
数据采集第四次作业
目录
作业一:
运行代码及结果-1
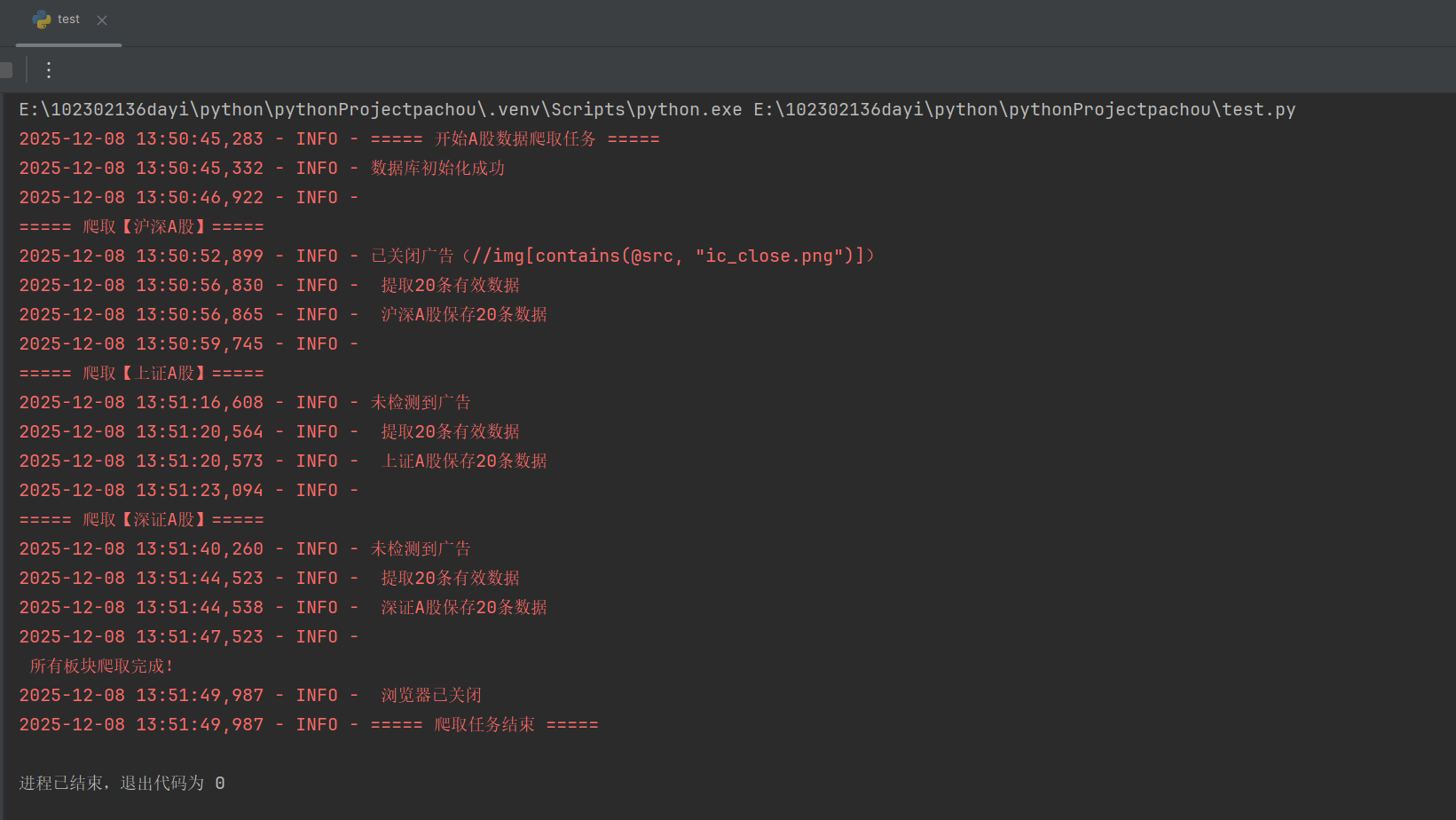
1、首先要去网站上确认目标网站结构,以沪深 A 股页面为例
2、打开网页时发现会有广告弹出,为了不影响数据的爬取,设置了一个关闭广告的函数close_ads

点击查看代码
# 关闭广告
def close_ads(driver):
# 定义可能的广告关闭按钮XPath列表
for xpath in ['//img[contains(@src, "ic_close.png")]', '//img[@onclick="_tk_tg_zoomin()"]',
'//button[contains(@class, "close")]', '//span[contains(text(), "关闭")]']:
try:
# 等待广告关闭按钮可点击,然后点击
WebDriverWait(driver, 3).until(EC.element_to_be_clickable((By.XPATH, xpath))).click()
logger.info(f"已关闭广告({xpath})")
return True # 关闭成功后退出函数
except:
continue # 该XPath对应的按钮不存在,尝试下一个
logger.info("未检测到广告") # 所有XPath都尝试过,未找到广告关闭按钮
3、对于东方财富网,由于其同一类页面(如不同股票板块的列表页)通常采用相同的 HTML 结构,因此我通过不同URL访问对应板块,再用统一的XPath提取数据。整体爬取的框架为:先访问页面→处理干扰(广告)→等待核心元素(表格)加载→提取数据。这里通过EC.presence_of_element_located确保表格加载完成后再提取,避免获取空数据。
点击查看代码
