响
- 释器只会在类中寻找特殊的方法,也就是说,repr(x) 执行的其实是
x.__class__.__repr__(x),因此 x 的__repr__属性对 repr(x) 方
法调用没有影响 - 出于同样的原因,实例的
__getattr__属性不会破坏常规的属性访问规则
- 由于函数和方法只实现了
- 使用特性以保持简单
-
描述符的文档字符串和覆盖删除操作
-
在描述符类中,实现常规的
__get__和(或)__set__方法之外,可以实现__delete__方法,或者只实现__delete__方法做到这一点 -
-
函数:def定义的,或者内置的,或者lambda
与类和实例无绑定关系的function都属于函数(function)
-
方法:跟类有关的,
__init__、def(self)与类和实例有绑定关系的function都属于方法(method)
-
-
21. 类元编程
-
前言
- 类元编程是指在运行时创建或定制类的技艺
- 元类是类元编程最高级的工具:使用元类可以创建具有某种特质的全新类种,例如我们见过的抽象基类
- 除非开发框架,否则不要编写元类
-
类工厂函数
-
record_factory.py:一个简单的类工厂函数
def record_factory(cls_name, field_names): try: field_names = field_names.replace(',', ' ').split() #1 except AttributeError: # 不能调用.replace或.split方法 pass # 假定field_names本就是标识符组成的序列 field_names = tuple(field_names) #2 def __init__(self, *args, **kwargs): attrs = dict(zip(self.__slots__, args)) attrs.update(kwargs) for name, value in attrs.items(): setattr(self, name, value) def __iter__(self): #4 for name in self.__slots__: yield getattr(self, name) def __repr__(self): #5 values = ', '.join('{}={!r}'.format(*i) for i in zip(self.__slots__, self)) return '{}({})'.format(self.__class__.__name__, values) cls_attrs = dict( __slots__ = field_names, __init__ = __init__, __iter__ = __iter__, __repr__ = __repr ) #6 return type(cls_name, (object,), cls_attrs) #7 -
通常,我们把 type 视作函数,因为我们像函数那样使用它。调用 type(my_object) 获取对象所属的类,作用与
my_object.__class__相同 -
type 当成类使用时,传入三个参数可以新建一个类
-
record_factory 函数创建的类,其实例有个局限——不能序列化,即不能使用 pickle 模块里的 dump/load 函数处理
-
-
定制描述符的类装饰器
-
我们要在创建类时设置储存属性的名称,用类装饰器或元类可以做到这一点
-
类装饰器与函数装饰器非常类似,是参数为类对象的函数,返回原来的类或修改后的类
-
model_v6.py:一个类装饰器
def entity(cls): #1 for key, attr in cls.__dict__.items(): #2 if isinstance(attr, Validated): #3 type_name = type(attr).__name__ attr.strorage_name = '_{}#{}'.format(type_name, key) #4 return cls #5 -
类装饰器有个重大缺点:只对直接依附的类有效;这意味着,被装饰的类的子类可能继承也可能不继承装饰器所做的改动,具体情况视改动的方式而定
-
-
导入时和运行时比较
-
在导入时,解释器会从上到下一次性解析完 .py 模块的源码,然后生成用于执行的字节码。如果句法有错误,就在此时报告。如果本地的
__pycache__文件夹中有最新的 .pyc 文件,解释器会跳过上述步骤,因为已经有运行所需的字节码了 -
import 语句,它不只是声明,在进程中首次导入模块时,还会运行所导入模块中的全部顶层代码——以后导入相同的模块则使用缓存,只做名称绑定
-
那些顶层代码可以做任何事,包括通常在“运行时”做的事,例如连接数据库
-
因此,“导入时”与“运行时”之间的界线是模糊的:import 语句可以触发任何“运行时”行为
