

Chi: A Scalable and Programmable Control Plane for Distributed Stream Processing Systems
摘要 Chi主要是为了解决大规模集群下负载的变化性,以及难以进行静态参数调优、多种多样的用户SLO而提出的,具体来说,就是让流系统能够在运行时动态的重配置,Chi本质上是通过在原有流系统上嵌入一个控制平面,允许用户自定义控制操作,从而可以监测到系统运行情况,进行动态重配置
Chi以一个控制环路的方式实现这个控制平面,并且将控制消息嵌入到数据流中,从而重用了数据管道,Chi 引入了一种新的反应式编程模型和设计机制来异步执行控制策略,从而避免全局同步,最后实验证明了Chi的灵活性。
介绍
首先就是说传统批处理已经无法满足需要,我们需要流处理!
但是实现流处理所描述的优点有几个障碍:
- 流负载有时间与空间的可变性,后面具体描述这两种可变性
- 大规模集群有高度的硬件异构型以及不可预测的并发使用,这就使得算子分工很复杂
- 现代流系统往往有很大的参数空间,使得调优变得很难,就是说现在的流系统都很庞大复杂,难以人为调优
- 不同的用户使用一套流系统的时候可能会有不同的SLO(服务等级目标),需要不同的配置
为了解决这些问题,我们需要对流系统进行运行时监控,获得反馈,然后进行动态重配置,如资源重新分配/调度或者调优,我们就把负责这些控制操作的层叫做控制平面,与之相对应的就是数据平面(负责数据处理的层)
于是Chi这个团队就和云运营商进行讨论,他们得出一个控制平面需要满足三点:
- 应该能让用户自定义控制操作,以适应不同场景
- 应该给用户提供简单直白的API
- 控制开销应该尽可能地小
不幸的是现在没有系统能满足这三点,于是就产生了我们的Chi
Chi受标点符号机制的启发,将控制消息放到数据平面中,利用了数据平面的FIFO等特性,为了方便测试,他们团队在Flare上实现了Chi,Flare是他们团队自己的内部流系统
动机
通过分析超过200000台服务器的日志数据,Chi团队进行了广泛的研究,得到了以下结果:
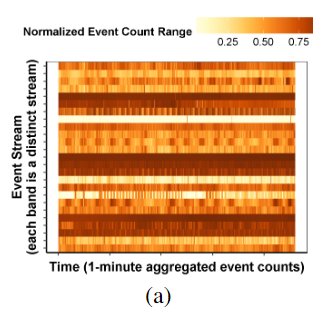
负载不可预测 检测到的负载变化如下图,首先每一行都有不同的特征,这就是空间可变性,而每一行有时会突然加深或者变浅,这就是时间可变性
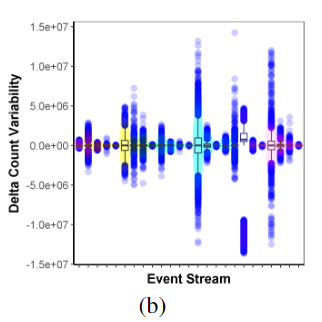
我们以每分钟的增量来量化这种可变性,绘制成箱须图,如下:
数据多样性 这里主要说的是key偏斜的问题,可能数据中的很大一部分都属于某几个key
多租客控制策略 就是说很多用户对同一个流系统有不同的控制策略,比如同一个流系统传输日志,对于某些重要的信息日志需要精确一次语义,对于某些详细日志,只需要至少一次语义
