
LargeWorldModels-总结
LargeWorldModels-总结
lwm 原理论文 代码 hgf总链接
链接2:[2402.08268] World Model on Million-Length Video And Language With RingAttention (arxiv.org)
lwm 论文
链接3:LargeWorldModel/LWM (github.com)
代码
链接4:LargeWorldModel (Large World Model) (huggingface.co)
模型
LargeWorldModel/LWM-Chat-1M-Jax · Hugging Face
https://huggingface.co/LargeWorldModel/LWM-Chat-1M-Jax
简洁链接:
1 code git:https://github.com/LargeWorldModel/LWM
2 论文 : https://arxiv.org/abs/2402.08268
3 jax导出来tflite: https://www.tensorflow.org/lite/examples/jax_conversion/overview#convert_to_tflite_model
4 hugging 总链接:https://largeworldmodel.github.io/
一 工程说明-错误信息
LargeWorldModel/LWM (github.com)
0 只在 ubuntu 系统, window不支持。
1 世界模型 使用数据video,text和图片 , 也可以输出视频图片和文字。 完成文字转图片,图片转文字任务
2 PyTorch inference支持 文字生成和 chat。 The vision-language models are available only in Jax, and the language-only models are available in both PyTorch and Jax
3 BPT and RingAttention算法
4 jax用于训练,jax和pytorch支持 文字生成, jax支持文字到视频
---
支持linux
先部署jax,位置:LargeWorldModel/LWM-Chat-1M-Jax · Hugging Face
环境 : 服务器37 conda环境:lwm
目录:/home/arm/disk_arm_8T/xiaoliu/topro/lwmodel/LWM-main
$ conda create -n lwm python=3.10 $ pip install -U "jax[cuda12_pip]==0.4.23" -f https://storage.googleapis.com/jax-releases/jax_cuda_releases.html $ pip install -r requirements.txt
$ pip install torch
模型链接:LargeWorldModel/LWM-Text-Chat-1M · Hugging Face
1 torch模型 load Hugging Face LlamaForCausalLM models
2 $ python scripts/sample_pyt.py
学习视频:【论文速递】GitHub热榜第一:UC伯克利震撼推出“世界大模型”_哔哩哔哩_bilibili
文章概览:1 更长的上下文文本输入。2 ring Attention 被提出 与 flash Attention 联合使用。
flashAttention 机制 Flash attention机制在计算注意力权重时引入了一个可学习的缩放参数,用于调整注意力分布的范围。
flashAttention 增加了

JAX教程
长视频:【搬运】【机翻】从零开始学习用JAX搞机器学习-从菜鸟到高手 #1_哔哩哔哩_bilibili
短视频:Google JAX实现最基本的神经网络(多层感知机)更新了清晰视频_哔哩哔哩_bilibili
4)https://huggingface.co/LargeWorldModel/LWM-Chat-1M-Jax
--------------------------------------------------
部署总结
文章:LWM(LargeWorldModel)大世界模型-可文字可图片可视频-多模态LargeWorld-视频问答成功运行-实现循环问答多次问答_lwm-chat 如何使用-CSDN博客
描述的就是bash run_vision_chat.sh这个脚本
bash scripts/run_vision_chat.sh
-> 已经尝试下载checkpoint 模型,下载完成
-> 但是 Out of memory while trying to allocate 2885681152 bytes.
->
原配置7b 改为3b 都会报
File "/home/liuxiao/anaconda3/envs/lwm/lib/python3.10/site-packages/tux/distributed.py", line 95, in shard_fn
return jax_shard_function(tensor).block_until_ready()
jaxlib.xla_extension.XlaRuntimeError: RESOURCE_EXHAUSTED: Out of memory while trying to allocate 2885681152 bytes.
