
zookeeper 分布式锁的实现及原理
保证线程安全
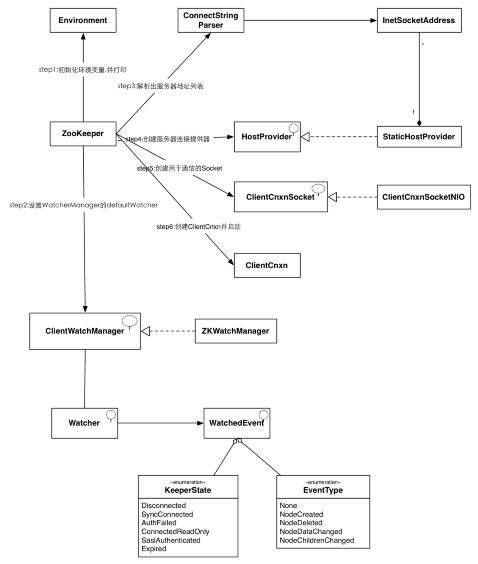
ZooKeeper初始化示意图
1 public static void main(String[] args) { 2 CuratorFramework curatorFramework = CuratorFrameworkFactory.builder() 3 // 客户端连接任意zk 节点都行,也可以指定集群 4 .connectString(CommonConstants.CONNECT_URL) 5 .sessionTimeoutMs(5000) 6 // 重试策略 7 .retryPolicy(new ExponentialBackoffRetry(1000, 3)) 8 .connectionTimeoutMs(4000).build(); 9 // 表示启动 10 curatorFramework.start(); 11 /** 12 * locks表示命名空间 13 * 14 * 锁的获取逻辑是放在zookeeper上 15 * 当前锁是跨进程可见 16 */ 17 InterProcessMutex lock = new InterProcessMutex(curatorFramework, "/locks"); 18 for (int i = 0; i < 10; i++) { 19 new Thread(()->{ 20 System.out.println(Thread.currentThread().getName() + "->" + "尝试抢占锁"); 21 try { 22 // 抢占锁,没有抢占到,则阻塞 23 lock.acquire(); 24 System.out.println(Thread.currentThread().getName() + "->" + "获取锁成功"); 25 } catch (Exception e) { 26 e.printStackTrace(); 27 } 28 // 释放锁 