实时数仓之Flink消费kafka消息队列数据入hbase
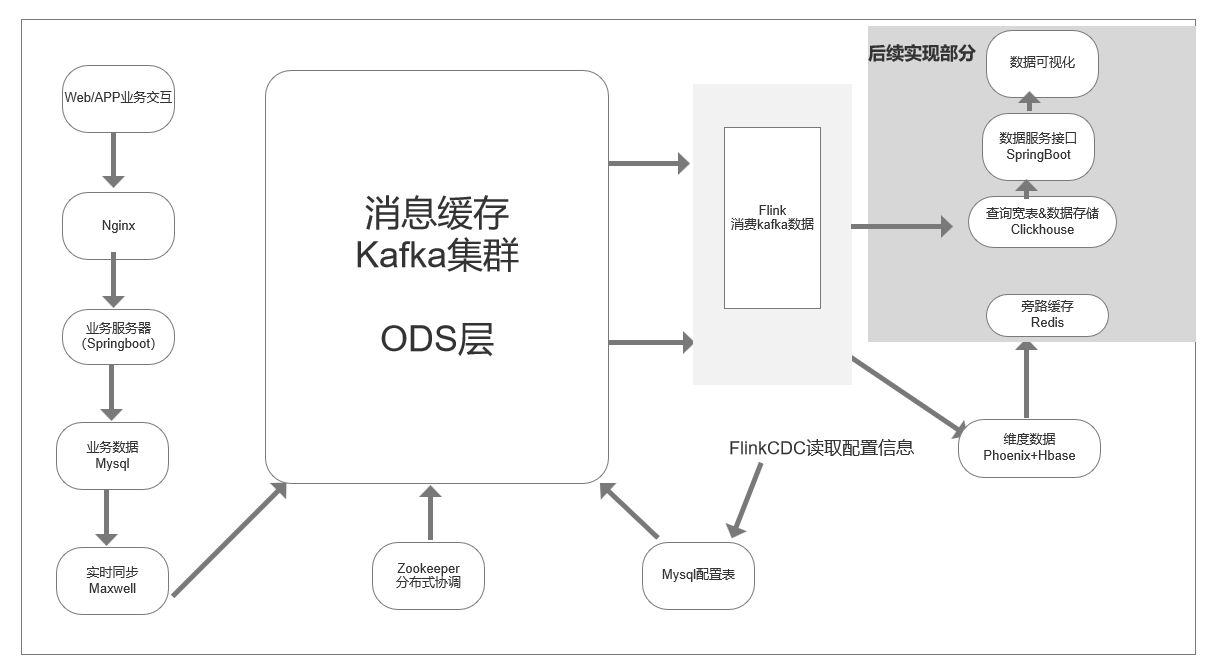
一、流程架构图
二、开源框架及本版选择
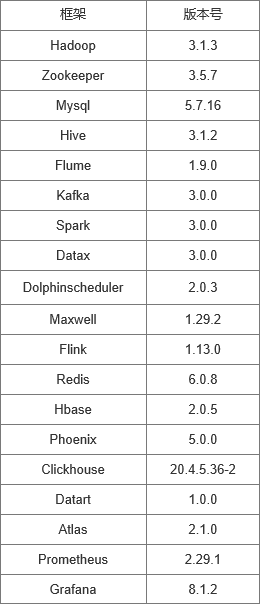
本次项目中用到的相关服务有:hadoop、zookeeper、kafka、maxwell、hbase、phoenix、flink
三、服务部署完成后,开发Flink主程序
3.1 结构图如下:
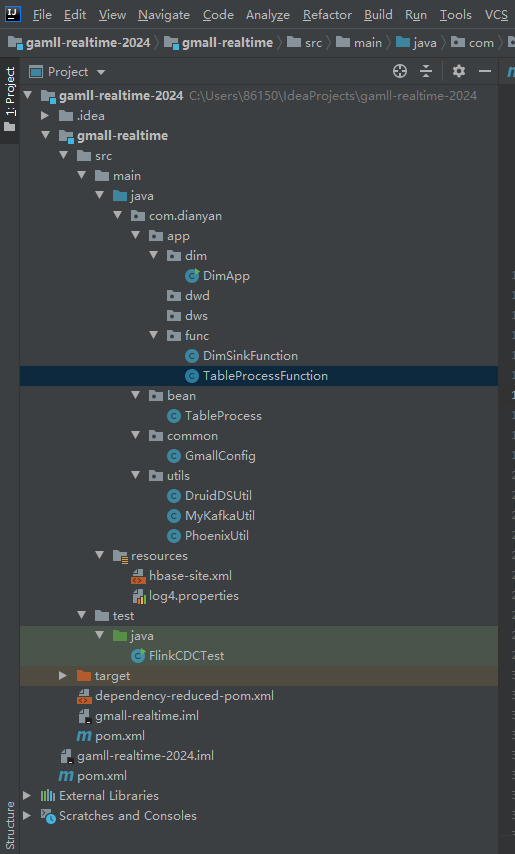
3.2 代码详细内容
3.2.1 pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>gamll-realtime-2024</artifactId>
<groupId>org.example</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<groupId>com.dianyanyuan</groupId>
<artifactId>gmall-realtime</artifactId>
<properties>
<java.version>1.8</java.version>
<maven.compiler.source>${java.version}</maven.compiler.source>
<maven.compiler.target>${java.version}</maven.compiler.target>
<flink.version>1.13.0</flink.version>
<scala.version>2.12</scala.version>
<hadoop.version>3.1.3</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.68</version>
</dependency>
<!--如果保存检查点到hdfs上,需要引入此依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.20</version>
</dependency>
<!--Flink默认使用的是slf4j记录日志,相当于一个日志的接口,我们这里使用log4j作为具体的日志实现-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.25</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.25</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-spark</artifactId>
<version>5.0.0-HBase-2.0</version>
<exclusions>
<exclusion>
<groupId>org.glassfish</groupId>
<artifactId>javax.el</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- 如果不引入 flink-table 相关依赖,则会报错:
Caused by: java.lang.ClassNotFoundException:
org.apache.flink.connector.base.source.reader.RecordEmitter
引入以下依赖可以解决这个问题(引入某些其它的 flink-table相关依赖也可)
-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.12</artifactId>
<version>1.13.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.16</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude>com.google.code.findbugs:jsr305</exclude>
<exclude>org.slf4j:*</exclude>
<exclude>log4j:*</exclude>
<exclude>org.apache.hadoop:*</exclude>
</excludes>
</artifactSet>
<filters>
<filter>
<!-- Do not copy the signatures in the META-INF folder.Otherwise, this might cause SecurityExceptions when using the JAR. -->
<!-- 打包时不复制META-INF下的签名文件,避免报非法签名文件的SecurityExceptions异常-->
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers combine.children="append">
<!-- The service transformer is needed to merge META-INF/services files -->
<!-- connector和format依赖的工厂类打包时会相互覆盖,需要使用ServicesResourceTransformer解决-->
<transformer
implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
