一、汇编
-
进制01
可以通过修改约定俗成的进制符号,起到对外加密的作用
比如8进制默认的是
0 1 2 3 4 5 6 7
我们可以将其打乱成
5 2 3 0 1 4 6 7
这里的符号‘5’对应默认的0 , 当然不仅是打乱,耶可以替换成其他其他字符
非十进制的计算,先手算出1+1~n+n,乘法通过查加法表完善,之后的大数相乘就和十进制类似列竖式
-
进制02
进制说了许多感觉没有意义的东西,目的就是想让我们了解进制的含义,逢N进一,抛开传统的十进制和数字作为符号,扳手指头计算。
-
数据宽度_逻辑运算
重要的计量单位 BYTE 字节 8-bit WORD 字 16-bit DWORD 双字 32-bit
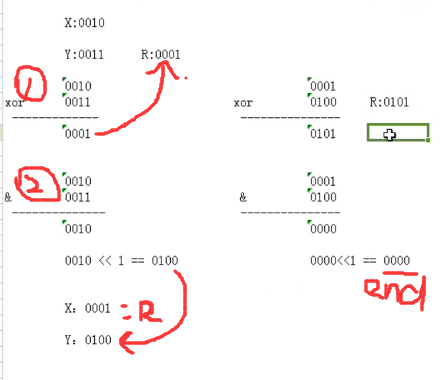
可逆的逻辑运算:^(异或,相同为0,不同为1)、!(非,取反)
CPU对加法的本质运算
-
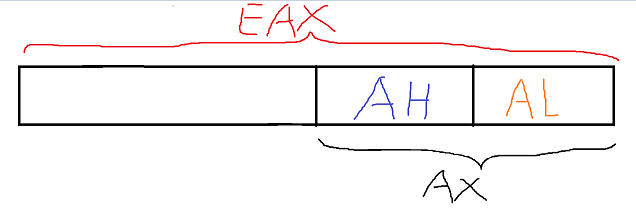
通用寄存器_内存读写
寄存器结构: EAX - AX - AH - AL
其中EAX为32位寄存器,AX为16位寄存器,AH与AL位8位寄存器,它们之间为包含关系

总结一下就是:立即数复制到寄存器,多余的直接扔掉。只有大小相同的寄存器之间才能mov
add和sub运算可以是目标操作数的大小大于源操作数,比如 " add r/16,r/8 "

内存mov到内存需要用寄存器中转一下。
-
内存地址_堆栈
大小端:大端模式即数据的高字节保存在内存的低地址中,小端模式即数据的高字节保存在内存的高地址中
比如0x12345678, 以16进制呈现,在大端模式中为 " 12 34 56 78 ",在小端模式中为" 78 56 34 12 "
很多时候逆向解密的时候需要细心处理大小端的问题
内存的寻址:
1. [立即数] eg:" dword prt ds:[0xff865f8] "
2..[寄存器] eg:“ dword prt ds:[eax] ” 寄存器需要是8个通用寄存器之一
3.[寄存器+立即数] eg:“ dword prt ds:[eax+0x10] ”
4.[寄存器+寄存器*{1,2,4,8}] eg:" dword prt ds:[eax+exc*2] "
5.[寄存器+寄存器*{1,2,4,8}+立即数] eg:" dword prt ds:[eax+exc*2+0x10] "
堆栈内数据查询可通过ebp(栈底)+offset(偏移),也可通过esp(栈顶)+offset(偏移)实现
-
标志寄存器
1.进位标志CF (Carry Flag) :如果运算结果的最高位产生了-一个进位或借位,那么,其值为1,否则其值为0。
2.奇偶标志PF (Parity Flag):奇偶标志PF用于反映运算结果的最低有效字节(后8位)中“1”的个数的奇偶性。如果“1”的个数为偶数,则PF的值为1,否则其值为0。
3.辅助进位标志AF (Auxiliary Carry Flag) :在发生下列情况时,辅助进位标志AF的值被置为1,否则其值为0:
(1)、在字操作时,发生低字节向高字节进位或借位时;
(2)、在字节操作时,发生低4位向高4位进位或借位时。
4.零标志ZF (Zero Flag): 零标志ZF用来反映运算结果是否为0。如果运算结果为0,则其值为1,否则其值为0。在判断运算结果是否为0时,可使用此标志位。
5.符号标志SF Flag):符号标志SF用来反映运算结果的符号位,它与运算结果的最高位相同。
6.溢出标志OF (Overflow Flag):溢出标志0F用于反映有符号数加减运算所得结果是否溢出。如果运算结果超过当前运算位数所能表示的范围,则称为溢出,OF的值被置为1,否则,OF的值被清为0
注意溢出标志位是给有符号的运算使用的,有以下规律:
正 + 正 = 正 如果结果是负数,说明有溢出
负 + 负 = 负 如果结果是正数,说明有溢出
正 + 负 永远不会溢出
而计算机最终是这样计算OF的:
首先做加法(减法可以看作是加法),设x=0/1(符号位无进位/有进位),y=0/1(最高有效位无进位/有进位),那么OF = x ^ y