-> 尝试更换输入 图片,和 MP4
错误详细分析:


I0325 09:10:52.304720 139799252627712 xla_bridge.py:660] Unable to initialize backend 'rocm': NOT_FOUND: Could not find registered platform with name: "rocm". Available platform names are: CUDA I0325 09:10:52.306992 139799252627712 xla_bridge.py:660] Unable to initialize backend 'tpu': INTERNAL: Failed to open libtpu.so: libtpu.so: cannot open shared object file: No such file or directory 2024-03-25 09:14:33.853852: W external/tsl/tsl/framework/bfc_allocator.cc:485] Allocator (GPU_0_bfc) ran out of memory trying to allocate 2.69GiB (rounded to 2885681152)requested by op 2024-03-25 09:14:33.854522: W external/tsl/tsl/framework/bfc_allocator.cc:497] *__***********___________***************************************************________________________ jax.errors.SimplifiedTraceback: For simplicity, JAX has removed its internal frames from the traceback of the following exception. Set JAX_TRACEBACK_FILTERING=off to include these. The above exception was the direct cause of the following exception: Traceback (most recent call last): File "/home/liuxiao/anaconda3/envs/lwm/lib/python3.10/runpy.py", line 196, in _run_module_as_main return _run_code(code, main_globals, None, File "/home/liuxiao/anaconda3/envs/lwm/lib/python3.10/runpy.py", line 86, in _run_code exec(code, run_globals) File "/home/arm/disk_arm_8T/xiaoliu/AI610-SDK-r1p3-00eac0/Out-Of-Box/out-of-box-nn-compiler/user-case-example/lworldmodel/LWM-main/lwm/vision_chat.py", line 254, in <module> run(main) File "/home/liuxiao/anaconda3/envs/lwm/lib/python3.10/site-packages/absl/app.py", line 308, in run _run_main(main, args) File "/home/liuxiao/anaconda3/envs/lwm/lib/python3.10/site-packages/absl/app.py", line 254, in _run_main sys.exit(main(argv)) File "/home/arm/disk_arm_8T/xiaoliu/AI610-SDK-r1p3-00eac0/Out-Of-Box/out-of-box-nn-compiler/user-case-example/lworldmodel/LWM-main/lwm/vision_chat.py", line 249, in main sampler = Sampler() File "/home/arm/disk_arm_8T/xiaoliu/AI610-SDK-r1p3-00eac0/Out-Of-Box/out-of-box-nn-compiler/user-case-example/lworldmodel/LWM-main/lwm/vision_chat.py", line 51, in __init__ self._load_model() File "/home/arm/disk_arm_8T/xiaoliu/AI610-SDK-r1p3-00eac0/Out-Of-Box/out-of-box-nn-compiler/user-case-example/lworldmodel/LWM-main/lwm/vision_chat.py", line 199, in _load_model self.params = tree_apply(shard_fns, self.params) File "/home/liuxiao/anaconda3/envs/lwm/lib/python3.10/site-packages/tux/jax_utils.py", line 148, in tree_apply return jax.tree_util.tree_map(lambda fn, x: fn(x), fns, tree) File "/home/liuxiao/anaconda3/envs/lwm/lib/python3.10/site-packages/jax/_src/tree_util.py", line 244, in tree_map return treedef.unflatten(f(*xs) for xs in zip(*all_leaves)) File "/home/liuxiao/anaconda3/envs/lwm/lib/python3.10/site-packages/jax/_src/tree_util.py", line 244, in <genexpr> return treedef.unflatten(f(*xs) for xs in zip(*all_leaves)) File "/home/liuxiao/anaconda3/envs/lwm/lib/python3.10/site-packages/tux/jax_utils.py", line 148, in <lambda> return jax.tree_util.tree_map(lambda fn, x: fn(x), fns, tree) File "/home/liuxiao/anaconda3/envs/lwm/lib/python3.10/site-packages/tux/distributed.py", line 95, in shard_fn return jax_shard_function(tensor).block_until_ready() jaxlib.xla_extension.XlaRuntimeError: RESOURCE_EXHAUSTED: Out of memory while trying to allocate 2885681152 bytes.
