哈撒给,英雄联盟全皮肤下载器来了
这是通过博主写的英雄联盟下载器下载的部分的英雄皮肤,可以看一下效果。每个英雄的皮肤的会自动根据英雄名称创建相应的文件夹存放。
完整源代码请阅读到文末获取...
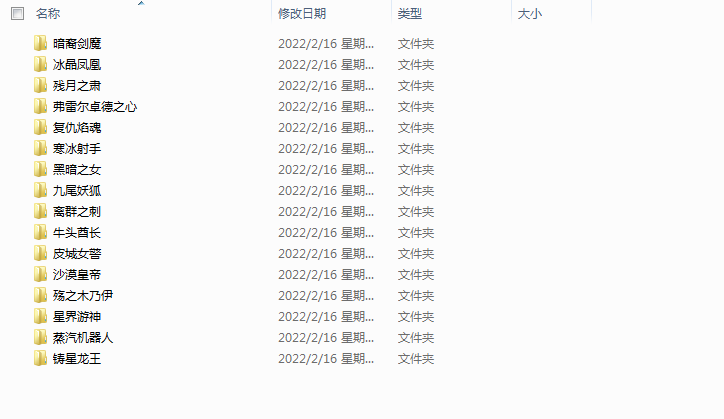


实现思路比较简单,同样是通过PyQt5来编写下载页面。最后通过request模块来进行皮肤的下载部分编写。演示一下操作过程是下面这样的,选择好皮肤的存储路径。然后直接点击开始下载就行了,并且可以在文本浏览器中查看下载进度信息。
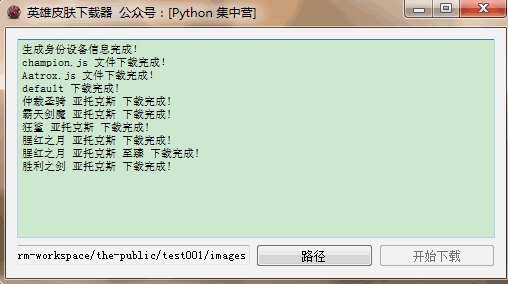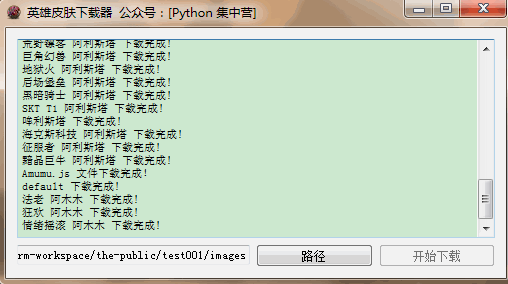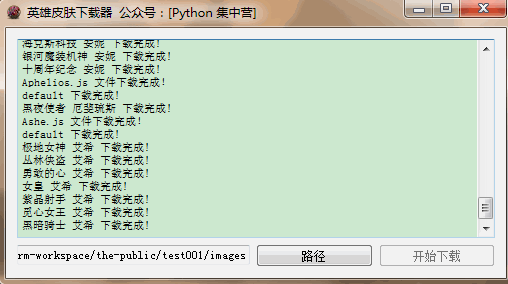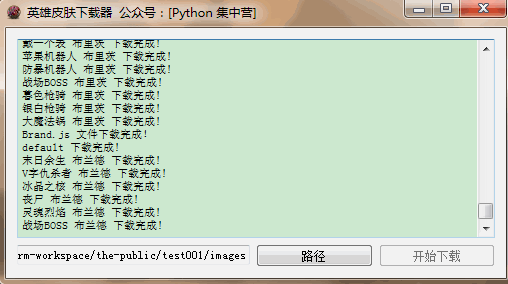
接下来,介绍一下代码块的主要是实现部分。首先,介绍一下整个代码块都使用了哪些第三方模块。
# 英雄联盟皮肤下载相关依赖模块
import requests # 网络请求库
import re # 正则表达式匹配库
import json # JSON格式转换库
import os # 应用操作库
import time # 时间模块
from random import random # 随机数模块
from fake_useragent import UserAgent # user_agent 生成库
import logging # 日志模块
import sys # 系统操作
# pyqt5的模块引用这里就不介绍了,最近一直在用。
from PyQt5.QtGui import *
from PyQt5.QtWidgets import *
from PyQt5.QtCore import *
UI界面的设计过程代码块以及信号与槽函数的应用过程。
def init_ui(self):
self.setWindowTitle('英雄皮肤下载器 公众号:[Python 集中营]')
self.setWindowIcon(QIcon('lol.ico'))
self.resize(500,250)
vbox = QVBoxLayout()
self.save_dir = QLineEdit()
self.save_dir.setReadOnly(True)
self.save_btn = QPushButton()
self.save_btn.setText('路径')
self.save_btn.clicked.connect(self.save_btn_click)
self.thread_ = DownLoadThread(self)
self.thread_.trigger.connect(self.update_log)
self.start_btn = QPushButton()
self.start_btn.setText('开始下载')
self.start_btn.clicked.connect(self.start_btn_click)
grid = QGridLayout()
grid.addWidget(self.save_dir, 0, 0, 1, 2)
grid.addWidget(self.save_btn, 0, 2, 1, 1)
grid.addWidget(self.start_btn, 0, 3, 1, 1)
self.result_brower = QTextBrowser()
self.result_brower.setFont(QFont('宋体', 8))
self.result_brower.setReadOnly(True)
self.result_brower.setPlaceholderText('英雄皮肤批量下载进度显示区域...')
