2023数据采集与融合技术实践作业1
1.2023数据采集与融合技术实践作业1
实验1
实验:爬取软科排名的大学信息
实验要求:
用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
输出信息:
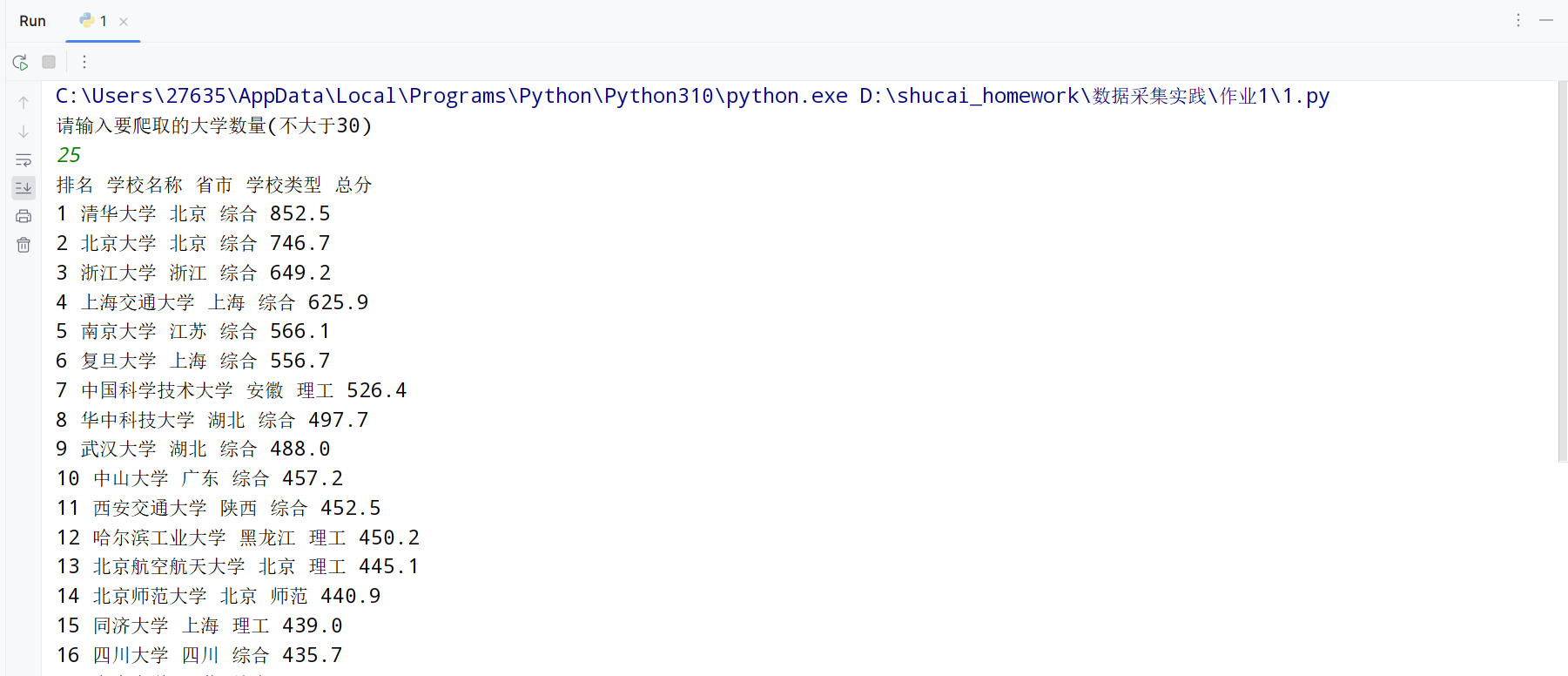
排名 学校名称 省市 学校类型 总分
1 清华大学 北京 综合 852.5
2......