7.方向标志DF (Direction Flag):决定执行某些语句后,寄存器值的 ‘ 增长 ’ 方向
eg : STOS DWORD PTR ES:[EDI] 当DF为0时候,EDI加上DWORD宽度,当DF为1时候,EDI减去DWORD宽度
ps:mov指令不修改标志寄存器的值
进位标志表示无符号数运算结果是否超出范围,溢出标志表示有符号数运算结果是否超出范围.
ADC指令:带进位加法,用法和ADD一样,只不过会额外加上CF标志位,并将其还原
SBB指令:带错位减法,用法和SUB一样,只不过会额外减去CF标志位,并将其还原
XCHG指令:交换指令,交换宽度相同的寄存器或内存(不包括内存和内存之间交换)
MOVS指令:移动数据,相当于MOV,并且支持内存之间的移动!!!
STOS指令:将AL/AX/EAX的值存储到[EDI]指定的内存单元,由宽度决定
REP指令:根据ECX的值决定重复次数。
eg:REP STOS DWORD PTR ES:[EDI] 就是将后面的句子重复ECX次
-
JCC
CMP:按照SUB运算,结果不保存,只修改标志位(比如ZF为0的时候说明两数相等)
TEST:两数进行与(&)操作,结果不保存,只修改标志位(一般用于判断该数是否为0)
常见的简单JCC:
JE/JZ:结果为零则跳转( 相等时跳转,ZF=1 )
JNE/JNZ:结果不为零跳转( 不相等跳转,ZF=0 )
JS:结果为负则跳转( SF=1 )
JNS:结果为非负则跳转( SF=0 )
JP/JPE:结果(低8位)中1的个数为偶数则跳转( PF=1 )
JNP/JPO:结果(低8位)中1的个数为奇数则跳转( PF=0 )
JO:结果溢出了则跳转( OF=1 )
JNO:结果没有溢出则跳转 ( OF=0 )
-
堆栈图
默认给每个函数都有分配一个栈缓存区,可以控制栈缓存区的大小,也可以取消分配。每次申请栈缓存的时候,里面都是历史数据,也就是垃圾内容,所以栈缓存区一般全部分配为CC,硬编码就是 'int8' 终止 当程序异常执行到栈的时候终止程序。
-
C语言基础
就算一个函数内没有任何c语句,程序默认要申请缓存区并为其赋处置CC。使用以下函数,编译器不会对空函数做任何处理:
void __declspec(naked) Fuction() { }
既然这样,就可以自己控制如何进行堆栈调整,比如
int __declspec(naked) Fuction(int a,int b) {//实现a+b _asm { push ebp mov ebp,esp sub esp,0x10 mov eax,dword ptr ds:[ebp+0x8] add eax,dword ptr ds:[ebp+0xc] mov esp,ebp pop ebp ret } }
此函数属于__cdecl,即调用者调正栈帧
-
数据类型
有符号与无符号变量,在内存中的存储一模一样,是由使用者来决定有无符号。
比如 char a=0xff; char b=1; 则a<b
浮点数的二进制储存:

有一个符号位,整数部分除以二取余数,从下往上列,小数部分乘以二取整数部分,从上往下列(小数部分可能存在精度问题),指数部分可以使用127±3(左移加,右移减)
https://www.bilibili.com/video/av36036005?t=738&p=13 111:34 关于float在内存中的存储
变量的储存:全局变量程序开始就分配内存,地址固定。局部变量在用到的时候分配内存,分配到堆栈内。
数据类型的转换:
小到大:MOVSX 符号扩展,即高位补符号位
MOVZX 零扩展,即高位补零
大到小:仅截取低位
-
函数
常见的几个约定调用:
__cdecl:从右至左入栈,调用者平衡栈
push 2
push 1
call fuction
add esp,0x8
__stdcall:从右至左入栈,被调用函数平衡栈
push 2
push 1
call fuction
------------------------------
fuction:
push ebp
mov ebp,esp
sub esp,0x40
.....
mov esp,ebp
pop ebp
ret 8
// 这里的ret 8 == pop eip
// add esp,8
__fastcall:ECX/EDX传递前两个参数(从左至右),剩下的参数从右至左入栈,被调用函数调整栈
Fuction(1,3,7,9):
push 9
push 7
mov edx,3
mov ecx,1
call fuction
既然想要变得fast,最好就是在只有2个一下参数的时候使用,不然意义不大
函数的返回值:返回1字节保存在al寄存器,2字节( short )保存在ax寄存器,4字节( int )保存在wax寄存器,8个字节( __int64 ) 高32位保存在edx寄存器,低32位保存在eax寄存器。
参数的传递:4字节以下的参数均以4字节传递,使用的时候仅取要用的部分。8字节的参数拆分成两个4字节,由高位到低位入栈。
栈空间的分配:遵循对齐本机位数的原则。定义任意一个4字节以下的变量,都会为其分配4字节。但是定义一个数组,会向上对齐到4的倍数,然后从左到右,从低地址到高地址存储。比如char[6]= 会分配 ( (6*4/)+1 )*4 = 8字节的空间。

多维数组的分布按照维度由低到高,栈地址由小到大匹配,仍然存在对齐4字节的规则

-
结构体
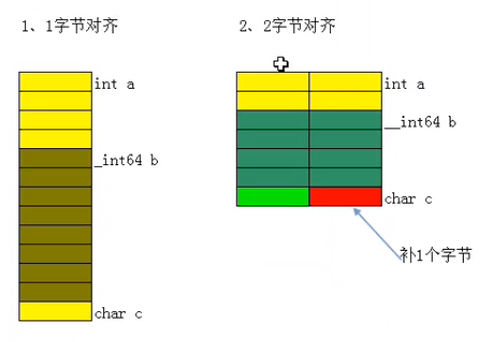
结构体的储存和数组相似,各个变量的地址都连续,不一样的是结构体内可以有不同的变量类型。结构体仍然存在内存对齐,不过并不是每个内部类型分别对齐,而是全部空间加起来对4向上取整。如下:

如图可见,结构体内定义了byte,word,dword各一个,但是总空间只有3c-38=8字节。因为他将byte和word放在了一个4字节的空间里了。
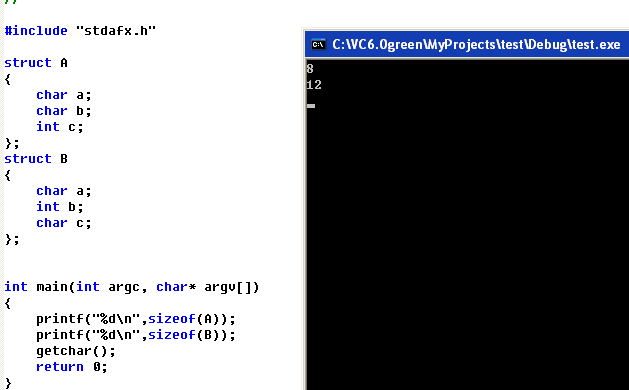
可以看作是依次为变量分配空间,每次分配前先检查上一次分配后剩下的空间是否够该变量类型分配,如果可以就利用上一次的,否则就新开辟一块。
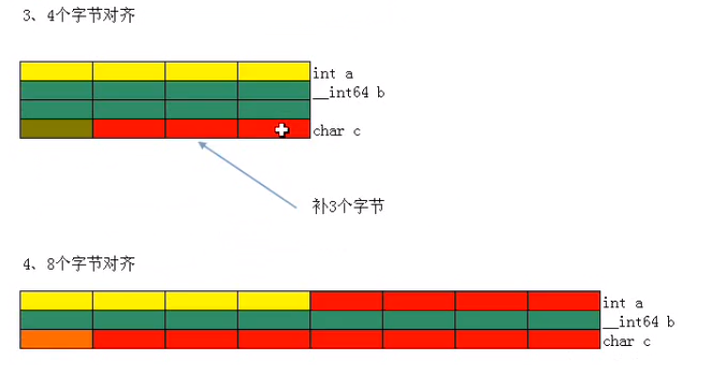
此外,因为编译器默认的对齐参数是4,我们可以修改其对齐参数(1,2,4,8),使用#prgma pack(n),将结构体包起来,如下
#pragma pack(8) struct A { char a; int b; long long c; } #pragma pack() // 后面这里不需要数字
每次对齐的值应该是对齐参数和变量类型中的较小值,比如一个结构体中一次定义了 int a;char b;char c; 对齐参数是8,但实际分配是这样的
a a a a b c 0 0
最终的空间大小一定是最大变量类型的整数倍。
具体还是参考滴水的视频把。。。
https://www.bilibili.com/video/BV1yt41127Cd 48:37
-
Switch语句
怎样编译都看编译器,一般来说有以下规律:
较少的时候按照if else编译
较多且比较连续的时候,生成大表,大表内连续,但是可能存在很多浪费
较多且不比较连续的时候,生成大表和小表,小表的目的是确定大表内的偏移,大表不存在空间浪费的情况
-
指针
理解为一种带*的变量,赋值只能使用“完整写法” 比如
char* a=(char*)1
带*变量的宽度永远是4字节,不论何种类型带*,也不论带多少个*
自增、自减、加减一个整数,要根据去掉一个*之后的类型判断其宽度。比如 char* 自增自减1 char**自增自减4
两个完全相同的带*变量可以相减,不能相加,结果应该除以去掉一个*后变量的宽度,也就得到了偏移量
& 可以取任何一个变量的地址,返回的类型为 变量类型+* 。比如
char a; //&a 的类型为 char* char*** b; //&b 的类型为 char****
* 可以取任意一个地址的值,返回类型为 变量类型-* 。 比如
char* a; //*a 的类型为 char char*** b; //*b 的类型为 char**
所以变量类型没有带*的变量不能在前面加*
这样一看,*和&就是两个逆运算,前者是取地址的值,后者是取变量的地址。意思是
int a=10; int* x = &a; // 则 *x = a 即类型和值完全相同
指针类型可以用于遍历数组,只需要把数组的某个值的地址传给指针即可,数组名就相当于数组第一个变量的地址。
char a[5]; char *p ; p = a //和 p = &a[0] //意义相同
特别的char* 还可以直接指向一个string。
char* p="abcdef";
此时的"abcdef"是一个全局变量。即有固定内存地址。
数组指针:实质就是把指针指向数组第一个变量的地址,使用指针来替代变量名,方便遍历数组。此外这两种定义有区别
int* a[5] int (*b)[5] b = (int (*)[5])a;//b point to a
第一个是定义了5个指针,第二个是定义了一个数组指针,可以指向一个数组,并且自增,自减,加减都是以5个int为单位一,即b++就是加上20。特殊的,**b才能取值,b和*b的值一样,都指向数组的首地址,但是类型不同,所以进行加减相同立即数的结果不同。b的类型为int*[2] 自增移动2*4个字节.*b的类型为int* 自增移动4个字节。
总结一下:数组指针是为了修改自增,自减的幅度而自行设计的。这里的数组指针是一维数组指针。相当于把一维数组分成,以5个为一维的二维数组。
n维数组指针类似,要用n+1个*才是取值,每次使用一个*,相当于降一维,从前到后降。
函数指针:把指向的数据段执行。如下

-
位运算
算数移位指令(SAL,SAR):移出去的那一位都记录在CF位,左移补零,右移补符号位

逻辑移位指令(SHL,SHR):移出去的那一位都记录在CF位,左移右移都补零
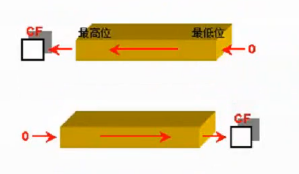
循环位移指令(ROL,ROR):顾名思义,最左端左移成为最右端,最右端右移成为最左端
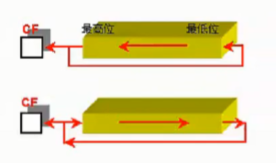
带进位的循环位移指令(RCL,RCR):循环过程中,增添了CF位,溢出的部分进入CF,CF以前的补上需要补的地方

 浙公网安备 33010602011771号
浙公网安备 33010602011771号