AtomicLong和LongAdder
一.介绍
AtomicLong是Java中Doug Lea大神在JDK 1.5实现的long类型的原子类,能远在的维护一个long类型的值。它提供了自增自减、累加累减等等数值常用的API,这些操作都是原子操作:
-
自增自减操作
long getAndIncrement();
long incrementAndGet();
long decrementAndGet()
long getAndDecrement() -
累加累减
long addAndGet(long delta);
long addAndGet(long delta);
LongAdder可以认为是另一种版本long类型原子类的实现。它是Doug lea大神在Java 8中增加。它也提供了类似的AtomicLong的操作能力。如:自增自减,累加累减:
-
自增自减
void increment();
void decrement() -
累加累减
void add(long x)
-
获取当前值
long sum();
它们经常被用作为计数器,也可以用作为自增ID生成器等等。
二.区别
说到它们的区别,Java Docs中阐述非常明确:
This class is usually preferable to {@link AtomicLong} when multiple threads update a common sum that is used for purposes such as collecting statistics, not for fine-grained synchronization control. Under low update contention, the two classes have similar characteristics. But under high contention, expected throughput of this class is significantly higher, at the expense of higher space consumption.
当在多线程环境中,更偏爱使用LongAdder而非AtomicLong。在少量线程的竞争,两者表现出类似的特征。但是在比较高的竞争时,LongAdder的吞吐量比AtomicLong更优秀,但是会有更高的空间消耗。
从以上docs描述中可以看出,LongAdder更适合在多线程环境中使用,它的性能优越于AtomicLong。以下是笔者在机器配置为:4core/8G mem上做的测试
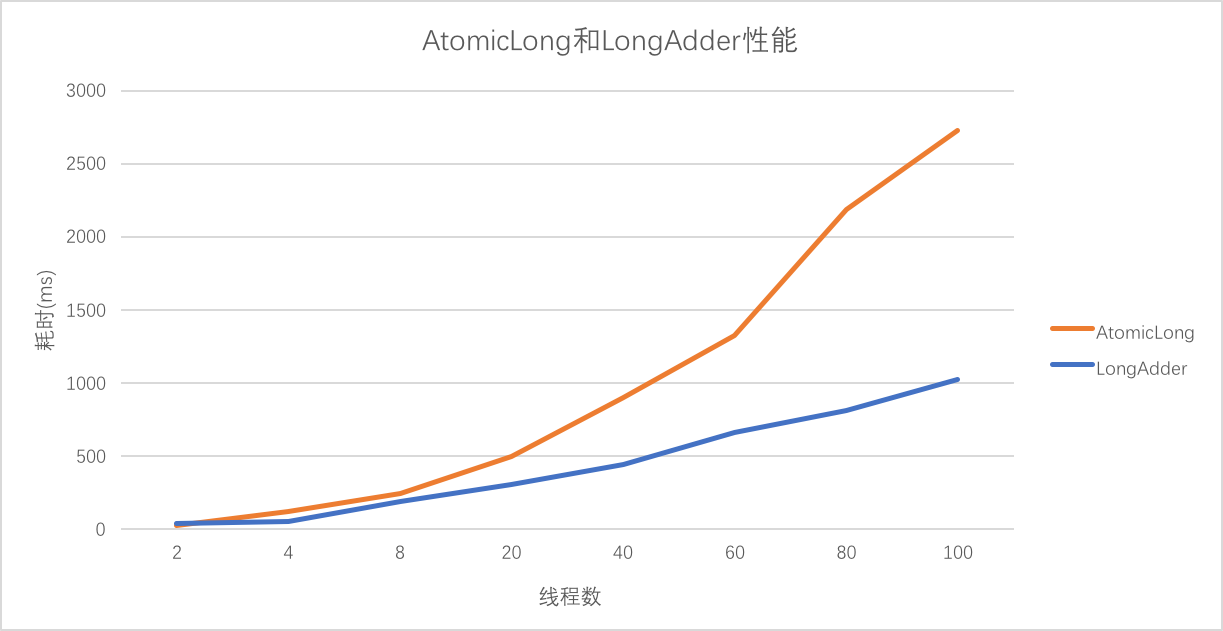
其中每个线程自加AtomicLong和LongAdder一万次,当线程数越多时,可以很明显看出LongAdder的耗时比AtomicLong的耗时要低很多。
三.原理
1.AtomicLong
首先介绍AtomicLong的实现原理,AtomicLong内部使用一个long型变量用来存储AtomicLong代表的数值,对于数值的操作都是基于CAS实现,保证操作的原子性和可见性。
再更深入了解原理前,先来熟悉下CAS是什么。
CAS的全称Compare And Swap,比较并且交换。它提供了保证读,更新,写连续操作的原子性。它能够实现主要依赖于底层硬件架构的支持,CPU提供了原语操作指令,可以保证以上操作的原子性。
compareAndSwapLong(this, valueOffset, expect, update)
如,以上的CAS操作API,它先比较expect值与当前值是否相等,如果相等再将update值更新进去。其中第一个参数是对象,第二个参数是需要更新的变量在对象中的偏移量,第三个是期待值,第四个参数是需要更新进去的值。
