达梦表关联理解测试(一)
一、 表关联理论理解
表关联查询在数据库的SQL语句中存在非常普遍,在常见的关系型数据库中,主要存在三种形式的表关联,分别是:嵌套循环连接、哈希连接、归并排序连接,在达梦数据库中,支持对于表的三种关联方式,主要表现形式是:
- NEST LOOP
- HASH JOIN
- MERGE JOIN
其中NEST LOOP根据连接列是否有索引,主要分为内连接和索引连接两种形式,这些连接方式在执行计划中均有相应的操作符进行标识,分别是:
- NEST LOOP INNER JOIN/NEST LOOP INDEX JOIN
- HASH INNER JOIN
- MERGE INNER JOIN
对于以上的三种连接方式,在何种场景下会使用,执行的原理进行说明:
- NEST LOOP
此种连接方式主要使用于被连接的数据子集较小的情况,NEST LOOP其实现原理就是扫描一个较小的表(称为驱动表或者外表,当然,也可以是根据查询条件筛选后的数据量较小),每读一条记录,就根据join字段上的索引去另外一张大表(称为被驱动表或者内表)里面查找所有符合join条件的记录,直到驱动表的数据全部查询完成,过程中,驱动表返回多少记录,就需要循环扫描大表多少次,所以必须保证驱动表返回记录较少,并且被驱动表的join列必须有索引。直到两个表的查询都完成,返回结果集进行展示或者传递给其他关联表,继续其他的表关联。这种查询的特点决定了其使用场景如下:
- 驱动表很小或者过滤条件很好,只返回少量的数据
- 被驱动表连接条件可以很好的使用索引
- 结果集比较小
- HASH JOIN
Hash join通常使用在大数据集的两表关联时,关联列不存在索引、索引无法使用、或者优化器认为索引列过滤条件有限不能很好的筛选数据等情况下,都会使用hash join,分为两个阶段:构造HASH表阶段和扫描匹配阶段。
通常会选择两个表中较小(相对较小,不是绝对值,我们称为左表)的表中每行数据经过散列函数计算放到不同的hash槽中,形成hash表,然后将另一张数据量较大的表(我们称为右表)的join列经过散列函数计算后与前一个较小表形成的hash表进行匹配,匹配则返回相应的数据行。
选择左表构造HASH表的原因在于左表需要申请内存区域以构造hash表,如果选择右表构建hash表,则需要花费更大的代价,另外右表只需要做一次扫描,不需要构造hash表。所以综合来看,选择左表构造hash表更合适。
经过前面的说明,HASH JOIN需要通过散列函数对左表数据构造HASH表,在并发较大的系统中,对CPU、内存等系统资源消耗较大高
- MERGE JOIN
Merge join在表关联中使用较少,此种关联首先需要确保两个关联表都是按照关联字段排序,再从每个表取一条记录进行匹配,如果符合关联条件,则放入结果集中,否则将关联字段值较小的记录抛弃,从这条记录对应的表中取下一条记录继续进行匹配,直到整个循环结束。
通过上面的理论描述,可以确认这三种连接方式在执行过程中,优化器如何选择连接方式,在统计信息准确的情况下,主要取决于以下因素
- 需要查询数据的数据大小(存在表比较大,但是通过查询条件的筛选,所以需要根据筛选后的数据量大小来决定连接顺序)
- 连接列是否有索引
- 连接列是否需要进行排序
二、 达梦默认两表关联测试
这个章节主要是测试默认情况下(即不人为干预),达梦优化器什么时候使用不同的关联方法进行两表的关联。
针对以上的描述,接下来进行实验以验证以上的理论描述。
- 准备表和索引等基础数据:
DROP TABLE T1;
DROP TABLE T2;
CREATE TABLE T1(C1 INT ,C2 INT,C3 VARCHAR(20) ,C4 VARCHAR(20) );
CREATE TABLE T2(C1 INT ,C2 INT,C3 VARCHAR(20) ,C4 VARCHAR(20) );
INSERT INTO T1 SELECT LEVEL C1,DBMS_RANDOM.RANDOM C2,DBMS_RANDOM.RANDOM_STRING('X',20),DBMS_RANDOM.RANDOM_STRING('a',20) FROM DUAL CONNECT BY LEVEL<=1000000;
