在Windows的IDEA上直接运行MapReduce
链接:https://pan.baidu.com/s/1vLGtYVv1VLJqaXY6LAsuLA
提取码:lycc
1、将下载好的hadoop-2.7.6.tar.gz包解压到任意目录
2、将下载的winutils-master.rar解压,选择自己的版本
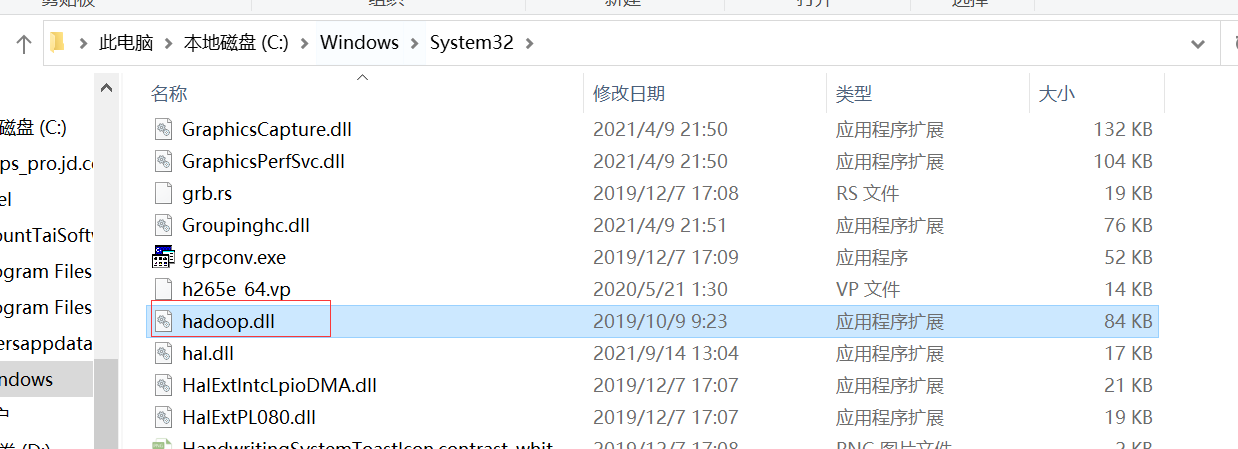
将bin目录下的hadoop.dll文件复制到C:\Windows\System32目录下
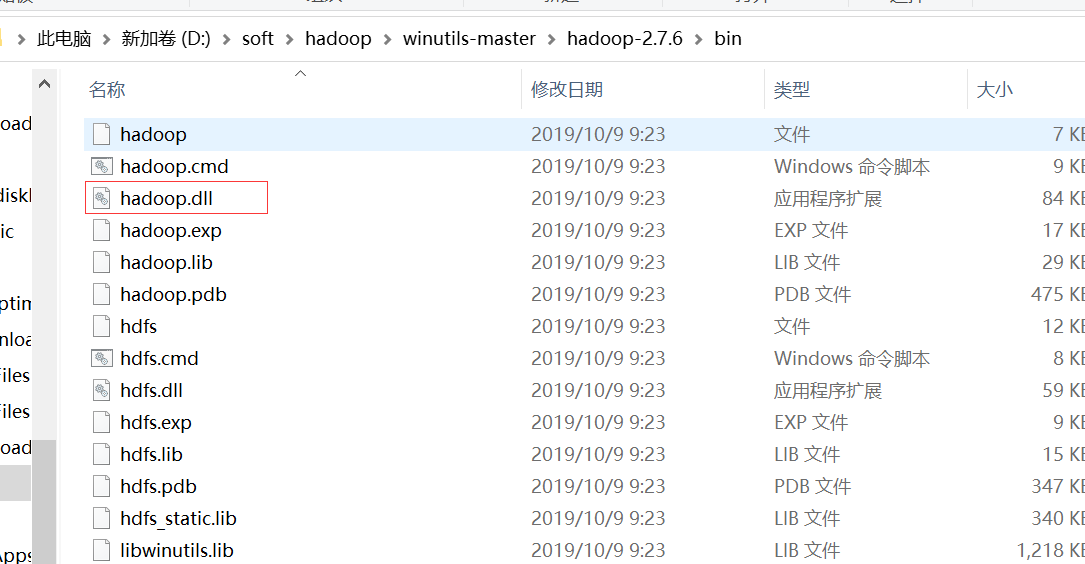
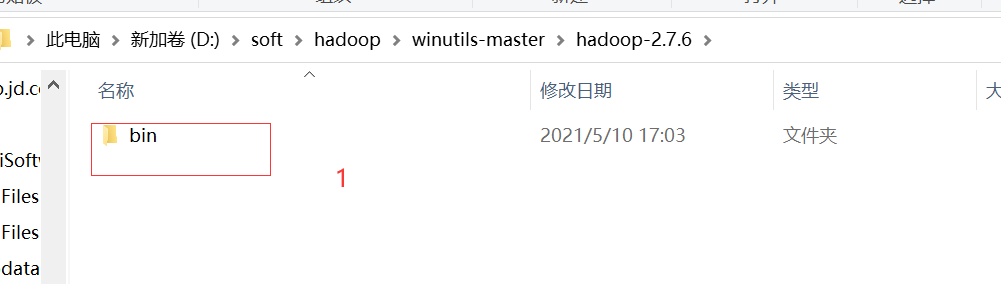
3、将下载的编译好的hadoop的bin目录①复制到解压hadoop-2.7.6.tar.gz的目录下替换bin②
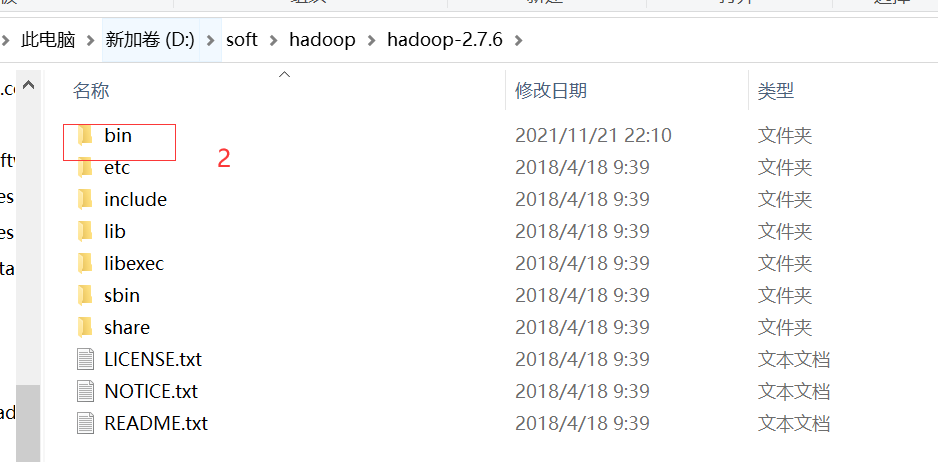
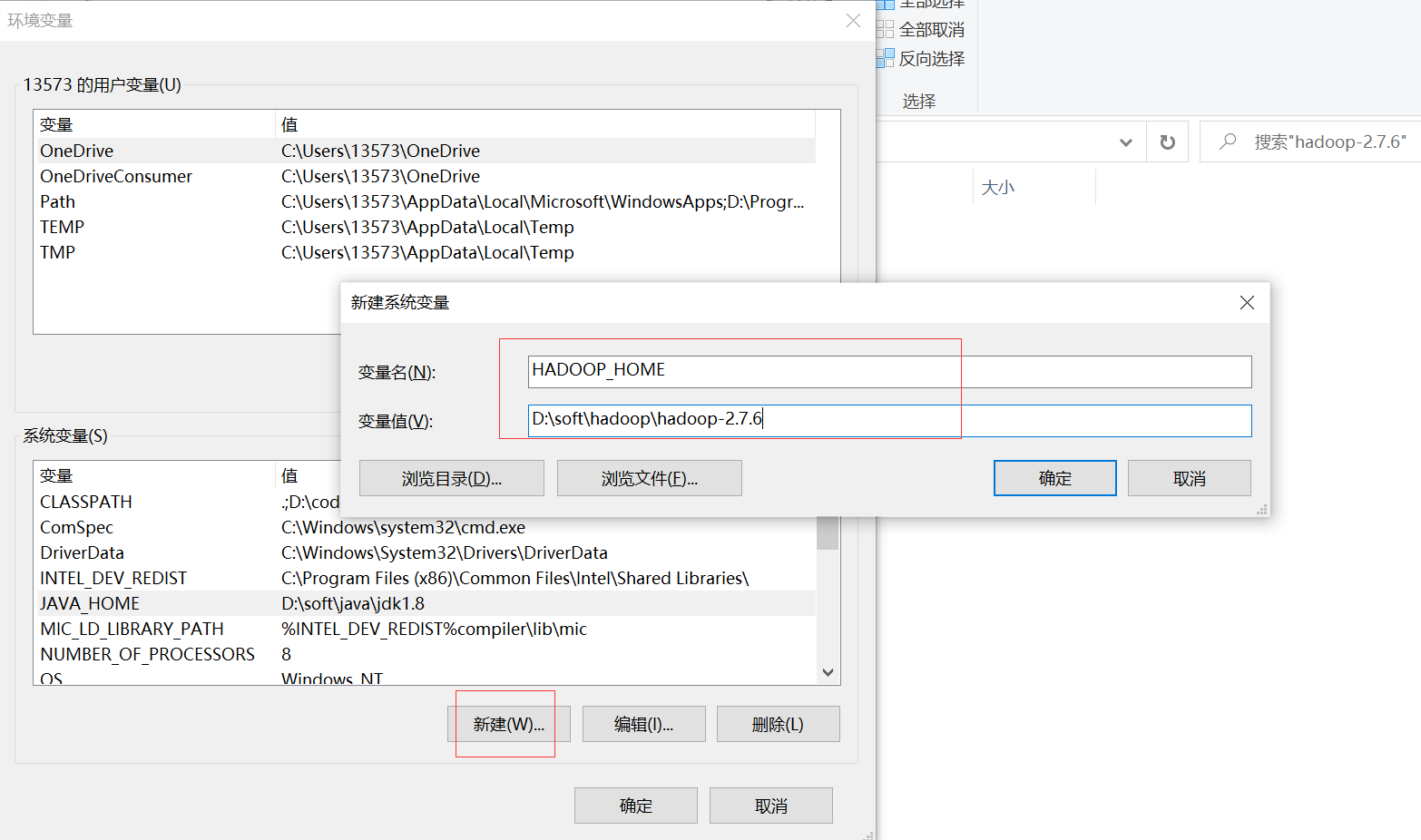