-> 执行命令 设置jax 使用cpu
export JAX_PLATFORM_NAME=cpu
-> 报错信息
100%|██████████| 1/1 [00:09<00:00, 9.48s/it] jax.errors.SimplifiedTraceback: For simplicity, JAX has removed its internal frames from the traceback of the following exception. Set JAX_TRACEBACK_FILTERING=off to include these.
-> 安装依赖
$ conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia
$ pip install -U "jax[cuda12_pip]==0.4.23"
$ pip install -r requirements.txt
修改脚本
1 删除 # --mesh_dim='!1,1,-1,1' \
2 修改 --dtype='fp32' \ dtype='fp16' 这样就不会出现内存问题
#! /bin/bash export SCRIPT_DIR="$( cd -- "$( dirname -- "${BASH_SOURCE[0]}" )" &> /dev/null && pwd )" export PROJECT_DIR="$( cd -- "$( dirname -- "$SCRIPT_DIR" )" &> /dev/null && pwd )" cd $PROJECT_DIR export PYTHONPATH="$PYTHONPATH:$PROJECT_DIR" export llama_tokenizer_path="/home/arm/disk_arm_8T/xiaoliu/AI610-SDK-r1p3-00eac0/Out-Of-Box/out-of-box-nn-compiler/user-case-example/lworldmodel/daownmodel/lw/tokenizer.model" export vqgan_checkpoint="/home/arm/disk_arm_8T/xiaoliu/AI610-SDK-r1p3-00eac0/Out-Of-Box/out-of-box-nn-compiler/user-case-example/lworldmodel/daownmodel/lw/vqgan" export lwm_checkpoint="/home/arm/disk_arm_8T/xiaoliu/AI610-SDK-r1p3-00eac0/Out-Of-Box/out-of-box-nn-compiler/user-case-example/lworldmodel/daownmodel/lw/params" #export input_file="/home/arm/disk_arm_8T/xiaoliu/AI610-SDK-r1p3-00eac0/Out-Of-Box/out-of-box-nn-compiler/user-case-example/lworldmodel/LWM-main/img/scenery.mp4" export input_file="/home/arm/disk_arm_8T/xiaoliu/AI610-SDK-r1p3-00eac0/Out-Of-Box/out-of-box-nn-compiler/user-case-example/lworldmodel/LWM-main/img/tankpacks.jpg" # Relevant params # --input_file: A given image file (png or jpg) or video file (any video format support by decord, e.g. mp4) # --max_n_frames: Maximum number of frames to process. If the video is longer than max_n_frames frames, it uniformly samples max_n_frames frames from the video python3 -u -m lwm.vision_chat \ --prompt="What is the video about?" \ --input_file="$input_file" \ --vqgan_checkpoint="$vqgan_checkpoint" \ --dtype='fp16' \ --load_llama_config='7b' \ --max_n_frames=8 \ --update_llama_config="dict(sample_mode='text',theta=50000000,max_sequence_length=131072,scan_attention=False,scan_query_chunk_size=128,scan_key_chunk_size=128,remat_attention='',scan_mlp=False,scan_mlp_chunk_size=2048,remat_mlp='',remat_block='',scan_layers=True)" \ --load_checkpoint="params::$lwm_checkpoint" \ --tokenizer.vocab_file="$llama_tokenizer_path" \ 2>&1 | tee ~/output.log read
-> 推理结果
视频位置:C:\Users\xialiu05\Documents\公司任务\ecosys\第一种任务-模型部署\LWM\LWM-main\video
Question: What is the video about?
Answer: The video is about a man walking on a suspension bridge and admiring the beautiful scenery.
图像:/home/arm/disk_arm_8T/xiaoliu/AI610-SDK-r1p3-00eac0/Out-Of-Box/out-of-box-nn-compiler/user-case-example/lworldmodel/LWM-main/img/tankpacks.jpg
Question: What is the video about?
Answer: The video showcases a group of soldiers standing on the backs of four armored vehicles, ready to engage in a military exercise. The vehicles are parked on a field, and the soldiers are positioned on top of them, indicating their readiness for action. The scene is set against a backdrop of a clear blue sky and a few clouds. The image conveys a sense of readiness and readiness for action, with the soldiers and the armored vehicles as the focal points.