3.2.2 log4.properties文件
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %10p (%c:%M) - %m%n
log4j.rootLogger=error,stdout
3.2.3 hbase配置文件 (这个可以直接复制服务器上hbase服务conf文件夹中的hbase-site.xml文件)
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
/**
*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
-->
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop101:8020/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop101,hadoop102,hadoop103</value>
</property>
<property>
<name>phoenix.schema.isNamespaceMappingEnabled</name>
<value>true</value>
</property>
<property>
<name>phoenix.schema.mapSystemTablesToNamespace</name>
<value>true</value>
</property>
</configuration>
3.2.4 工具类-druid
package com.dianyan.utils;
import com.alibaba.druid.pool.DruidDataSource;
import com.dianyan.common.GmallConfig;
public class DruidDSUtil {
private static DruidDataSource druidDataSource = null;
public static DruidDataSource createDataSource() {
// 创建连接池
druidDataSource = new DruidDataSource();
// 设置驱动全类名
druidDataSource.setDriverClassName(GmallConfig.PHOENIX_DRIVER);
// 设置连接 url
druidDataSource.setUrl(GmallConfig.PHOENIX_SERVER);
// 设置初始化连接池时池中连接的数量
druidDataSource.setInitialSize(5);
// 设置同时活跃的最大连接数
druidDataSource.setMaxActive(20);
// 设置空闲时的最小连接数,必须介于 0 和最大连接数之间,默认为 0
druidDataSource.setMinIdle(1);
// 设置没有空余连接时的等待时间,超时抛出异常,-1 表示一直等待
druidDataSource.setMaxWait(-1);
// 验证连接是否可用使用的 SQL 语句
druidDataSource.setValidationQuery("select 1");
// 指明连接是否被空闲连接回收器(如果有)进行检验,如果检测失败,则连接将被从池中去除
// 注意,默认值为 true,如果没有设置 validationQuery,则报错
// testWhileIdle is true, validationQuery not set
druidDataSource.setTestWhileIdle(true);
// 借出连接时,是否测试,设置为 false,不测试,否则很影响性能
druidDataSource.setTestOnBorrow(false);
// 归还连接时,是否测试
druidDataSource.setTestOnReturn(false);
// 设置空闲连接回收器每隔 30s 运行一次
druidDataSource.setTimeBetweenEvictionRunsMillis(30 * 1000L);
// 设置池中连接空闲 30min 被回收,默认值即为 30 min
druidDataSource.setMinEvictableIdleTimeMillis(30 * 60 * 1000L);
return druidDataSource;
}
}
3.2.5 工具类-kafka
package com.dianyan.utils;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.KafkaDeserializationSchema;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import java.util.Properties;
public class MyKafkaUtil {
private static final String KAFKA_SERVER = "hadoop101:9092";
public static FlinkKafkaConsumer<String> getFlinkKafkaConsumer(String topic,String groupId){
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG,groupId);
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,KAFKA_SERVER);