def crawl_board(board_name, url, driver):
driver.get(url) # 访问页面
close_ads(driver) # 预处理(关广告)
# 等待表格加载完成
WebDriverWait(driver, 15).until(EC.presence_of_element_located((By.XPATH, '//div[@class="quotetable"]//table//tbody')))
# 提取表格数据
for row in driver.find_elements(...):
cols = row.find_elements(By.TAG_NAME, 'td')
data.append((cols[0].text, cols[1].text, ...)) # 按列索引收集数据
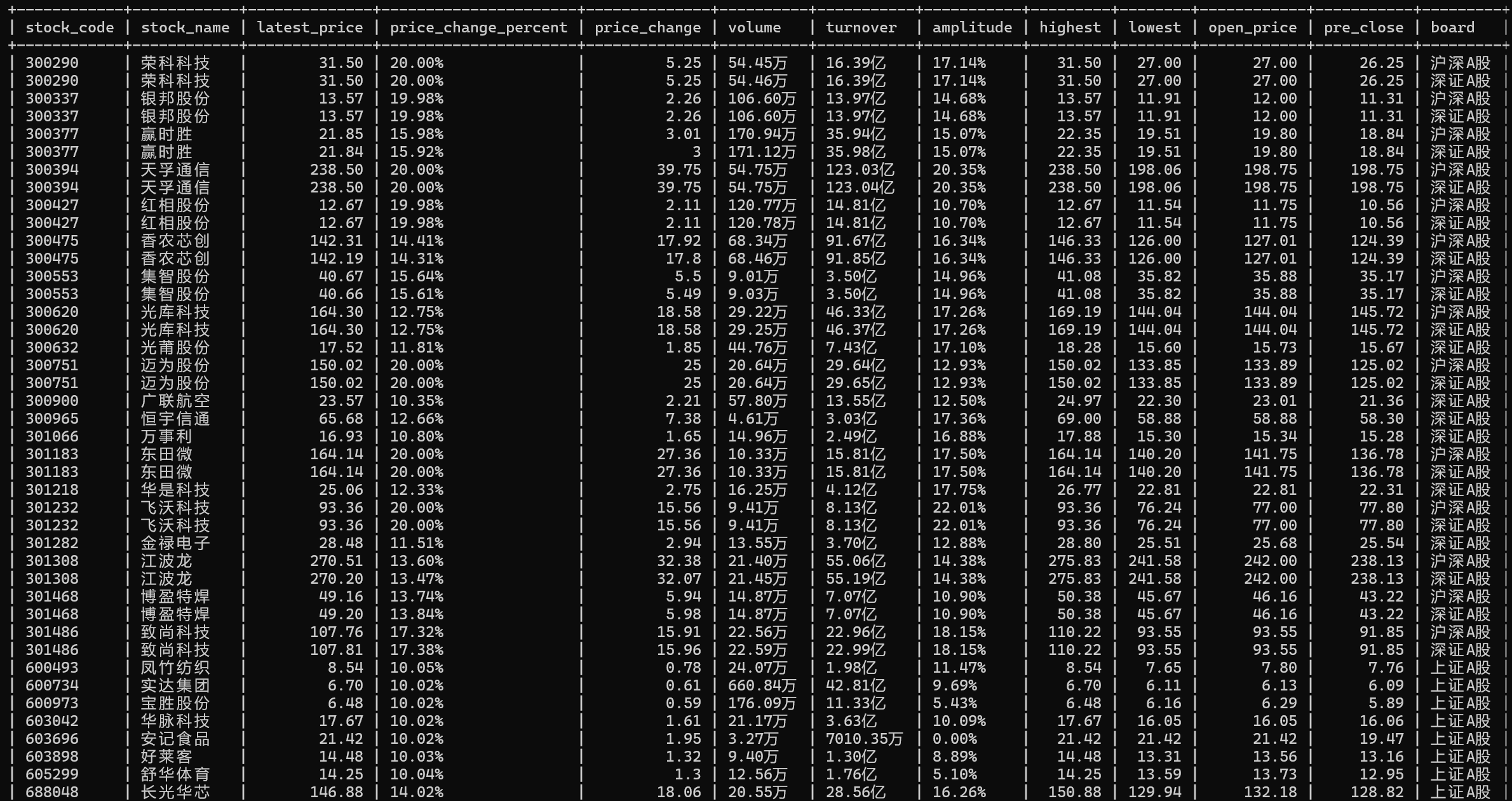
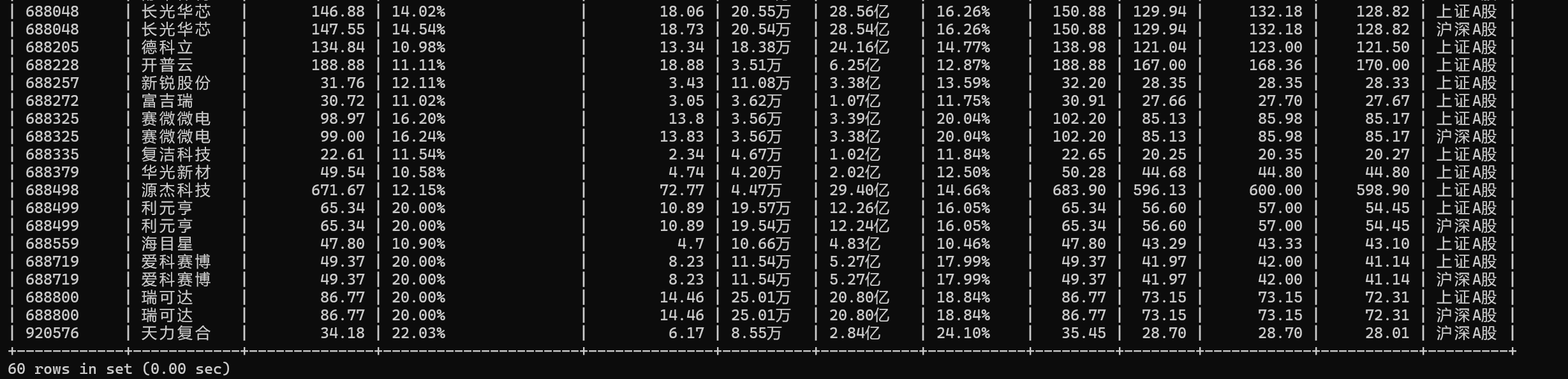
4、在爬取完数据后,下一步就是将数据存储到数据库了。首先先清洗数据(处理格式问题和特殊值),再用executemany批量插入,保证数据的准确性。INSERT IGNORE配合主键约束,进一步防止重复数据。代码如下
点击查看代码
def save_data(data, board):
if not data: return logger.warning(f"{board}无数据可保存")
try:
with pymysql.connect(**DB_CONFIG) as conn:
with conn.cursor() as cur:
sql = """INSERT IGNORE INTO stock_info
(stock_code, stock_name, latest_price, price_change_percent, price_change,
