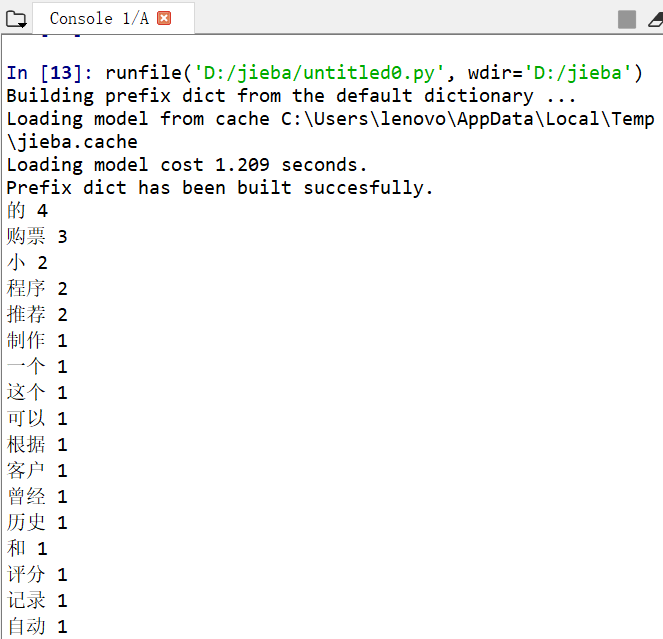
jieba库词频统计练习

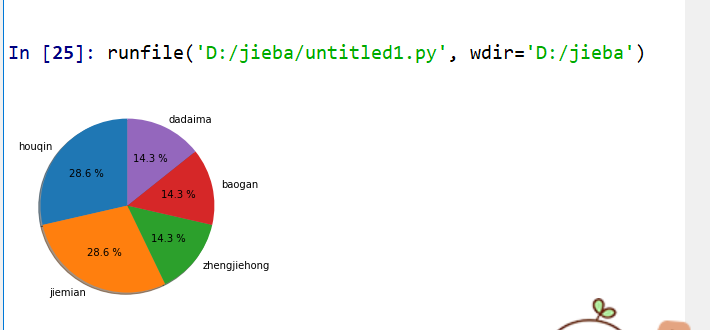
在sypder上运行jieba库的代码:
import matplotlib.pyplot as plt
fracs = [2,2,1,1,1]
labels = 'houqin', 'jiemian', 'zhengjiehong','baogan','dadaima'
explode = [ 0,0,0,0,0]
plt.axes(aspect=1)
plt.pie(x=fracs, labels=labels, explode=explode,autopct='%3.1f %%',
shadow=True, labeldistance=1.1, startangle = 90,pctdistance = 0.6)
plt.show()
运行结果如图:
饼图制作代码:
import jieba
import collections
s="暂定做微信小程序,具体还需队伍学习协商定下最终计划。"
s+="郑杰鸿:擅长Python、Java。爆肝打代码角色。无事Debug,有事120。"
s+="梁旖:随性风格,后勤角色,无,后勤。坚持就是胜利,活着就是奇迹。"
s+="庄子庆:边学边死磕型,有耐心做大量的无趣工作。比较喜欢设计界面。做界面的角色。介系李没有体验过的船新版本。"
s1=jieba.cut(s)
k=[]
l=['、',',','。',';','!',':']
for i in s1:
if i not in l:
k.append(i)
count=collections.Counter(k)
for a,b in count.most_common():
print(a,b)
运行结果如图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号