

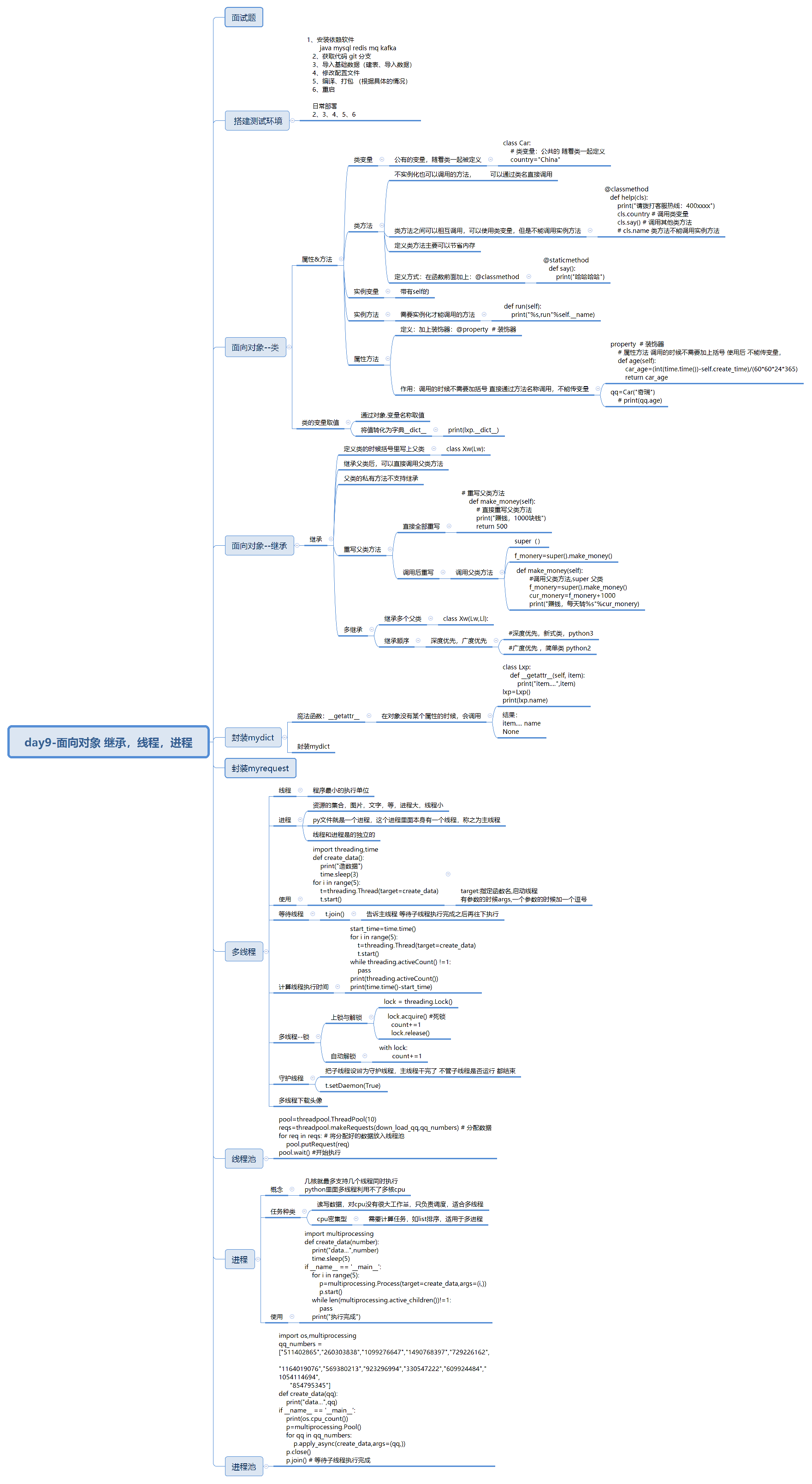
一、内容大纲
二、面试题讲解
面试题内容:

代码:
from collections import defaultdict
def get_data(string:str):
index_list_map=defaultdict(list)
print(index_list_map)
[index_list_map[s].append(index) for index,s in enumerate(string) if string.count(s)>1]
print(index_list_map)
count=1
for index_list in index_list_map.values():
for index in range(len(index_list)-1):
start_index=index_list[index]
end_index=index_list[index+1]
target_str=string[start_index:end_index+1]
target_len=len(target_str)-2
print("%s. %s %s"%(count,target_str,target_len))
count+=1
if __name__ == '__main__':
l="qweasessqs"
get_data(l)
知识点:defauldict:设置字典默认值
例:
from collections import defaultdict
d=defaultdict(dict)
print(d["age"])
结果:{}空字典
三、搭建测试环境
3.1新的测试环境搭建
1、安装依赖软件
java mysql redis mq kafka
2、获取代码 git 分支
3、导入基础数据(建表、导入数据)
4、修改配置文件
5、编译、打包 (根据具体的情况)
6、重启
3.2、更新测试环境:
不需要安装依赖,只需要2,3,4,5,6步
四、面向对象--类的其他属性和方法
4.1类变量与类方法:
公有的变量,随着类一起被定义
例:
class Car:
# 类变量:公共的 随着类一起定义
country="China"
类方法:不需要实例化也可以调用的方法
特点:通过类名直接调用,但是不能调用实例方法,可以调用类变量以及其他类方法
定义:在方法前加上@classmethod
class Car:
# 类变量:公共的 随着类一起定义
country="China"
@classmethod
def help(cls):
print("请拨打客服热线:400xxxx")
cls.country # 调用类变量
cls.say() # 调用其他类方法
# cls.name 类方法不能调用实例方法
调用:
Car.help()
4.2实例变量与实例方法
带有self的,必须实例化才能调用的方法
def __init__(self,name):
self.__name=name #实例变量 待self的 self.xxx
def run(self):
print("%s,run"%self.__name)
调用:
bmw=Car("宝马")
bmw.run()
4.3属性方法:@property
调用的时候不需要加上括号,不能传参
@property # 装饰器
# 属性方法 调用的时候不需要加上括号 使用后 不能传变量,
def age(self):
car_age=(int(time.time())-self.create_time)/(60*60*24*365)
return car_age
调用:
qq=Car("奇瑞")
print(qq.age)
4.4变量取值:
数据转化为字典:__dict__
import faker
f=faker.Faker(locale="zh_CN")
class Student:
def __init__(self,name,age,_class,addr,email,country="china"):
self.name=name
self.age=age
self._class=_class
self.addr=addr
self.email=email
self.country=country
lxp=Student(f.name(),26,"飞马","1@qq.com","China")
# 可以通过类.取数据
print(lxp.name)
# 转化为字典
print(lxp.__dict__)
结果:{'name': '李刚', 'age': 26, '_class': '飞马', 'addr': '1@qq.com', 'email': 'China', 'country': 'china'}
4.5,静态方法:@staticmethod
只是放在这里,无法调用其他方法,和类无关
@staticmethod
def say():
print("哈哈哈哈")
五、继承
1、定义:类被继承类)
class XXw(Lw)
2、特点:私有方法不支持继承
3、调用:
class Ll:
country="韩国"
def paocai(self):
print("泡菜")
def eat(self):
print("老李吃饭")
class Xl(Ll):
pass
xl=Xl()
xl.eat()
结果:老李吃饭
4、多继承
class Xw(Lw,Ll):
def huaqian(self):
print("花钱")
5、重写父类方法
(1)直接重写父类方法:
def huaqian(self):
print("花钱")
# 重写父类方法
def make_money(self):
# 直接重写父类方法
print("赚钱,1000块钱")
return 500
(2)继承后修改:super()
class XXw(Lw):
def dubo(self):
#继承父类后 可以直接继承父类方法
self.eat()
print("赌博")
