第五次作业——词法分析程序的设计与实现
词法分析程序(Lexical Analyzer)要求:
- 从左至右扫描构成源程序的字符流
- 识别出有词法意义的单词(Lexemes)
- 返回单词记录(单词类别,单词本身)
- 滤掉空格
- 跳过注释
- 发现词法错误
程序结构:
输入:字符流(创建测试数据a.txt,利用函数freopen()函数读取文件获取数据)
处理:
–遍历(利用do-while循环,通过cin.get()函数逐一获取字符到数组test中)
–词法规则
输出:单词流(判断完标识符的语种后,输出该种别码和该标识符)
–二元组
单词类别:
1.标识符(10)
2.无符号数(11)
3.保留字(一词一码)
4.运算符(一词一码)
5.界符(一词一码)
具体表格如下:
|
单词符号 |
种别码 |
单词符号 |
种别码 |
|
begin |
1 |
<= |
21 |
|
if |
2 |
<> |
22 |
|
then |
3 |
> |
23 |
|
while |
4 |
>= |
24 |
|
do |
5 |
= |
25 |
|
end |
6 |
== |
26 |
|
l(l|d)* |
10 |
! |
27 |
|
dd* |
11 |
!= |
28 |
|
+ |
13 |
; |
29 |
|
- |
14 |
( |
30 |
|
* |
15 |
) |
31 |
|
/ |
16 |
[ |
32 |
|
: |
17 |
] |
33 |
|
:= |
18 |
{ |
34 |
|
< |
20 |
} |
35 |
|
# |
0 |
$ |
-1 |
程序代码如下:
1 #include<stdio.h> 2 #include<string.h> 3 #include<iostream> 4 using namespace std; 5 6 int row=1;//记录行 7 int p=0; 8 int m=0; 9 char ans; 10 char test[200];//存放输入 11 char word[200];//存放经过转化的 12 const char *keyword[]={"begin","if","then","while","do","end"};//保留字 13 const char *symbol[]={"+","-","*","/",":",":=","<","<=","<>",">",">=","=",";","(",")","==","!","!=","/*","*/","[","]","{","}"}; 15 char comments[200]; 16 int mark=0;//用来记录输出的种别码 17 long long int sum=0;//记录和 18 19 void transfer(){//扫描字符串 20 int i,j; 21 for(j=0;j<200;j++) //每一次都要重新赋值 22 word[j]='\0'; 23 ans=test[p++]; 24 m=0; 25 while(ans==' ')//如果等于空格,则跳过 26 { 27 ans=test[p]; 28 p++; 29 } 30 if((ans>='A'&&ans<='Z') ||(ans>='a'&&ans<='z')) {//以字母开头的字母/数字串 31 m=0; 32 while((ans>='A'&&ans<='Z') ||(ans>='a'&&ans<='z')||(ans>='0' && ans<='9')){ 33 word[m++]=ans; 34 ans=test[p++]; 35 } 36 word[m++]='\0';//结束 37 p--;//往回退一位 38 mark=10;//标识符 39 for(i=0;i<6;i++){//查找是否为保留字 40 if(strcmp(word,keyword[i])==0){//若为保留字 41 mark=i+1;//保留字 42 break; 43 } 44 } 45 } 46 else if(ans>='0'&& ans<='9') {//判断是否为数字 47 sum=0; 48 while(ans>='0'&& ans<='9'){ 49 sum=sum*10+ans-'0'; 50 ans=test[p++]; 51 } 52 p--;//回退一位 53 mark=11;//为num 54 } 55 else if(ans=='<' || ans=='>' || ans=='=' || ans=='!'){// "<",">","<=",">=","=","==","!","!