点击查看代码
# _*_ coding : utf-8 _*_
# @Time : 2023/9/21 14:45
# @Author : lvmingxun
# @File : 1
# @Project : shucai_homework
import requests
from bs4 import BeautifulSoup
import bs4
def printall(html,num):
x = int(0)
print("排名","学校名称","省市","学校类型","总分")
soup = BeautifulSoup(html,"html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr,bs4.element.Tag):
a = tr('a')
tds = tr('td')
xuhao = tds[0].text.strip()
mingzi = a[0].string.strip()
shengshi = tds[2].text.strip()
xuexiaoleixing = tds[3].text.strip()
zhongfen = tds[4].text.strip()
print(xuhao,mingzi,shengshi,xuexiaoleixing,zhongfen)
x = x+1
if(x == num):
break
if __name__ == '__main__':
print('请输入要爬取的大学数量(不大于30)')
num1 = int(input())
start_url = "https://www.shanghairanking.cn/rankings/bcur/2020"
response = requests.get(start_url)
response.encoding = 'urf-8'
printall(response.text,num1)
点击查看运行结果
实验心得:学会了使用BeautifulSoup和request库爬取网页数据
实验2
实验:爬取商城商品的名称与价格
要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
输出信息:
序号 价格 商品名
1 65.00 xxx
2......
ps:选取当当网
点击查看代码
# _*_ coding : utf-8 _*_
# @Time : 2023/9/21 14:48
# @Author : lvmingxun
# @File : 2
# @Project : shucai_homework
import requests
import re
from bs4 import BeautifulSoup
import time
def getUrl(page):
if(page == 1):
url = 'http://search.dangdang.com/?key=%CA%E9%B0%FC&act=input&page_index=1'
else:
url = 'http://search.dangdang.com/?key=%CA%E9%B0%FC&act=input&page_index=' + str(page)
return url
def getHtmlText(url):
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Connection':'keep - alive',
'Upgrade - Insecure - Requests':'1',
'referer': 'http://search.dangdang.com/?key=%CA%E9%B0%FC&act=input&page_index=2',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'cookie':'ddscreen=2; __permanent_id=20230914142012452307023337867172107; dest_area=country_id%3D9000%26province_id%3D111%26city_id%3D0%26district_id%3D0%26town_id%3D0; __visit_id=20230914153906616162588952493689495; __out_refer=1694677147%7C!%7Ccn.bing.com%7C!%7C; search_passback=3aa3a5bba56ad27ea0bb0265f0010000d9bf67009dbb0265; __rpm=s_293152.520689412835%2C520689412836..1694677921402%7Cs_293152.520689412835%2C520689412836..1694677963051; __trace_id=20230914155243130214127882145433947'}