29 try { 30 Thread.sleep(4000); 31 lock.release(); 32 System.out.println(Thread.currentThread().getName() + "->" + "释放锁成功"); 33 } catch (Exception e) { 34 e.printStackTrace(); 35 } 36 },"t-"+i).start(); 37 } 38 39 }
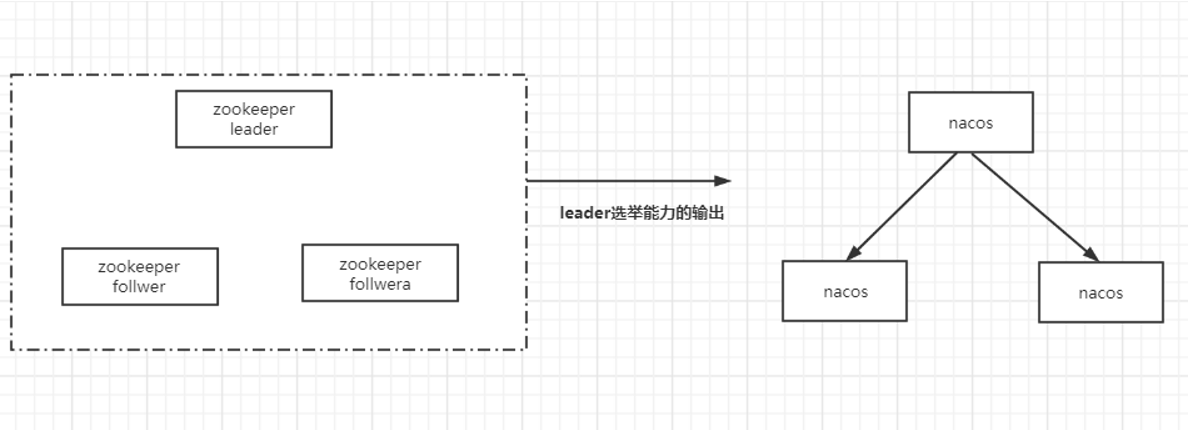
zookeeper leader 选举
kafka -> master/slave | kafka+zookeeper
-
-
dubbo + zookeeper 配置中心,元数据管理
-
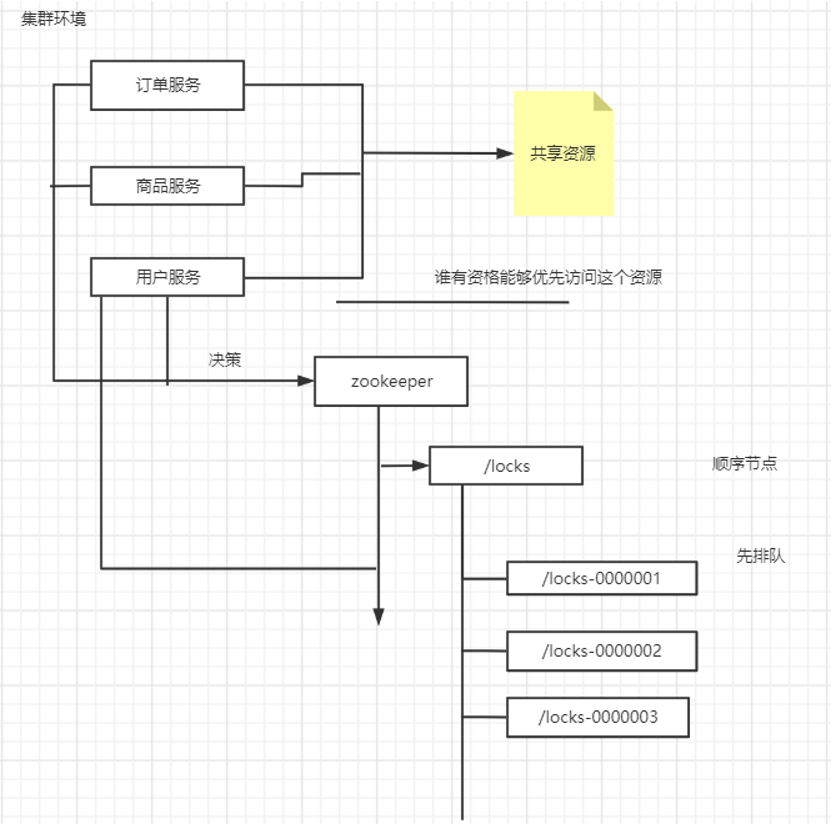
实现分布式锁(Curator)
-
leader 选举(定时任务的互斥执行)
-
leader latch
-
-
zookeeper实际应用以及原理分析
Zookeeper的基本原理
数据模型
-
弱一致性模型
-
2 PC协议(原子性)
-
过半提交
ZABZAB(zookeeper atomic Broadcast)
-
-
数据同步
-
崩溃恢复 (looking)
-
原子广播
-
消息广播
-
Zxid(64)
-
observer(不参与投票和ack,只和leader保持数据 同步)
崩溃恢复
-
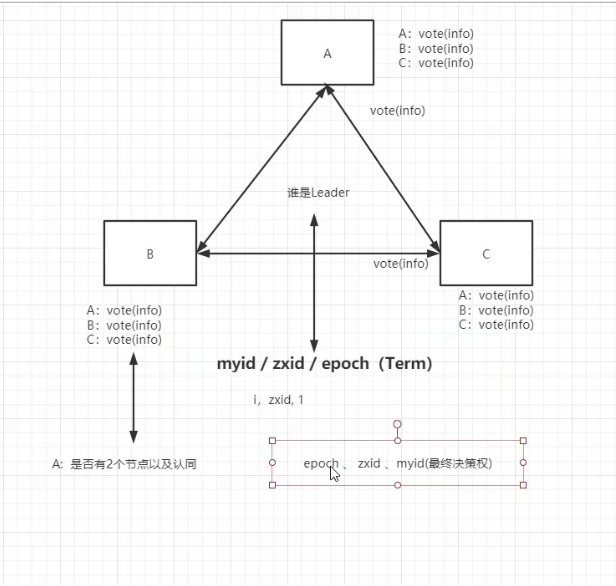
选举出新leader(选举谁作为leader)
-
Zxid(*)
-
已经被处理的消息不能丢失
-
被丢弃的消息不能再次出现
如何实现?(leader)
-
zxid最大(和leader选举有关系?)
-
Epoch ->term(raft).zxid()
Zxid(事务id)
-
64位
-
高32位是epoch、低32位代表递增是不编号


 浙公网安备 33010602011771号
浙公网安备 33010602011771号