volume, turnover, amplitude, highest, lowest, open_price, pre_close, board)
VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"""
proc_data = []
for item in data:
try:
code, name = item[1].strip(), item[2].strip()
latest = float(item[3].strip().replace(',', '')) if item[3].strip() != '-' else None
pct, change = item[4].strip(), float(item[5].strip().replace(',', '')) if item[
5].strip() != '-' else None
vol, turn, amp = item[6].strip(), item[7].strip(), item[8].strip()
high = float(item[9].strip().replace(',', '')) if item[9].strip() != '-' else None
low = float(item[10].strip().replace(',', '')) if item[10].strip() != '-' else None
open_p = float(item[11].strip().replace(',', '')) if item[11].strip() != '-' else None
pre_p = float(item[12].strip().replace(',', '')) if item[12].strip() != '-' else None
proc_data.append(
(code, name, latest, pct, change, vol, turn, amp, high, low, open_p, pre_p, board))
except:
continue
if proc_data:
cur.executemany(sql, proc_data)
conn.commit()
logger.info(f" {board}保存{len(proc_data)}条数据")
except Exception as e:
logger.error(f"{board}保存失败:{e}")
conn.rollback()
心得体会-1
本次实践我掌握了 Selenium 自动化爬取、XPath 元素定位与 MySQL 数据存储的核心逻辑。学会了处理广告干扰、数据清洗问题,体会到代码模块化与容错设计的重要性。
代码链接:https://gitee.com/lin-weijie123/2025_crawl_project/blob/master/作业四/1.py
作业二:
运行代码及结果-2
1、慕课上的课程众多,为了方便爬取,我选择先登录mooc平台,从我自己选择的课程中爬取信息
2、对于上图的页面,并不能看到所有课程的详细信息,因此需要通过开发者工具提取每个课程的URL,再逐一进行爬取
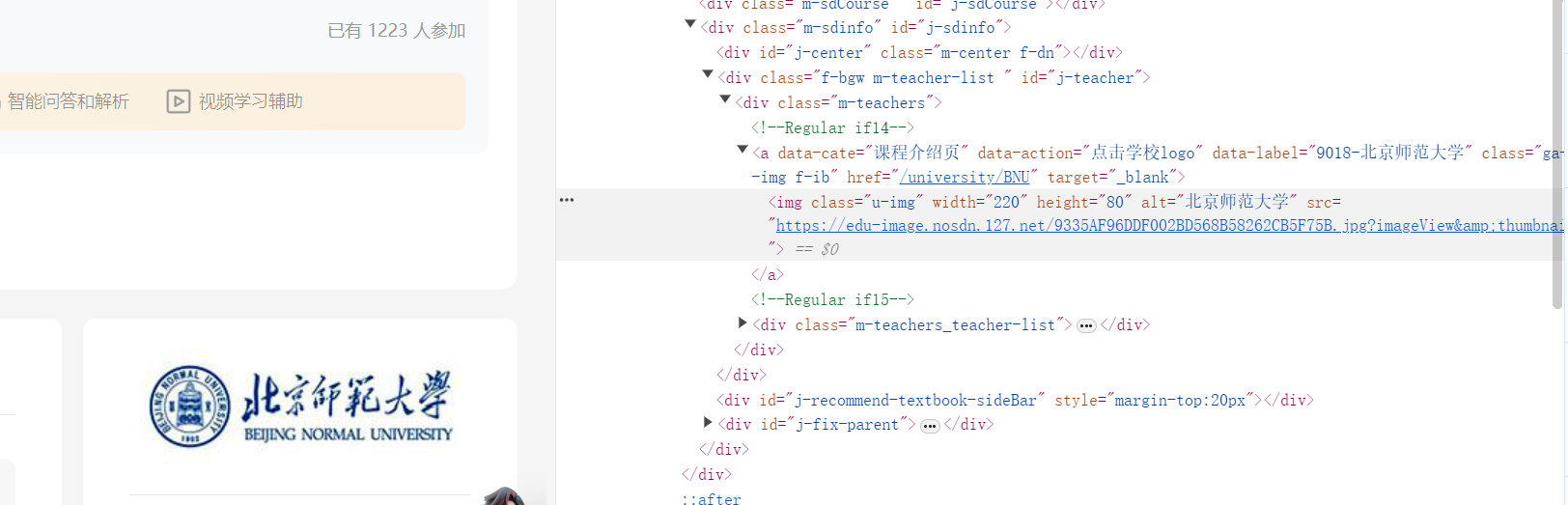
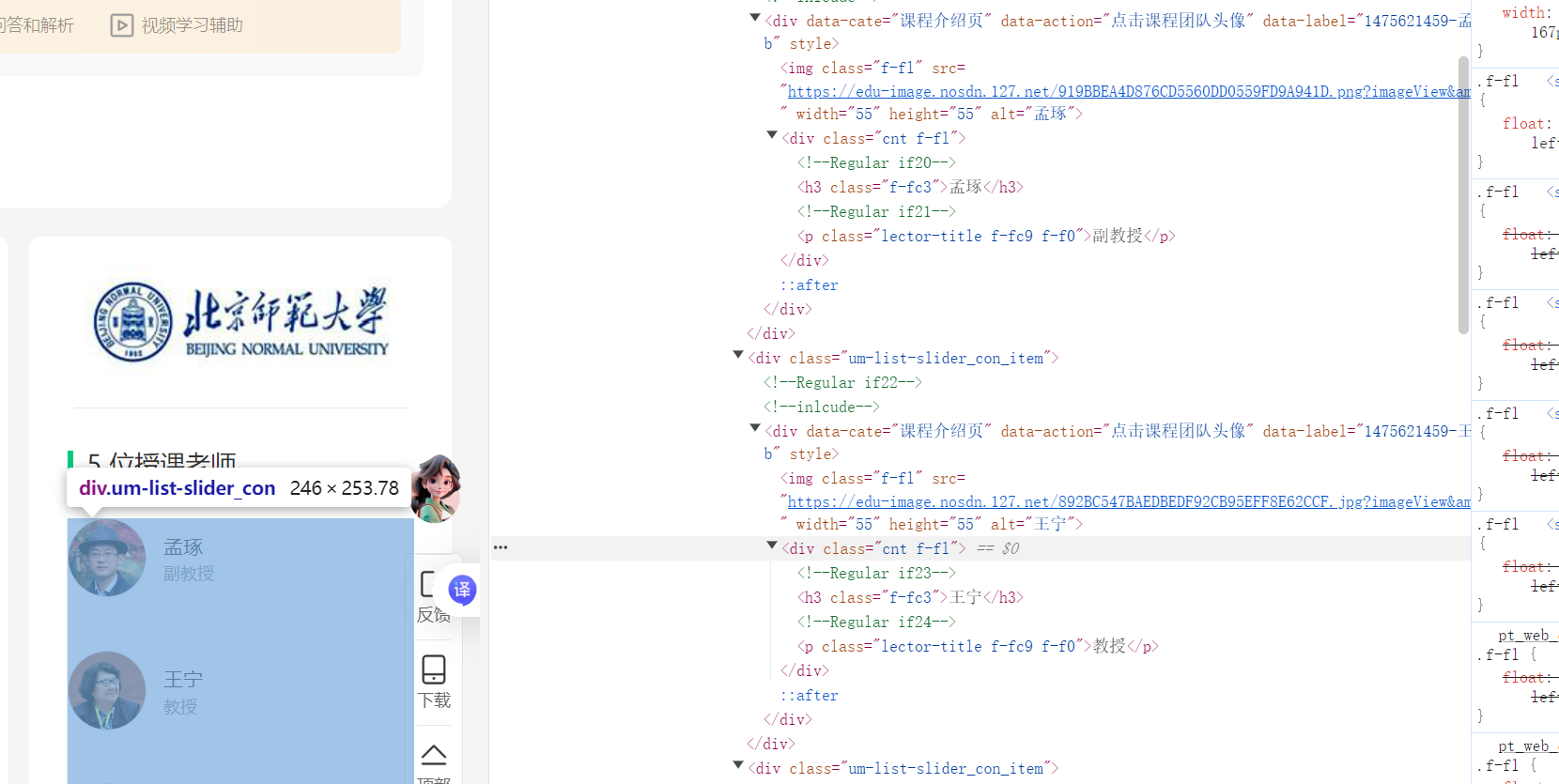
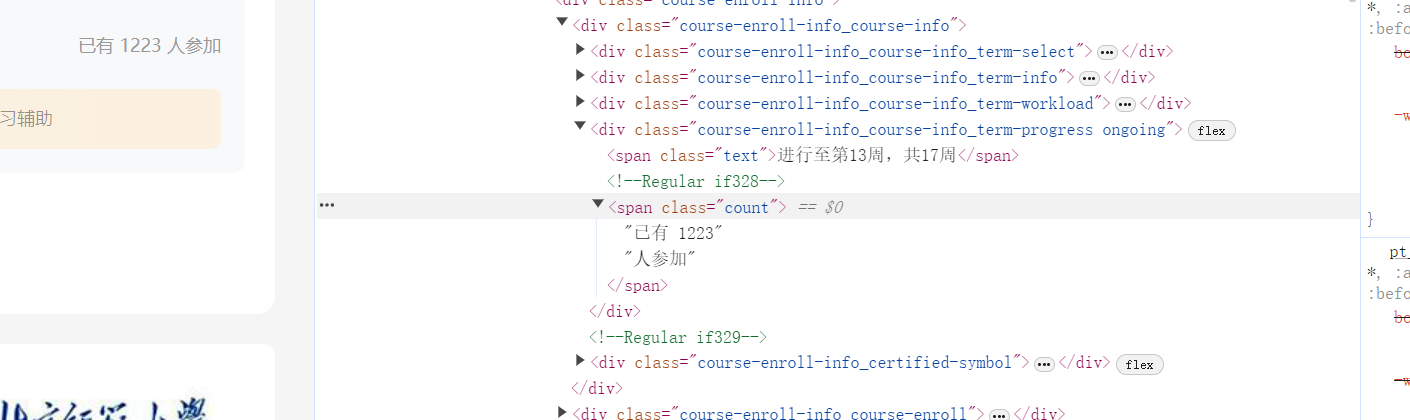
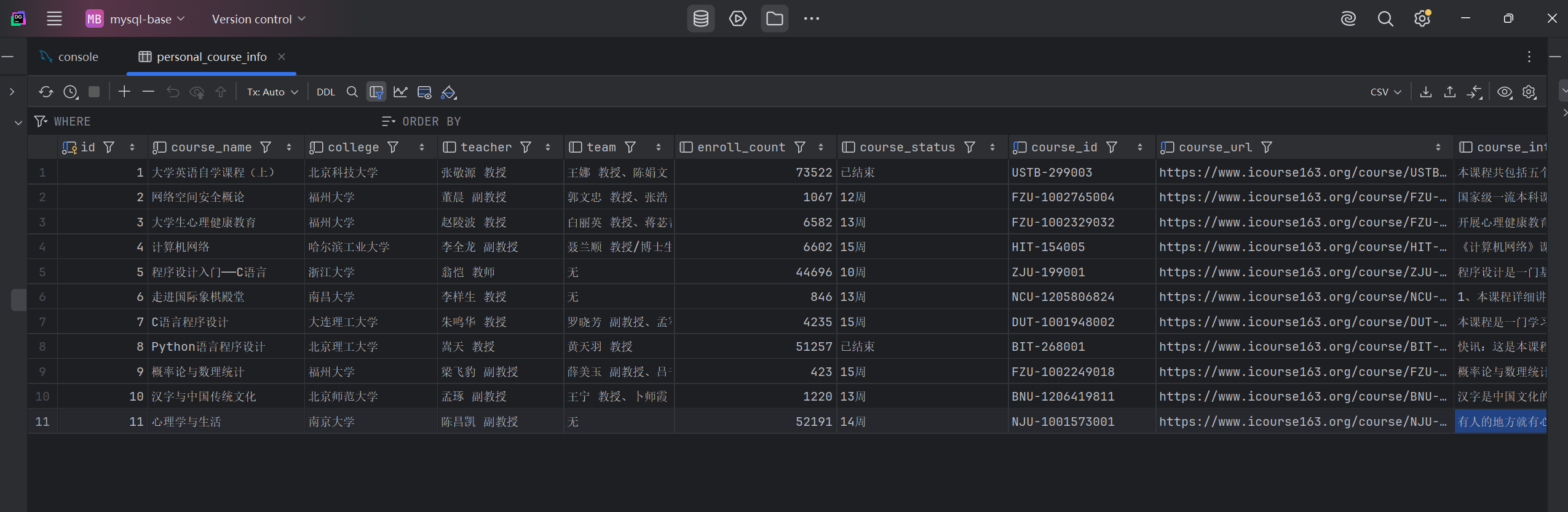
3、随便进入一个课程,根据题目的要求,依次查看课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介

4、懒加载提取课程 URL:使用滚动触发懒加载,确保加载所有课程