二 模型结构
训练过程
论文 3.2 Training Steps
progressively 逐步的
1 init model, llama2 model。
2 训练方法 Progressive Training
论文 Figure 4
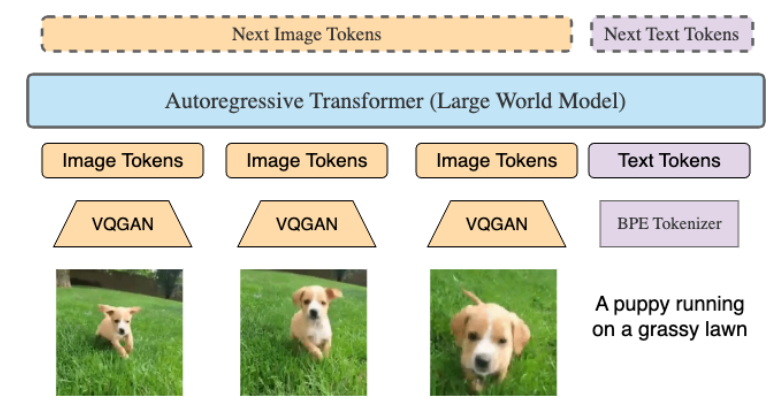
LWM是输入数百万长度token序列的自回归transformer。
视频中的每一帧被VQGAN标记化为256个token。这些tokens 与 text tokens 合在一起,输入到transformer中自回归的推理下一个token。 special delimiters <vision> and </vision>. 使用特殊分隔符来包住 视频和图片的token。
三块结构 init llama2 -> ring attention 加载哪里了? -> 额外提问 VQGAN 是否只在训练中使用???
ring attention是基于预训练模型的 微调模型
论文 3 Stage I: Learning Long-Context Language Models
positional encoding和 ring attention 一起作用。 论文中也展示了如何构建模型生成的QA数据,以实现长序列对话。
论文 P5
Scalable Training on Long Documents. Training on long documents becomes prohibitively expensive due to memory constraints imposed by the quadratic complexity of computing the attention weights. 基于attention的计算,在内存中过于占用资源。
In order to address these computational constraints, 为了解决计算的约束。我们使用ringattention来实现,(序列是并行的), 采用分块计算 -> 理论上扩展了无限的上下文,只是收到可用设备的限制。 (有多少设备就可以更多的分块,加速计算)
We further fuse RingAttention with FlashAttention using Pallas to optimize performance compared with using XLA compiler.
当每个device分配足够的tokens,RingAttention期间的通信成本与计算完全重叠,并且不增加任何额外的开销。
-> RingAttention的主要特点是将自注意力机制中的注意力矩阵(Attention Matrix)设计为环形结构,即每个位置只与其周围一定范围内的位置进行交互,形成一个环形的连接方式。这种设计可以减少计算复杂度,同时保持模型的局部和全局信息交互能力。
参考文档: 伯克利 | 提出Ring Attention,Transformer分块,最高支持100M上下文! - 知乎 (zhihu.com)
-> 分组查询注意力 (GQA) llama2采用这种注意力机制。参考:【NLP】理解 Llama2:KV 缓存、分组查询注意力、旋转嵌入等_llama2中的注意力机制 分组注意力-CSDN博客 -> llama2 中的各种创新结构。
-> 结合了Flash Attention和Ring Attention的结构。
小结: 因为序列过长 -> 为了放开计算消耗的限制 ,采用ring Attention结构。
四 转onnx
查询LargeWorldModel onnx 未见结果。
查到了量化模型 https://huggingface.co/MaziyarPanahi/LWM-Text-256K-GGUF
方案1 :推理代码为jax 代码 -> jax-> Trax -> onnx
JAX的模型转换为Trax模型 -> onnx模型 -> 生成aipu -> 部署
方案2: 基于github中的 issue 查到完全pytorch代码。
目前暂未查到
目标: 来自zongqiao总
最好是绿框的,如果比较难弄的话,可以先弄红框的(+比较分析下两者的模型结构差异,预估下绿框的部署会遇到哪些问题)
1 ) 先 jax 2 ) 如果问题,列出来记录 3)再弄红框 -> 4)对比两种模型结构

4.2 jax框架转onnx代码
1) jax 保存模型 其本质是numpy
可以-> numpy
可以保存为.pkl 用pickle
可以用flax保存为序列,本质还是没有结构保存在里面。参考路径:flax 02 优化器,模型保存 - hoNoSayaka - 博客园 (cnblogs.com)
2) jax -?> TENSORFLOW 或tflite 也不太容易 -> tf的源码模型
那么 lwm源码中的模型使用什么来写的呢?
