ARM Multi-core processors总结
背景
ARMv8支持多核系统,比如说一个Cortex-A57MPCore 或者 Cortex-A53MPCore的处理器可以包含一个或者四个core。ARM多核技术允许每个core并发执行,而且在空闲时允许独立睡眠。多核系统会共享很多资源比如电源、时钟、cahce,那它们共享方式以及同步方式是怎样的?
Multi-processing systems(多处理器系统)
- 包含一个核的处理器。
- 包含多核的处理器。比如多个Cortex-A53 core组成一个cluster。
- 包含多cluster的处理器。
代码跑在哪个核上?
许多软件操作依赖于运行的核,这是通过核号进行区分的。MPIDR_EL1(Multi-Processor Affinity Register),通常affinity 0代表在cluster内部的core ID,affinity 1代表cluster ID。
在EL1上运行的软件可能运行在虚拟机中。为了配置虚拟机,EL2或EL3可以在运行时将MPIDR_EL1设置为不同的值,以便特定的虚拟机看到每个虚拟核心的一致的、唯一的值。虚拟核和物理核之间的关系由hypervisor控制,可能会随时间而变化。MIPDR_EL3包含每个物理核不可更改的ID。任意个两个核的MPIDR_EL3值均不相同。
Symmetric multi-processing(SMP对称多处理器)
对称多处理(SMP)是一种软件架构,它动态地确定各个核心的角色。集群中的每个核心都有相同的内存视图和共享的硬件。任何应用程序、进程或任务都可以在任何核心上运行,操作系统调度器可以动态地在核心之间迁移任务,以实现最佳的系统负载。一个多线程应用程序可以同时运行在几个核心上。
application跑在OS上称为一个process。application会向kernel发起系统调度,每个process拥有对应的资源包括堆栈、常量、优先级。process对应为kernel视角中的一个task。thread是在相同的进程空间中执行的独立任务,它使应用程序的不同部分能够在不同的核心上并行执行。
通常,一个进程中的所有线程共享多个全局资源(包括相同的内存映射和对任何打开文件和资源句柄的访问)。线程也有它们自己的本地资源,包括它们自己的栈和寄存器使用情况,这些使用情况由内核在上下文切换时保存和恢复。然而,这些资源是本地的这一事实并不意味着任何线程的本地资源就能保证免受其他线程的错误访问。线程是单独调度的,在同一个进程中的线程也可以有不同的优先级。