self.result_brower.ensureCursorVisible()
vbox.addWidget(self.result_brower)
vbox.addLayout(grid)
self.setLayout(vbox)
def start_btn_click(self):
self.start_btn.setEnabled(False)
self.thread_.start()
def update_log(self, text):
cursor = self.result_brower.textCursor()
cursor.movePosition(QTextCursor.End)
self.result_brower.append(text)
self.result_brower.setTextCursor(cursor)
self.result_brower.ensureCursorVisible()
def save_btn_click(self):
directory = QFileDialog.getExistingDirectory(self, "选取文件夹", self.cwd)
self.save_dir.setText(directory)
UI界面的设计代码,遵循的是和其他PyQt5一样的设计范式。按照这样的范式写出来的UI代码块个人觉得看起来也比较美观。
为了防止下载过程比较慢的情况下会导致UI界面的主线程直接挂掉,所以在编写下载业务的逻辑时是需要单独使用QThread子线程的方式来编写的。这样可以使得业务逻辑和主页面逻辑分离,就不会产生挂掉的情况发生了。
class DownLoadThread(QThread):
trigger = pyqtSignal(str)
def __init__(self, parent=None):
super(DownLoadThread, self).__init__(parent)
# 初始化日志对象
self.logger = logging.getLogger('英雄联盟皮肤')
logging.basicConfig()
self.logger.setLevel(logging.DEBUG)
self.parent = parent
self.working = True
def __del__(self):
self.working = False
self.wait()
def run(self):
'''
英雄联盟皮肤下载函数
:return:
'''
while self.working == True:
# 构造useragent身份设备信息
headers = {
"User-Agent": str(UserAgent().random),
}
self.logger.info('生成身份设备信息完成')
self.trigger.emit('生成身份设备信息完成!')
# 在LOL的官网经过分析champion.js中包含了我们要用到的英雄ID编号,因此,将这个JS文件下载下来
champion_js_url = "https://lol.qq.com/biz/hero/champion.js"
# 发送http请求、请求地址为这个JS文件的地址。就会将其下载下来了。
response = requests.get(url=champion_js_url, headers=headers)
self.logger.info('champion.js 文件下载完成')
self.trigger.emit('champion.js 文件下载完成!')
# 获取下载的文本信息
text = response.text
self.logger.info('champion.js 文本信息:' + text)
# 匹配champion对象对应的JSON数据,该JSON数据的第0个位置是包含英雄ID编号的JSON数据
hero_json = re.findall(r'champion=(.*?);', text, re.S)[0]
# 将JSON数据转换为dict字典
hero_dict = json.loads(hero_json)
self.logger.info('英雄ID字典信息:' + str(hero_dict))
# 逐个英雄信息遍历
for hero_data in hero_dict["data"].items():
# 获取英雄详细信息的JS文件
hero_js_url = "http://lol.qq.com/biz/hero/{}.js"
# 发送请求下载该JS文件、hero_data[0]取第0位就是英雄ID
response = requests.get(url=hero_js_url.format(hero_data[0]), headers=headers)
# 获取下载文本
text = response.text
self.logger.info(hero_data[0] + '.js 文本信息:' + text)
self.trigger.emit(hero_data[0] + '.js 文件下载完成!')
skins_dict = json.loads(re.findall("{}=(.*?);".format(hero_data[0]), text, re.S)[0])
self.logger.info('当前英雄皮肤字典:' + str(skins_dict))
# 从字典 skins_dict 获取皮肤列表
skins_list = skins_dict["data"]["skins"]
# 获取英雄名称
hero_name = hero_data[1]["name"]
# 在当前目录下面创建images文件夹、以英雄名称作为文件夹名称
os.makedirs(r"./images/{}".format(hero_name), exist_ok=True)
for skin_info in skins_list:
# 初始化皮肤图片地址
skin_pic_url = "https://ossweb-img.qq.com/images/lol/web201310/skin/big{}.jpg"
# 发送下载请求
reponse = requests.get(url=skin_pic_url.format(skin_info["id"]), headers=headers)
try:
self.logger.info('保存路径' + self.parent.save_dir.text().strip())
# 保存皮肤
with open(r"" + self.parent.save_dir.text().strip() + "/{}/{}.jpg".format(hero_name,
skin_info["name"]),
"wb") as f:
f.write(reponse.content)
self.logger.info("{} 下载完成!".format(skin_info["name"]))
self.trigger.emit("{} 下载完成!".format(skin_info["name"]))
except:
self.logger.error(skin_info["name"] + ',下载出现异常.跳过执行下一个!')
self.trigger.emit(skin_info["name"] + ',下载出现异常.跳过执行下一个!')
self.sleep(round(random(), 5))
由于下载这一块的业务比较多,为了方便大家查看。基本上主要的代码块我都写上了注释,需要的小伙伴可以根据自己的需求进行改造。
公众号内回复"英雄联盟皮肤下载器"获取完整源代码...

我是 [Python 集中营]、很高兴您看到了最后, 我是一个专注于 Python 知识分享的公众号,希望可以得到您的关注~
【往期精彩】
PyQt5的敏感词检测工具制作,运营者的福音...
手绘图片生成器:以雪容融为例一键生成...
刚刚出炉的冬奥会吉祥物:冰墩墩,附源码...
最优美的表格查看插件:tabulate
抖音同款课堂点名系统,PyQt5写起来很简单...
欢迎关注作者公众号【Python 集中营】,专注于后端编程,每天更新技术干货,不定时分享各类资料!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号