一:关于list,set和map的区别
list:list是collection集合的接口,它的特点是可以存储重复的元素,可以有多个null,按照元素插入的顺序存储,主要的实现类有arraylist和linkedlist,arraylist主要用于按照索引来查找数据,而linkedlist则适用于在list中增加,删除或修改数据。
set: set也是collection集合的接口。它的特点是不可以存储重复的元素,最多只能存一个null值,并且存储元素的顺序是不确定的。主要的实现类有hashset ,linkedhashset和treeset。treeset实现了sortedset的接口所以是个有序排序的容器。
map:根据键-值对来存储的接口。值可能相同但键是唯一的。
二:vector,arraylist和linkedlist的区别
1.vector,arraylist以数组的形式存储在内存中,而linkedlist以链表的形式存储在内存中。
2.Vector是线程同步的,ArrayList和linkedlist不是线程同步的。
三:collection和collections的区别
collection:是一个集合接口。它提供了对集合对象进行基本操作的通用接口方法。collection在java库中有很多具体的实现。collection接口的最大意义是为各种具体的集合提供了最大化的统一操作方式,其直接继承接口有list和set。
collections:是一个针对集合类的包装类。它提供了一系列的静态方法实现对各个集合类的搜索,排序和线程安全化等操作。
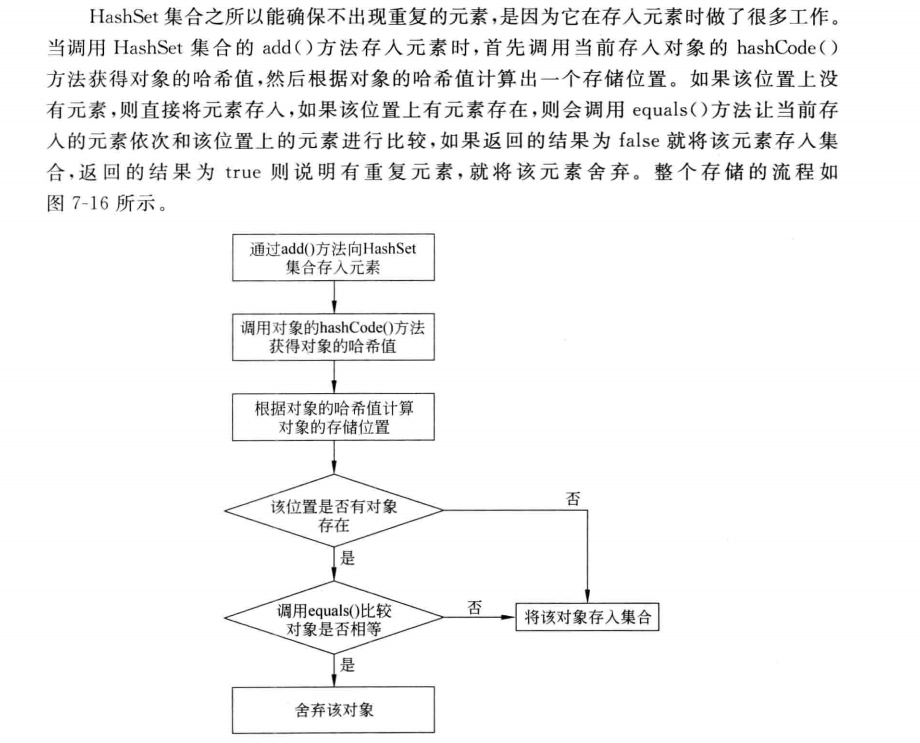
四:hashset添加数据过程
![]()
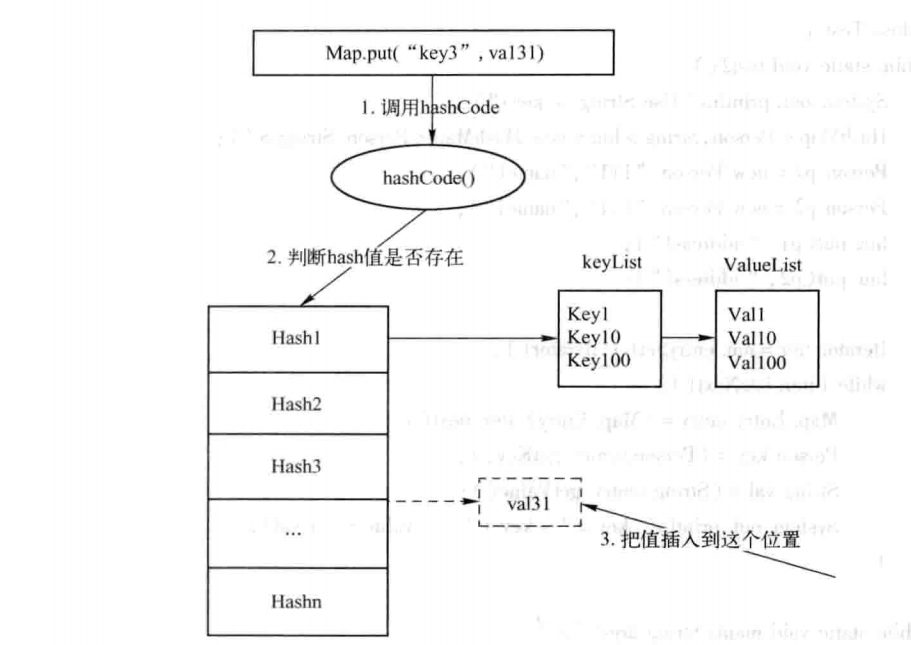
五:hashmap添加键值对<key,value>过程
![]()
![]()
六:泛型的作用
泛型是java JDK1.5后出现的。泛型赋予了类型参数式多态的能力
泛型的第一个好处是编译时的严格类型检查。有效的避免了运行期的ClassCastException,提高了程序的安全性和健壮性。
这是集合框架最重要的特点。此外,泛型消除了绝大多数的类型转换。如果没有泛型,当你使用集合框架时,你不得不进行类型转换。另外 泛型简化了代码,应用泛型的程序提高程序的可读性,更利于团队的合作开发。
七:最新的jdk版本
JDK 1.8
特性:
引入Lambda 表达式;
管道和流;
新的日期和时间 API;
默认的方法;
类型注解;
Nashorn javascript引擎;
并行累加器;
并行操作
内存错误移除
八:数据库优化方法:
常见的数据库优化方法:索引(数据库),缓存,分表,分库,sql优化。
索引:创建索引一般有以下两个目的:维护被索引列的唯一性和提供快速访问表中数据的策略。95% 的数据库能 问题都可以采用索引技术得到解决。索引有助于提高检索性能,但过多或不当的索引也会导致系统低 效。因为用户在表中每加进一个索引,数据库就要做更多的工作。过多的索引甚至会导致索引碎片。
缓存:hibernate,spring3有缓存模块
分表:针对每个时间周期产生大量的数据,可以考虑采用一定的策略将数据存到多个数据表中。
分库:就是将系统按照模块相关的特征分布到不同的数据中,以提高系统整体负载能力。
sql优化:
1.in 和 not in 也要慎用,因为IN会使系统无法使用索引,而只能直接搜索表中的数据。如:
select id from t where num in(1,2,3)对于连续的数值,能用 between 就不要用 in 了:
select id from t where num between 1 and 3
2.当判断真假是,如果带and 或者 or :
(当存在 “where 条件1 and 条件2” 时,数据库先执行右边的语句)
and尽量把假的放到右边(一个为假就为假) Or尽量把为真的放到右边(一个为真就为真)
3.应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。 如:
SELECT * FROM T1 WHERE F1/2=100
应改为:
SELECT * FROM T1 WHERE F1=100*2