SMP系统的kernel调度器会对任务做负载均衡。SMP会考虑这样的事情,在更多的核上以更低的频率运行任务,在更少的核上以更高的频率运行任务,哪种会是最佳的功耗和性能平衡的场景。中断处理也可以在各个核心之间实现负载均衡。这可以帮助提高性能或节省能源。在核心之间平衡中断或为特定类型的中断保留核心可以减少中断延迟。kernel不支持自动的中断负载均衡,但是kernel提供了绑定中断的机制。有一些开源项目,如irqbalance (https://github.com/Irqbalance/irqbalance),它们使用绑定中断机制安排中断的分布。Irqbalance知道系统属性,比如共享缓存层次结构(哪些核心具有公共缓存)和电源域布局(哪些核心可以独立关闭)。
Timer(时钟)
支持SMP的操作系统内核通常有一个任务调度器,负责在多个任务之间对核心上进行时间分片。它动态地确定各个任务的优先级,并决定在每个核心上下一步运行哪个任务。为了周期性地中断每个核心上的活动任务,通常需要一个计时器,让调度器有机会选择不同的任务。
当所有核心都竞争相同的关键资源时,可能会出现问题。每个核心运行调度器来决定它应该执行哪个任务,这以固定的间隔发生。内核调度器代码需要使用一些共享数据,比如任务列表,可以通过排除(由互斥锁提供)对其进行保护,防止并发访问。
系统计时器体系结构描述了一个通用的系统计数器,它为每个核心提供了最多四个计时器通道。这个系统计数器时钟频率是固定的。有安全物理计时器和非安全物理计时器以及两个用于虚拟化目的的计时器。每个通道都有一个比较器,它比较系统范围内的64位计数,从0开始计数。你可以配置计时器,以便当计数大于大于或等于编程的比较器值时产生中断。虽然系统计时器必须有固定的频率(通常是MHz),但允许变化的更新粒度。这意味着,不是在每个时钟滴答上增加1的计数,而是可以在每10或100个周期中相应地以减少的速率增加计时器更大的数量,如10或100。这提供了同样有效的频率,但减少了更新的粒度。这对于实现低功耗状态很有用。
CNTFRQ_EL0寄存器报告系统定时器的频率。一个常见的误解是CNTFRQ_EL0由所有核心共享,其实这个寄存器是per core的。所有软件看到这个寄存器已经初始化为正确值在所有核上。计数器频率是全局的,对所有核心都是固定的。CNTFRQ_EL0为bootrom或固件提供了一种方便的方式来告诉其他软件全局计数器频率是多少,但是不控制硬件行为的任何方面。
CNTPCT_EL0寄存器报告当前的计数值。CNTKCTL_EL1控制EL0是否可以访问系统定时器。配置定时器的步骤如下:
1 )将比较器值写入64位寄存器CNTP_CVAL_EL0。
2) 在CNTP_CTL_EL0中使能计数器和中断生成