def make_money(self):
#调用父类方法,super 父类
f_monery=super().make_money()
cur_monery=f_monery+1000
print("赚钱,每天转%s"%cur_monery)
六、封装myrequest,mydict
1、mydict:
(1)魔法方法:在对象没有这个属性的时候,会调用这个方法:--getattr
例:
class Test:
def __getattr__(self, item):
print("item...",item)
my=Test()
my.name
结果:item... name
(2)封装mydeict
class Mydict(dict):
def __getattr__(self, item):
value=self.get(item)
if type(value)==dict:
value=Mydict(value)
if isinstance(value,list) or isinstance(value,tuple):
value=list(value)
for index, v in enumerate(value):
if isinstance(v,dict):
value[index]=Mydict(v)
return value
if __name__ == '__main__':
d1 = {"name": "lxp", "age": 26, "info": {"city": "广州"},
"phone": ({"name": "huawei", "price": 5000}, {"name": "xiaomi", "price": 5900})}
my=Mydict(d1)
print(my.phone[0].price)
2、myrequest:
import requests
import traceback
from loguru import logger
class MyDict(dict):
def __getattr__(self, item):
value = self.get(item)
if type(value) == dict:
value = MyDict(value)
if isinstance(value,list) or isinstance(value,tuple):
value = list(value)
for index,v in enumerate(value):
if isinstance(v,dict):
value[index] = MyDict(v)
return value
class MyRequest:
def __init__(self,url,params=None,data=None,headers=None,files=None,json=None,timeout=5):
self.url = url
self.params = params
self.data = data
self.headers = headers
self.files = files
self.json = json
self.timeout = timeout
def __get_response(self):
try:
ret = self.response.json()
except:
logger.warning("接口返回的不是json!无法转成字典!response:{}", self.response.content)
return MyDict()
logger.debug("接口返回数据:{}", ret)
return MyDict(ret)
def __request(self,method):
logger.debug("url:{},params:{},data:{},json:{},files:{},headers:{}",self.url,self.params,self.data,self.json,self.files,self.headers)
try:
self.response = requests.request(method,url=self.url,params=self.params,data=self.data,
json=self.json,headers=self.headers,files=self.files,verify=False,timeout=self.timeout)
except:
logger.error("接口不通,请求出错,错误信息是:{}",traceback.format_exc())
return MyDict()
return self.__get_response()
def get(self):
return self.__request("get")
def post(self):
return self.__request("post")
def put(self):
return self.__request("put")
def delete(self):
return self.__request("delete")
if __name__ == '__main__':
data = {"file":open("myDict.py",'rb')}
r = MyRequest("http://118.24.3.41/api/file/file_uploa",files=data)
# result = r.get()
ret1 = r.post()
七、多线程,多进程
7.1线程
1、线程:程序最小的执行单位
2、使用:
import threading
def create_data(number):
print("data:",number)
for i in range(5):
t = threading.Thread(target=create_data,args=(i,))
t.start()
3、主线程:py文件是一个进程,这个进程里面有一个自带的线程,称之为主线程