SELECT * FROM RECORD WHERE SUBSTRING(CARD_NO,1,4)=’5378’
应改为:
SELECT * FROM RECORD WHERE CARD_NO LIKE ‘5378%’
SELECT member_number, first_name, last_name FROM members
WHERE DATEDIFF(yy,datofbirth,GETDATE()) > 21
应改为:
SELECT member_number, first_name, last_name FROM members
WHERE dateofbirth < DATEADD(yy,-21,GETDATE())
即:任何对列的操作都将导致表扫描,它包括数据库函数、计算表达式等等,查询时 要尽可能将操作移至等号右边。
4.很多时候用 exists是一个好的选择:
elect num from a where num in(select num from b)
用下面的语句替换:
select num from a where exists(select 1 from b where num=a.num)
SELECT SUM(T1.C1)FROM T1 WHERE(
(SELECT COUNT(*)FROM T2 WHERE T2.C2=T1.C2>0)
SELECT SUM(T1.C1) FROM T1WHERE EXISTS(
SELECT * FROM T2 WHERE T2.C2=T1.C2)
两者产生相同的结果,但是后者的效率显然要高于前者。因为后者不会产生大量锁定 的表扫描或是索引扫描。
如果你想校验表里是否存在某条纪录,不要用count(*)那样效率很低,而且浪费服务 器资源。可以用EXISTS代替。如:
IF (SELECT COUNT(*) FROM table_name WHERE column_name = 'xxx')
可以写成:
IF EXISTS (SELECT * FROM table_name WHERE column_name = 'xxx')
5.充分利用连接条件,在某种情况下,两个表之间可能不只一个的连接条件,这时在 WHERE 子句中将 连接条件完整的写上,有可能大大提高查询速度。
例:
SELECT SUM(A.AMOUNT) FROM ACCOUNT A,CARD B WHERE A.CARD_NO = B.CARD_NO
SELECT SUM(A.AMOUNT) FROM ACCOUNT A,CARD B WHERE A.CARD_NO = B.CARD_NO AND A.ACCOUNT_NO=B.ACCOUNT_NO
第二句将比第一句执行快得多。
6.使用视图加速查询
把表的一个子集进行排序并创建视图,有时能加速查询。它有助于避免多重排序 操 作,而且在其他方面还能简化优化器的工作。例如:
SELECT cust.name,rcvbles.balance,……other columns
FROM cust,rcvbles
WHERE cust.customer_id = rcvlbes.customer_id
AND rcvblls.balance>0
AND cust.postcode>“98000”
ORDER BY cust.name
如果这个查询要被执行多次而不止一次,可以把所有未付款的客户找出来放在一个视 图中,并按客户的名字进行排序:
CREATE VIEW DBO.V_CUST_RCVLBES
AS
SELECT cust.name,rcvbles.balance,……other columns
FROM cust,rcvbles
WHERE cust.customer_id = rcvlbes.customer_id
AND rcvblls.balance>0
ORDER BY cust.name
然后以下面的方式在视图中查询:
SELECT * FROM V_CUST_RCVLBES
WHERE postcode>“98000”
视图中的行要比主表中的行少,而且物理顺序就是所要求的顺序,减少了磁盘I/O,所以查询工作量可以得到大幅减少。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号