点击查看代码
def extract_personal_course_urls(driver, wait):
driver.get(PERSONAL_COURSE_URL)
# 滚动3次加载所有课程(懒加载机制)
for i in range(3):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(3)
# 多选择器定位课程链接(兜底适配不同页面结构)
selectors = ["a[data-action='课程tag-非新学期课程']", "div.course-card-wrapper a.j-course-card-box"]
course_link_elements = []
for selector in selectors:
elements = driver.find_elements(By.CSS_SELECTOR, selector)
if elements:
course_link_elements = elements
break
# 提取课程ID和URL(正则匹配)
course_urls = []
for elem in course_link_elements:
full_url = elem.get_attribute("href")
course_id_match = re.search(r'course/(\w+-\d+)', full_url) # 提取课程号(如BNU-1206419811)
if course_id_match:
course_id = course_id_match.group(1)
course_urls.append((course_id, full_url))
return course_urls
5、课程详情提取(部分示例)
点击查看代码
def get_course_detail(driver, wait, course_id, course_url):
driver.get(course_url)
time.sleep(8) # 等待页面加载
# 1. 课程名称
name_selectors = [".course-title", "h1.course-title"]
for selector in name_selectors:
try:
course_info["course_name"] = driver.find_element(By.CSS_SELECTOR, selector).text.strip()
break
except:
continue
# 2. 教师信息
teacher_selectors = [".m-teachers_teacher-list .um-list-slider_con_item", ".teacher-panel .teacher-item"]
teachers = []
for selector in teacher_selectors:
items = driver.find_elements(By.CSS_SELECTOR, selector)
if items:
for item in items:
teacher_text = item.text.strip().replace("\n", " ") # 去掉换行(如“王宁\n教授”→“王宁 教授”)
teachers.append(teacher_text)
break
course_info["teacher"] = teachers[0] if teachers else "未公开" # 主讲教师
course_info["team"] = "、".join(teachers[1:]) if len(teachers)>1 else "无" # 团队
