

数据采集第二次作业
目录
作业一:
完整代码及结果-1
以北京为例,先去查看网页的html结构
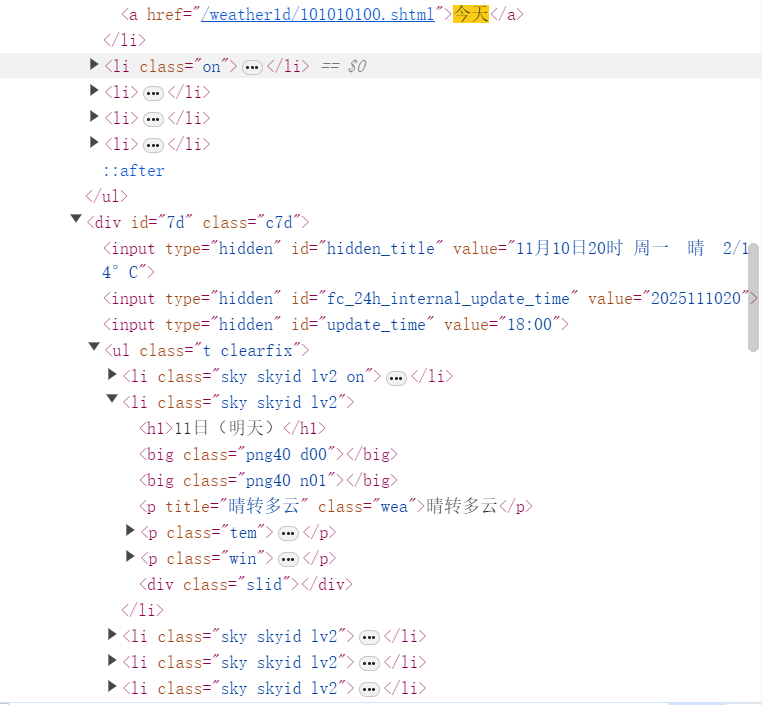
与上次实验不同的是,这次的实验需要保存到数据库,这里使用openDB()方法创建、连接到weathers.db数据库,创建weathers表,再通过insert()方法插入天气数据
- 完整代码
点击查看代码
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import sqlite3
# 数据库操作类:管理天气数据的存储与查询
class WeatherDB:
def openDB(self):
self.con = sqlite3.connect("weathers.db") # 数据库连接对象
self.cursor = self.con.cursor() # 数据库操作游标
try:
self.cursor.execute(
"create table weathers (wCity varchar(16), wDate varchar(16), wWeather varchar(64), wTemp varchar(32), constraint pk_weather primary key (wCity, wDate))")
except:
self.cursor.execute("delete from weathers")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self, city, date, weather, temp): # 插入单条天气数据
try:
self.cursor.execute("insert into weathers (wCity,wDate,wWeather,wTemp) values (?,?,?,?)", (city, date, weather, temp))
except Exception as err:
print(err)
def show(self): # 显示所有存储的天气数据
count = 1
self.cursor.execute("select * from weathers")
rows = self.cursor.fetchall()