-
解释器在导入时定义顶层函数,但是仅当在运行时调用函数时才会执行函数的定义体
-
对类来说,情况就不同了:
- 在导入时,解释器会执行每个类的定义体,甚至会执行嵌套类的定义体
- 执行类定义体的结果是,定义了类的属性和方法,并构建了类对象
-
从这个意义上理解,类的定义体属于“顶层代码”,因为它在导入时运行
-
场景演示
-
evalsupport.py
print('<[100]> evalsupport module start') def deco_alpha(cls): print('<[200]> deco_alpha') def inner_1(self): print('<[300]> deco_alpha:inner_1') cls.method_y = inner_1 return cls class MetaAleph(type): print('<[400]> MetaAleph body') def __init__(cls, name, bases, dic): print('<[500]> MetaAleph.__init__') def inner_2(self): print('<[600]> MetaAleph.__init__:init_2') cls.method_z = inner_2 print('<[700]> evalsupport module end') -
evaltime.py
from evalsupport import deco_alpha print('<[1]> evaltime module start') class ClassOne(): print('<[2]> ClassOne body') def __init__(self): print('<[3]> ClassOne.__init__') def __del__(self): print('<[4]> ClassOne.__del_-') def method_x(self): print('<[5]> ClassOne.method_x') class ClassTwo(object): print('<[6]> ClassTwo body') @deco_alpha class ClassThree(): print('<[7]> ClassThree body') def method_y(self): print('<[8]> ClassThree.method_y') class ClassFour(ClassThree): print('<[9]> ClassFour body') def method_y(self): print('<[10]> ClassFour.method_y') if __name__ == '__main__': print('<[11]> ClassOne tests', 30 * '.') one = ClassOne() one.method_x() print('<[12]> ClassThree tests', 30 * '.') three = ClassThree() three.method_y() print('<[13]> CLassFour tests', 30 * '.') four = ClassFour() four.method_y() print('<[14]> evaltime module end') -
结果
>>> import evaltime <[100]> evalsupport module start <[400]> MetaAleph body <[700]> evalsupport module end <[1]> evaltime module start <[2]> ClassOne body <[6]> ClassTwo body <[7]> ClassThree body <[200]> deco_alpha <[9]> ClassFour body <[14]> evaltime module end -
结论:
- 这个场景由简单的 import evaltime 语句触发
- 解释器会执行所导入模块及其依赖(evalsupport)中的每个类定义体
- 解释器先计算类的定义体,然后调用依附在类上的装饰器函数,这是合理的行为,因为必须先构建类对象,装饰器才有类对象可处理
-
-
场景2:
python evaltime.py-
结果
