
Python爬虫Post请求返回值为-1000
今天写了一个简单的爬虫程序,为了爬取kfc官网的餐厅数据,代码如下
# ajax的post请求--肯德基官网
def create_request(page):
url='http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx'
data={
'cname':'濮阳',
'pid':'',
'pageIndex':page,
'pageSize':10
}
new_data=urllib.parse.urlencode(data).encode('utf-8')
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:128.0) Gecko/20100101 Firefox/128.0'
}
# post方式不能直接拼接,要在请求对象定制的方法中加入该参数
request=urllib.request.Request(url=url,headers=headers,data=new_data)
return request
def get_content(request):
response=urllib.request.urlopen(request)
content=response.read().decode('utf-8')
return content
def load_content(page,content):
with open('kendeji'+str(page)+'.json','w',encoding='utf-8') as fp:
fp.write(content)
if __name__=='__main__':
start_page=int(input('请输入起始页码'))
end_page=int(input('请输入终止页码'))
for page in range(start_page,end_page):
request=create_request(page)
content=get_content(request)
print(f"页面 {page} 的内容: {content}")
# load_content(page,content)
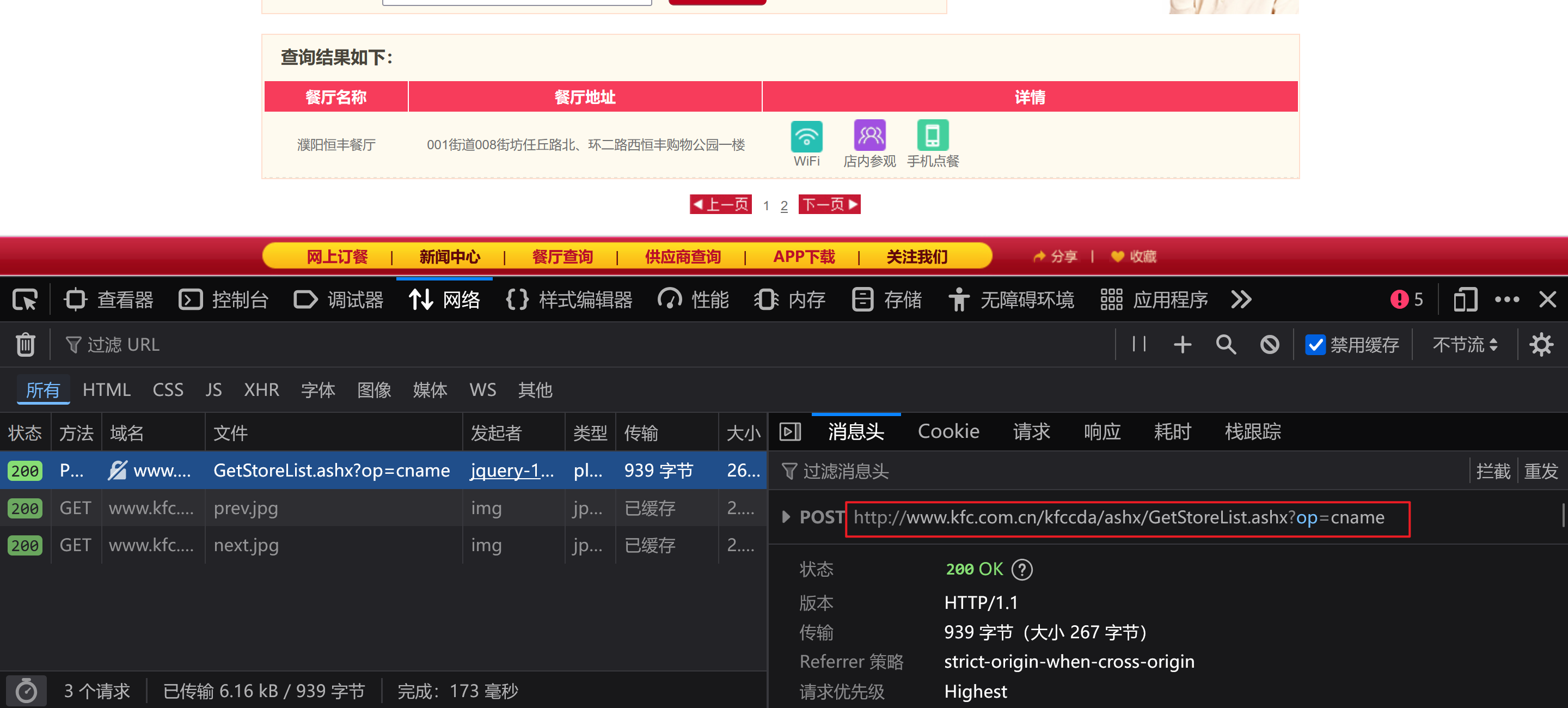
结果如下图:

原因如下:
1.URL中的参数没有复制全
我的URL:
url='http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx'
正确的URL:
url='http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
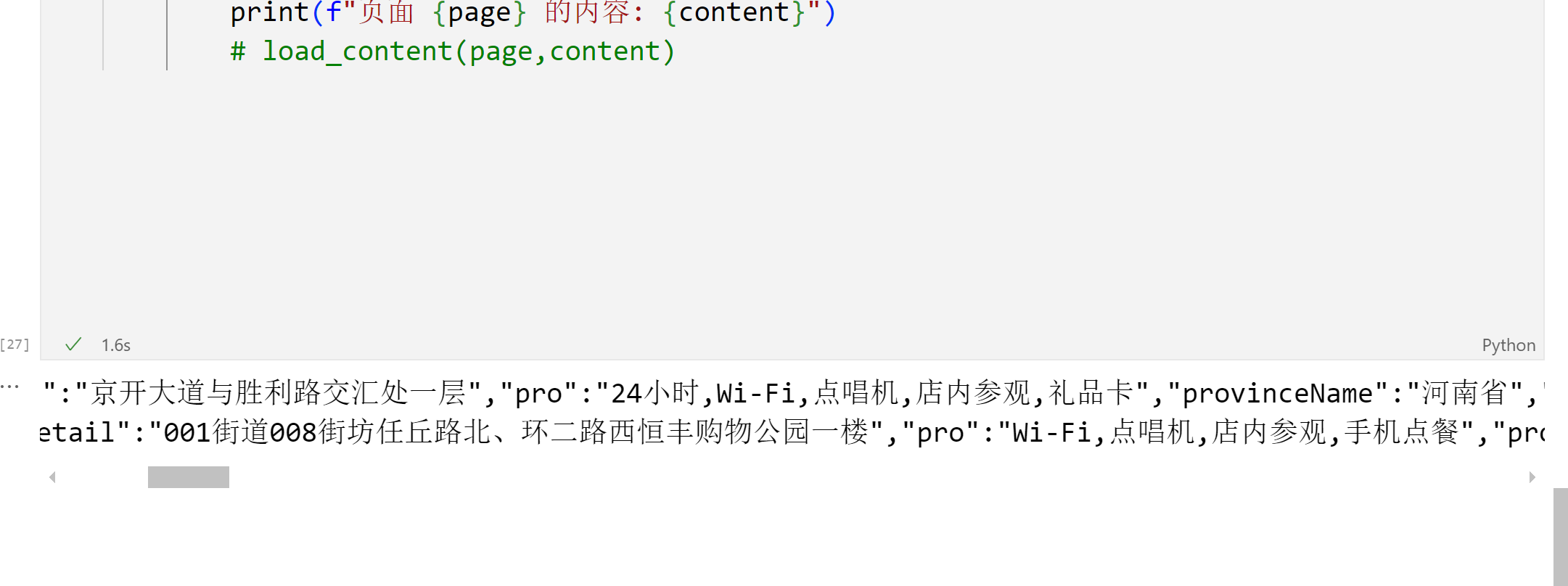
修改后的代码运行结果如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号