通过索引进行优化
一、索引的格式
为什么不用hash表的索引格式?
1、hash存储需要将所有的数据文件添加到内存中,比较耗费内存空间
2、如果等值查询,hash定位会很快,但是企业中或工作中范围查找会更多,因此hash就不合适了
当链表长度达到8,节点个数达到64时会由链表转换为红黑树
为什么不用二叉树的索引格式?
二叉树的索引格式会造成树节点过深,I/O次数增加
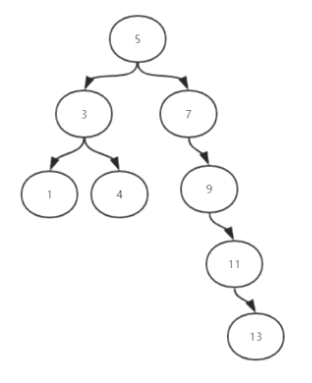
为什么不用平衡树(AVL)的索引格式?
为了保证平衡,在插入节点时会进行旋转(左、右),保证最短子树和最长子树长度不能超过1。旋转过程浪费时间,插入删除效率极低,查询效率较高。
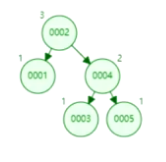
为什么不用红黑树的索引格式?
红黑树要求最长子树不超过最短子树的二倍即可。损失了部分查询性能来增加增删操作。
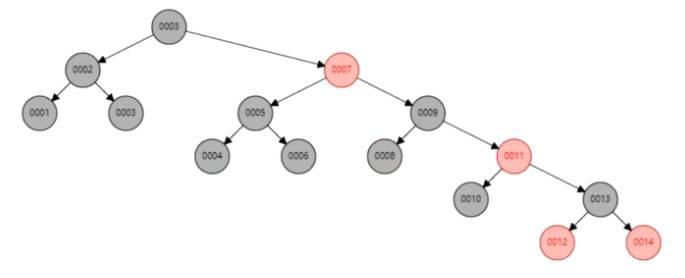
左旋:逆时针旋转,父节点被孩子取代,而自己成为自己的左孩子
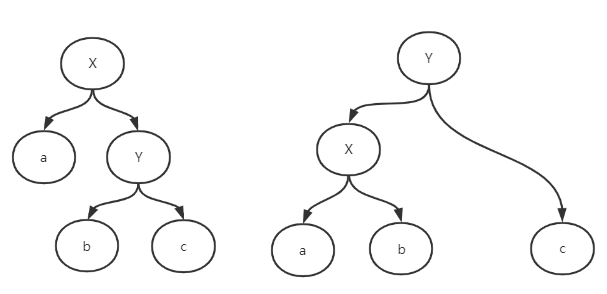
右旋:顺时针旋转,父节点被孩子取代,而自己成为自己的右孩子