python evaltime.py <[100]> evalsupport module start <[400]> MetaAleph body <[700]> evalsupport module end <[1]> evaltime module start <[2]> ClassOne body <[6]> ClassTwo body <[7]> ClassThree body <[200]> deco_alpha <[9]> ClassFour body <[11]> ClassOne tests .............................. <[3]> ClassOne.__init__ <[5]> ClassOne.method_x <[12]> ClassThree tests .............................. <[300]> deco_alpha:inner_1 <[13]> CLassFour tests .............................. <[10]> ClassFour.method_y <[14]> evaltime module end <[4]> ClassOne.__del_- -
结论:
- 类装饰器可能对子类没有影响
- 当然,如果
ClassFour.method_y方法使用super(...)调用ClassThree.method_y方法,我们便会看到装饰器起作用,执行 inner_1 函数
-
-
-
元类基础知识
-
元类是制造类的工厂,是用于构建类的类
-
根据 Python 对象模型,类是对象,因此类肯定是另外某个类的实例
-
默认情况下,Python 中的类是 type 类的实例
-
type 是大多数内置的类和用户定义的类的元类
-
左边的示意图强调 str、type 和 LineItem 是 object 的子类;右边的示意图则清楚地表明 str、object 和 LineItem 是 type 的实例
![在这里插入图片描述]()
-
object 类和 type 类之间的关系很独特:object 是 type 的实例,而 type 是 object 的子类
-
所有类都直接或间接地是 type 的实例,不过只有元类同时也是 type 的子类
-
元类(如 ABCMeta)从 type 类继承了构建类的能力
![在这里插入图片描述]()
-
所有类都是 type 的实例,但是元类还是 type 的子类,因此可以作为制造类的工厂
-
元类可以通过实现
__init__方法定制实例。元类的__init__方法可以做到类装饰器能做的任何事情,但是作用更大 -
evaltime_meta.py:ClassFive 是 MetaAleph 元类的实例
from evalsupport import deco_alpha from evalsupport import MetaAleph print('<[1]> evaltime_meta module start') @deco_alpha class ClassThree(): print('<[2]> ClassThree body') def method_y(self): print('<[3]> ClassThree.method_y') class ClassFour(ClassThree): print('<[4]> ClassFour body') def method_y(self): print('<[5]> ClassFour.method_y') class ClassFive(metaclass=MetaAleph): print('<[6]> CLassFive body') def __init__(self): print('<[7]> ClassFive.__init__') def method_z(self): print('<[8]> ClassFive.method_z') class ClassSix(ClassFive): print('<[9]> ClassSix body') def method_z(self): print('<[10]> ClassSix.method_z') if __name__ == '__main__': print('<[11]> ClassThree tests', 30 * '.') three = ClassThree() three.method_y() print('<[12]> ClassFour tests', 30 * '.') four = ClassFour() four.method_y() print('<[13]> ClassFive tests', 30 * '.') five = ClassFive() five.method_z() print('<[14]> ClassSix tests', 30 * '.') six = ClassSix() six.method_z() print('<[15]> evaltime_meta module end') -
场景3:在 Python 控制台中以交互的方式导入 evaltime_meta.py 模块