3) 轮询CTP_CTL_EL0以报告EL0定时器中断的原始状态。
您可以使用系统计时器作为倒计时计时器。在本例中,所需的计数被写入到32位的CNTP_TVAL_EL0寄存器。硬件为您计算正确的CNTP_CVAL_EL0值。
Synchronization(同步)
ARM架构提供了三条与独占访问相关的指令(读、写、清),以及这些指令的变体,它们操作字节、半字、字或双字大小的数据。指令依赖于核心或内存系统的能力来标记特定地址,以便由该核心使用独占访问监视器进行独占访问监视。
指令依赖于core或内存系统的能力,以便该core可以独占访问标记的特定地址,。这些指令的使用在多核系统中很常见,但在单核系统中也可以找到,用于实现运行在同一核心上的线程之间的同步操作。
LDXR执行读取内存,但也标记物理地址,以便由该核心进行独占访问。STXR执行一个条件写内存,只有当目标位置被标记为被该核心监控的独占访问时才成功。如果存储不成功,这个指令在通用寄存器Ws中返回非零,如果存储成功,则的值为0。在汇编程序语法中,它总是被指定为W寄存器,也就是说,不是X寄存器。此外,STXR清除独占标记。
1. Load Exclusive (LDXR): LDXR W|Xt, [Xn]
2. Store Exclusive (STXR): STXR Ws, W|Xt, [Xn] where Ws indicates whether the store
completed successfully. 0 = success.
3. Clear Exclusive access monitor (CLREX) This is used to clear the state of the Local Exclusive Monitor.
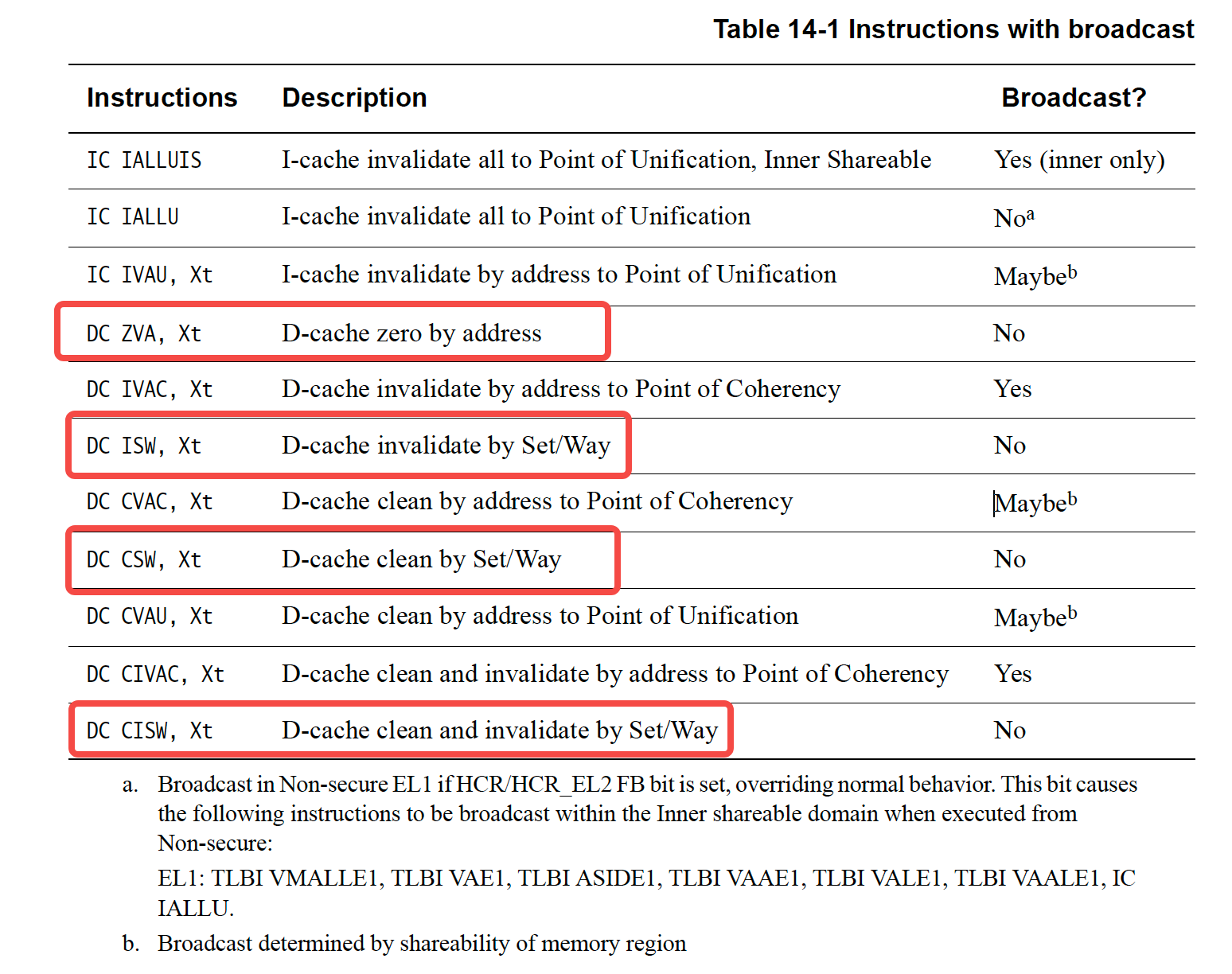
Load exclusive和store exclusive操作只保证在普通内存中起作用,以下所有属性的普通内存均可:
• Inner or Outer Shareable.
• Inner Write-Back.
• Outer Write-Back.
• Read and Write allocate hints.
• Not transient.
每个核心只能标记一个地址。独占监视器并不阻止其他核心或线程读写所监视的位置,而是简单地监视自LDXR以来该位置是否已被写入。
Asymmetric multi-processing(AMP非对称多处理器)
在多核处理器上实现AMP系统的原因可能包括安全性、实时性,或者因为单个核专用于执行特定的任务。