INSERT INTO T2 SELECT LEVEL C1,DBMS_RANDOM.RANDOM C2,DBMS_RANDOM.RANDOM_STRING('X',20),DBMS_RANDOM.RANDOM_STRING('a',20) FROM DUAL CONNECT BY LEVEL<=1000000;
commit;
create index ind_t1_c1 on t1(C1);
create index ind_t2_c1 on t2(C1);
call SYS.DBMS_STATS.GATHER_TABLE_STATS('SYSDBA','T1',null,100,TRUE,'FOR ALL COLUMNS SIZE AUTO');
call SYS.DBMS_STATS.GATHER_TABLE_STATS('SYSDBA','T2',null,100,TRUE,'FOR ALL COLUMNS SIZE AUTO');
这里准备了两个基础表,两个表分别插入100万行记录,并对表进行统计信息收集。
- 测试内容:
explain select * from t1 inner JOIN t2 on t1.C1=t2.C1 and t1.C1=10;
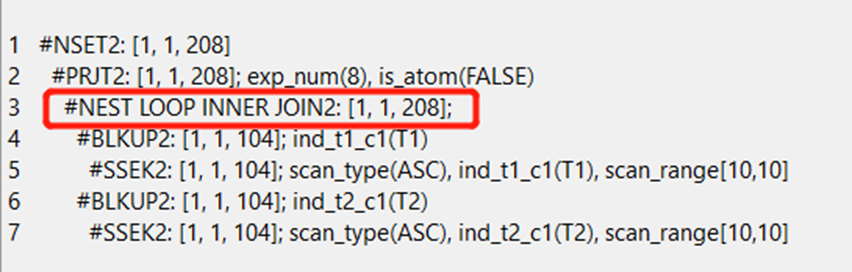
此时是先使用索引对T1表进行扫描,再根据关联列,使用索引对T2表进行扫描,最后再进行nest loop的inner操作。从执行计划的内容可以看出,在关联列是等值条件及筛选条件只有一条记录的情况下,会选择使用nest loop inner join2进行两表关联。
explain select * from t1 inner JOIN t2 on t1.C1=t2.C1 and t1.C1<10;
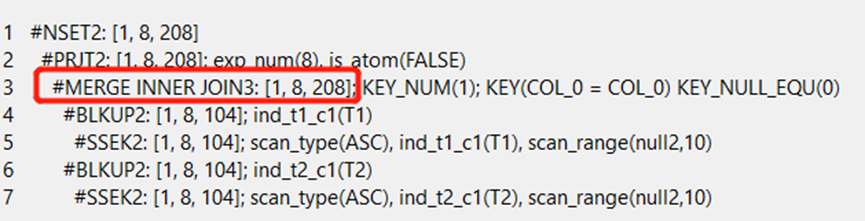
对于关联列等值,筛选条件过滤性比较好的情况下,会选择使用merge join的方式进行两表关联。
explain select * from t1 inner JOIN t2 on t1.C1=t2.C1 and t1.C1<10000;
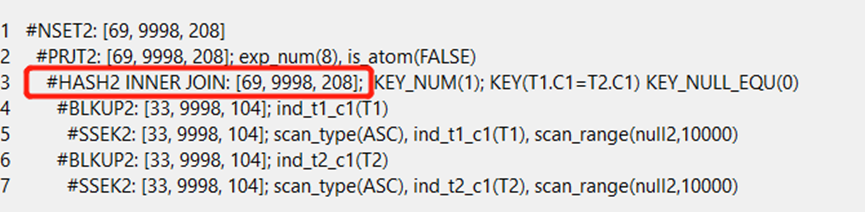
对于关联列等值,筛选条件过滤性不佳的情况下,优化器会选择使用hash join的方式进行两表关联。
explain select * from t1 inner JOIN t2 on t1.C1>t2.C1 and t1.C1<10;
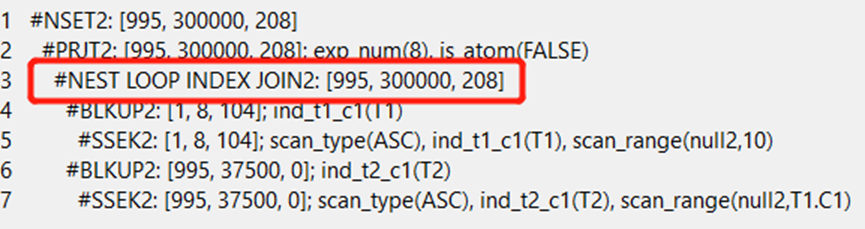
在非等值连接,且过滤条件较好的情况下,会使用nest loop index join的方式进行两表有关联。
explain select /*+ENABLE_HASH_JOIN(1)*/* from t1 inner JOIN t2 on t1.C1>t2.C1 and t1.C1<10;

在关联列非等值的情况下,无论筛选条件如何,都不会选择hash join方式对两表进行关联,即使加hint强制,执行计划也不会变化。
三、 测试结果
经过以上的测试,发现达梦优化器在默认情况下,对关联或筛选在不同条件下的默认关联方式都存在不同,熟悉这些规则,对于后续在实际的生产系统进行SQL优化时,可以帮助更好的理解执行计划,在进行SQL改写时,可以更好的帮助如何干预执行计划步骤。
测试结果如下:
- 关联列等值过滤条件为等值时,将会使用nest loop inner join方式表连接
- 关联列不等值过滤条件为不等值时,将会使用nest loop index join方式表连接
- 关联列等值过滤条件筛选条件较好时,将会使用merge inner join方式进行表连接
- 关联列等值过滤条件筛选条件较差时,将会使用hash inner join方式进行表连接
达梦社区:https://eco.dameng.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号