CAS的能力在Java中由Unsafe提供,该类是一个具有不安全操作类,因为它提供不安全操作内存的功能,Java的内存都是JVM管理。故该类是包访问权限,避免开发者们随意调用,造成数据不安全问题。
从以上的分析中,是否联想到了乐观锁的机制,CAS其实就是一种乐观锁机制的实现。通过比较,然后决定是否更新。
再回到AtomicLong的原理问题探讨上,下面通过AtomicLong源码初略分析下它。
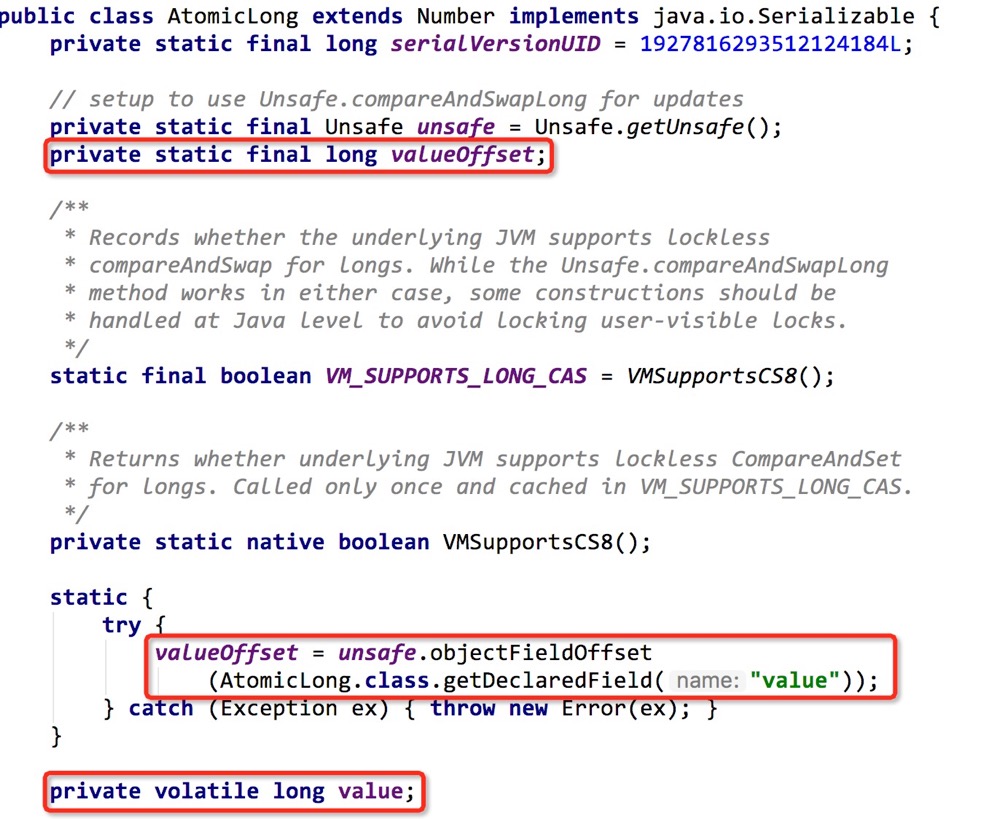
如上图标注,AtomicLong中最为关键两个域分别是value和valueOffset。
其中value被volatile修饰,保证value在多线程下的可见性。虽然Unsafe也提供了getObjectVolatile接口也可以用于并发的可见性,但是没有volatile便捷和优雅。valueOffset表示的是value在AtomicLong中的偏移量,JVM可以根据AtomicLong的base + 偏移量快速定位到内存中value值,进行操作。
这里需要注意的是,valueOffset偏移量值获取方式,同样也是利用Unsafe提供的objectFieldOffset方法。这个点,非常重要,在日常应用的开发中我们也可以这样使用,且返回的偏移量是long类型。
其实上述代码是Java中使用Unsafe的CAS的一套模板,在应用开发中如果也需要使用CAS,就可以按照这样模板构建:
- 定义变量;
- 定义变量的偏移量,long类型;
- 使用静态语句块在Class对象初始化时,利用Unsafe的objectFieldOffset计算变量的偏移量。注意需要catch异常;
由于AtomicLong提供的操作非常多,这里挑选一个自加操作分析。
public final long incrementAndGet() {
return unsafe.getAndAddLong(this, valueOffset, 1L) + 1L;
}
内部非常简单,只有一行语句。直接调用Unsafe的getAndAddLong实现。
2.LongAdder
当在并发竞争比较激烈的情况下,很多线程会进行CAS操作,每次其实只有一个线程能成功。其他线程需要通过不断的Spin操作,才能成功。这样导致的问题是,增加CPU开销,效率低
下,无疑降低吞吐量。简而言之,还是锁的机制带来的竞争后果。
既然如此,再来看看LongAdder的设计,是如何解决锁竞争激烈的问题。
One or more variables that together maintain an initially zero {@code long} sum. When updates (method {@link #add}) are contended across threads, the set of variables may grow dynamically to reduce contention. Method {@link #sum} (or, equivalently, {@link #longValue}) returns the current total combined across the variables maintaining the sum.
AtomicLong中是用一个long类型值表示AtomicLong所表示的数值,所以存在多线程读写竞争一个变量的问题。LongAdder正是对这个竞争点做了优化,它将long型的值做了拆分,拆分成一个Base + 多个Cells的和来表示long。多线程的操作可以分散多个Cells,从而将竞争分摊,弱化竞争从而提升吞吐量。本质上,这种方式细化锁的粒度,从而降低竞争。
接下来从源码角度分析下设计的实现方式。首先分析看下LongAdder提供的API:

