


selenium元素定位之css选择器和xpath
CSS选择器(css selector)
作用:用于定位页面上的标签元素的,找到符合选择器的标签元素,然后应用样式。
语句:dr.find_element_by_css_selector("CSS选择器") —— 根据CSS选择器
(1)标签名选择器 —— 标签名
h3 选择页面上的所有h3标签
p 选择页面上的所有p标签
(2)类样式选择器 —— .类样式名
.author 选择标签上有class="author"属性的标签
(3):ID选择器 —— #ID
#ye 选择标签上有id="ye"属性的标签
(4)属性选择器 —— [属性名="属性值"] 、 [属性名]
[value="登录"] 选择标签上有value="登录"属性的标签
[type="submit"] 选择标签上有type="submit"属性的标签
(5)派生选择器
由基础选择器组合在一起
.poem p 选择p标签,但p标签必须在class="poem"的标签的里面
.poem > p 选择p标签,但p标签必须在class="poem"的标签的下一级
.poem, p 选择.poem或者p标签
XPATH定位
1. 路径定位
XPATH表达式的路径一定是从HTML文件的根开始计算的。
路径的分隔符
/ —— 进入到下一级
// —— 进入到下任意多级
.. —— 进入到上一级
XPATH表达式一定要有路径,路径分隔符后一定要有标签名,如果实在不知道是什么标签,可以用
*代表。
举例子:
//student/name 匹配所有student标签下一级的name标签
//class/* 匹配所有class标签下一级的任意标签
2:属性,函数和位置定位
(1)属性举例:
//input[@name='email'] 匹配标签上有name="email"属性的input标签
//input[@value='登 录'] 匹配标签上有value="登 录"属性的input标签
//p[@class='author'] 匹配标签上有class='author'属性的p标签
(2)函数举例:
//p[last()] 匹配所有的p标签,且这些p标签必须是其父标签下的最后1个p标签
//p[position() = 2] 匹配所有的p标签,且这些p标签必须是其父标签下的第2个p标签
//p[position() > 3] 匹配所有的p标签,且这些p标签的位置必须大于3
//a[text()='帮助'] 匹配标签内部文本等于“帮助”的a标签 ☆☆☆===》精准匹配