基于此,得出了控制平面的需要:
- 高效且可扩展的反馈控制回路
- 简单的控制接口
- 对数据平面的影响最小化
背景
本节主要介绍数据流模型,略
设计
我们主要关注Chi是如何实现上面的需求的
首先,Chi重用数据平面高效的基础设施,还可以为用户提供熟悉的API,并且这种重用还可以提供天然的异步屏障,从而完成异步操作
4.1 概述
Chi依赖于以下三个基本功能
- 算子之间的管道必须支持精确一次与FIFO传递,当下游算子buffer要填满时触发背压
- 算子按收到的顺序依次处理一个记录
- 底层引擎能提供算子生命周期管理的能力,允许我们启动、停止算子
1与2主要是用来保证一致性,目前很多流系统都已经实现了上述三个要求,包括Flink等
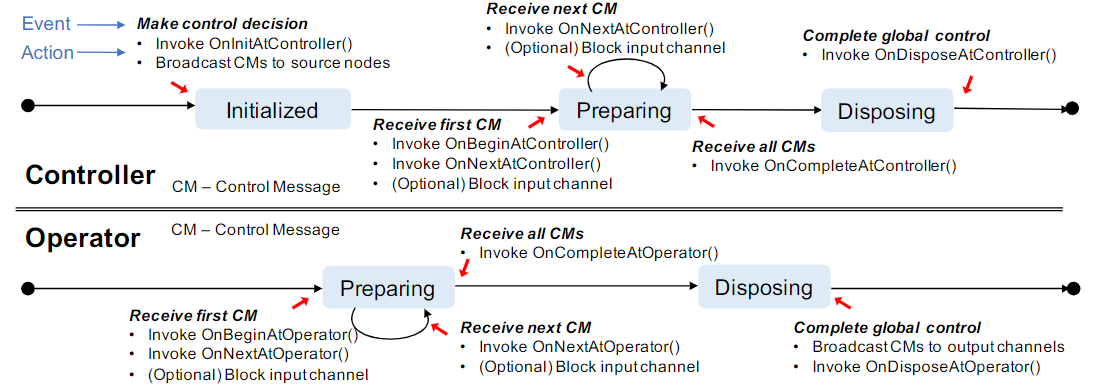
系统引入了一个控制器,负责监视数据流行为并触发控制操作,用户自定义的控制操作提交给该控制器
一个控制操作由控制环路来执行,由三阶段组成:
- 控制器做出控制决策,并使用唯一标识符实例化控制消息,控制消息里包含每个算子的配置变换
- 控制消息广播到所有源算子中,随数据在数据流图中传播,每个算子接收到控制消息后触发相应的操作
- sink算子将控制消息发送回控制器中,控制器进行后期处理
例如下图:

4.2 控制机制
接下来我们描述了支撑 Chi 的核心机制
4.2.1 通过元拓扑进行图转变
之前的例子中虽然很好的实现了控制操作,但还有一些实现细节没有讨论到,比如R3是何时被启动的,每次迁移可能会涉及到图拓扑的改变,本小节来描述如何实现图转变
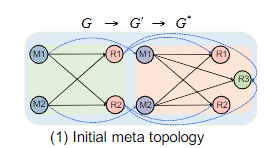
Chi通过一个中间拓扑图来完成迁移,定义原来的拓扑图为G,转变后的拓扑图为\(G^*\),中间元拓扑为G',迁移触发前,控制器将拓扑图G转变为G',迁移完成后再修剪为\(G^*\),G' = G ∪ \(G^*\) ∪ \(E_{V,V∗}\) 其中 \(E_{V,V∗}\)为G中影响\(G^*\)中状态的节点之间的边,这样就可以避免Flink中全部停止再迁移所引入的时延了,例如前面例子的元拓扑如下图:
但是这样会导致重配置期间对资源的利用率增加,数据流图的规模会扩大两倍,所以Chi又提出了一些优化:
状态不变性 如果一个控制操作没有改变算子的状态S,就可以合并两个算子,例如M1、M2
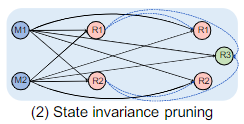
无环不变性 如果合并两个算子不会引入新的环路,可以合并两个算子
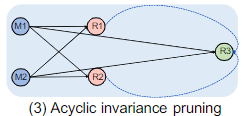