r= requests.get(url=url,headers = headers)
time.sleep(2) #画蛇添足
r.encoding = r.apparent_encoding
return r.text
def parsePage(ilt,html):
soup = BeautifulSoup(html, "html.parser")
num = re.findall('<li ddt-pit="(.*?)"',html)
plt = re.findall('<span class="price_n">¥(.*?)</span>',html)
tlt = re.findall("alt='(.*?)'",html)
for i in range(len(plt)):
number = num[i+1].split(':')[0]
price = eval(plt[i].split(':')[0])
title = tlt[i].split(':')[0]
ilt.append([number,title,price])
def printGoodsList(ilt):
for i in ilt:
print(i[0],i[1],i[2])
if __name__ == '__main__':
start_page = int(input("输入起始页"))
end_page = int(input("输入尾页"))
infoList = []
print("序号","商品名称","价格")
for page in range(start_page,end_page+1):
url = getUrl(page)
html = getHtmlText(url)
parsePage(infoList,html)
printGoodsList(infoList)
点击查看运行结果

实验心得:熟悉了re正则表达式,更加熟练掌握查找html的元素
实验3
实验:爬取给定网页所有JPEG、JPG格式文件
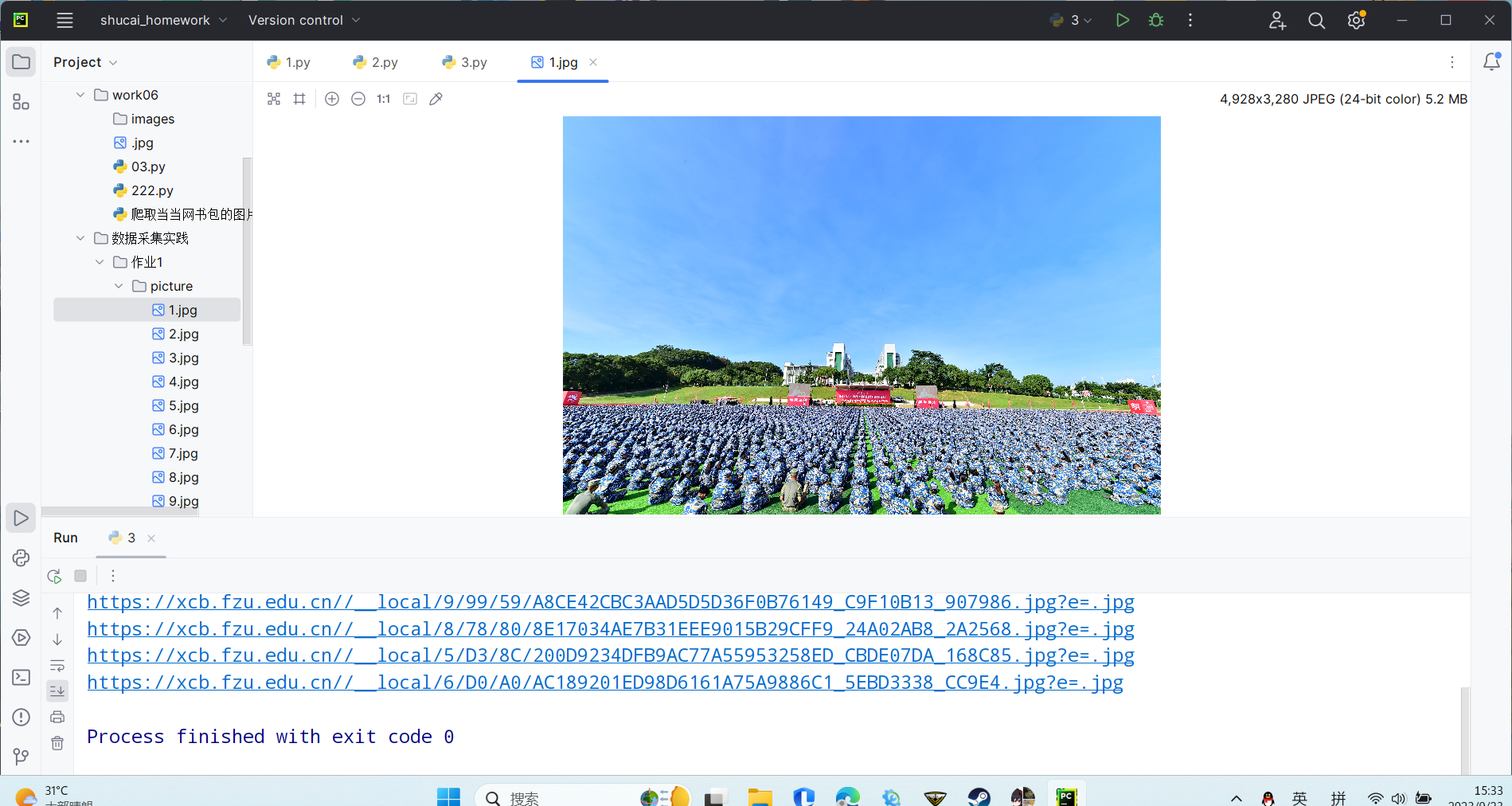
要求:爬取一个给定网页( https://xcb.fzu.edu.cn/info/1071/4481.htm)或者自选网页的所有JPEG和JPG格式文件
输出信息:将自选网页内的所有JPEG和JPG文件保存在一个文件夹中
ps:这里我选取了网页:https://xcb.fzu.edu.cn/info/1071/4504.htm
点击查看代码
# _*_ coding : utf-8 _*_
# @Time : 2023/9/21 14:49
# @Author : lvmingxun
# @File : 3
# @Project : shucai_homework
import urllib.request
from lxml import etree
def getcontent(url):
headers = {
'Use-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.31',
'Cookie' : 'JSESSIONID=EF2185F88B7A22E556CB70130B7A55B7'
}
request = urllib.request.Request(url=url, headers=headers)
with urllib.request.urlopen(request) as response:
content = response.read().decode('utf-8')
return content
def download(content):
tree = etree.HTML(content)
name = int(0)
src_list = tree.xpath('//*[@class="vsbcontent_img"]/img/@src')
for i in range(len(src_list)):
src = src_list[i]
img_url = 'https://xcb.fzu.edu.cn/' + src
name+=1
print(img_url)
urllib.request.urlretrieve(url=img_url,filename='D:\shucai_homework\数据采集实践\作业1\picture\\'+ str(name) +'.jpg')
if __name__ == '__main__':
url = 'https://xcb.fzu.edu.cn/info/1071/4504.htm'
content = getcontent(url)
download(content)
点击查看运行结果
实验心得:学会如何将爬取的数据下载到本地

 浙公网安备 33010602011771号
浙公网安备 33010602011771号