

最近做了小项目的性能压测,对自己设计的脚本出现的问题做个记录,给自己强加记忆。。。
一.压测内容:
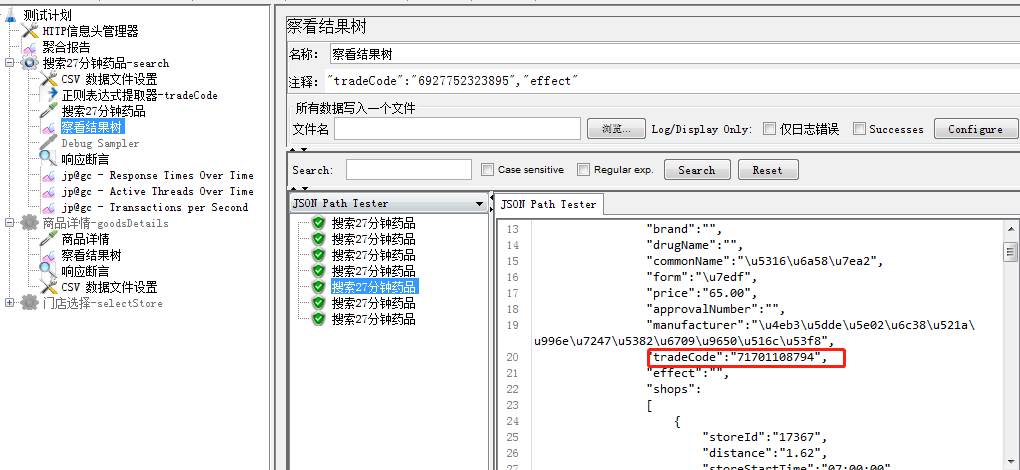
搜索27分钟药品,商品详情和门店选择,之间的关联是药品编码(tradeCode)
二.设计脚本过程出现的问题
1.药品详情接口的入参需要到搜药请求结果的tradeCode,需要用到后置处理器-正则表达式
需关注点:正则表达式应放在你要需要提取的请求里(我这是要放在搜药接口)
(1)添加正则表达式
测试计划-右击选择后置处理器-选择正则表达式
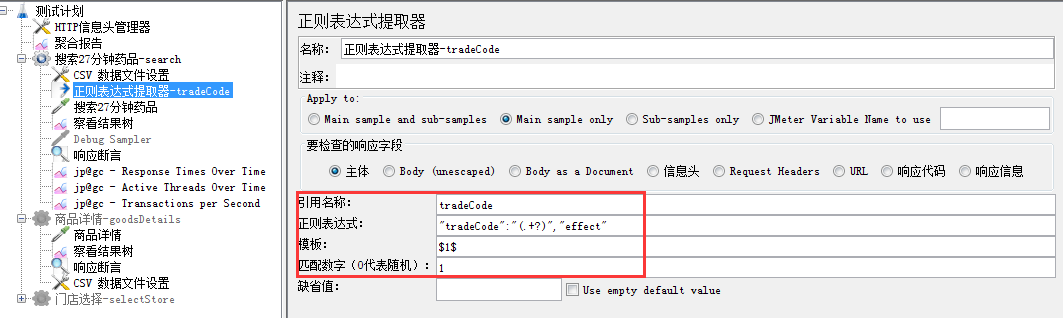
正则表达式提取说明:
<1>名称:可以编辑名称清楚提取哪个关键字段
<2>Apply to: 应用范围
<3>引用名称:其他地方引用时的变量名称,我这里写的tradeCode
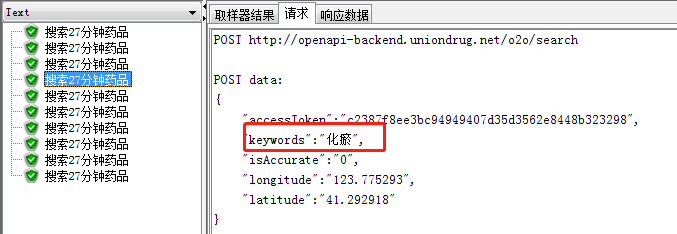
<4>正则表达式:数据提取器,()括号里为你要获取的的值。"tradeCode":"( 相当于LR左边界, )","effect"相当于LR右边界。而括号里.+?为正则表达式,用来匹配所需要获取的数据,何谓正则表达式文章末尾会附上说明
需注意:左右边界是在响应数据找到