tplt = "{0:^16}\t{1:^16}\t{2:^16}\t{3:^32}\t{4:^16}"
print(tplt.format("序号", "地区", "日期", "天气信息", "温度", chr(12288)))
for row in rows:
print(tplt.format(str(count), row[0], row[1], row[2], row[3], chr(12288)))
count += 1
# 天气爬取类:负责网页请求、数据解析与存储协调
class WeatherForecast:
def __init__(self):
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36"}
self.cityCode = {"北京": "101010100", "上海": "101020100", "广州": "101280101", "深圳": "101280601"} # 城市-编码映射
def forecastCity(self, city): # 爬取单个城市的天气预报
if city not in self.cityCode.keys():
print(city + " code cannot be found")
return
url = "http://www.weather.com.cn/weather/" + self.cityCode[city] + ".shtml"
try:
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
lis = soup.select("ul[class='t clearfix'] li")
for li in lis:
try:
date = li.select('h1')[0].text
weather = li.select('p[class="wea"]')[0].text
temp = li.select('p[class="tem"] span')[0].text + "/" + li.select('p[class="tem"] i')[0].text
self.db.insert(city, date, weather, temp)
except Exception:
try:
temp = li.select('p[class="tem"] i')[0].text
self.db.insert(city, date, weather, temp)
except Exception as err:
print(err)
except Exception as err:
print(err)
def process(self, cities): # 批量处理多城市爬取、存储与显示
self.db = WeatherDB()
self.db.openDB()
for city in cities:
self.forecastCity(city)
self.db.show()
self.db.closeDB()
ws = WeatherForecast()
ws.process(["北京", "上海"])
- 运行结果
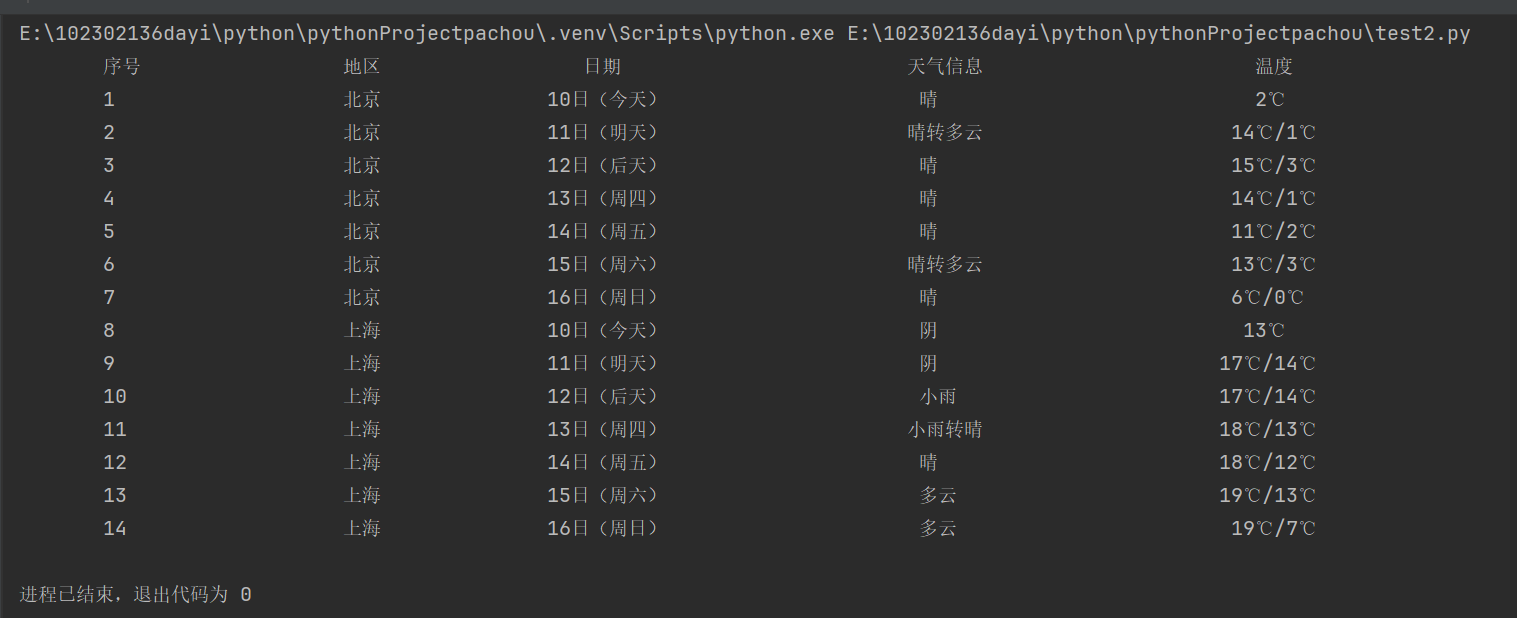
心得体会-1
熟悉了使用BeautifulSoup提取HTML元素的流程,也懂得了处理不同时间段的温度格式差异,以及SQLite数据库的CRUD操作。
代码链接:
https://gitee.com/lin-weijie123/2025_crawl_project/blob/master/作业二/1/1.py
作业二:
完整代码及结果-2
到东方财富网上找到保存股票信息的js文件
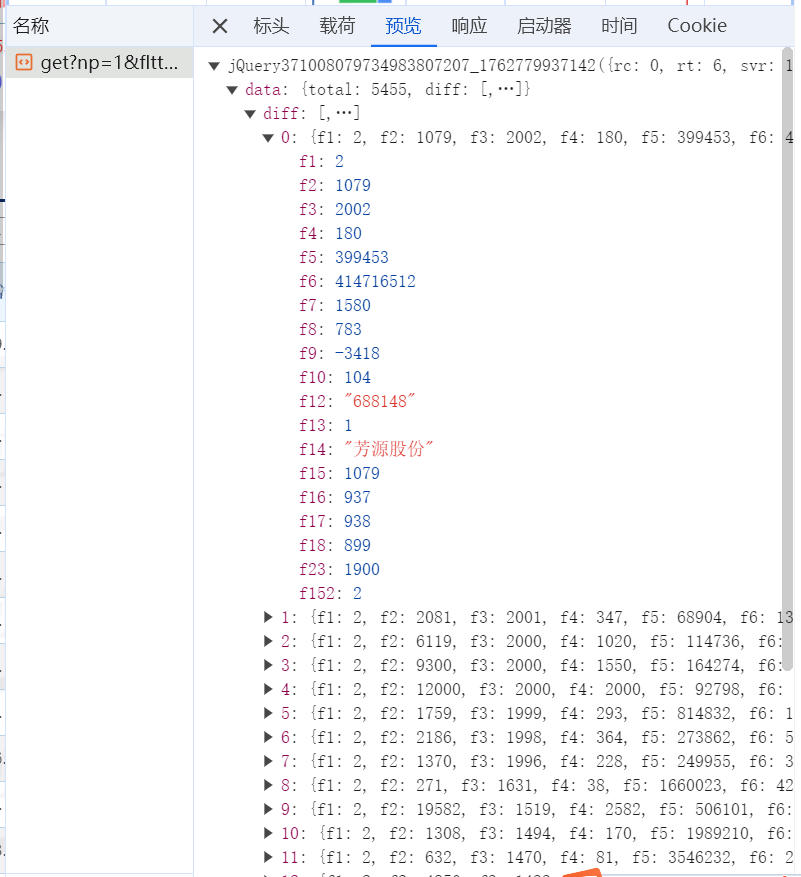
获取网页的URL
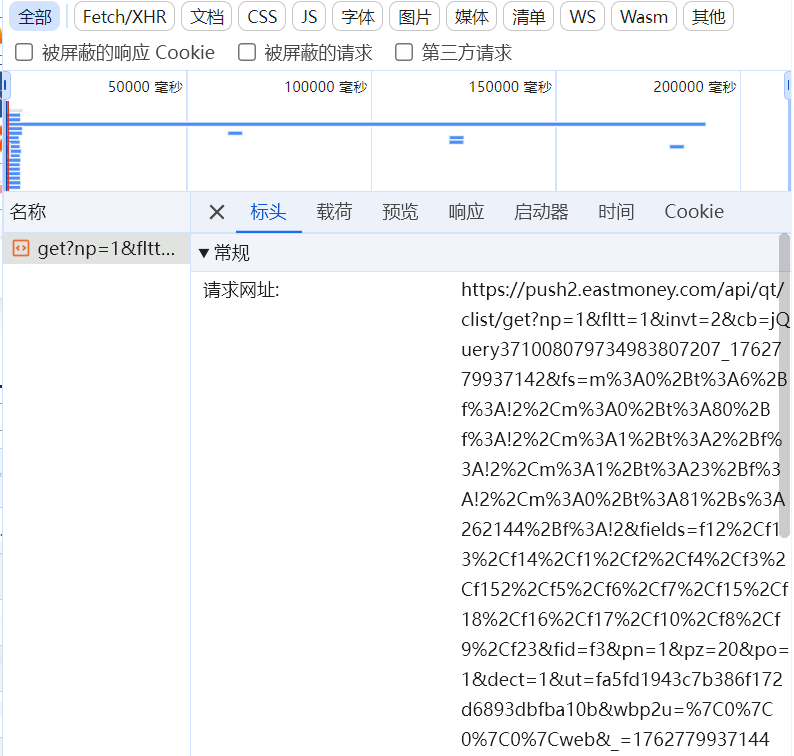
观察财富网的股票信息,发现一页有20条数据,这里用pn参数指定页码,pz设每页条数,循环传不同pn获取对应页数据。
- 完整代码
点击查看代码
import requests
import pandas as pd
import json
import sqlite3
# 常量定义
BASE_URL = "http://44.push2.eastmoney.com/api/qt/clist/get"
API_PARAMS = {
'cb': 'jQuery112406854618710877052_1696660618066',
'pz': 20,
'po': 1,
'np': 1,
'ut': 'bd1d9ddb04089700cf9c27f6f7426281',
'fltt': 2,
'invt': 2,
'wbp2u': '|0|0|0|web',