>>> import evaltime_meta <[100]> evalsupport module start <[400]> MetaAleph body <[700]> evalsupport module end <[1]> evaltime_meta module start <[2]> ClassThree body <[200]> deco_alpha <[4]> ClassFour body <[6]> CLassFive body <[500]> MetaAleph.__init__ <[9]> ClassSix body <[500]> MetaAleph.__init__ <[15]> evaltime_meta module end -
场景4:在命令行中运行 evaltime_meta.py 模块
python evaltime_meta.py <[100]> evalsupport module start <[400]> MetaAleph body <[700]> evalsupport module end <[1]> evaltime_meta module start <[2]> ClassThree body <[200]> deco_alpha <[4]> ClassFour body <[6]> CLassFive body <[500]> MetaAleph.__init__ <[9]> ClassSix body <[500]> MetaAleph.__init__ <[11]> ClassThree tests .............................. <[300]> deco_alpha:inner_1 <[12]> ClassFour tests .............................. <[5]> ClassFour.method_y <[13]> ClassFive tests .............................. <[7]> ClassFive.__init__ <[600]> MetaAleph.__init__:init_2 <[14]> ClassSix tests .............................. <[7]> ClassFive.__init__ <[600]> MetaAleph.__init__:init_2 <[15]> evaltime_meta module end -
编写元类时,通常会把 self 参数改成 cls;在元类的
__init__方法中,把第一个参数命名为 cls 能清楚地表明要构建的实例是类 -
装饰器装饰的类产生的效果不会影响其子类;而通过metaclass设置了原类的类,产生的效果会影响其子类
-
-
定制描述符的元类
class EntityMeta(type): """元类,用于创建带有验证字段的业务实体""" def __init__(cls, name, bases, attr_dict): super().__init__(name, bases, attr_dict) #1 for key, attr in attr_dict.items(): #2 if isinstance(attr, Validated): type_name = type(attr).__name__ attr.storage_name = '_{}#{}'.format(type_name, key) class Entity(metaclass=EntityMeta): #3 """带有验证字段的业务实体"""class LineItem(Entity): ... -
元类的特殊方法
__prepare__-
元类或类装饰器获得映射时,属性在类定义体中的顺序已经丢失了(因为名称到属性的映射是字典)
-
这个问题的解决办法是,使用 Python 3 引入的特殊方法
__prepare__ -
这个特殊方法只在元类中有用,而且必须声明为类方法(即,要使用 @classmethod 装饰器定义)
-
解释器调用元类的
__new__方法之前会先调用__prepare__方法,使用类定义体中的属性创建映射 -
__prepare__方法的第一个参数是元类,随后两个参数分别是要构建的类的名称和基类组成的元组,返回值必须是映射 -
元类构建新类时,
__prepare__方法返回的映射会传给__new__方法的最后一个参数,然后再传给__init__方法 -
代码
import collections class EntityMeta(type): """元类,用于创建带有验证字段的业务实体""" @classmethod def __prepare__(cls, name, bases): return collections.OrderedDict() def __init__(cls, name, bases, attr_dict): super().__init__(name, bases, attr_dict) cls._field_names = [] for key, attr in attr_dict.items(): if isinstance(attr, Validated): type_name = type(attr).__name__ attr.storage_name = '_{}#{}'.format(type_name, key) cls._field_names.append(key) class Entity(metaclass=EntityMeta): #3 """带有验证字段的业务实体""" @classmethod def field_names(cls): for name in cls._field_names: yield name -