//a[contains(text(), 'Pow')] 匹配所有的a标签,且这些a标签的文本中必须包含“Pow”=-==》模糊匹配
//input[@id='kw' and @class='s_ipt'] 匹配所有的input标签,且这些input标签比如有id=‘kw’和class=‘s_ipt'。
同理,有not and or三种关系运算符
//标签名[@元素名称='元素值' and @元素名称='元素值']
// 标签名[@元素名称='元素值' or @元素名称='元素值']
//标签名称[@元素名称 != '元素值']
重难点===》轴定位
轴表达式说明
parent::* :表示当前节点的父节点元素
ancestor::* :表示当前节点的祖先节点元素
child::* :表示当前节点的子元素 /A/descendant::* 表示A的所有后代元素
self::* :表示当前节点的自身元素
ancestor-or-self::* :表示当前节点的及它的祖先节点元素
descendant-or-self::* :表示当前节点的及它们的后代元素
following-sibling::* :表示当前节点的后序所有兄弟节点元素
preceding-sibling::* :表示当前节点的前面所有兄弟节点元素
following::* :表示当前节点的后序所有元素
preceding::* :表示当前节点的所有元素
举例说明使用方法:
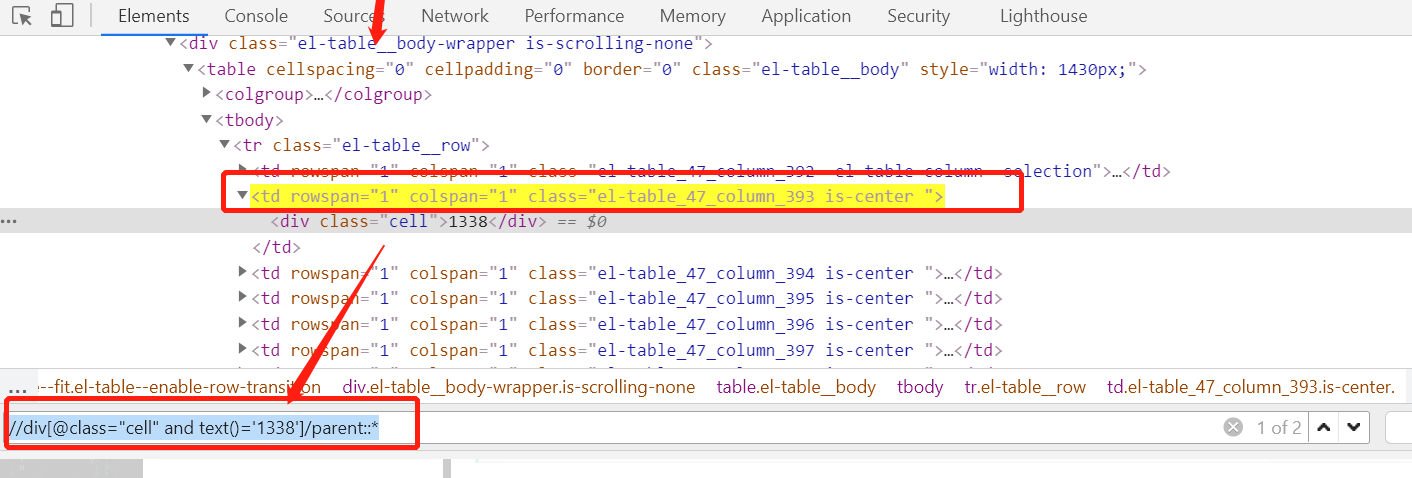
//div[@class="cell" and text()='1338']/parent::* =====》匹配该div上的所有父节点元素,如同即定位到392和393两个元素。
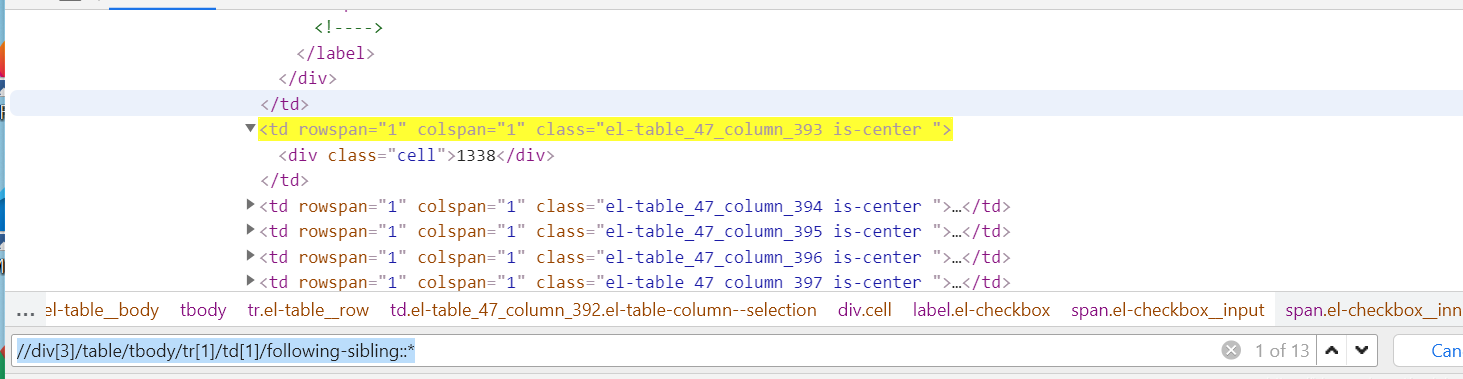
//div[3]/table/tbody/tr[1]/td[1]/following-sibling::* ===》匹配td【1】之后的所有兄弟元素,即下面13个td元素
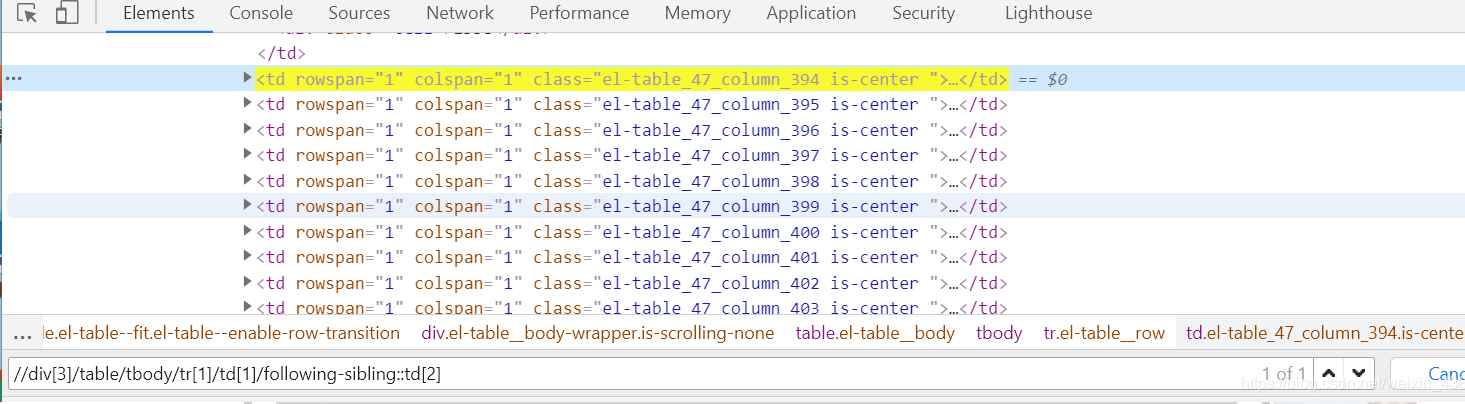
//div[3]/table/tbody/tr[1]/td[1]/following-sibling::td[2] ===》因为*是匹配所有,想要精准匹配可以接上位置索引,这个语句则是查找td[1]下同级节点下的第二个节点

 浙公网安备 33010602011771号
浙公网安备 33010602011771号