4、配置Windows环境变量
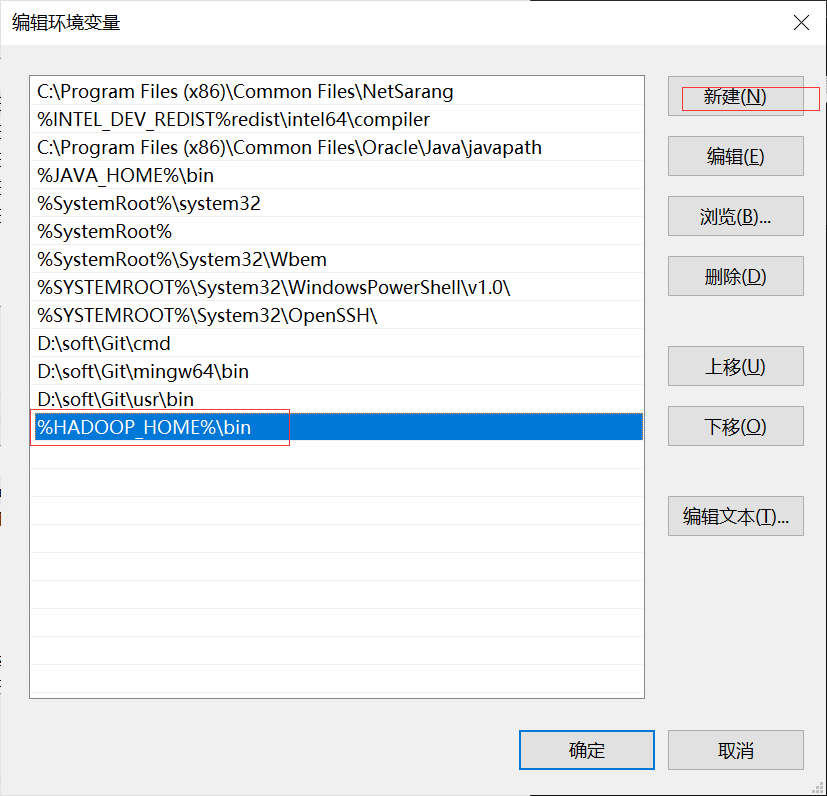
将变量添加到Path
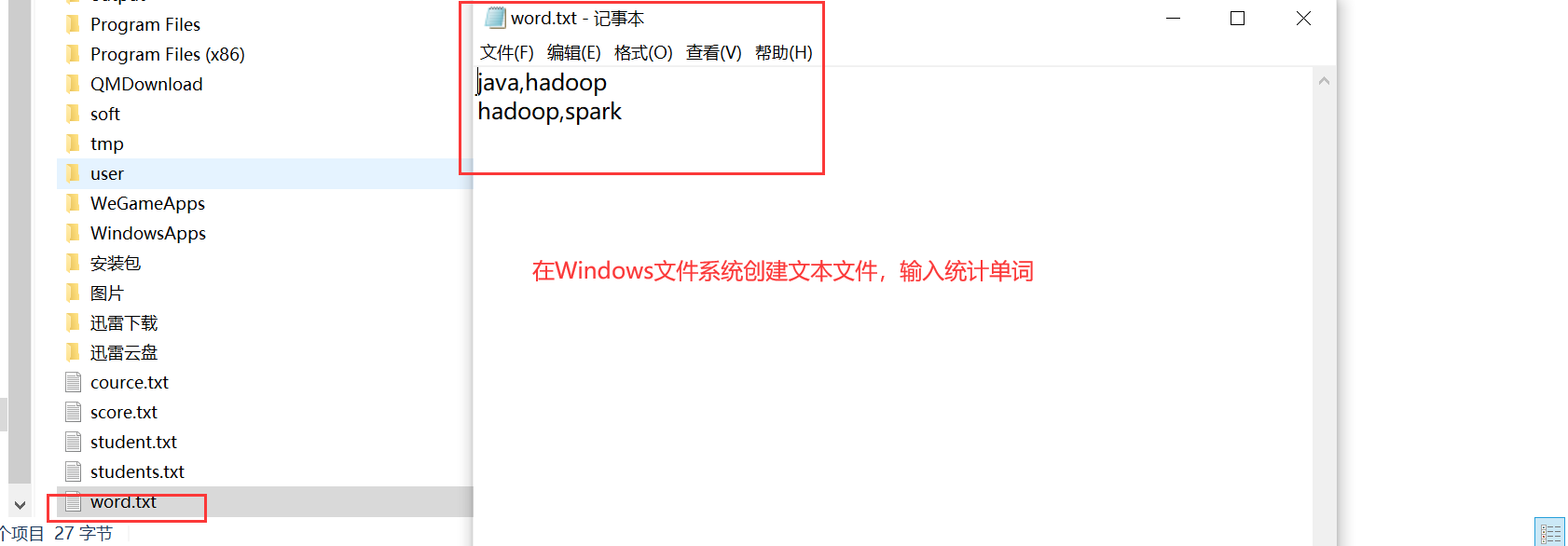
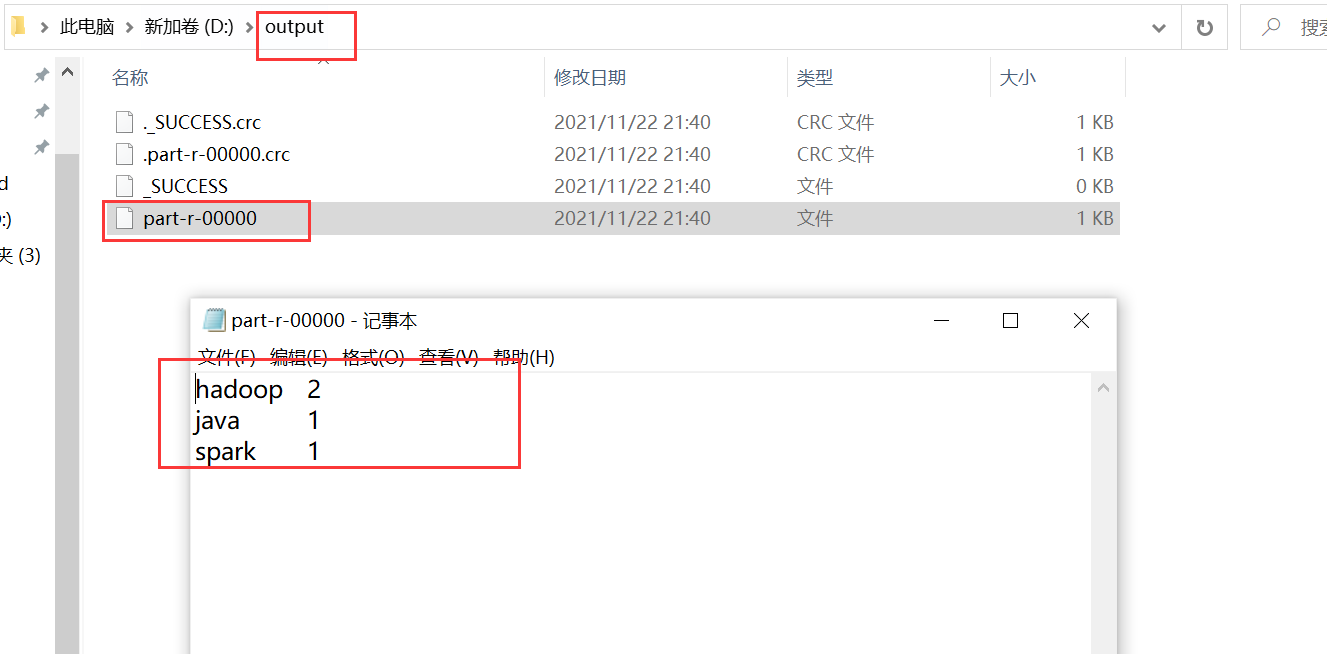
现在就可以直接在IDEA中运行MapReduce程序即可
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /** * 单词统计 * map阶段 分组 java:1 java:1 hadoop:1 hadoop:1 * reduce阶段 聚合 java:{1,1} hadoop:{1,1} java:2 */ public class MR02 { public static class WordMapper extends Mapper<LongWritable,Text,Text,LongWritable>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] words = line.split(","); for (String word : words) { context.write(new Text(word),new LongWritable(1)); } } } //中间通过suffer阶段合并排序 // key:{1,1,1,1,1,1....} public static class WordReduce extends Reducer<Text,LongWritable,Text,LongWritable>{ @Override protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException { //统计每个单词的累加结果 int count = 0; for (LongWritable value : values) { count+=value.get(); } context.write(key,new LongWritable(count)); } } // maia方法中构建mapreduce任务 通过Job类构建 public static void main(String[] args) throws Exception { Job job = Job.getInstance(); job.setJobName("统计每行多少单词"); job.setJarByClass(MR02.class); //mapreduce的输出格式 job.setMapperClass(WordMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class); job.setReducerClass(WordReduce.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); //指定路径 注意:输出路径不能已存在,输入输出路径指定Windows文件系统文件路径 Path input = new Path("D:\\word.txt"); Path output = new Path("D:\\output"); FileInputFormat.addInputPath(job,input); //路径不能已存在 // 手动加上 如果存在就删除 FileSystem FileSystem fileSystem = FileSystem.get(new Configuration()); if (fileSystem.exists(output)){ fileSystem.delete(output,true);//true代表迭代删除多级目录 } FileOutputFormat.setOutputPath(job,output); //启动job job.waitForCompletion(true); System.out.println("统计一行多少个单词"); } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号