'fid': 'f3',
'fs': 'm:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048',
'fields': 'f2,f3,f4,f5,f6,f7,f12,f14',
'_': '1696660618067'
}
DB_PATH = 'stock_info.db'
COLUMNS = ['序号', '代码', '名称', '最新价', '涨跌幅', '涨跌额', '成交量', '成交额', '振幅']
def fetch_stock_info(page_number):
"""
获取指定页码的股票信息
"""
params = API_PARAMS.copy()
params['pn'] = page_number
response = requests.get(BASE_URL, params=params)
content = response.text
json_str = content[content.find('(') + 1: content.rfind(')')]
data_json = json.loads(json_str)
stock_items = data_json['data']['diff']
for idx, item in enumerate(stock_items):
yield [
idx + 1,
item['f12'],
item['f14'],
item['f2'],
item['f3'],
item['f4'],
item['f5'],
item['f6'],
item['f7']
]
def save_to_database(stock_data):
"""
将股票数据保存到SQLite数据库
"""
with sqlite3.connect(DB_PATH) as conn:
cursor = conn.cursor()
cursor.execute('''
CREATE TABLE IF NOT EXISTS stock_data (
序号 INTEGER,
代码 TEXT,
名称 TEXT,
最新价 REAL,
涨跌幅 REAL,
涨跌额 REAL,
成交量 INTEGER,
成交额 REAL,
振幅 REAL
)
''')
cursor.executemany('INSERT INTO stock_data VALUES (?,?,?,?,?,?,?,?,?)', stock_data)