4.3 代码走读
转化方案:
方案1 调用tensorflow的接口,可以将jax 转为 tflite。尝试基于jax编写小模型,可以转为tflite。
https://www.tensorflow.org/lite/examples/jax_conversion/overview#convert_to_tflite_model
方案2
1) 在jax外包一层tensorflow,然后save model。(自定义一个模型可以save)-> 验证使用tf2onnx是否可以转换
2)外包一层torch,是不可以的。
图1 :Jax包装一层tensorflow代码 -> 可以保存.pb文件
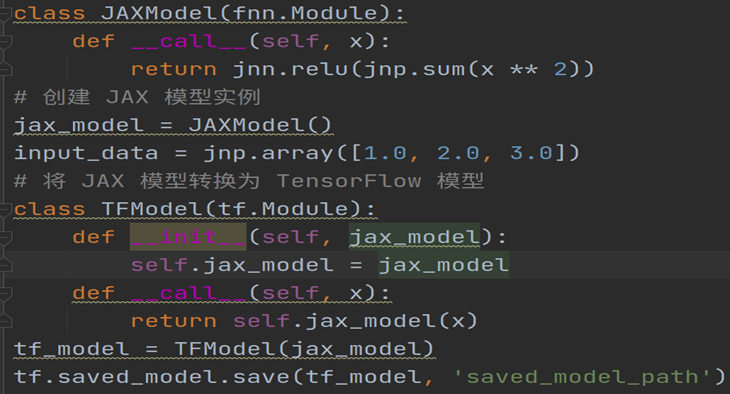
方案3:
https://github.com/google/jax/blob/main/jax/experimental/jax2tf/examples/tflite/mnist/mnist.py
先转tf在转tflite
五 jax 教程:
官方文档:https://jax.readthedocs.io/en/latest/jax.sharding.html
1 定义:代替numpy。 jax可以再GPU NPU TPU执行, 但是numpy只在cpu。
jax 还有封装好的深度学习模块, 如CNN,等
在JAX中,自动微分是指利用计算图和反向传播算法来计算函数的梯度。JAX是一个用于数值计算和机器学习的库,它提供了一种高效的方式来计算函数的梯度,这在深度学习和优化问题中非常有用。
2 基本语法:from jax.experimental.pjit import pjit, pjit函数是用于并行化JAX程序的函数。pjit代表"parallel JIT",它允许用户将JAX程序中的某些部分并行化,从而加速程序的执行。
b. jit :just in time compliance 即时编译, jit函数是JAX中的一个重要函数,用于对Python函数进行即时编译,以提高函数的执行效率。
c. from jax.sharding import PartitionSpec as PS
PartitionSpec类通常用于在JAX中进行分布式计算时,对数据进行合理的分片和分配。
参考连接1:
jax ->只支持纯函数 -> 动态编译加速
参考链接1:Google JAX实现最基本的神经网络(多层感知机)更新了清晰视频_哔哩哔哩_bilibili
grad函数
from jax import grad def fn(x): return x ** 2 print(fn(2.0)) def get_grad(x): grad_func = grad(fn) return grad_func(x) print(get_grad(3.0))
5.2 保存model,load model
搜索:jax.numpy.load — JAX documentation
找一个框架:satojkovic/vit-jax-flax: Vision Transformer from scratch (JAX/Flax). (github.com)
本地位置:C:\Users\xialiu05\Documents\公司任务\ecosys\第一种任务-模型部署\LWM\vit-jax-flax-main
实现save
视频连接:快速掌握jax!详细讲解在flax中实现线性回归_哔哩哔哩_bilibili
依据这个工程来保存模型pkl 然后再加载
import jax from flax import linen as nn import jax.random as rdm seed = 0 key = rdm.PRNGKey(seed) k1, k2 = rdm.split(key) print(key, k1, k2) x = rdm.normal(k1, (3,6)) print("x shape === ", x.shape) model = nn.Dense(features=1) # model init parameters params = model.init(k2, x) # params IS FrozenDict print(params) # params all data * 3. # IF you want to change data in node,you use the tree_util.tree_map. # x1 = jax.tree_util.tree_map(lambda x: x*3, params) # print(x1) # mse import jax.numpy as jnp def mse(params, x, y): # params