# 3. 参加人数
count_text = driver.find_element(By.CSS_SELECTOR, ".course-enroll-info .count").text.strip()
count_match = re.search(r'(\d+)', count_text)
course_info["enroll_count"] = int(count_match.group(1)) if count_match else 0
return course_info
- 数据库保存:将爬取的课程信息插入数据库,使用ON DUPLICATE KEY UPDATE避免重复数据,确保数据唯一性
点击查看代码
def save_to_database(conn, cursor, course_info):
cursor.execute('''
INSERT INTO personal_course_info
(course_name, college, teacher, team, enroll_count, course_status, course_intro, course_id, course_url)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s)
ON DUPLICATE KEY UPDATE # 重复课程ID时更新数据
college=%s, teacher=%s, team=%s, enroll_count=%s, course_status=%s, course_intro=%s
''', (course_info["course_name"], course_info["college"], ...)) # 传入所有字段值
conn.commit()
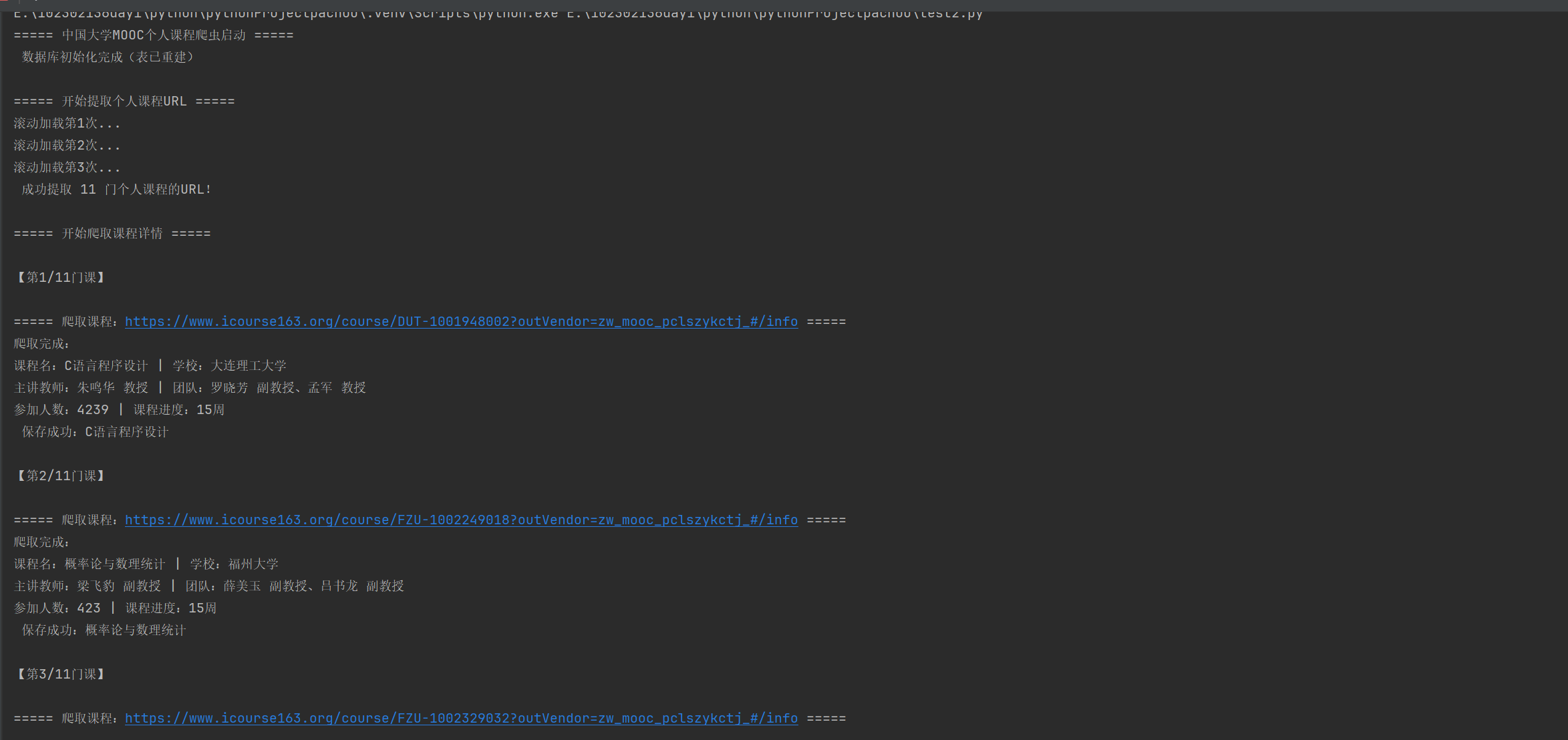
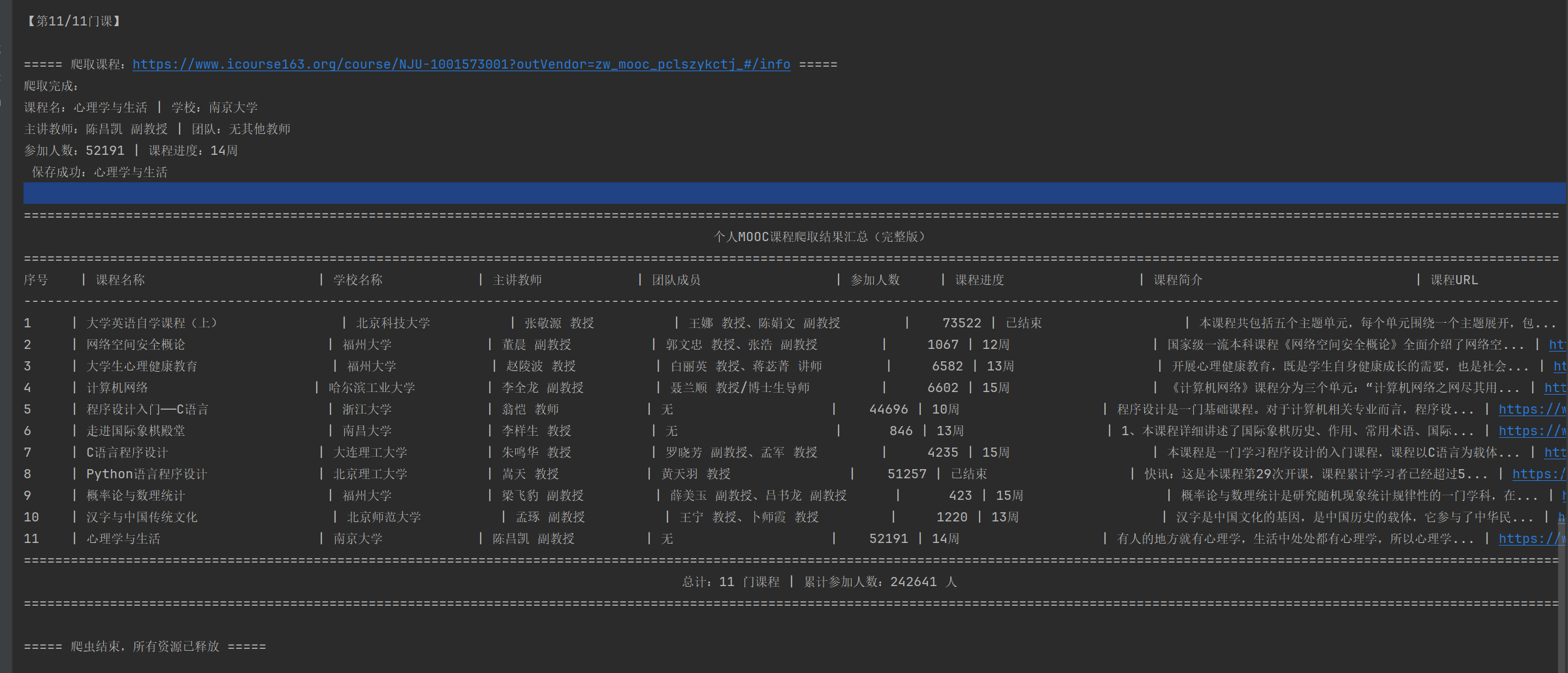