conn.commit()
def get_user_input():
"""
获取用户输入的页数
"""
while True:
try:
page_input = int(input("请输入要爬取的页数:"))
if page_input <= 0:
raise ValueError("页数必须为正整数")
return page_input
except ValueError as e:
print(f"输入错误: {e}")
def main():
"""
主函数,执行数据获取和存储操作
"""
page_input = get_user_input()
total_stock_data = []
for page in range(1, page_input + 1):
total_stock_data.extend(fetch_stock_info(page))
if total_stock_data:
save_to_database(total_stock_data)
df = pd.DataFrame(total_stock_data, columns=COLUMNS)
print(df)
if __name__ == "__main__":
main()
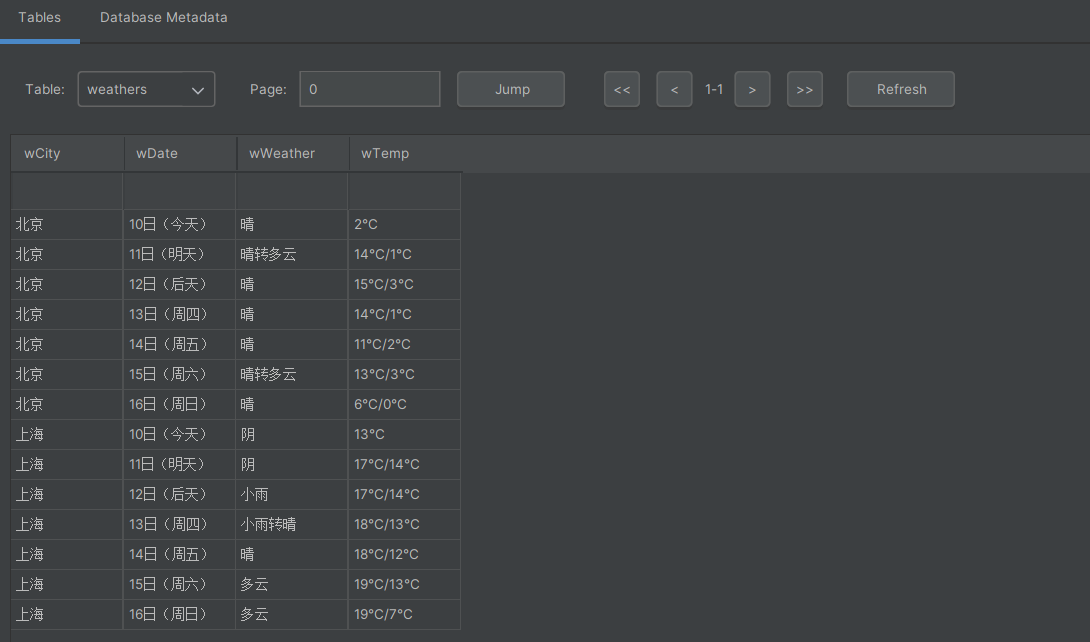
- 运行结果
![image]()
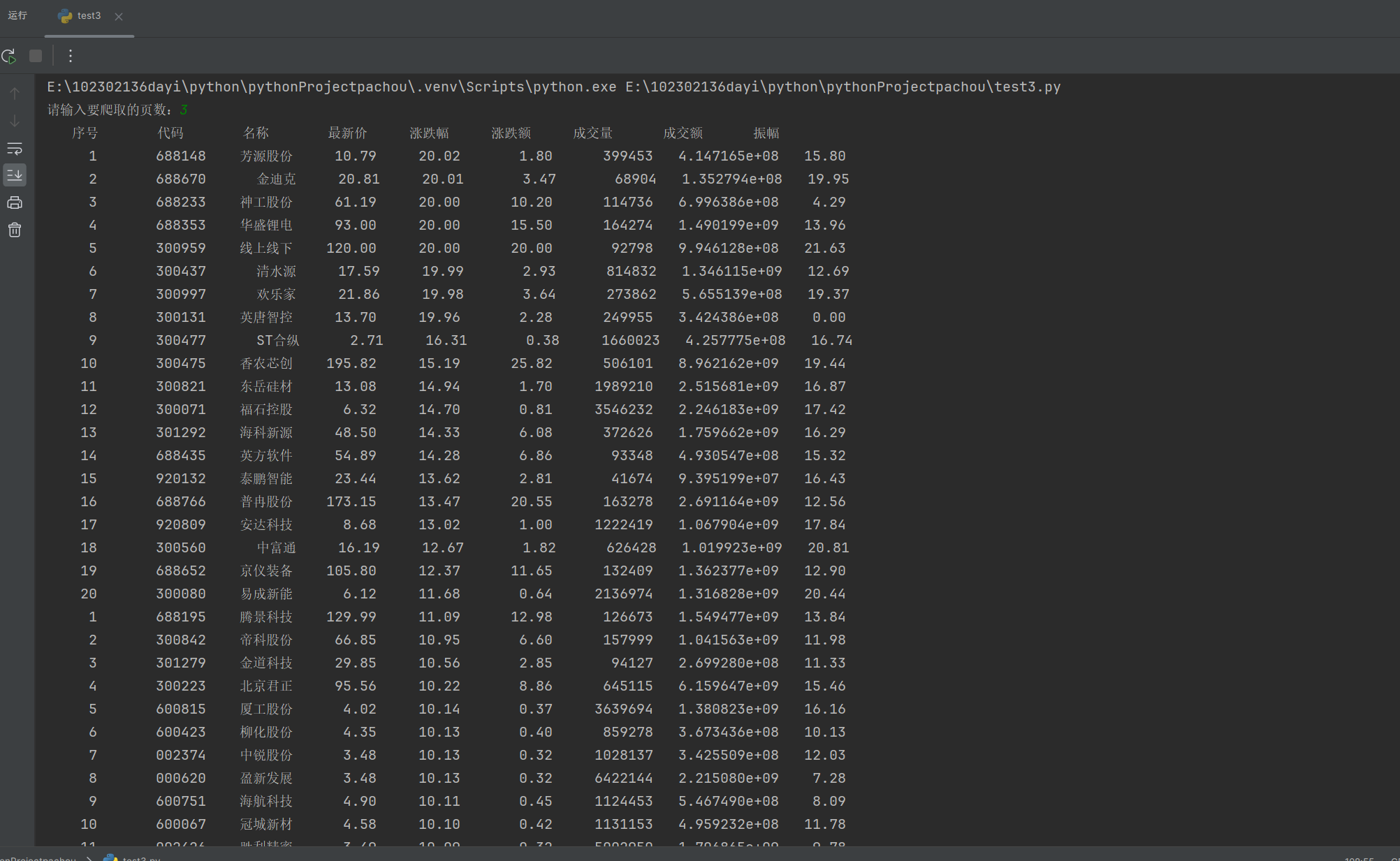
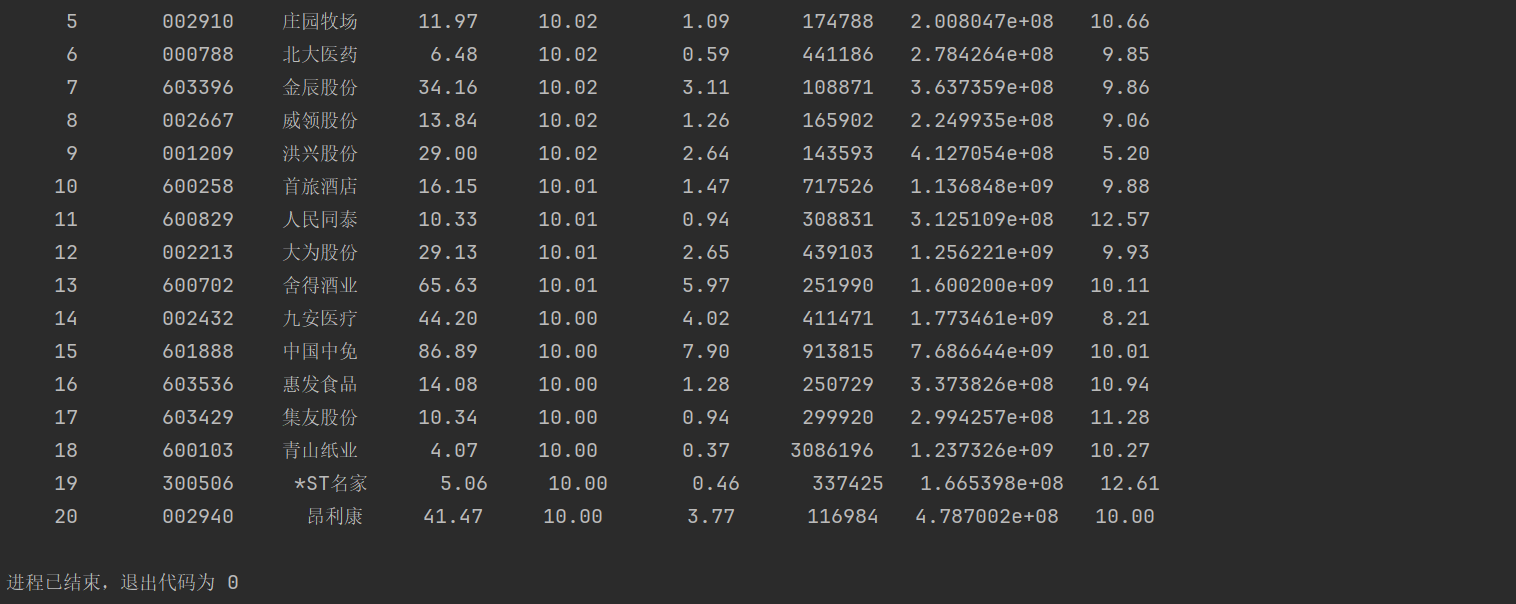
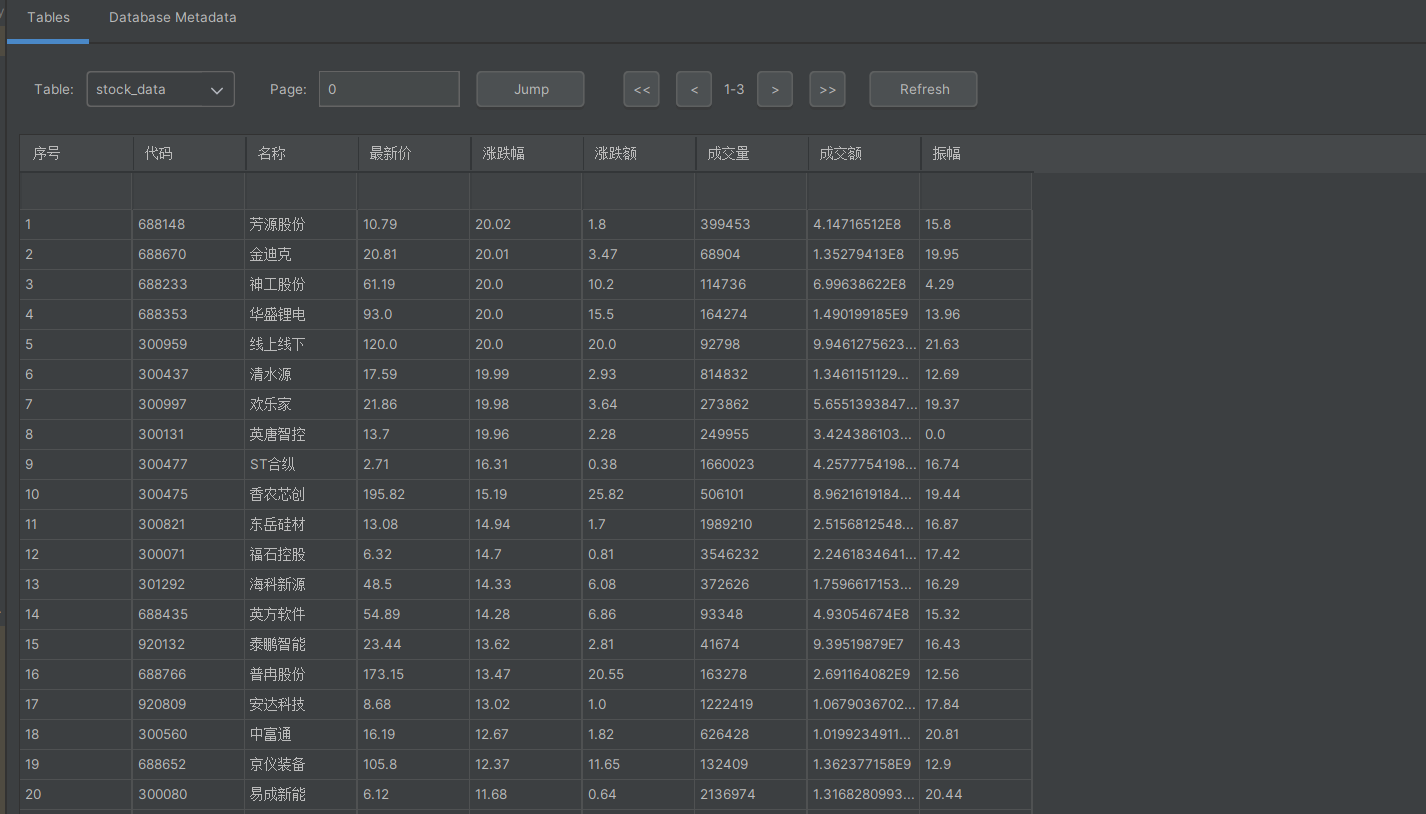
心得体会-2
通过F12调试工具找到真实的数据源,还是比解析HTML更高效稳定的。
代码链接:
https://gitee.com/lin-weijie123/2025_crawl_project/blob/master/作业二/2/2.py
作业三:
完整代码及结果-3
gif录制
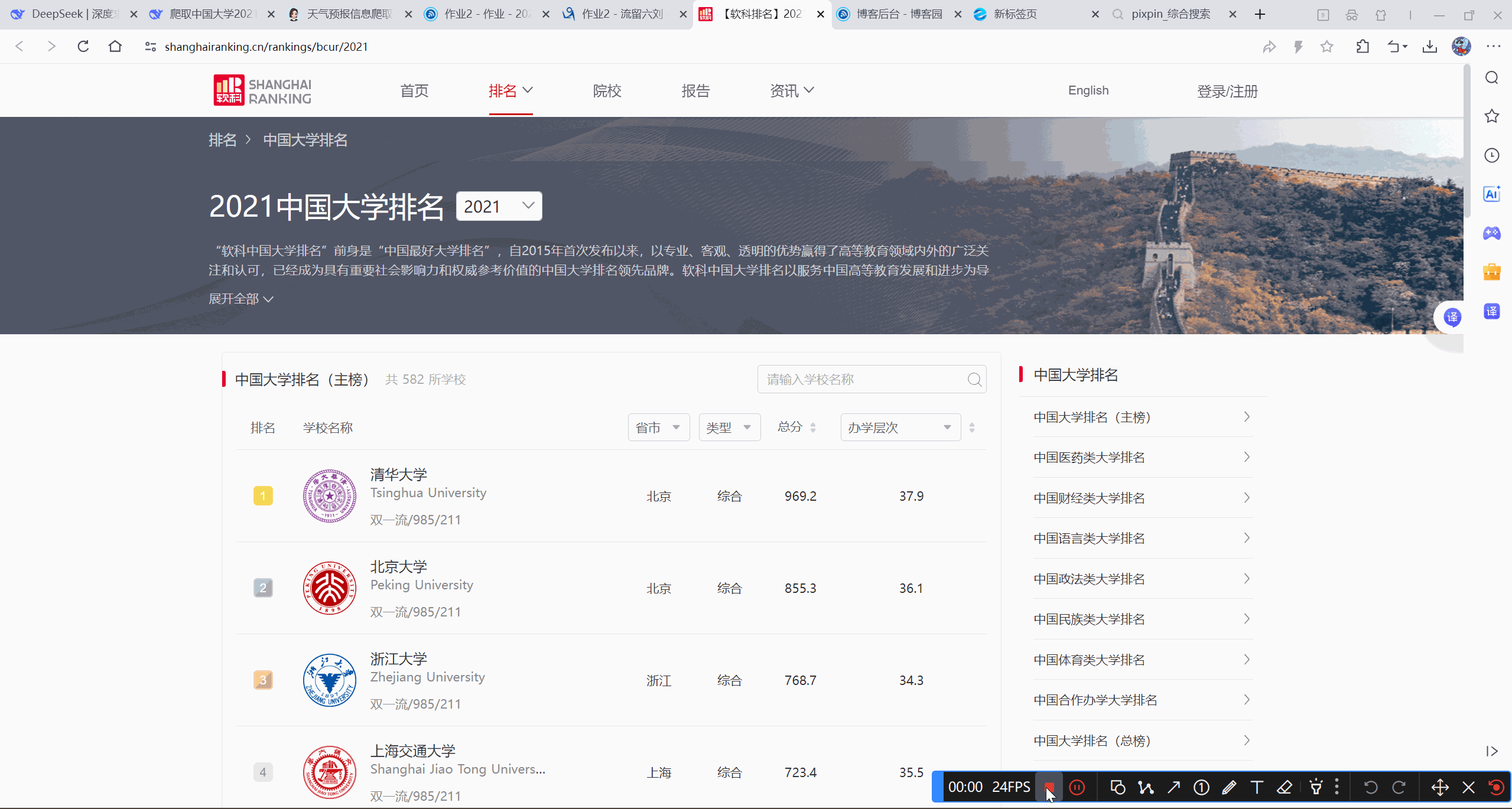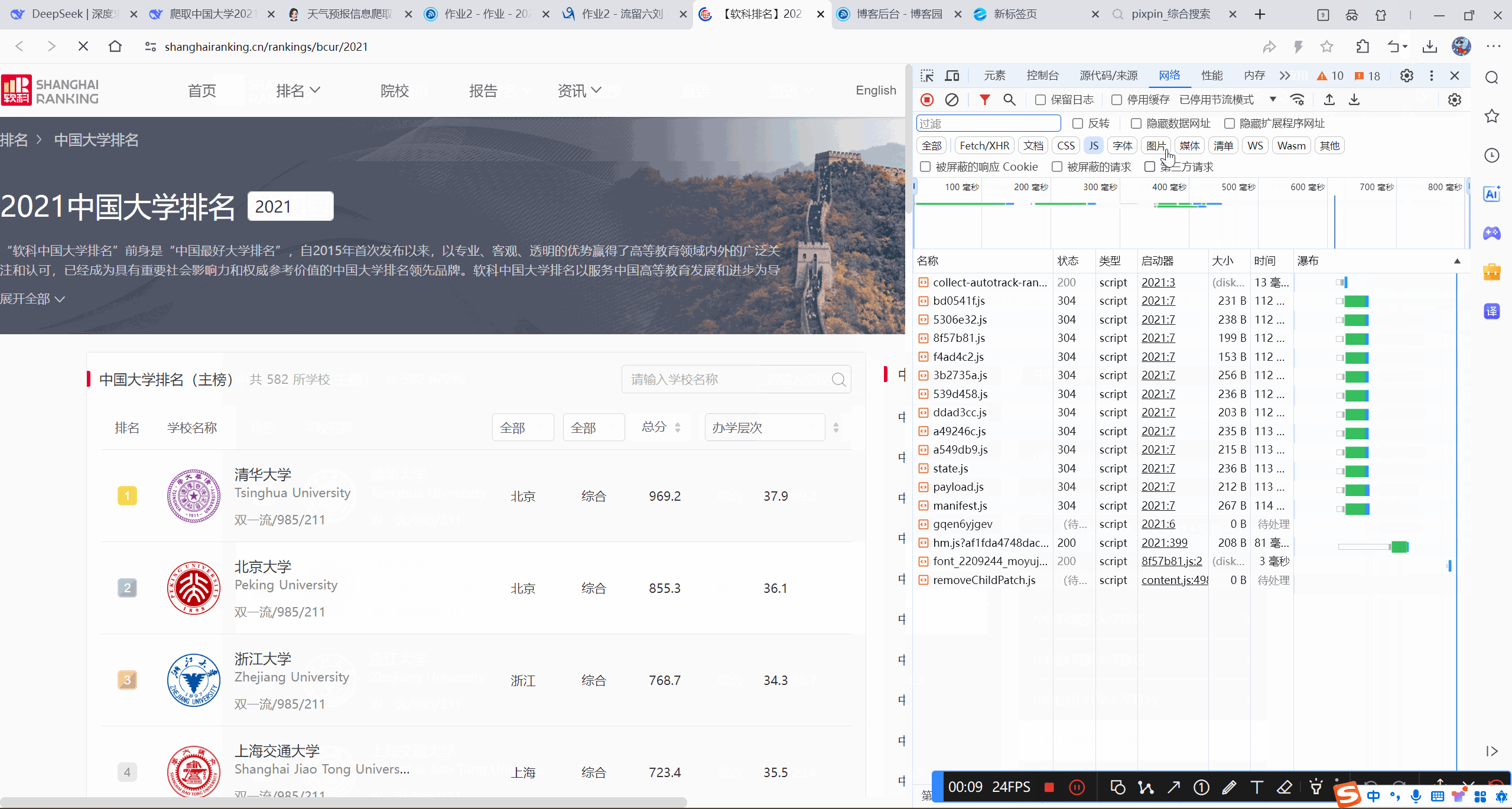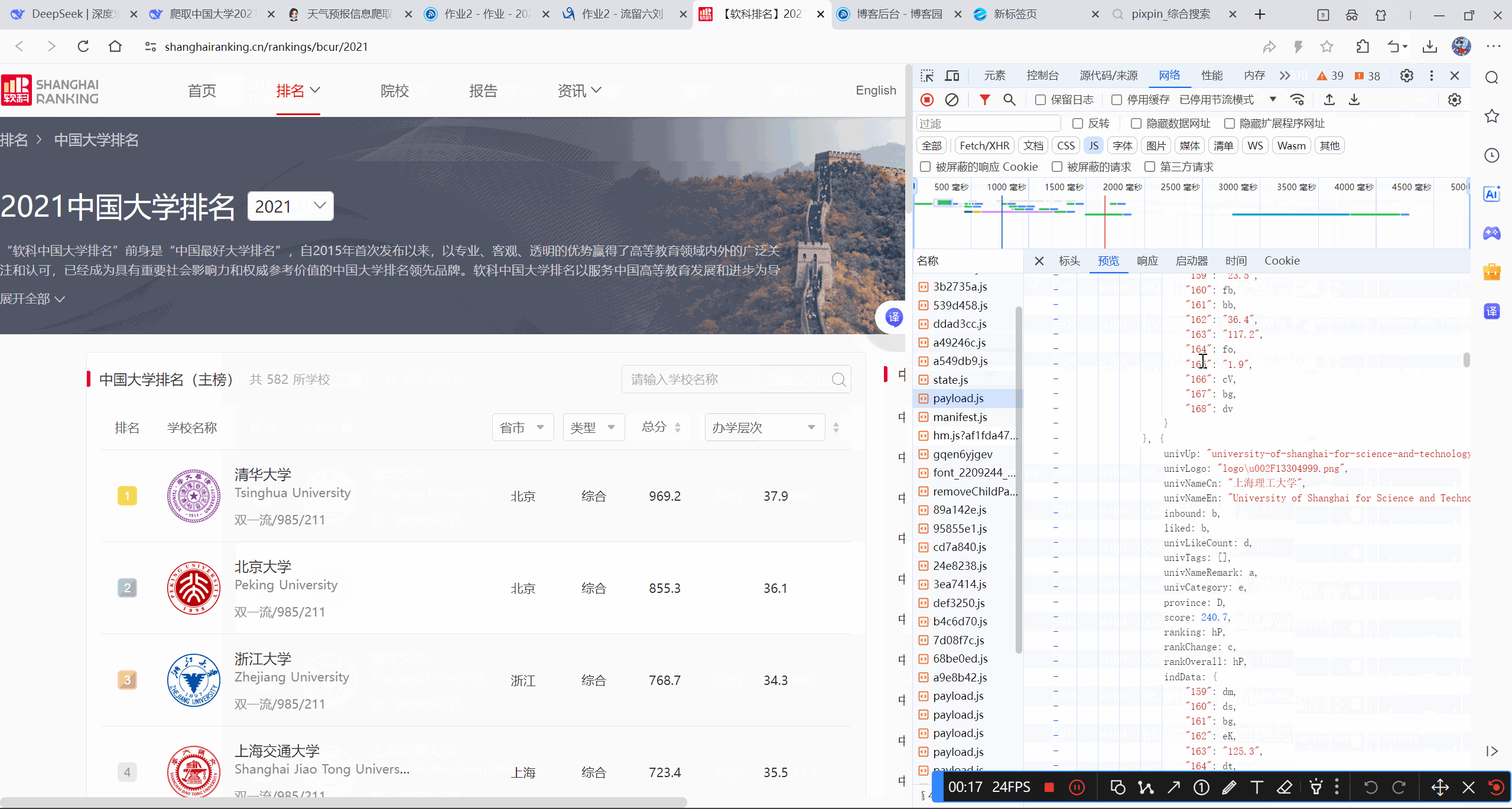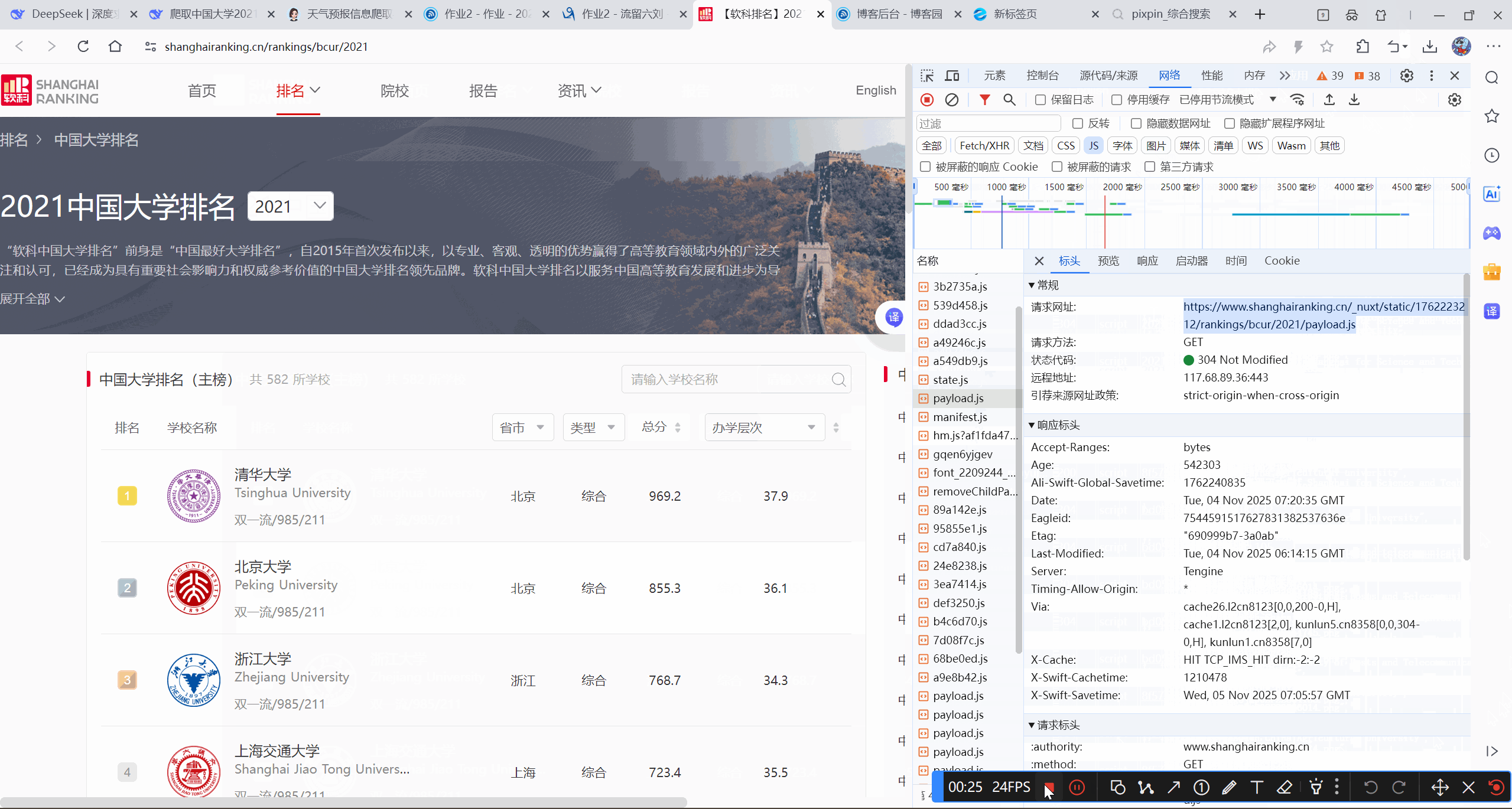