<5>模板:用于从找到的匹配项创建字符串的模板。这是一个带有特殊元素的任意字符串,用于引用正则表达式中的组。引用组的语法是:' $ 1 $ '引用组1,' $ 2 $ '引用组2,等等。$ 0 $引用整个表达式匹配的内容。(我这里是只有一个用到:$1$)
<6>匹配数字:正则表达式匹配数据的所有结果可以看做一个数组,匹配数字即可看做是数组的第几个元素。-1表示全部,0随机,1第一个,2第二个,以此类推。若只要获取到匹配的第一个值,则填写1
<7>缺省值:匹配失败时的默认值。可以不写。若需用于后续逻辑判断,可简单写为 ERROR。
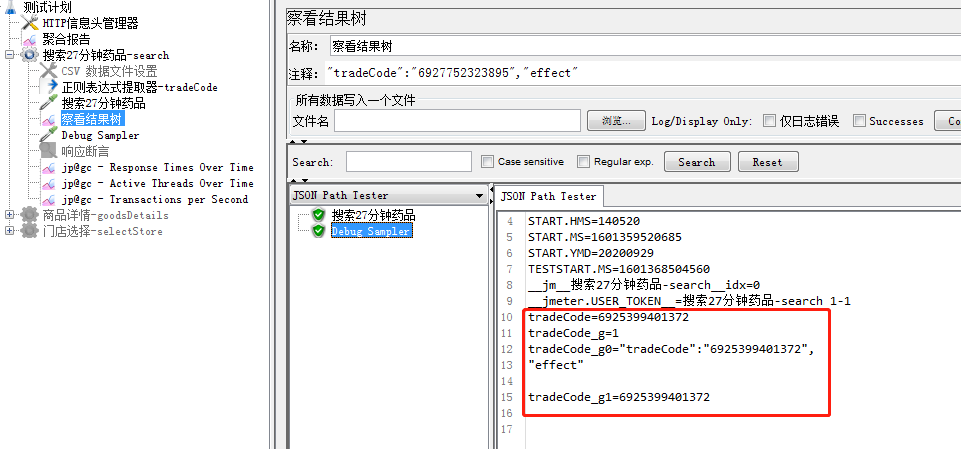
(2)在搜药里添加一个调试正则表达式:Debug PostProcessor(查看获取的变量值)
测试计划-右击选择后置处理器-Debug PostProcessor(调试的结果在响应结果看到)
(3).在商品详情请求中,将正则表达式获取的值进行引用,引用方法:${引用变量},与正则表达式的提取器名称保持一致
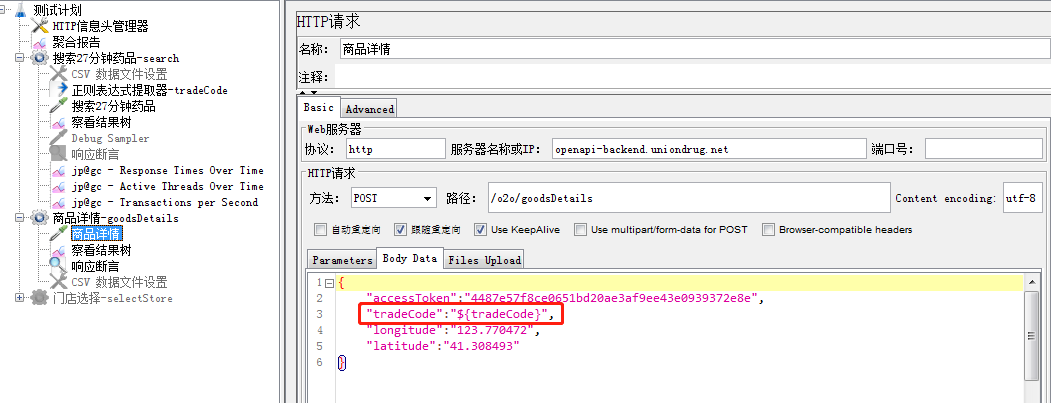
(4)最终引用正则表达式成功,且请求无报错。

小结:1.正则表达式调试器Debug PostProcessor用好就禁用掉,影响后面流程及变量引用
(我犯过错就是:调试没有关,搜药请求添加的断言失败,原因是调试的响应结果没有我要的断言变量;
商品详情里没有成功获取到搜药请求tradeCode原因是没有取调试的响应结果的变量,见上图3其实是用tradeCode_g1指代tradeCode)
2.保证响应数据是否满足预期结果,可添加断言( 断言定义:检查响应数据里是否存在特点的描述)
测试计划--右击选择断言-选择响应断言