非对称多处理 (AMP) 系统使您能够为cluster内的每个核心静态分配角色,这样实际上,每个核心执行单独任务。这被称为功能分布软件架构,通常意味着在各个核心上运行单独的操作系统。该系统可以认为是一个为某些关键系统配备专用加速器的单核系统服务。 AMP不是指任务或中断绑定特定的核心。在 AMP 系统中,每个任务可以有不同的内存视图,不能再AMP之间进行负载均衡。此类系统的硬件缓存一致性没有要求。
有一些系统同时具有SMP和AMP特性。这意味着有两个或更多的核心运行一个SMP OS,其他核心运行独立的OS。
独立的核心需要一些同步机制,可以通过消息通信协议Multicore Communications Association API (MCAPI),基本上就是门铃机制+共享内存来实现消息收发。
Heterogeneous multi-processing(HMP异构多处理器)
ARM用HMP来表示一个由应用处理器集群组成的系统,这些处理器在指令集架构上100%相同,但在微架构上却非常不同。所有处理器都是完全缓存一致的,并且是同一个一致性域的一部分。ARM的big.LITTLE架构就是HMP的实现。在一个big.LITTLE系统,节能的LITTLE核心与高性能大核心相结合,形成一个系统。
Exclusive monitor system location
典型的多核系统可能包括多个独占监视器。每个核心都有自己的本地监视器,并且有一个或多个全局监视器。翻译表项的可共享和可缓存属性与用于独占指令的位置相关,从而决定了使用哪一个独占监视器。
在硬件中,核心包括一个名为本地监视器的设备。这个监视器观察核心。当核心执行独占加载访问时,它将在本地监视器中记录这一事件。当它执行独占存储时,它检查之前的独占加载是否执行,如果没有执行,则独占存储失败。核心一次只能标记一个物理地址。
本地独占监视器在每次异常返回时(即在ERET指令执行时)被清除。在Linux内核中,多个任务在EL1的内核上下文中运行,并且可以进行上下文切换。只有当我们返回到与内核任务相关的用户空间线程时,才会执行异常返回。这与ARMv7架构不同,内核任务调度器必须显式地清除每个任务开关上的独占访问监控器。
本地监视器使用场景:当用于独占访问的位置标记为不可共享时,即仅在同一个核心上运行的不同线程,将使用本地监视器。例如线程A发起独占load后,中断导致同一核心上的另一线程B也发起了独占load,这时就会使用本地监视器。本地监视器还可以处理将访问标记为内部可共享的情况,例如,保护可共享域中任何核心上运行的SMP线程之间共享资源的互斥锁。全局监视器使用场景:对于运行在不同的、非一致的核心上的线程,互斥锁的位置被标记为正常的、不可缓存的,并且需要在系统中使用全局访问监视器。