这就解决了状态迁移期间不停止的问题,实现了需求1:控制回路
4.2.2 控制API
Chi的控制API能为开发人员提供不同维度的控制操作,包括空间维度:M算子与R算子行为不同,时间维度:R3收到第一次控制消息与第二次控制消息的行为不同。我们向用户提供以下功能:
- 配置注入 允许一条消息承担不同算子的配置(实现空间维度)

- 响应式执行 Chi提供了一系列响应式接口,OnBegin操作与OnNext操作行为自定义(时间维度)
阻塞行为 在之前状态迁移的例子中,我们采用了阻塞并等待对齐的方式等待控制消息,在某些情况下可能很耗费时间,Chi提供了阻塞消息与非阻塞消息两种类型,以满足不同需求,例如在监视流系统的情况下就不需要阻塞

由此满足了需求2:可用API
4.3 高级功能
- 多控制器:Chi允许多个控制器同时存在,比如让每个控制器负责不同的功能,只要保证控制消息的可串行性,多个控制器就可以同时工作
- 广播/聚合树:避免多个source或者sink的情况下控制器成为瓶颈而引入
- 处理拥塞、死锁:背压等待
- 容错:消息-->依赖底层数据平面;控制器-->checkpoint
4.4 Chi与其他现有模型对比
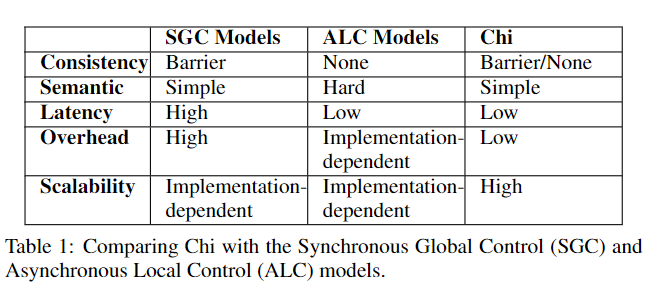
这里主要将Chi与不同流系统模型进行比较:BSP-based与record-at-a-time,SGC与ALC是这两种系统采用的方法
一致性 BSP可以通过屏障达到一致性,Chi也可以实现BSP,而ALC不能满足一致性,Chi在非阻塞消息的情况下与之相同
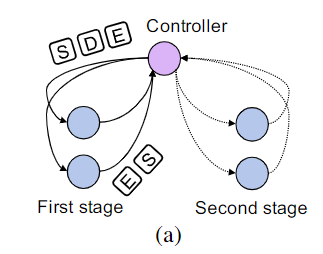
应用实例
持续监视

数据流重配置 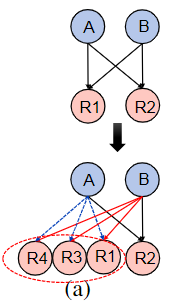
自动参数调优 结合前两个
实现&讨论
分布式运行时
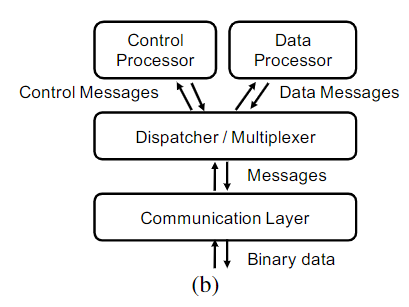
communication layer提供先进先出的精确一次传输管道,并且有背压
message dispatcher/multiplexer根据消息的类型调用相应的处理模块,并将其输出多路复用到通信层
data processor与control processor根据消息执行相应操作
自定义序列化
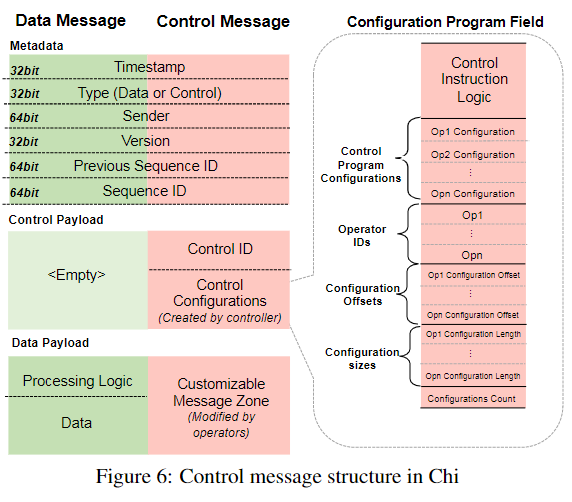
可移植性 如果底层系统不提供 FIFO 一次性消息传递,则移植communication layer,移植message dispatcher/multiplexer并重用data processor
评估
控制平面影响数据平面了吗?