return new FlinkKafkaConsumer<String>(
topic,
new KafkaDeserializationSchema<String>() {
@Override
public boolean isEndOfStream(String s) {
return false;
}
@Override
public String deserialize(ConsumerRecord<byte[], byte[]> consumerRecord) throws Exception {
if(consumerRecord == null || consumerRecord.value() == null){
return null;
}else {
return new String(consumerRecord.value());
}
}
@Override
public TypeInformation<String> getProducedType() {
return BasicTypeInfo.STRING_TYPE_INFO;
}
},
properties
);
}
}
3.2.6 工具类-Phoenix
package com.dianyan.utils;
import com.alibaba.druid.pool.DruidPooledConnection;
import com.alibaba.fastjson.JSONObject;
import com.dianyan.common.GmallConfig;
import org.apache.commons.lang3.StringUtils;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.Collection;
import java.util.Set;
public class PhoenixUtil {
/**
*
* @param connection Phoenix连接
* @param sinkTable 表名
* @param data 数据
*/
public static void upsertValues(DruidPooledConnection connection, String sinkTable, JSONObject data) throws SQLException {
//1.拼接SQL语句 upsert into db.table(id,name,sex) values("1001","张三","male")
Set<String> columns = data.keySet();
Collection<Object> values = data.values();
String sql = "upsert into " + GmallConfig.HBASE_SCHEMA + "." + sinkTable + "(" +
StringUtils.join(columns,",") + ") values ('" +
StringUtils.join(values,"','") + "')";
//2.预编译sql
PreparedStatement preparedStatement = connection.prepareStatement(sql);
//3.执行
preparedStatement.execute();
connection.commit();
//4.释放资源
preparedStatement.close();
}
}
3.2.7 数据库驱动
package com.dianyan.common;
public class GmallConfig {
// Phoenix库名
public static final String HBASE_SCHEMA = "GMALL_REALTIME";
// Phoenix驱动
public static final String PHOENIX_DRIVER = "org.apache.phoenix.jdbc.PhoenixDriver";
// Phoenix连接参数
public static final String PHOENIX_SERVER = "jdbc:phoenix:hadoop101,hadoop102,hadoop103:2181";
}
3.2.8 table配置
package com.dianyan.bean;
import lombok.Data;
@Data
public class TableProcess {
//来源表
String sourceTable;
//输出表
String sinkTable;
//输出字段
String sinkColumns;
//主键字段
String sinkPk;
//建表扩展
String sinkExtend;
}
3.2.9 简单过滤逻辑
package com.dianyan.app.func;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.dianyan.bean.TableProcess;
import com.dianyan.common.GmallConfig;
import org.apache.flink.api.common.state.BroadcastState;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.api.common.state.ReadOnlyBroadcastState;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.co.BroadcastProcessFunction;