=" 56 m=0; 57 word[m++]=ans; 58 ans=test[p++]; 59 for(i=0;i<24;i++){ 60 if(strcmp(word,symbol[i])==0){ //追踪对应运算符的种别码 61 mark=13+i;//op 62 break; 63 } 64 } 65 if(ans=='='){ 66 word[m++]=ans; 67 for(i=0;i<24;i++){ 68 if(strcmp(word,symbol[i])==0){ //追踪对应运算符的种别码 69 mark=13+i;//op 70 break; 71 } 72 } 73 } 74 else 75 p--; 76 } 77 else if(ans=='*'){ 78 m=0; 79 word[m++]=ans; 80 ans=test[p++]; 81 mark=15;//* op 82 if(ans=='/'){ 83 mark=32;// */ symbol 84 word[m++]=ans; 85 } 86 else 87 p--; 88 } 89 else if(ans=='/'){ 90 m=0; 91 word[m++]=ans; 92 ans=test[p++]; 93 mark=16;// op 除号 94 if(ans=='*'){ 95 word[m++]=ans; 97 ans=test[p++]; 98 int k=0; 99 while(1){ 100 if(ans=='*' && test[p]=='/'){//检索到是注释 101 p++; 103 break; 104 } 105 else{ 106 mark=100;//检索到是注释 107 comments[k++]=ans; 108 ans=test[p++]; 109 } 110 } 111 } 112 else 113 p--; 114 } 115 else if(ans=='+'){//op 116 word[0]=ans; 117 mark=13; 118 } 119 else if(ans=='-') { 120 word[0]=ans; 121 mark=14; 122 } 123 else if(ans=='('|| ans==')' || ans=='[' || ans==']' || ans=='{' || ans=='}' || ans==';') {//symbol 124 word[0]=ans; 125 for(i=0;i<24;i++){ 126 if(strcmp(word,symbol[i])==0) //追踪对应运算符的种别码 127 mark=13+i;//界符 128 } 129 } 130 else if(ans=='#'){//特殊符号 131 mark=0; 132 word[0]=ans; 133 } 134 else if(ans=='$'){ 135 mark= -1;//结束符 136 word[0]=ans; 137 } 138 else if(ans=='\n'){ 139 mark=6;//表示换行了 140 } 141 else{ 142 mark=-2;//非法 143 } 144 } 145 146 int main(){ 147 char ch; 148 freopen("a.txt","r",stdin); 149 do{ 150 cin.get(ch);//可以接受空格 151 test[p]=ch; 152 p++; 153 }while(ch!='$');//以$结尾 154 p=0;//重新置为0 155 do{ 156 transfer(); 157 if(mark==11)//num 158 cout<<mark<<"\t"<<sum<<endl; 159 else if(mark==6) 160 row++; 161 else if(mark>=1&&mark<=36&&mark!=11) 162 cout<<mark<<"\t"<<word<<endl; 163 else if(mark==100){ 164 cout<<mark<<"\t/*"<<comments<<"*/"<<endl; 165 } 166 }while(mark!=-1); 167 return 0; 168 }
测试文本a.txt内容如下:

运行结果如下:
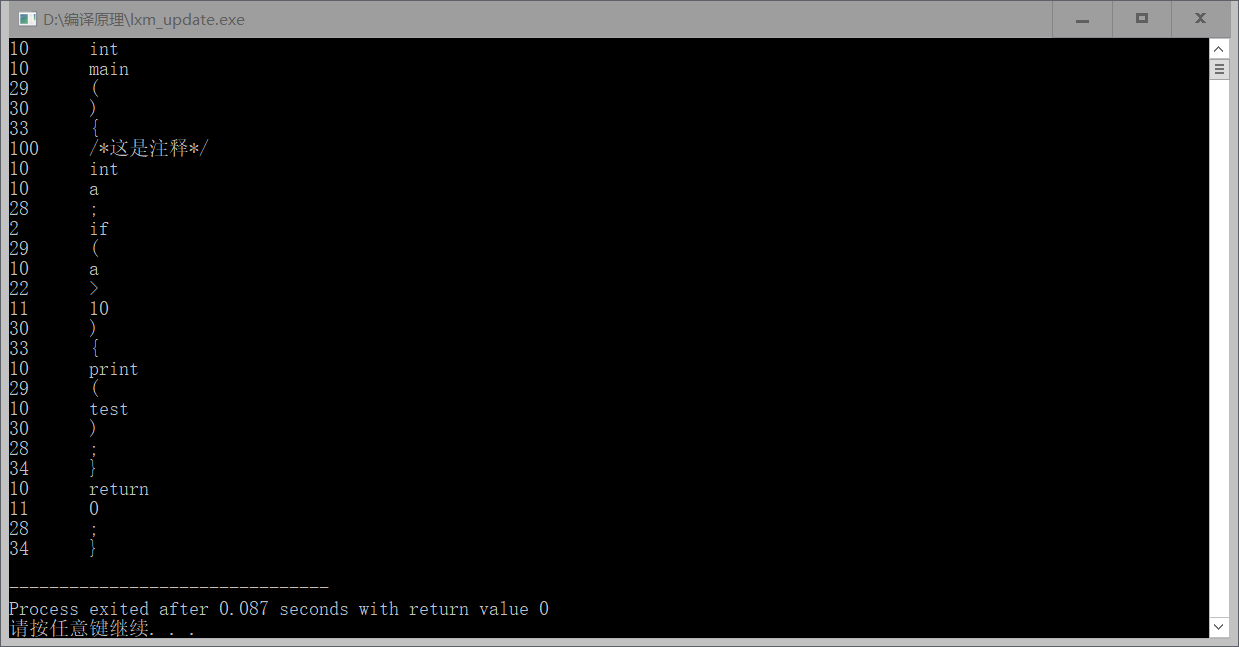
另外,该程序还有很多可以完善的地方,例如字符串应该以整串字符串的形式出现,保留字也可以增加进行精确区分。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号