正如文章开篇列,LongAdder提供了很多long操作的接口。但是它只提供了操作的行为,关于数据的存储却不在LongAdder本身中定义的,而是在其父类Striped64中定义。
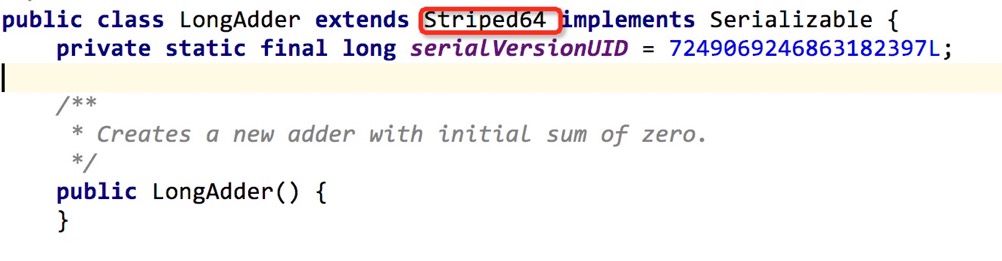
Striped64中有几个非常关键的域

- NCPU:CPU核数
- Cell数组:每个Cell都包含一个long值,且提供对这个值的CAS操作
- base:基本值
- cellBusy:用来表示cell是否存在竞争

多线程竞争环境下,尽量将每个线程的操作,比如累加累减分摊到不同的Cell上,每个Cell提供CAS操作。如果需要获取LongAdder的值,只需要将Cells的long累加再加上base,即是LongAdder的值。当竞争缓和时,直接操作base。
但是如何将不同线程对应到Cell数组的哪个Cell上,又是一个分片的本质问题。接下来分析下LongAdder的add方法,看透其本质:

在初始化LongAdder时,会调用父类Striped64的构造方法,两者的构造方法中没有任何逻辑,空方法。由此可以看出当LongAdder被实例化后,其中cells是null。当在后续每次调用add时,有以下几种情况:
- (as = cells) != null为false,然后使用cas直接在base上累积,如果成功则直接返回
- (as = cells) != null为false,然后cas累加base失败,则说明有多线程竞争
- (as = cells) != null为true,说明cells已经被初始化,说明之前存在多线程竞争
int h = (hc = threadHashCode.get()).code 获取线程的hashCode
如果cells为null,或者线程hashCode需要操作的cell为null,说明cell未被初始化,或者是线程需要操作的cell未被初始化。则调用Striped64中retryUpdate方法,初始化cells或者cell,或者扩容cells。
四.优秀设计
看了AtomicLong的实现或许会立马想到ReentrantLock或者Synchronized也可以实现原子类,只要在操作前获取锁,操作完释放锁。
但是为什么不用这些锁,而是用CAS呢?
显然,这些锁都是互斥锁,在多线程竞争激烈的情况下,伴随着大量线程上下文切换和独占,严重降低吞吐量。
然使用CAS + Volatile,这种乐观锁的机制,能使得线程Spin,并且可以并发读。这将会大幅度提升吞吐。
然而无论是互斥锁还是CAS + Volatile,它们本身都是一种锁机制。在严重竞争的情况下,都会有性能牺牲,比如大量的CAS失败,反复的Spin,消耗CPU资源。
在这种情况下,需要弄清楚竞争的资源是什么,是否可以将竞争点拆分,分摊压力。这种方式本质上是一种锁的粒度控制,将锁的粒度控制的更细,锁的范围更小。这种做法很多地方都有:
- ConcurrentHashMap中的实现,将对整个Map的锁,细化到对每个Segment上
- 如使用Synchronized或者ReentrantLock,尽量控制锁的范围,避免锁的范围
- Mysql的表锁和行锁设计,从MyISAM表锁到InnoDB支持行锁,将锁的粒度控制在行,从而提高存储引擎的并发
通过以上的优秀设计,可以总结出一套锁的优化思路:
互斥锁 -> 乐观锁 -> 锁的粒度控制
在Java中对应的实现方式:
ReentrantLock或者Syschronized -> CAS + Volatile -> 拆分竞争点

 浙公网安备 33010602011771号
浙公网安备 33010602011771号