为什么不用B-tree的索引格式?
B-tree中非叶子节点中带有数据存储信息,数据信息占用了空间,会导致存储索引信息变小
最终改进B+tree作为索引格式
在B-tree树的基础上,将非叶子节点中用于存储数据的空间去除,将所有数据全部放到叶子节点中,这样会节省空间,提高索引效率
在B+tree树中叶子节点之间为双向链表
二、索引分类
主键索引、唯一索引、普通索引、全文索引、组合索引
三、面试技术名词
1、回表:Innodb默认情况下会为主键创建索引。某些情况下我们会为普通列创建索引,为普通列创建的索引中的叶子节点中存储的是主键Id
查询流程:根据索引中B+树搜索到主键id,根据主键id到主键B+树中取出最终结果,遍历了2遍B+树
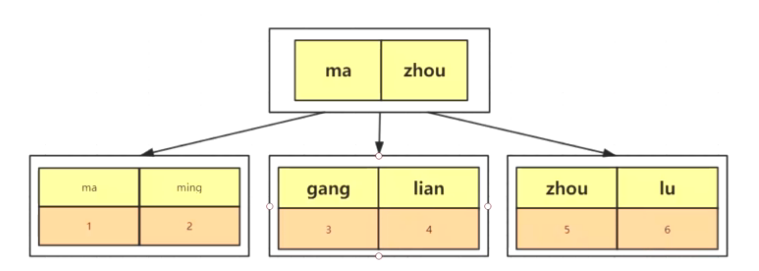
select * from emp where name = '1';
如图,最下面数据为主键,要根据name找到主键,再去搜索主键B+tree找到完整信息
2、覆盖索引:回表的过程没有了就称作索引覆盖,即通过一次B+tree的搜索就可以得到结果,不需要回表操作
select id from emp where name = '1';
首先根据name找到主键,但是此时得到的主键已经为最终想要得到的结果,减少了一次搜索B+tree
3、最左匹配:有一个联合索引(name,age)
当执行select * from emp where name = ? and age = ?时可以使用该索引
当执行sql:select * from emp where age = ?时该索引不生效
特殊情况:
select * from emp where name = ? and age = ?;
select * from emp where name = ?;
select * from emp where age = ?;
有两种索引创建形式:a:name,age的组合索引,再单独创建name索引
b:age,name的组合索引,再单独创建age索引
此时选b:索引是要持久化保存的,单独创建age索引占用的空间比单独创建name索引占用的空间小
4、索引下推:有一个联合索引(name,age)
之前的情况会先按照name从存储引擎中取出值,到server层中再去 过滤age
现在的情况会在按照name从存储引擎中取值的时候同事按照age过滤
四、索引匹配方式
建表及创建索引信息:
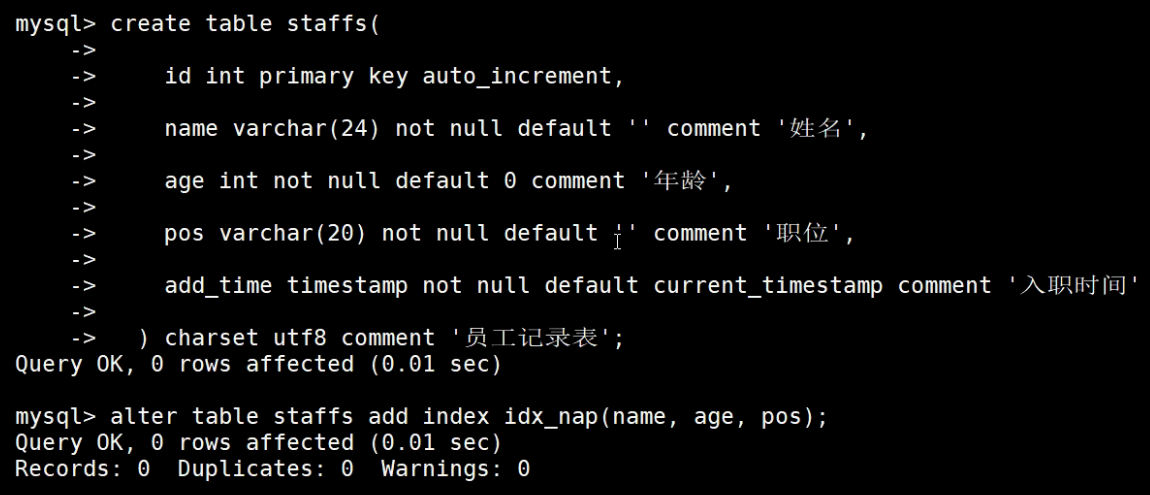
1、全值匹配:和索引中的全部列进行匹配

一个const表示用到索引中的一列
2、匹配最左前缀:只匹配前面的几列

上图中按照name搜索,name列在创建索引时在最前面,走的匹配最左前缀
3、匹配列前缀:可以匹配某一列的值的开头部分

模糊匹配不走索引

在使用索引时,如果%放在最前面是不会走索引的,上图type为all(一行一行匹配)
4、匹配范围值:可以查找某一范围的数据

5、精确匹配某一列并范围匹配另外一列:可以查询第一列的全部和第二列的部分

注意:下图中pos不走索引,因为创建索引的顺序是name、age、pos,但是没有age,pos也不会生效
所以下图中ref是const,type为ref不为range

6、只访问索引的查询:查询的时候只需要访问索引,不需要访问数据行,本质上就是覆盖索引

extra列显示为Using index表示使用了覆盖索引,即所有查找的列都设置有索引
注意: 创建组合索引a,b,c后。当b使用的范围查找或者模糊匹配时,c是不会走索引的
where a=10 and b>10 and c=1; 此时c不会走索引
where a=10 and b like '啊%' and c=1; 此时c不会走索引
where a=10 and b like '%啊%' and c=1; 此时b,c都不会走索引
优化小细节
需要使用union或union all时建议使用union all,因为union会进行distinct去重,去重会消耗很大性能
作者:http://cnblogs.com/lyc-code/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号