系统可能不包含全局监视器,或者全局监视器可能只对某些地址区域可用。如果执行独占访问的位置在系统中没有合适的监视器,会发生什么情况,这是由IMPLEMENTATION定义的。一些允许的选项:指令产生External Abort,MMU fault,NOP,排他指令被当做简单的读写指令。
独占监视器的粒度Exclusives Reservation Granule (ERG)是IMPLEMENTAION DEFINED,但通常是一条缓存行cache line。它给出监视器区分它们的最小地址间距。在单个ERG中放置两个互斥量可能会导致错误,对其中一个互斥量执行STXR指令会清除这两个互斥量的独占标记。这个ERG限制可能会降低效率。特定核心上独占监视器的ERG大小可以从缓存类型寄存器CTR_EL0中读取。
Cache coherency
Cortex-A53和Cortex-A57处理器支持集群中不同核心之间的一致性管理。这需要用正确标记地址区域的可共享属性。允许构建包含多cluster的系统,这样的系统级一致性需要一个缓存相干互连,例如ARM CCI-400,它实现了AMBA 4 ACE总线规范。例如下图的一致性总线。
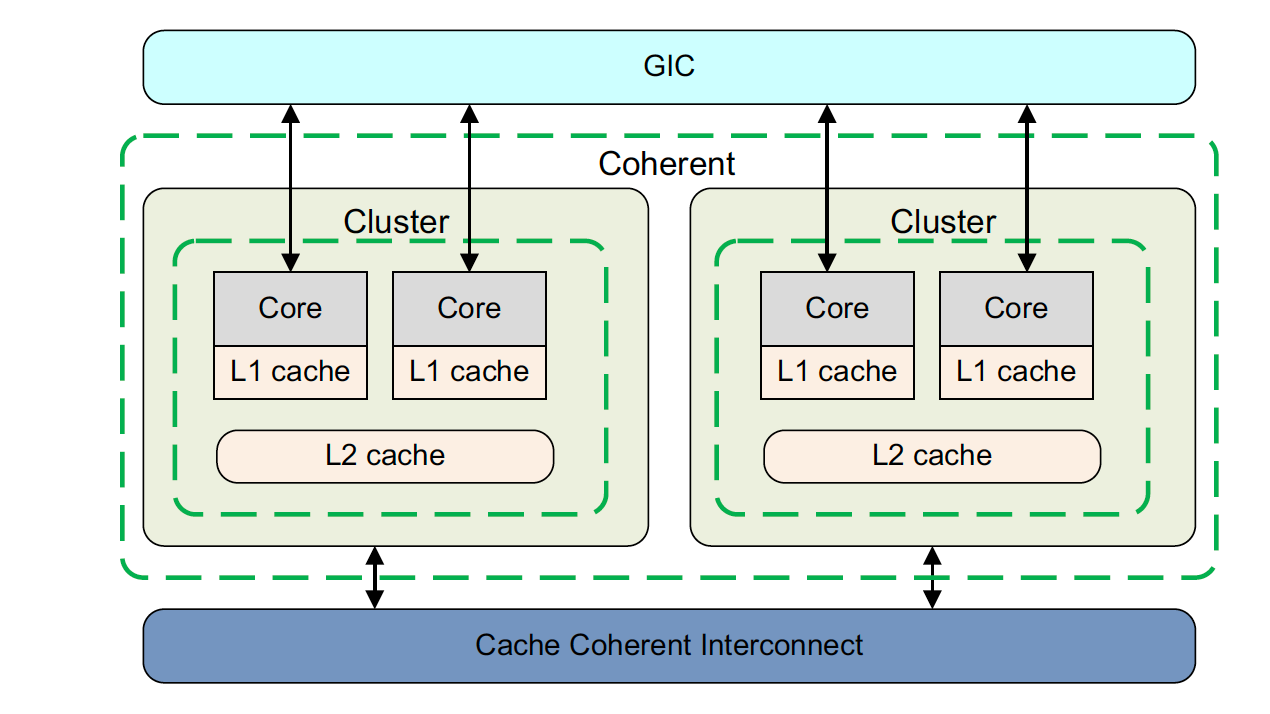
系统中的一致性支持取决于硬件设计决策和存在许多可能的配置。例如,一致性只能在单个cluster中得到支持。一个big.LITTLE系统可能内部域包括两个集群的核心,或者是一个多cluster系统,其中内部域包括一部分cluster,外部域包括其他cluster。
除了维护缓存之间数据一致性的硬件之外,你必须能够在一个核心上广播缓存一致性操作到系统其他部分。 有的硬件配置信号,在复位是采样,它控制是广播内部还是外部或两个缓存维护操作,以及是否广播系统屏障指令。AMBA 4 ACE协议允许向其他master发送屏障信号,以便维护和一致性操作的顺序得到维护。Interconnect逻辑可能需要通过引导代码进行初始化。
对于普通可缓存区域,这意味着将可共享属性设置为不可共享、内部可共享或外部可共享中的一个。对于不可缓存的区域,可共享的属性将被忽略。缓存操作可能需要广播到互连。这意味着一个核心上的软件可以向一个地址发出缓存清除或无效操作,该地址目前可能存储在持有该地址的另一个核心的数据缓存中。当一个维护操作通过广播时,特定共享性域中的所有内核执行该操作。SMP系统依赖这些操作进行同步。
Multi-core cache coherency within a cluster(多核cache一致性)