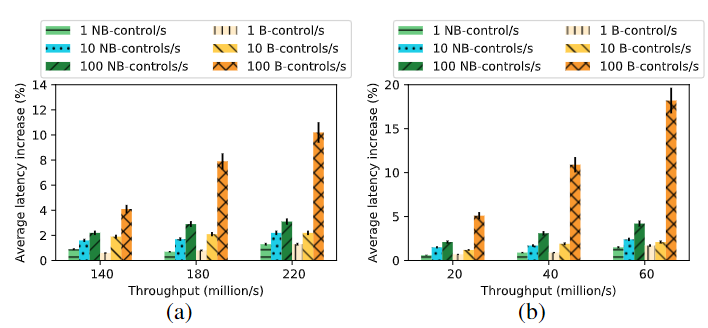
繁忙的数据平面会限制控制平面吗?
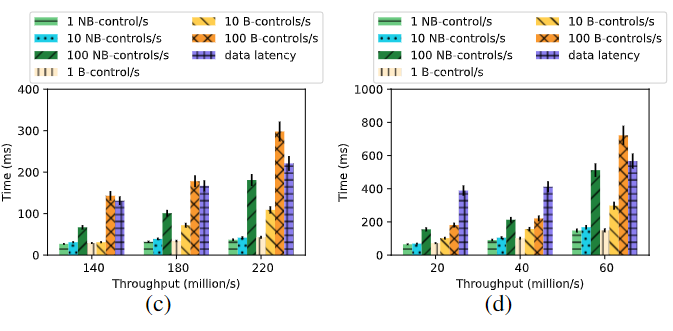
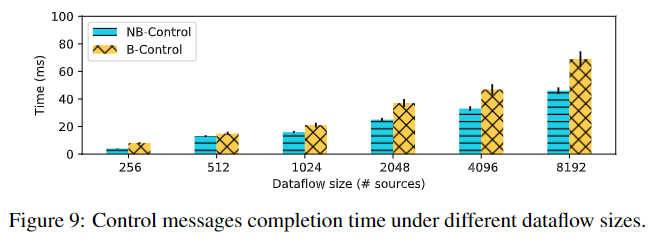
控制平面可扩展吗?对数增加
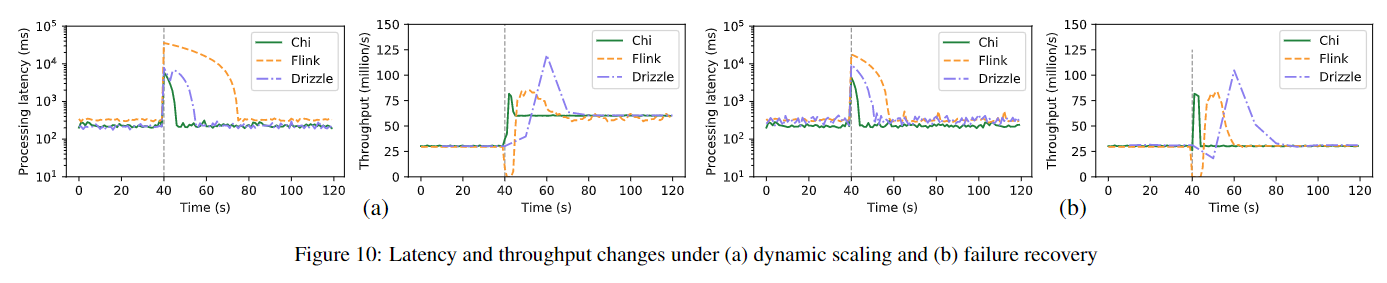
适应性与容错

 浙公网安备 33010602011771号
浙公网安备 33010602011771号