
python学习第十四天- 深浅拷贝、集合、函数
深浅拷贝 只copy一层 独立第一层
集合
函数
概念
参数
https://www.cnblogs.com/yuanchenqi/articles/5782764.html 老男孩-袁 数据类型
1. 深浅拷贝
现在,大家先不要理会什么是深浅拷贝,听我说,对于一个列表,我想复制一份怎么办呢?
肯定会有同学说,重新赋值呗:
|
1
2
|
names_class1=['张三','李四','王五','赵六']names_class1_copy=['张三','李四','王五','赵六'] |
这是两块独立的内存空间
这也没问题,还是那句话,如果列表内容做够大,你真的可以要每一个元素都重新写一遍吗?当然不啦,所以列表里为我们内置了copy方法:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
names_class1=['张三','李四','王五','赵六',[1,2,3]]names_class1_copy=names_class1.copy()names_class1[0]='zhangsan'print(names_class1)print(names_class1_copy)############names_class1[4][2]=5print(names_class1)print(names_class1_copy)#问题来了,为什么names_class1_copy,从这一点我们可以断定,这两个变量并不是完全独立的,那他们的关系是什么呢?为什么有的改变,有的不改变呢? |
这里就涉及到我们要讲的深浅拷贝了:
1.1浅拷贝
#eg1 # s=[1,"alex","alve"] # s2=s.copy() # s2[0]="33" # print(s2) # print(s) #eg2 # s1=[[1,2],"alex","alve"] # s3=s1.copy() # s3[0][1]=323 # print(s3) # print(s1) #浅拷贝只拷贝一层
那么怎么解释这样的一个结果呢?
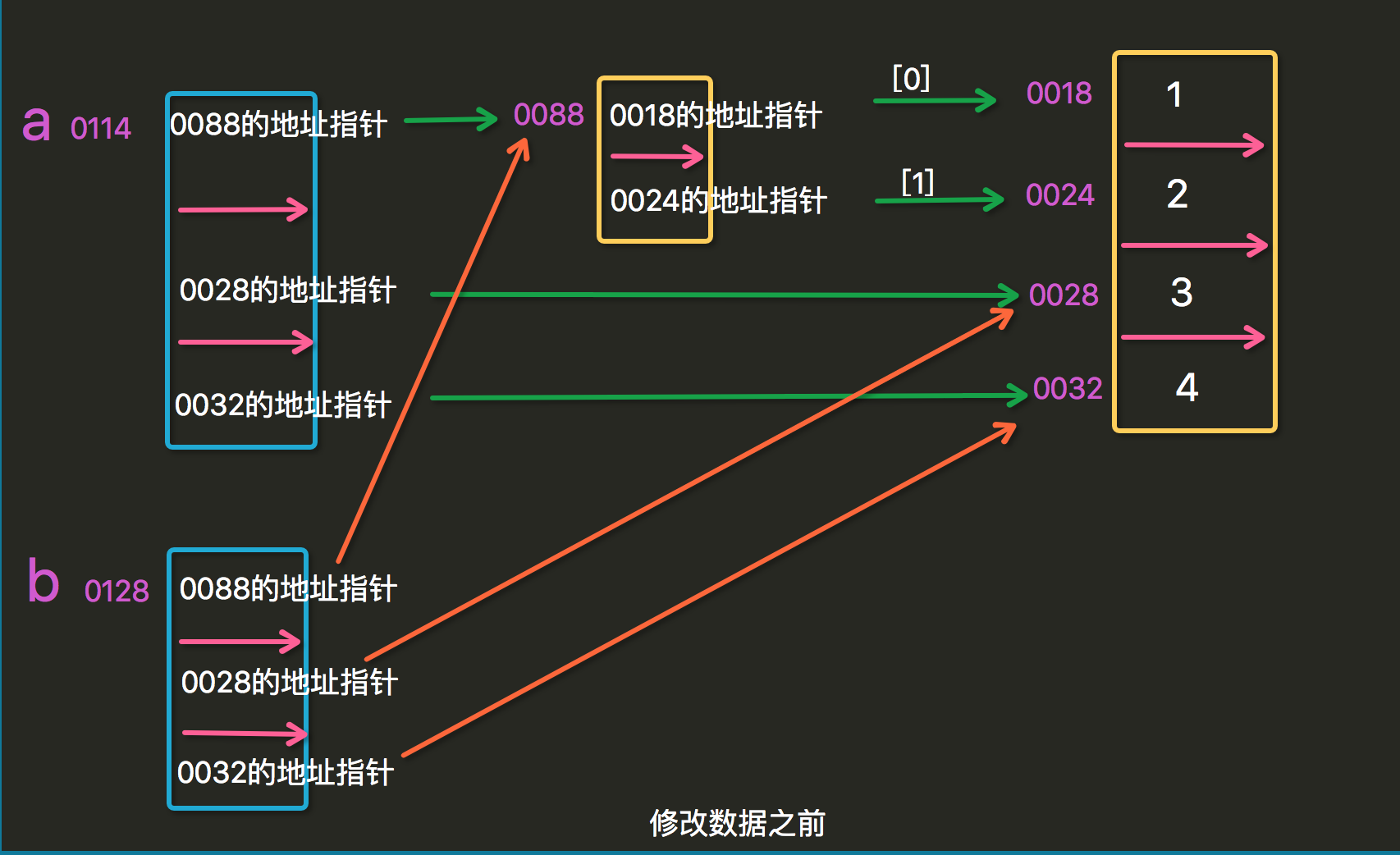
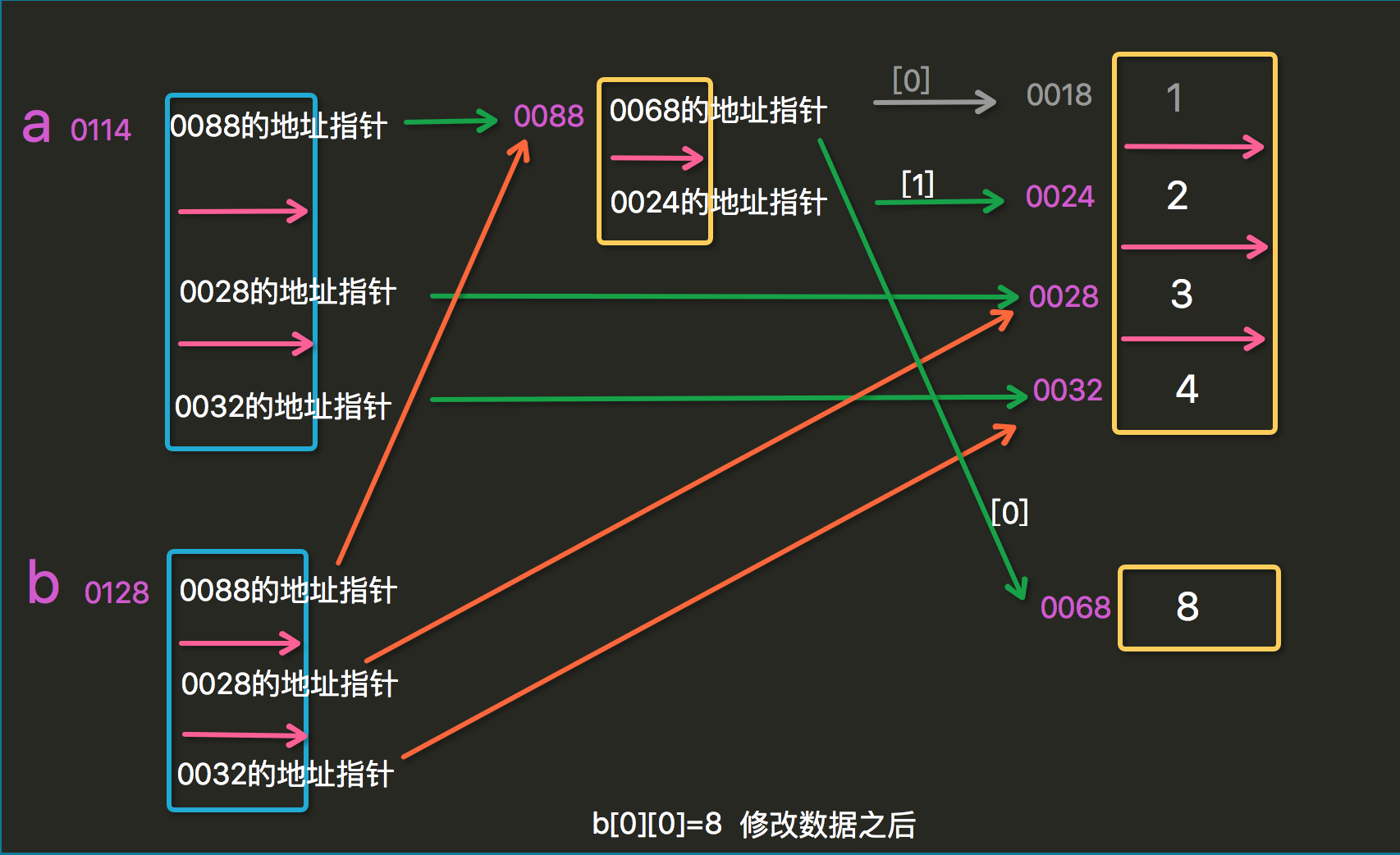
再不懂,俺就没办法啦...