4.计算时间
t.jion()告诉主线程,等待子线程执行完成再往下执行
判断全部执行完成:threading.activeCount():当前线程数
while threading.activeCount() !=1:
pass
计算时间:
start_time=time.time()
for i in range(5):
t = threading.Thread(target=create_data,args=(i,))
t.start()
# 等待线程执行完成
while threading.activeCount() !=1:
pass
end_time=time.time()
#查看当前线程数
print(threading.activeCount()) # 默认程序有一个线程
print("时间",end_time-start_time) # 主线程运动到现在的时间 不包含其他线程时间
5.上锁:lock=threading.Lock()
上锁与解锁:
上锁:
lock.acquire()
解锁:
lock.release()
自动解锁::with
with lock:
count+=1
6.线程池与头像下载:threadpool
import threadpool
pool = threadpool.ThreadPool(10)
reqs = threadpool.makeRequests(down_load_img, qq_numbers)
7、头像下载
import requests,os,threadpool
qq_numbers = ["511402865","260303838","1099276647","1490768397","729226162",
"1164019076","569380213","923296994","330547222","609924484","1054114694",
"854795345"]
MIAGE_URL="https://q4.qlogo.cn/g?b=qq&nk=%s&s=140"
def down_laod(qq):
url=MIAGE_URL%qq
req=requests.get(url)
path=os.path.join("images",qq+".jpg")
with open(path,"wb") as fw:
fw.write(req.content)
pool=threadpool.ThreadPool(10)
reqs=threadpool.makeRequests(down_laod,qq_numbers)
for req in reqs:
pool.putRequest(req)
pool.wait()
8、守护线程:
把子线程设置为守护线程,主线程活干完了,不管子线程是否在运行中,都结束程序
t.setDaemon(True)
for i in range(10):
t=threading.Thread(target=ganhuo)
t.setDaemon(True) # 把子线程设置为守护线程,主线程干完了 不管子线程是否运行 都结束
t.start()
print("主线程干完了")
结果:不会执行到子线程
9、继承的方式启动线程
import threading,time
class MyThread(threading.Thread):
def __init__(self,name):
super().__init__()
self.name = name
def run(self):
time.sleep(1)
# print("%s创建数据"%self.name)
print("创建数据")
for i in range(5):
t = MyThread("name")
t.start()
7.2进程
1、概念:资源的集合,如图片,文字等
进程大,线程小
2、特点:
任务分类:
(1)io密集型:读写数据,对cpu没有很大工作量,只负责调度,适合多线程
(2)cpu密集型:需要计算的任务,如排序等,适用于多进程
3、使用:与线程类似
import multiprocessing
import threading
import time
lock=multiprocessing.Lock()
def create_data(number):
print("data..",number)
#启动进程的时候必须要写在main里面
if __name__ == '__main__':
for i in range(5):
p=multiprocessing.Process(target=create_data,args=(i,))
p.start()
# 子进程
while len(multiprocessing.active_children()) !=1:
pass
print("运行完成")
4、进程池
import multiprocessing,time,os
qq_numbers = ["511402865","260303838","1099276647","1490768397","729226162",
"1164019076","569380213","923296994","330547222","609924484","1054114694",
"854795345"]
def create_data(number):
print("data..",number)
time.sleep(5)
if __name__ == '__main__':
print(os.cpu_count())
p=multiprocessing.Pool()
for qq in qq_numbers:
p.apply_async(create_data,args=(qq,))
p.close()
p.join() # 等待子线程执行完成
print("done")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号