在现实世界中,框架和库会使用元类协助程序员执行很多任务:
- 验证属性
- 一次把装饰器依附到多个方法上
- 序列化对象或转换数据
- 对象关系映射
- 基于对象的持久存储
- 动态转换使用其他语言编写的类结构
-
-
类作为对象
-
cls.__mro__:类的继承关系和调用顺序,方法解析顺序,Method Resolution Order -
cls.__class__:实例调用__class__属性时会指向该实例对应的类 -
cls.__name__:类、 函数、方法、描述符或生成器对象的名称 -
cls.__bases__:由类的基类组成的元组 -
cls.__qualname__:其值是类或函数的限定名称,即从模块的全局作用域到类的点分路径![在这里插入图片描述]()
-
cls.__subclasses__():这个方法返回一个列表,包含类的直接子类- 这个方法的实现使用弱引用,防止在超类和子类之间出现循环引用
- 子类在
__bases__属性中储存指向超类的强引用 - 这个方法返回的列表中是内存里现存的子类
-
cls.mro():构建类时,如果需要获取储存在类属性__mro__中的超类元组,解释器会调用这个方法;元类可以覆盖这个方法,定制要构建的类解析方法的顺序 -
dir(...)函数不会列出上述提到的任何一个属性
-
-
小结:
- 元类可以定制类的层次结构。类装饰器则不同,它只能影响一个类,而且对后代可能没有影响
dunder:首尾有两条下划线的特殊方法和属性的简洁读法(即把__len__读成“dunder len”)- ORM:Object-Relational Mapper(对象关系映射器)
- REPL:read-eval-print loop(读取-求值-输出循环)的简称
- 绑定方法(bound method):
- 通过实例访问的方法会绑定到那个实例上
- 方法其实是描述符,访问方法时,会返回一个包装自身的对象,把方法绑定到实例上
- 那个对象就是绑定方法
- 调用绑定方法时,可以不传入 self 的值
- 例如,像
my_method = my_obj.method这样赋值之后,可以通过my_method()调用绑定方法
- 并行赋值(parallel assignment):使用类似 a, b = [c, d] 这样的句法,把可迭代对象中的元素赋值给多个变量,也叫解构赋值。这是元组拆包的常见用途。
- 初始化方法(initializer):
__init__方法更贴切的名称(取代构造方法)。__init__方法的任务是初始化通过 self 参数传入的实例。实例其实是由__new__方法构建的。 - 储存属性(storage attribute):托管实例中的属性,用于存储由描述符管理的属性的值
- 在 Python 中,None 对象是单例
- 泛函数(generic function):以不同的方式为不同类型的对象实现相同操作的一组函数,
functools.singledispatch,在其他语言中,这叫多分派方法 - 非绑定方法(unbound method):直接通过类访问的实例方法没有绑定到特定的实例上,因此把这种方法称为“非绑定方法”
- 高阶函数(higher-order function):以其他函数为参数的函数,例如 sorted、map 和 filter;或者,返回值为函数的函数,例如 Python 中的装饰器
- 猴子补丁(monkey patching):在运行时动态修改模块、类或函数,通常是添加功能或修正缺陷
- 猴子补丁在内存中发挥作用,不会修改源码,因此只对当前运行的程序实例有效
- 为猴子补丁破坏了封装,而且容易导致程序与补丁代码的实现细节紧密耦合,所以被视为临时的变通方案,不是集成代码的推荐方式
- 活性(liveness):异步系统、线程系统或分布式系统在“期待的事情终于发生”(即虽然期待的计算不会立即发生,但最终会完成)时展现出来的特性叫活性。如果系统死锁了,活性也就没有了。
- 可散列的(hashable)
- 在散列值永不改变,而且如果 a == b,那么 hash(a) == hash(b) 也是 True 的情况下,如果对象既有
__hash__方法,也有__eq__方法,那么这样的对象称为可散列的对象 - 在内置的类型中,大多数不可变的类型都是可散列的
- 但是,仅当元组的每一个元素都是可散列的时,元组才是可散列的
- 在散列值永不改变,而且如果 a == b,那么 hash(a) == hash(b) 也是 True 的情况下,如果对象既有