import org.apache.flink.util.Collector;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.*;
public class TableProcessFunction extends BroadcastProcessFunction<JSONObject, String, JSONObject> {
private Connection connection;
private MapStateDescriptor<String, TableProcess> mapStateDescriptor;
// 构造器
public TableProcessFunction(MapStateDescriptor<String, TableProcess> mapStateDescriptor) {
this.mapStateDescriptor = mapStateDescriptor;
}
@Override
public void open(Configuration parameters) throws Exception {
connection = DriverManager.getConnection(GmallConfig.PHOENIX_SERVER);
}
//{"before":null,"after":{"source_table":"3213","sink_table":"22","sink_columns":"33","sink_pk":"44","sink_extend":"55"},"source":{"version":"1.5.4.Final","connector":"mysql","name":
// "mysql_binlog_source","ts_ms":1710926254168,"snapshot":"false","db":"gmall-config","sequence":null,"table":"table_process","server_id":0,"gtid":null,"file":"","pos":0,"row":0,
// "thread":null,"query":null},"op":"r","ts_ms":1710926254171,"transaction":null}
@Override
public void processBroadcastElement(String value, Context context, Collector<JSONObject> out) throws Exception {
// 1.获取并解析数据
JSONObject jsonObject = JSON.parseObject(value);
TableProcess tableProcess = JSON.parseObject(jsonObject.getString("after"), TableProcess.class);
// 2.校验并建表
checkTable(tableProcess.getSinkTable(),
tableProcess.getSinkColumns(),
tableProcess.getSinkPk(),
tableProcess.getSinkExtend());
// 3.写入状态,广播出去
BroadcastState<String, TableProcess> broadcastState = context.getBroadcastState(mapStateDescriptor);
broadcastState.put(tableProcess.getSourceTable(),tableProcess);
}
/**
* 校验并建表 : create table if not exists db.table(id varchar primary key ,bb varchar ,cc varchar) xxx
* @param sinkTable phoenix表名
* @param sinkColumns phoenix表字段
* @param sinkPk phoenix表主键
* @param sinkExtend phoenix表扩展字段
*/
private void checkTable(String sinkTable,String sinkColumns,String sinkPk,String sinkExtend){
PreparedStatement preparedStatement = null;
try {
// 处理特殊字段,比如字段值为null的情况
if(sinkPk == null || "".equals(sinkPk)){
sinkPk = "id";
}
if(sinkExtend == null){
sinkExtend = "";
}
//1.拼接SQL create table if not exists db.table(id varchar primary key ,bb varchar ,cc varchar) xxx
StringBuilder createTableSql = new StringBuilder("create table if not exists ")
.append(GmallConfig.HBASE_SCHEMA)
.append(".")