浅拷贝应用场景
#应用场景 夫妻卡 husband=["新洲",123,[15000,9000]] #15000额度,9000的可用额 wife=husband.copy() wife[0]="林林" wife[1]=345 husband[2][1]-=3000 #丈夫消费 3000元 print(husband,wife) ##['新洲', 123, [15000, 6000]] ['林林', 345, [15000, 6000]]
列表补充:
b,*c=[1,2,3,4,5]
1.2深拷贝
import copy #引入包 copy 运用深copy时需要引入包 husband=["新洲",123,[15000,9000]] #15000额度,9000的可用额 wife=husband.copy() wife[0]="林林" wife[1]=345 xiaosan=copy.deepcopy(husband) xiaosan[0]="小洲" xiaosan[1]=456 xiaosan[2][1]-=3000 print(wife) print(xiaosan)
# ['林林', 345, [15000, 9000]] ['小洲', 456, [15000, 6000]]
2.集合
集合是一个无序的,不重复的数据组合,它的主要作用如下:
- 去重,把一个列表变成集合,就自动去重了
- 关系测试,测试两组数据之前的交集、差集、并集等关系
集合(set):把不同的元素组成一起形成集合,是python基本的数据类型。
集合元素(set elements):组成集合的成员(不可重复)
2.1基本操作
#创建(无序的、不可变的)
s=set("alex li")
print(s) #{'x', 'a', 'e', 'l'}
#去重
s1=["alex" , "li","ee" , "alex"]
s2=set(s1) #转换成集合
s1=list(s2)
print(s1)
#添加.add() 添加一个元素
s2.add("u")
print(s2) #{'alex', 'ee', 'u', 'li'}
#更新#.update("ops")
s2.update("ops") #添加元素,添加一个序列
print(s2) #{'s', 'ee', 'u', 'li', 'p', 'alex', 'o'}
s2.update("ooooe")
print(s2) #{'alex', 'o', 's', 'ee', 'e', 'p', 'u', 'li'}
s2.update([12,"alex"])
print(s2) #{'o', 'e', 's', 12, 'alex', 'ee', 'u', 'p', 'li'}
#删除
s2.pop() #随机删除一个元素
print(s2) #{'ee', 'o', 's', 12, 'u', 'alex', 'p', 'e'}
#清空
# s2.clear()
# print(s2) #set()
del s2
print(s2) #NameError: name 's2' is not defined
2.1逻辑操作
#关系测试
print(set("alex")==set("alexexexxe")) #测试相等 True
print(set("alex")<set("alexerrere")) #是否包含 True
a=set([1,2,3,4,5])
b=set([4,5,6,7,8])
#交集.intersection()
print(a.intersection(b)) #{4, 5}
print(a&b) #{4, 5}
#并集.union() print(a|b)
print(a.union(b)) #{1, 2, 3, 4, 5, 6, 7, 8}
print(a|b) #{4, 5}
#差集.
print(a.difference(b)) #{1, 2, 3} a里面有b里面没有
print(a-b) #{1, 2, 3} a里面有b里面没有
print(b.difference(a)) #{8, 6, 7} b里面有a里面没有
print(b-a) #{8, 6, 7} b里面有a里面没有
#对称差集
print(a.symmetric_difference(b)) #{1, 2, 3, 6, 7, 8}
print(a^b) #{1, 2, 3, 6, 7, 8}
#父集 超集
print(a.issuperset(b)) #测试是否是包含关系 False
#子集
print(a.issubset(b)) #测试是否是子集关系 False
3.函数 https://www.cnblogs.com/yuanchenqi/articles/5828233.html
3.1函数的创建
#eg1
def show_shopping(): #show_shopping为函数名字描述性的名字,命名规则跟变量是一样的。
print("ok")
show_shopping()#调用带参数
#eg2
def add(x,y):
print(x+y)
add(7,23)
add(45,675723)
#eg3
def f(x):
print("function %s"%x) #格式化输出 需要添加%s 后面跟参数x
f(23232)
# ok
# 30
# 675768
# function 23232
3.2函数日志记录
import time
def logger(n):
time_format="%Y-%M-%D %X" #定义时间格式
time_current=time.strftime(time_format) #time.strftime()得到当前时间,和格式
with open("log_txt", "a") as f:
f.write("%s end action%s\n"%(time_current,n))#当有两个参数时,必须得加括号
def action1(n):
print("starting action1....")