- 完整代码
点击查看代码
import requests
from bs4 import BeautifulSoup
import sqlite3
import re
# 常量定义
DATABASE_NAME = 'university_rankings.db'
TABLE_NAME = 'UniversityRanking'
URL = "https://www.shanghairanking.cn/rankings/bcur/2021"
LABELS_TO_REMOVE = ['双一流', '985工程', '211工程', '985', '211']
COLUMNS = ["排名", "学校", "省份", "类型", "总分"]
TEMPLATE = "{0:^6}\t{1:{5}<20}\t{2:^6}\t{3:^8}\t{4:^6}"
def fetch_html_content(url):
"""
获取指定URL的HTML内容
"""
try:
response = requests.get(url)
response.raise_for_status()
response.encoding = response.apparent_encoding
return response.text
except requests.RequestException as e:
print(f"请求错误: {e}")
return None
def sanitize_university_name(name, labels_to_remove):
"""
清理大学名称中的标签和非中文字符
"""
for label in labels_to_remove:
name = name.replace(label, '')
name = re.sub(r'[A-Za-z]', '', name)
name = re.sub(r'[^\u4e00-\u9fa5]', '', name)
return name
def extract_university_data(html_content, labels_to_remove):
"""
解析HTML内容,提取大学信息列表
"""
soup = BeautifulSoup(html_content, "html.parser")
