04
1.用图与自己的话,简要描述Hadoop起源与发展阶段。
Hadoop是道格·卡丁(Doug Cutting)创建的,Hadoop起源于开源网络搜索引擎Apache Nutch,后者本身也是Lucene项目的一部分。Nutch项目面世后,面对数据量巨大的网页显示出了架构的灵活性不够。当时正好借鉴了谷歌分布式文件系统,做出了自己的开源系统NDFS分布式文件系统。第二年谷歌又发表了论文介绍了MapReduce系统,Nutch开发人员也开发出了MapReduce系统。随后NDFS和MapReduce命名为Hadoop,成为了Apache顶级项目。
从Hadoop的发展历程来看,它的思想来自于google的三篇论文。
GFS:Google File System 分布式处理系统 ------》解决存储问题
Mapreduce:分布式计算模型 ------》对数据进行计算处理
BigTable:解决查询分布式存储文件慢的问题,把所有的数据存入一张表中,通过牺牲空间换取时间。
2.用图与自己的话,简要描述名称节点、数据节点的主要功能及相互关系、名称节点的工作机制。
名称节点:负责管理分布式文件系统的命名空间,里面包含了两个核心的数据结构,即FsImage和EditLog。FsImage用户文件树以及所有的文件和文件夹的元数据。EfitLog记录的是文件的增删改查。
首次安装format格式化就是在本地生成FsImage。首次安装format格式化就是在本地生成FsImage。
HDFS的更新都会被写入到FsImage中而不是EditLog,因为对于分布式而言,FsImage非常庞大,直接对FsImage速度非常慢。HDFS的更新都会被写入到FsImage中而不是EditLog,因为对于分布式而言,FsImage非常庞大,直接对FsImage速度非常慢。
数据节点(DataNode):定期向名称节点发送自己的存储块的列表。数据节点(DataNode):定期向名称节点发送自己的存储块的列表。
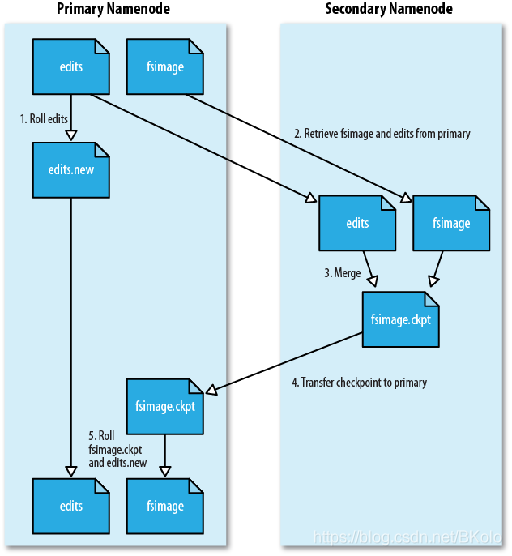
因为HDFS文件会逐渐地变大,不断变大的EditLog文件通常不会对系统文件产生影响,但是当EditLog很大时,使得在HDFS重启时,将EditLog合并到FsImage中的过程十分缓慢,系统长期处于“安全模式”,用户的使用收到影响。
HDFS的第二名称节点(secondary NameNode)的作用:完成EditLog合并到FsImage的过程,缩短合并的重启时间,其次作为“检查点”保存元数据的信息。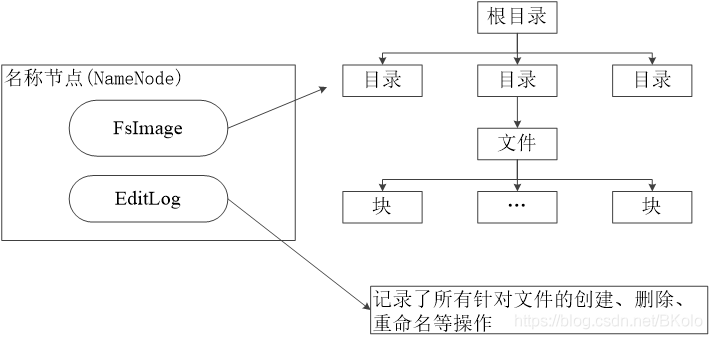
3.分别从以下这些方面,梳理清楚HDFS的 结构与运行流程
1、HDFS 采用主/从架构,主节点即NameNode 从节点即:DataNode
2、NameNode即是模式, 并完成外模式和模式之间的映像,模式和内模式之间的映像。
3、NameNode存放HDFS全局命名空间,充当全局数据目录;存储全局文件系统树,目录-文件-文件块信息
NameNode存放的数据块信息是在启动时扫描所有数据节点重构;
在运行过程中周期性受到数据节点发送的数据块列表信息重构而得;
4、在客户端读取数据过程中,将数据块和数据节点映射按远近排序列表发送给客户端;
5、在客户端写数据过程中,检查文件是否存在、是否有权限;将待写入文件分成若干文件块,并根据数据节点的繁忙和磁盘容量程度,分配数据块和数据节点对应关系列表反馈给客户端

 浙公网安备 33010602011771号
浙公网安备 33010602011771号