logger(n)
def action2(n):
print("starting action2....")
logger(n)
def action3(n):
print("starting action3....")
logger(n)
action1(213)
action2(2123)
action3(3123)
调用时间
import time time_format="%Y-%M-%D %X" #定义时间格式
time_current=time.strftime(time_format) #time.strftime()得到当前时间,和格式
3.3函数的参数
1.必须参数 按照顺序一一对应 2.关键字参数 3.不定长参数
#参数的种类
def print_info(name,age):
print("name:%s"%name)
print("name:%d"%age)
print_info("alex",232) #1.必须参数 按照顺序一一对应
print_info(age=12,name="deff") #2.关键字参数
#name:alex
#age:232
#name:deff
#age:12
#关键字参数
def print_info(name,age,sex="man"): #3.默认参数
print("name:%s"%name)
print("age:%d"%age)
print("sex:%s"%sex)
print_info("alex",232)
print_info("xiaohu",12)
print_info("jinxin",32)
print_info("linlin",18,sex="woman")
# name:alex
# age:232
# sex:man
# name:xiaohu
# age:12
# sex:man
# name:jinxin
# age:32
# sex:man
# name:linlin
# age:18
# sex:woman
不定长参数
def add(*args): # *不定长参数 *args 被处理成元组 无命名参数
sum=0
for i in args:
sum+=i
print(sum)
add(212,123,1231,1,321,4,5345) #7237
def print_info(*args,**kwargs): #**kwargs 不定长参数,数据被处理成字典
print(args)
print(kwargs)
print_info("alex",12,sex="男",job="it")
# ('alex', 12)
# {'job': 'it', 'sex': '男'}
def print_info(*args,**kwargs): #**kwargs 不定长参数,数据被处理成字典 无命名参数*args放在左边,有命名参数放在右边**kwargs
for i in kwargs:
print("%s:%s"%(i,kwargs[i])) #i表示字典的键,kwargs[i]表示键
print_info(name="alex",age=12,sex="男",job="it")
#关于不定长参数,无命名参数*args放在左边,有命名参数放在右边**kwargs,关键参数的位置放在最左边
#关于不定长参数,无命名参数*args放在左边,有命名参数放在右边**kwargs,关键参数的位置放在最左边
3.4函数的返回值 return
1.函数在执行过程中只要遇到return语句,就会停止执行并返回结果,return语句代表着函数的结束。
2.数里如果没有return 会默认返回None
3.return如果返回多个对象能把他封装成成元组返回
def f():
print("ok")
return 10 #return 作用 1结束函数,2返回某个值
def add(*args): # *不定长参数 *args 被处理成元组 无命名参数
sum = 0
for i in args:
sum += i
return sum
a=add(212, 123, 1231, 1, 321, 4, 5345) # 7237
print(a)
def too():
return 1,"123",[1,2,3]
print(too()) #(1, '123', [1, 2, 3])
#return 注意点 1.函数里如果没有return 会默认返回None
# 2.如果返回多个对象能把他做成元组返回
3.5高阶函数
#高阶函数 函数名字可以赋值
#1函数名作为一个参数传递
def f(n):
return n*n
def fo(a,b,func):
ret= func(a)+func(b)
return ret
print(fo(2,4,f)) #将f作为一个函数传递进去 20
#2函数名作为一个返回值返回
def f():
def inner():
return 8
return inner
ret =f()
print(ret) #<function f.<locals>.inner at 0x0000000001170378>
3.6函数的作用域
python中的作用域分4种情况:
- L:local,局部作用域,即函数中定义的变量;
- E:enclosing,嵌套的父级函数的局部作用域,即包含此函数的上级函数的局部作用域,但不是全局的;
- G:globa,全局变量,就是模块级别定义的变量;
- B:built-in,系统固定模块里面的变量,比如int, bytearray等。 搜索变量的优先级顺序依次是:作用域局部>外层作用域>当前模块中的全局>python内置作用域,也就是LEGB。
-
x = int(2.9) # int built-in g_count = 0 # global def outer(): o_count = 1 # enclosing def inner(): i_count = 2 # local print(o_count) # print(i_count) 找不到 inner() outer() # print(o_count) #找不到3.7递归函数
- 关于递归
- 调用自身函数
- 有一个结束条件
- 但凡是递归可以写的循环都可以解决
- 递归的效率很低
-
#阶乘函数 def f(x): ret=1 for i in range(1,x+1): ret*=i return ret print(f(5)) #递归函数 def fact(n): if n==1: return 1 return n*fact(n-1) print(fact(5)) #120 #1203.8常见内置函数
https://www.runoob.com/python/python-built-in-functions.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号