.append(sinkTable)
.append("(");
String[] columns = sinkColumns.split(",");
for (int i = 0; i < columns.length; i++) {
// 取出字段
String column = columns[i];
// 是否为主键
if(sinkPk.equals(column)){
createTableSql.append(column).append(" varchar primary key");
}else{
createTableSql.append(column).append(" varchar");
}
// 判断是否为最后一个字段
if(i < columns.length-1){
createTableSql.append(",");
}
}
createTableSql.append(")").append(sinkExtend);
//2.编译SQL
System.out.println("建表语句为>>>>>" + createTableSql);
// 预编译
preparedStatement = connection.prepareStatement(createTableSql.toString());
//3.执行SQL,建表
preparedStatement.execute();
} catch (SQLException e) {
throw new RuntimeException("建表失败:" + sinkTable ); // 把编译时异常转换为运行时异常
} finally {
//4.释放资源
if(preparedStatement != null){
try {
preparedStatement.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
// {"database":"gmall","table":"base_trademark","type":"bootstrap-insert","ts":1710921861,"data":{"id":2,"tm_name":"苹果","logo_url":"/static/default.jpg"}}
@Override
public void processElement(JSONObject value, ReadOnlyContext readOnlyContext, Collector<JSONObject> collector) throws Exception {
//1.获取广播的配置数据
ReadOnlyBroadcastState<String, TableProcess> broadcastState = readOnlyContext.getBroadcastState(mapStateDescriptor);
String table = value.getString("table");
TableProcess tableProcess = broadcastState.get(table);
if(tableProcess != null){
//2.过滤字段
filterColumn(value.getJSONObject("data"),tableProcess.getSinkColumns());
//3.补充SinkTable并写出到流中
value.put("sinkTable",tableProcess.getSinkTable());
collector.collect(value);
}else{
System.out.println("找不到对应的Key:" + table);
}
}
/**
* 过滤字段
* @param data {"id":2,"tm_name":"苹果","logo_url":"/static/default.jpg"}
* @param sinkColumns "id","tm_name"
*/
private void filterColumn(JSONObject data, String sinkColumns) {
// 切分
String[] columns = sinkColumns.split(",");
List<String> columnList = Arrays.asList(columns);
Set<Map.Entry<String, Object>> entries = data.entrySet(); // 遍历
Iterator<Map.Entry<String, Object>> iterator = entries.iterator(); // 迭代器
while(iterator.hasNext()){
Map.Entry<String, Object> next = iterator.next();
if(!columnList.contains(next.getKey())){
iterator.remove();
}
}
}
}
3.2.10 sink端
package com.dianyan.app.func;
import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.pool.DruidPooledConnection;
import com.alibaba.fastjson.JSONObject;
import com.dianyan.utils.DruidDSUtil;
import com.dianyan.utils.PhoenixUtil;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
public class DimSinkFunction extends RichSinkFunction<JSONObject> {
private DruidDataSource druidDataSource = null;
@Override
public void open(Configuration parameters) throws Exception {
druidDataSource = DruidDSUtil.createDataSource();
}
// {"database":"gmall","table":"base_trademark","type":"bootstrap-insert","ts":1710921861,"data":{"id":2,"tm_name":"苹果","logo_url":"/static/default.jpg"},"sinkTable":"dim_xxx"}
@Override
public void invoke(JSONObject value, Context context) throws Exception {
// 获取连接
DruidPooledConnection connection = druidDataSource.getConnection();
// 写出数据
String sinkTable = value.getString("sinkTable"); // 表名
JSONObject data = value.getJSONObject("data");
PhoenixUtil.upsertValues(connection,sinkTable,data);
// 归还连接
connection.close();
}
}
3.2.11 主程序
package com.dianyan.app.dim;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.dianyan.app.func.DimSinkFunction;
import com.dianyan.app.func.TableProcessFunction;
import com.dianyan.bean.TableProcess;