- 描述符(descriptor):一个类,实现
__get__、__set__和__delete__特殊方法中的一个或多个,其实例作为另一个类(托管类)的类属性;描述符管理托管类中托管属性的存取和删除,数据通常存储在托管实例中 - 名称改写(name mangling):Python 解释器在运行时自动把私有属性
__x重命名为_MyClass__x - 平坦序列(flat sequence):这种序列类型存储的是元素的值本身,而不是其他对象的引用
- 内置的类型中, str、bytes、bytearray、memoryview 和 array.array 是平坦序列
- 与之相对应的是容器序列,如:list、tuple 和 collections.deque
- 切片(slicing)
- 使用切片表示法生成序列的子集,例如
my_sequence[2:6] - 切片经常复制数据,生成新对象
- 然而,
my_sequence[:]是对整个序列的浅复制 - memoryview 对象的切片虽是一个 memoryview 新对象,但会与源对象共享数据
- 使用切片表示法生成序列的子集,例如
- 弱引用(weak reference):一种特殊的对象引用方式,不计入指示对象的引用计数。弱引用使用 weakref 模块里的某个函数和数据结构创建
- 蛇底式(snake_case):标识符的一种命名约定,使用下划线(_)连接单词,例如
run_until_complete - 生成器函数(generator function):定义体中有 yield 关键字的函数。调用生成器函数得到的是生成器
- 属性(attribute):在 Python 中,方法和数据属性(即 Java 术语中的“字段”)都是属性。方法也是属性,只不过恰好是可调用的对象(通常是函数,但也不一定)
- 特殊方法(special method):名称特殊的方法,首尾各有两条下划线,例如
__getitem__ - 统一访问原则(uniform access principle):Eiffel 语言之父 Bertrand Meyer 写道:“不管服务是由存储还是计算实现的,一个模块提供的所有服务都应该通过统一的方式使用。”
- Python 中,可以使用特性和描述符实现统一访问原则
- 文档字符串(docstring):documentation string 的简称
- 如果模块、类或函数的第一个语句是字符串字面量,那个字符串会当作所在对象的文档字符串,解释器把那个字符串存储在对象的
__doc__属性中
- 如果模块、类或函数的第一个语句是字符串字面量,那个字符串会当作所在对象的文档字符串,解释器把那个字符串存储在对象的
- 虚拟子类(virtual subclass):不继承自超类,而是使用
TheSuperClass.register(TheSubClass)注册的类 - 序列化(serialization):把对象在内存中的结构转换成便于存储或传输的二进制或文本格式,而且以后可以在同一个系统或不同的系统中重建对象的副本。pickle 模块能把任何 Python 对象序列化成二进制格式
- 鸭子类型(duck typing):多态的一种形式,在这种形式中,不管对象属于哪个类,也不管声明的具体接口是什么,只要对象实现了相应的方法,函数就可以在对象上执行操作
- 一等函数(first-class function):在语言中属于一等对象的函数(即能在运行时创建,赋值给变量,当作参数传入,以及作为另一个函数的返回值)。Python 中的函数都是一等函数
- 预激(prime,动词):在协程上调用
next(coro),让协程向前运行到第一个 yield 表达式,准备好从后续的coro.send(value)调用中接收值 - 装饰器(decorator)
- 一个可调用的对象 A,返回另一个可调用的对象 B,在可调用的对象 C 的定义体之前使用句法 @A 调用
- Python 解释器读取这样的代码时,会调用 A(C),把返回的 B 绑定给之前赋予 C 的变量,也就是把 C的定义体换成 B
- 如果目标可调用对象 C 是函数,那么 A 是函数装饰器;如果 C 是类,那么 A 是类装饰器
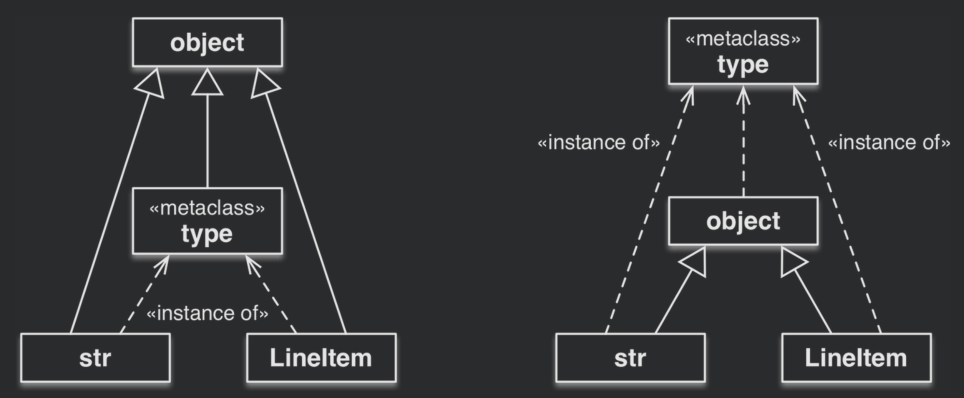
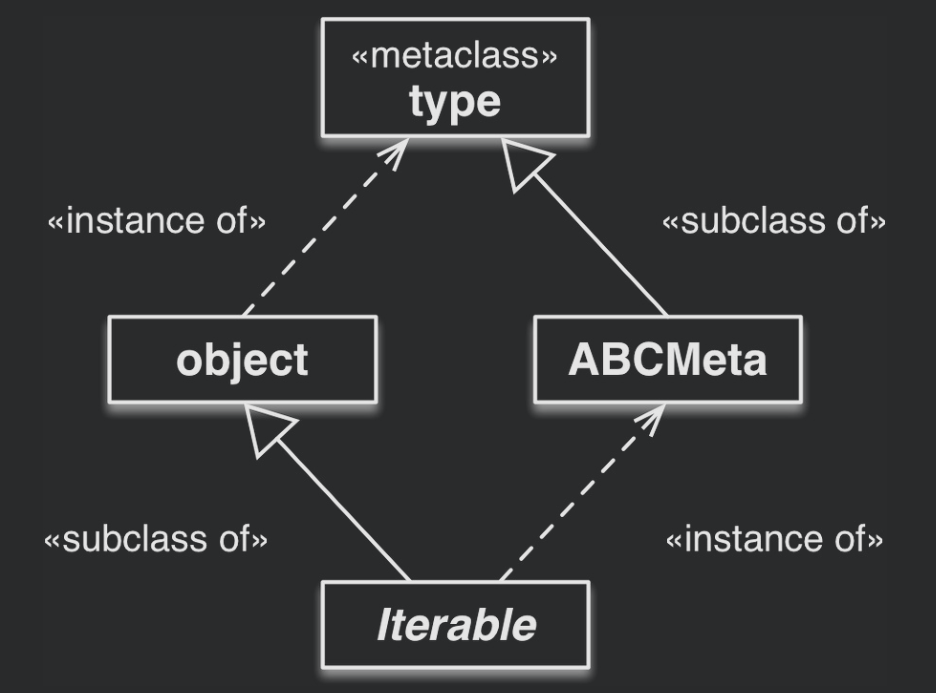
- ☁️ 我的CSDN:https://blog.csdn.net/qq_21579045
- ❄️ 我的博客园:https://www.cnblogs.com/lyjun/
- ☀️ 我的Github:https://github.com/TinyHandsome
- 🌈 我的bilibili:https://space.bilibili.com/8182822
碌碌谋生,谋其所爱。🌊 @李英俊小朋友

 浙公网安备 33010602011771号
浙公网安备 33010602011771号