需注意:1.模式匹配规则:如果是要断言两个变量,模式匹配规则一定要勾选上或者
2.要测试的模式:里面的变量一定去结果树的响应数据里复制,查看有没有空格,或者中文字符(我犯过错:复制postman的出现空格断言失败)
3.csv数据文件配置后(变量是中文),结果树的请求里出现乱码如何解决?
测试计划-右击配置元件-csv数据文件配置
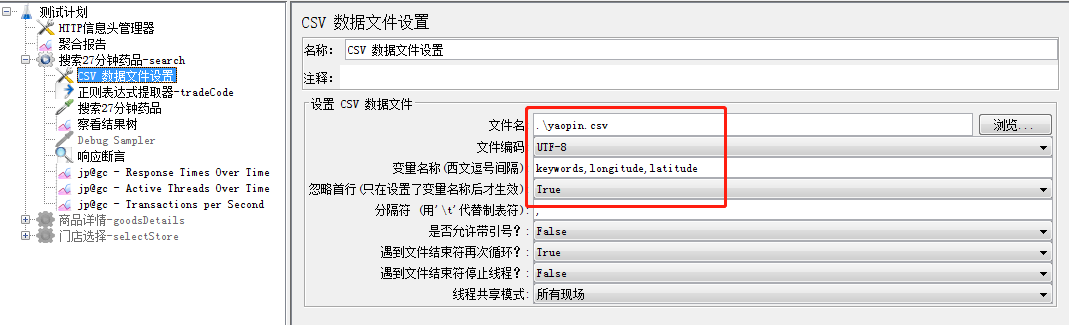
需注意:1.文件名:十分建议使用.\文件名称.csv能更方便
2.文件编码:utf-8
3.变量名称:变量之间要用英文逗号隔开,最后一个不需要的
4.忽略首行:一定要选择True(原因是csv文件头一行一般填变量名称,如果选择false,请求时带上会影响结果)
请求结果出现乱码如下:

而打开notepad++是灭有乱码的
应该从两个角度思考:
(1).jmeter 编码格式配置文件默认不开启导致的,解决方案:
1)进入jmeter-***\bin目录下,找到jmeter.properties文件,以文本文件形式打开
2)查找sampleresult.default.encoding这个参数,此行默认是注释的
#sampleresult.default.encoding=ISO-8859-1
3)将ISO-8859-1修改成utf-8,去掉注释符号
![]()
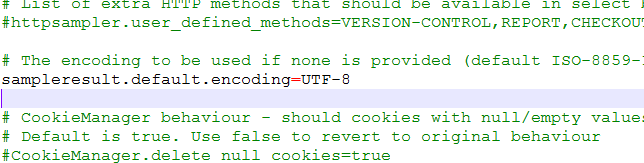
4)修改完成后,保存,并且退出jmeter重新打开,再次发送请求,查看响应数据,已解决
(2)若确认上面配置正确,那就考虑下notepad++编码配置解决方案
编码-选择‘转为UTF-8’-保存退出-运行脚本
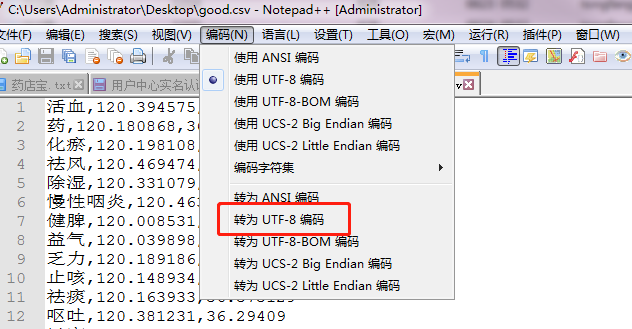
运行成功了,无乱码
附正则表达式说明:

常见两种组合:
-
【"*?" 重复任意次,但尽可能少重复
例如 "acbacb" 正则 "a.*?b" 只会取到第一个"acb" 原本可以全部取到但加了限定符后,只会匹配尽可能少的字符 ,而"acbacb"最少字符的结果就是"acb" 】
-
【"+?" 重复1次或更多次,但尽可能少重复,与"*?" 一样,只是至少要重复1次】

 浙公网安备 33010602011771号
浙公网安备 33010602011771号