import com.dianyan.utils.MyKafkaUtil;
import com.ververica.cdc.connectors.mysql.source.MySqlSource;
import com.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.runtime.state.hashmap.HashMapStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.BroadcastConnectedStream;
import org.apache.flink.streaming.api.datastream.BroadcastStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.BroadcastProcessFunction;
import org.apache.flink.util.Collector;
public class DimApp {
public static void main(String[] args) throws Exception {
//TODO 1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1); // 并行度 生产环境根据Kafka的分区数
// 1.1 开启checkpoint
// env.enableCheckpointing(5 * 6000L, CheckpointingMode.EXACTLY_ONCE);
// env.getCheckpointConfig().setCheckpointTimeout(10 * 6000L);
// env.getCheckpointConfig().setMaxConcurrentCheckpoints(2); //checkpoint的并行度
// env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3,5000L)); // 如果Flink服务意外挂了,此处配置每隔5秒重新连接一次,一共尝试3次。
// 1.2 设置状态后端
// env.setStateBackend(new HashMapStateBackend());
// env.getCheckpointConfig().setCheckpointStorage("hdfs://hadoop101:8020/dianyan");
// System.setProperty("HADOOP_USER_NAME","linxueze100");
//TODO 2.读取kafka topic=maxwell 主题数据创建主流
String topic = "maxwell";
String groupid = "dim_app_001";
DataStreamSource<String> kafkaDS = env.addSource(MyKafkaUtil.getFlinkKafkaConsumer(topic, groupid));
//TODO 3.过滤掉非JSON数据以及保留新增、变化以及初始化数据 并将数据转换为JSON格式
SingleOutputStreamOperator<JSONObject> filterJsonObjDS = kafkaDS.flatMap(new FlatMapFunction<String, JSONObject>() {
@Override
public void flatMap(String value, Collector<JSONObject> collector) throws Exception {
try {
// 将数据转换为JSON格式
JSONObject jsonObject = JSON.parseObject(value);
// 获取数据中的操作字段
String type = jsonObject.getString("type");
// 保留新增、变化和初始化的数据
if ("insert".equals(type) || "update".equals(type) || "bootstrap-insert".equals(type)) {
collector.collect(jsonObject);
}
} catch (Exception e) {
System.out.println("发现脏数据:》》》》》》" + value);
}
}
});
//TODO 4.使用FlinkCDC读取Mysql配置信息表,创建配置流
MySqlSource<String> mySqlSource = MySqlSource.<String>builder()
.hostname("hadoop101")
.port(3306)
.username("root")
.password("123456")
.databaseList("gmall-config")
.tableList("gmall-config.table_process")
.startupOptions(StartupOptions.initial()) // 启动方式
.deserializer(new JsonDebeziumDeserializationSchema()) // 反序列化 binlog二进制
.build();
DataStreamSource<String> mySqlSourceDS = env.fromSource(mySqlSource, WatermarkStrategy.noWatermarks(), "MysqlSource");
//TODO 5.将配置流处理为广播流
MapStateDescriptor<String, TableProcess> mapStateDescriptor = new MapStateDescriptor<>("map-state", String.class, TableProcess.class);
BroadcastStream<String> broadcastStream = mySqlSourceDS.broadcast(mapStateDescriptor);
//TODO 6.连接主流和配置流
BroadcastConnectedStream<JSONObject, String> connectedStream = filterJsonObjDS.connect(broadcastStream);
//TODO 7.处理连接流 根据配置信息 处理主流数据
SingleOutputStreamOperator<JSONObject> dimDS = connectedStream.process(new TableProcessFunction(mapStateDescriptor));
//TODO 8.将数据写入Phoenix
dimDS.addSink(new DimSinkFunction());
dimDS.print(">>>>>>>>>>>>>>>");
//TODO 9.启动任务
env.execute("DimApp");
}
}
四、实现效果
通过maxwell实时监控并抽取mysql的binlog文件,对数据的insert、update做实时采集并写入kafka对应topic;通过Flink程序消费kafka指定topic中的数据,简单清洗数据并写入hbase中。过程中zk做协同,phoenix做select等便捷查询。
五、写在最后
此篇文章,重在记录调研实时数仓的碎片记忆。很多细节的地方,没有写出来,也是因为时间有限,比如主程序中Flink消费kafka的topic的名称,要和maxwell采集过来写入kafka的topic保持一致,还有maxwell监控mysql的binlog的配置表的一些问题。
不要为了追逐,而忘记当初的样子。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号