一致性意味着确保系统中所有的处理器或总线master具有共享内存的相同视角。这意味着对一个核心缓存中保存的数据进行修改对于其他核心是可见的,这使得核心不可能看到过时的或旧的数据副本。
- 软件管理的一致性
软件管理的一致性是处理数据共享的一种更常见的方法。一般,设备驱动程序必须清除缓存中的脏数据或使旧数据失效。这增加了耗时以及软件的复杂性,并且在共享率很高的情况下会降低性能。 - 硬件管理的一致性
硬件维护cluster内level 1数据缓存之间的一致性。核心在上电后自动参与一致性方案,启用D-cache和MMU,并将一个地址标记为相干的。然而,这种缓存一致性逻辑并不维护数据和指令缓存之间的一致性。在ARMv8-A体系结构和相关实现中,一般都使用硬件管理的一致方案。这为互连和集群增加了一些硬件复杂性,但极大地简化了软件。
缓存一致性方案可以通过多种标准方式进行操作。ARMv8处理器使用MOESI协议。ARMv8处理器也可以连接到AMBA 5 CHI互连,其缓存一致性协议类似(但不完全相同)MOESI。根据使用的协议,SCU用以下属性之一标记缓存中的每一行:M(修改的)、O(拥有的)、E(独占的)、S(共享的)或I(无效的)。其他类似协议还有MSI、MOSI、MESI等,https://en.wikipedia.org/wiki/MOESI_protocol
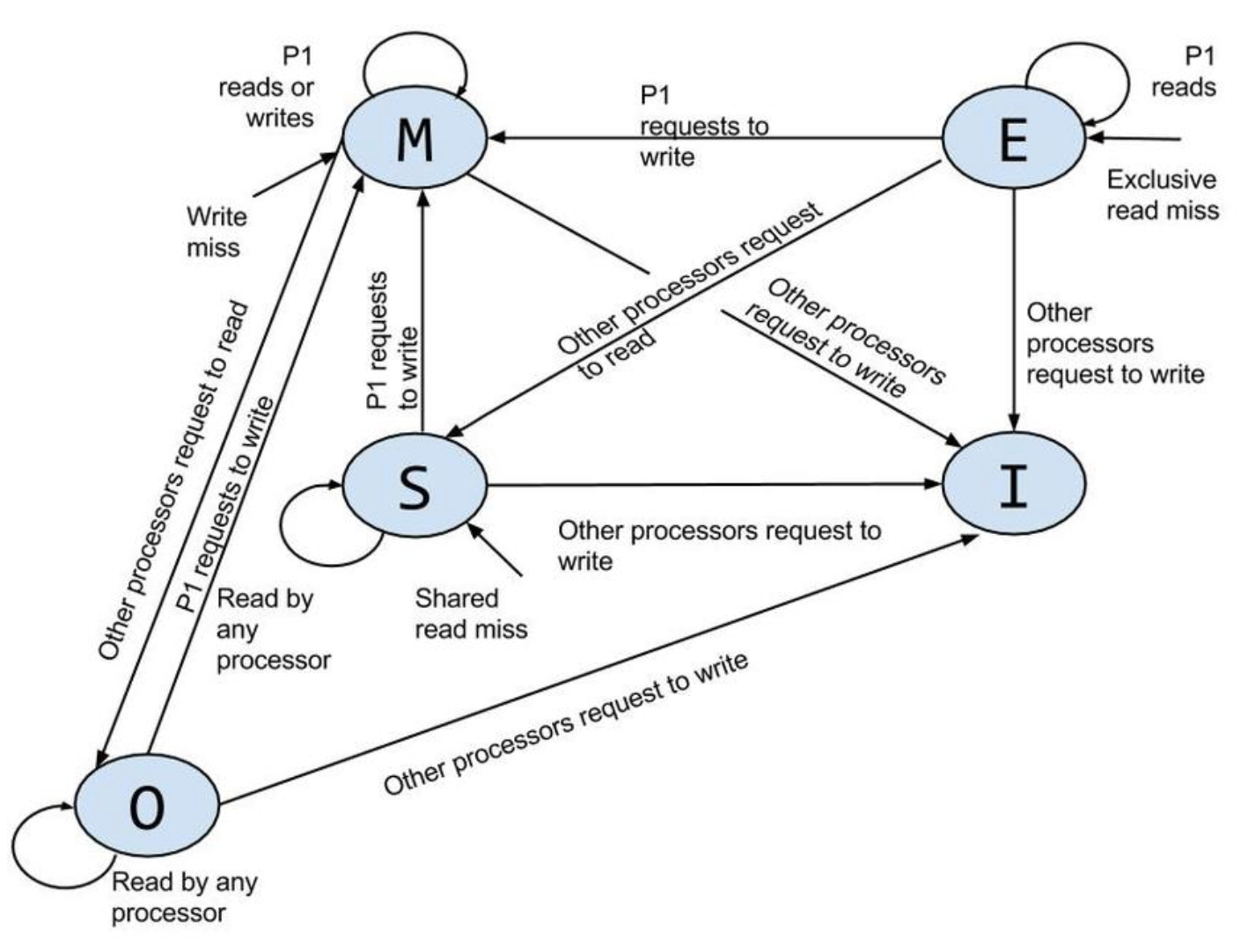
SCU
处理器cluster包含一个Snoop Control Unit (SCU),它包含存储在各个L1数据缓存标记的副本。
- 维护L1数据缓存之间的一致性。
- 仲裁对L2接口的访问,包括指令和数据。
- 包括tag RAM以跟踪每个核心分配的数据。
SCU是通过位于私有内存区域中的控制寄存器启用的。每个核心可以单独配置,以参与或不参与数据缓存一致性管理方案。处理器内部的SCU自动维护cluster内部level 1的缓存一致性。SCU只能在单个cluster内保持一致性。如果系统中有额外的处理器或其他总线master,就需要显式的软件同步。
Accelerator coherency port
SCU拥有与AMBA 4 AXI兼容的从接口为主机提供了一个连接点,
- 该接口支持所有标准的读写事务,而不需要额外的一致性要求。但是,任何到内存的一致区域的读事务都会与SCU交互,以测试信息是否已经存储在L1缓存中。
- SCU在执行写到系统内存的强制一致性,可能分配到L2缓存,消除直接写到片外内存的功率和性能影响。
Cache coherency between clusters