心得体会-2
通过本次MOOC个人课程爬虫作业,我掌握了Selenium自动化爬取、MySQL数据存储等核心技能,过程中使用了正则提取关键信息、也使用了用多选择器适配不同页面结构。
代码链接:https://gitee.com/lin-weijie123/2025_crawl_project/blob/master/作业四/2.py
作业三:
运行代码及结果-3
- 任务一:开通MapReduce服务

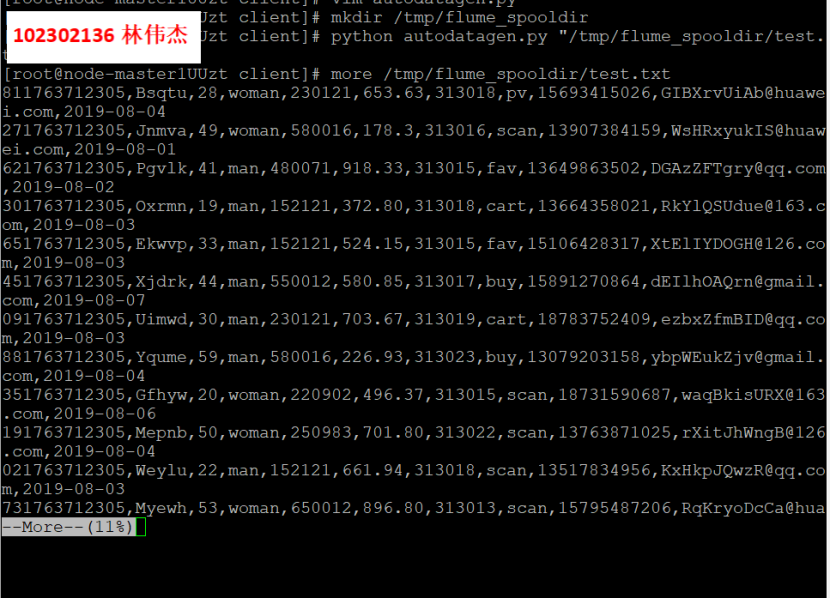
- 任务一:Python脚本生成测试数据
使用more命令查看生成的数据
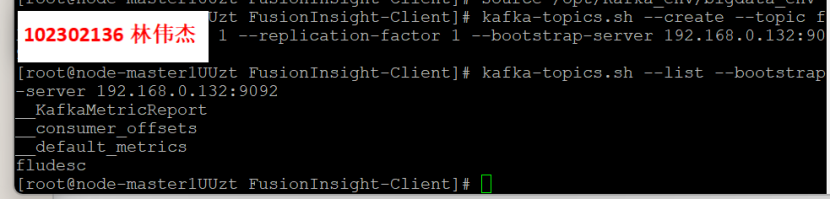
2.任务二:配置Kafka
步骤 1:客户端下载成功

步骤 2:查看kafka的IP
kafka-topics.sh --create --topic fludesc --partitions 1 --replication-factor 1 --bootstrap-server 192.168.0.132:9092
步骤 3:查看topic信息
3.任务三: 安装Flume客户端
步骤 1:下载Flume客户端
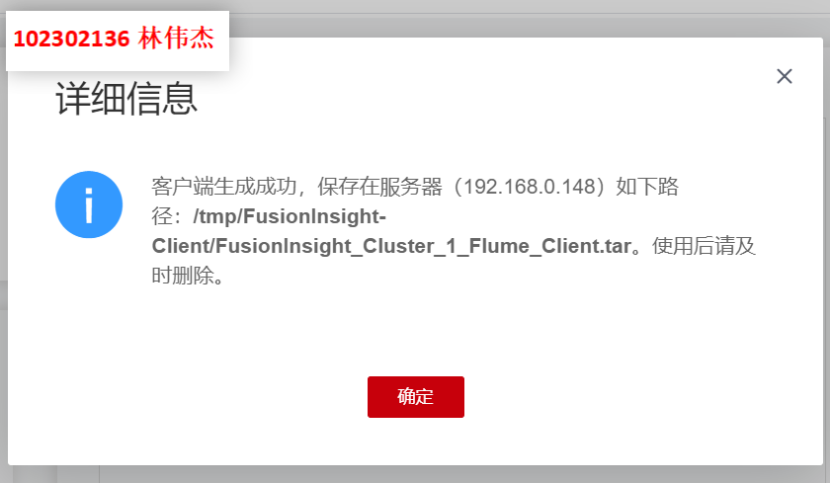
步骤 2:重启Flume服务
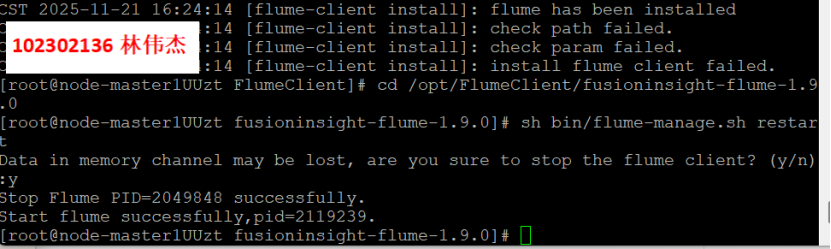
4.任务四:配置Flume采集数据
测试消费者消费kafka中的数据

心得体会-3
完成华为云Flume日志采集实验,我掌握了Xshell操作、MapReduce开通及Kafka、Flume配置,熟悉了大数据实时数据采集流程,通过实践提升了工具实操能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号