Poisson分布(转载)
|
Poisson 分布
曹亮吉 |
|
二项分布是离散型机率模型中最有名的一个,其次是Poisson 分布,它可以看成为二项分布的一种极限情形。
假定某机关的总机在一个短时间
我们可以把t分成n小段,每小段长为
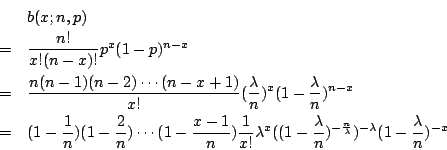
当t保持不变(亦即λ不变),而让
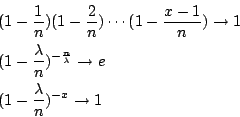
所以
因为
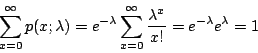 所以
这就是说,在时间t内,接到x次电话的机率为
Simeon D. Poisson(1781~1840年)是一个著名的法国数学家及物理学家。到了晚年,他热衷于将数学的机率论用到司法的运作上。他在这方面的主要著作是1837年出版的《司法机率的研究》(Recherches sur la Probabilité des Jugements)。虽然这本书的主旨是要对司法运作有具体的贡献,但它包含了许多纯粹数学的、机率的理论,所以可以看成是一本以司法应用为例的机率课本,这本书德文版的书名《机率论及其重要应用》(Lehrbuch der Wathrscheinlichkeitsrechnung und deren wichtigstein Auwendungen) 看起来和内容较为一致。在这本书的数学推演中,Poisson 从二项分布的极限得到了这个日后以他为名的机率分布。
Poisson 虽然得到这样的机率分布,但在书中他并没有继续讨论这种分布的性质,在往后的研究中,Poisson 似乎也把它忘掉了。
在十九世纪的许多统计研究报告上,Poisson 这个名字经常出现,但这与Poisson 分布无关,大家所关注的是他在常态分布方面的研究。常态分布在解释理论与数据变异之间的关系非常成功,当时许多人认为常态分布是机率与统计之间唯一的桥梁了。
直到十九世纪末,Bortkiewicz 才注意到Poisson 分布与某些数据之间也有类似的关联。Ladislaus von Bortkiewicz(1868~1931年)是出生在俄国圣彼得堡的波兰人。他在德国Göttingen 大学得到学位(1893年),并曾在Strassburg 做过研究。在Strassburg 时,他写了一本小册子《小数法则》(Das Gesetz der Kleinen Zahlen),专门研究Poisson 分布。他不但在理论方面推演了Poisson 分布的许多性质,并且在应用方面,也比较了一些实际发生的、有关于自杀或意外伤害的数据。Poisson 分布虽然出于Poisson 之手,但真正使它为人重视,使它成为统计学一部分的可要算是Bortkiewicz了。
在这本书中,Bortkiewicz 举了一个至今仍是脍炙人口的例子,说明数据契合Poisson 分布的情形。从1875到1894年的20年间,德国的十四个军团部有士兵被马踢伤因而致死的人数纪录。这20×l4 = 280个(团年)纪录,按死亡人数来分,则如表一的左二栏所示。
在280个纪录中,死亡的人数共有196,因此致死率为 Poisson分布既然是二项分布的极限情形,反过来Poisson分布也可以做为二项分布的近似值。譬如p =0.04 , n =49,则
我们发现对应的值相当接近。一般,若用列表方式,则二项分布b ( x ; n , p )要兼顾三个变数x , n , p,而Poisson只要两个:x ,λ,所以较为方便。若直接计算,则因
b ( x ;49,0.04)= C x 49 (0.04) x (0.96) 49- x
所以二项分布算起来相当费事。另一方面
通常只要n很大,p很小,
由表三可知售量达到5 罐以上的机率只有5.3%,而达到6 罐以上则只有1.7%。所以合理的库存量为4 罐(平均19星期才会有一次缺货),如果怕万一,那么5 罐就非常保险(平均59星期才会有一次缺货)。
我们从另一个角度来看上面的数据。假设某工厂每做100个螺丝钉,平均会有两个不合规格,而这是合理的不合格率。根据Poisson 分布,偶而出现3 个或4 个不合规格的螺丝钉也是正常的现象。但是如果出现的频率太高,或出现5 个以上的不合规格的螺丝钉,那么生产过程就可能出了问题。Poisson 分布是品质管制的利器,它可以帮助我们决定生产过程是否出了毛病。
Poisson 分布还有种种的用途:放射性物质的蜕变、细胞间因受X 光照射而引起的染色体交换次数、细菌和血球的计数、交通事故数及死亡率等等莫不遵行Poisson 分布。其实,无论在自然科学、在工业、在农业、在商业、在医药、在交通、在社会或在军事上,无不可找到Poisson 分布的应用。
和二项分布一样,我们也可以从理论方面来探讨Poisson分布的期望值μ及散布差
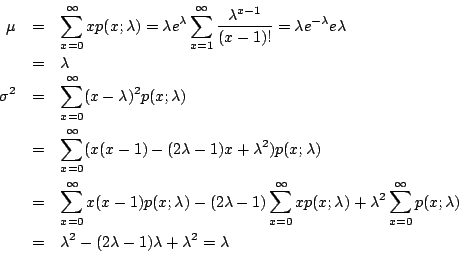
所以Poisson 分布的确是以λ 为期望值。
在〈二项分布与大数法则〉(《科学月刊》第十六卷第六期)一文中,我们曾导出二项分布的Chebyshev不等式
如果把二项分布换成Poisson分布或任何离散型分布,不等式也照样成立,因为在导出不等式的过程中只用到b ( x ; n , p )是种机率分布这件事,并没有用到b ( x ; n , p)之值。现在既然知道Poisson分布的
亦即:在Poisson分布的机率模型假定之下,只要试验的次数n够大,则事件发生的次数比 |
来自:http://episte.math.ntu.edu.tw/articles/sm/sm_16_07_1/index.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号