university_list = []
tbody = soup.find('tbody')
if not tbody:
print("未找到表格数据")
return university_list
rows = tbody.find_all('tr')
for row in rows:
columns = row.find_all('td')
if len(columns) < 5:
continue
rank = columns[0].text.strip()
name_tag = columns[1].find('a')
name = sanitize_university_name(name_tag.text.strip() if name_tag else columns[1].text.strip(), labels_to_remove)
province = columns[2].text.strip()
category = columns[3].text.strip()
score = columns[4].text.strip()
university_list.append([rank, name, province, category, score])
return university_list
def store_university_data(data_list, database_name, table_name):
"""
将大学信息存储到SQLite数据库中
"""
with sqlite3.connect(database_name) as conn:
cursor = conn.cursor()
cursor.execute(f'''
CREATE TABLE IF NOT EXISTS {table_name} (
Rank TEXT,
Name TEXT,
Province TEXT,
Category TEXT,
Score TEXT
)
''')
cursor.executemany(f'INSERT INTO {table_name} VALUES (?,?,?,?,?)', data_list)
conn.commit()
def display_university_data(universities, count, template, columns):
"""
打印大学信息列表
"""
print(template.format(*columns, chr(12288)))
for i in range(min(count, len(universities))):
uni = universities[i]
print(template.format(*uni, chr(12288)))
def execute_university_ranking(url, database_name, table_name, labels_to_remove, columns, template, count):
"""
主函数,执行数据获取、解析、存储和显示操作
"""
html_content = fetch_html_content(url)
if not html_content:
return
university_data = extract_university_data(html_content, labels_to_remove)
if not university_data:
print("未提取到大学信息")
return
store_university_data(university_data, database_name, table_name)
display_university_data(university_data, count, template, columns)
if __name__ == '__main__':
execute_university_ranking(URL, DATABASE_NAME, TABLE_NAME, LABELS_TO_REMOVE, COLUMNS, TEMPLATE, 10)
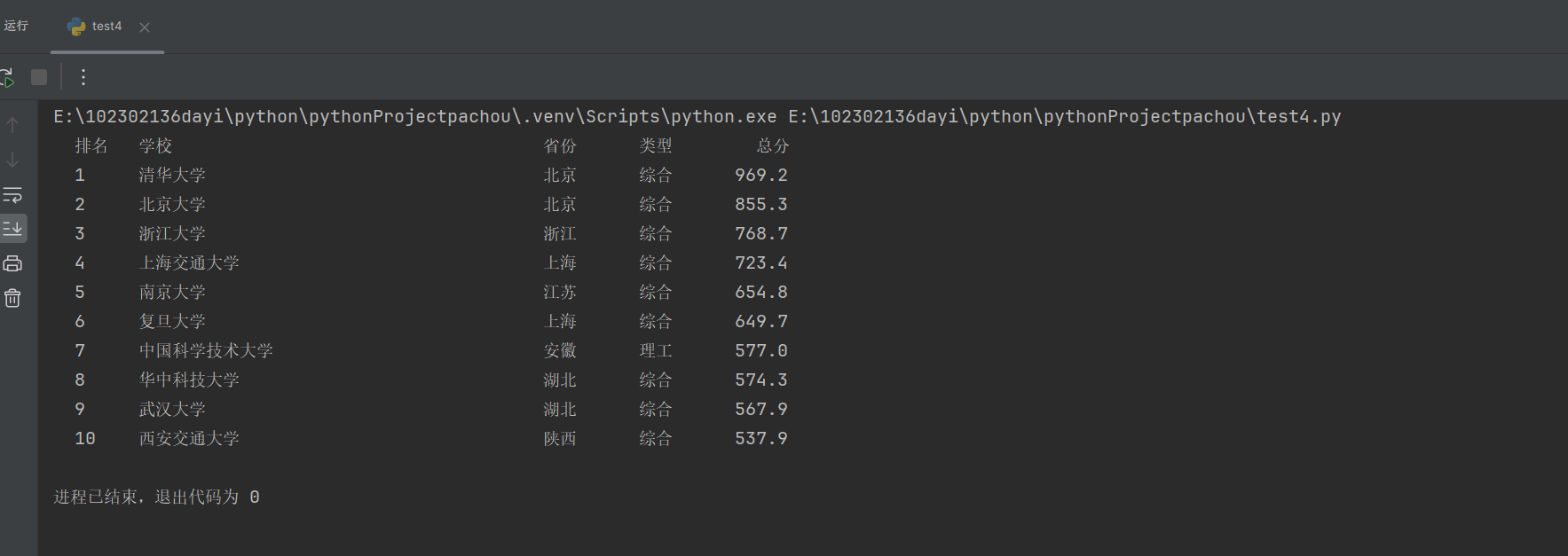
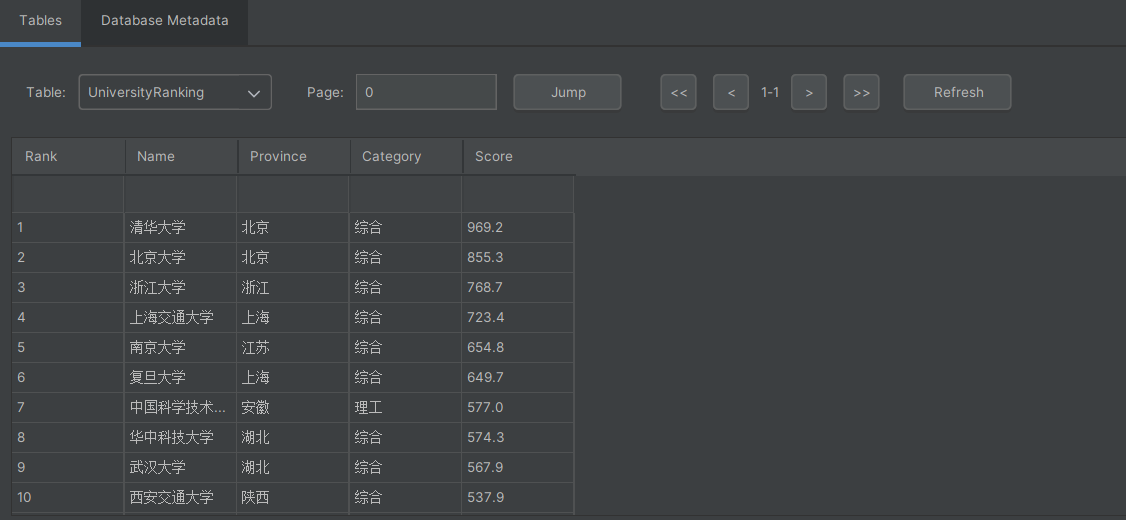
- 运行结果
![image]()
![image]()
心得体会-3
重温了用BeautifulSoup精准定位表格数据,正则表达式清理大学名称中的多余标签
代码链接:
https://gitee.com/lin-weijie123/2025_crawl_project/blob/master/作业二/3/3.py

 浙公网安备 33010602011771号
浙公网安备 33010602011771号