系统还可以包含PMU硬件来维护集群之间的一致性。集群可以动态地从一致性管理中添加或删除,例如,当整个集群(包括L2缓存)关闭电源时。操作系统可以通过内置的性能监视单元(Performance Monitoring Units,pmu)监视上的活动。
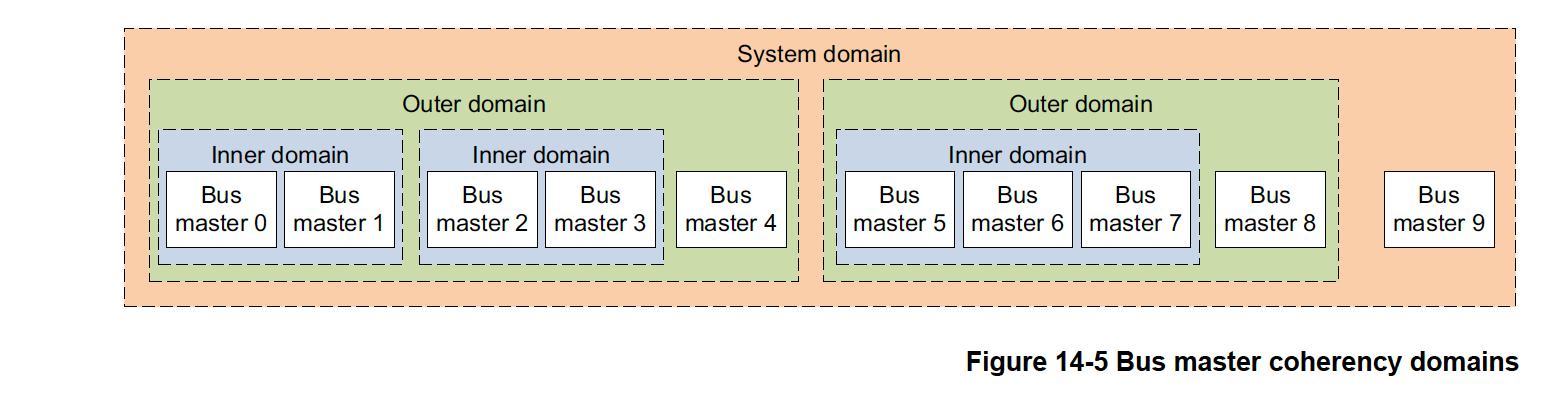
Domain
在ARMv8-A体系结构中,术语domain用于指一组总线上的master。domain决定snoop哪些master,以便进行一致性处理。snooping是对master的缓存进行检查,以查看请求的位置是否存储在那里。有四个定义的domain类型:
- Non-shareable.
- Inner Shareable.
- Outer Shareable.
- System.
典型的系统使用情况是,在相同操作系统下运行的master位于相同的Inner Shareable域中。不那么紧密地耦合的master在同一个Outer Shareable域中。内存访问的domain选择是通过页面表中的项来控制的。
Bus protocol and the Cache Coherent Interconnect(总线协议和cache一致性互联)
将硬件一致性扩展到多集群系统需要一个一致性的总线协议。AMBA 4 ACE规范包括AXI一致性扩展(ACE)。完整的ACE接口支持集群之间的硬件一致性,并使SMP操作系统能够在多个核上运行。如果你有多个集群,那么在一个集群中对内存的共享访问都可以窥探其他集群的缓存,以查看数据是否在那里,或者是否必须从外部内存加载数据。AMBA 4 ACE-Lite接口是全接口的一个子集,专为单向IO相干系统master设计,如DMA引擎、网络接口和gpu。这些设备可能没有自己的缓存,但可以从ACE处理器读取共享数据。用于non-core master的缓存通常不与core的缓存保持一致。例如,在许多系统中,core无法窥探GPU的缓存内部。但反过来是可以的。
ACE-Lite允许其他主机窥探其他集群的缓存内部。这意味着,对于可共享位置,必要时将从一致缓存中完成读取,而可共享的写将从一致缓存线中合并为强制清理并使其失效。ACE规范允许TLB和I-Cache维护操作广播到所有能够接收它们的设备。数据屏障被发送到从接口,以确保它们编程上是完整的。
CoreLink CCI-400缓存相干接口是AMBA 4 ACE的第一个实现IP,支持最多两个ACE集群,使最多8个核能够看到相同的内存视图,并运行SMP操作系统,例如,一个big.LITTLE系统,Cortex-A57处理器和Cortex-A53处理器。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号