enter model ,and model predicts. pred_y = model.apply(params, x) out = ((pred_y - y) ** 2).mean() return out # grad loss_grad_fn = jax.value_and_grad(mse) # loss, grads = loss_grad_fn(params, x, 2*x+3) # print(grads) lr = 0.001 def update_params(params, lr, grads): jax.tree_util.tree_map(lambda p, g: p - lr*g, params, grads) return params # print(update_params(params, lr, grads)) epochs = 101 for i in range(epochs): loss, grads = loss_grad_fn(params, x, 2 * x + 3) params = update_params(params, lr, grads) if i % 10 == 0: print("Step%s loss = %s"%(i, loss)) import optax opt = optax.adam(learning_rate=lr) optstate = opt.init(params) epochs = 101 for i in range(epochs): loss, grads = loss_grad_fn(params, x, 2 * x + 3) updates, optstate = opt.update(grads, optstate, ) params = optax.apply_updates(params, updates) if i % 10 == 0: print("Step%s loss = %s" % (i, loss)) print(params)
六 差异报告
1 t-t :llama2+ringATT
2 video-text:llama2+ringATT+VQGAN
七 工程部署详细说明-来自第一章节(部署总结)
7.1 部署总结
LWM模型部署最简使用说明 - lexn - 博客园 (cnblogs.com)
7.2 jax转tflite方法总结
进入调试模式-以了解怎么转为tflite
pycharm 设置conda环境 -> 启动terminal -> 打断点
工程位置:/home/arm/disk_arm_8T/xiaoliu/AI610-SDK-r1p3-00eac0/Out-Of-Box/out-of-box-nn-compiler/user-case-example/lworldmodel/LWM-main
环境: conda lwm
服务器25
安装指导:
1 $ conda create -n lwm python=3.10
2 $ pip install -U "jax[cuda12_pip]==0.4.23" -f https://storage.googleapis.com/jax-releases/jax_cuda_releases.html
问题:
1 (FLAGS.vqgan_checkpoint
以及model checkpoint 等都没模型路径
1前提条件配置
根据文档,fp32可能过大-> 配置为fp16
两处修改:
1.1删除mesh
$ vim run_vision_chat.sh
1.2 修改模型数据类型
fp32可能过大-> 配置为fp16
2操作步骤总结
2.1进入工程
$ cd /home/arm/disk_arm_8T/xiaoliu/AI610-SDK-r1p3-00eac0/Out-Of-Box/out-of-box-nn-compiler/user-case-example/lworldmodel/LWM-main
2.2 启动环境
$ conda activate lwm
2.3 确定使用设备
当在25服务器时,(代码默认使用GPU),25服务器GPU12G,不够用, 会报错 out of内存。 -> 改用CPU
$-> 执行命令设置jax 使用cpu
export JAX_PLATFORM_NAME=cpu
2.4 尝试跑
大语言模型, VQGAN 模型 输入数据都在里面配置
$ bash scripts/run_vision_chat.sh
2.5 调用的py
$ python3 -u -m lwm.vision_chat

 浙公网安备 33010602011771号
浙公网安备 33010602011771号