

google、baidu、yahoo、bing这些搜索引擎网站的图片抓取方法汇总
icrawler基本用法
内置爬虫
该框架包含6个内置的图像抓取工具。
-
谷歌
-
bing
-
百度
-
Flickr
-
通用网站图片爬虫(greedy)
-
UrlList(抓取给定URL列表的图像)
以下是使用内置抓取工具的示例。 搜索引擎抓取工具具有相似的界面。
第一步:
pip install icrawler
第二步:
from icrawler.builtin import BaiduImageCrawler
from icrawler.builtin import BingImageCrawler
from icrawler.builtin import GoogleImageCrawler
"""
parser_threads:解析器线程数目,最大为cpu数目
downloader_threads:下载线程数目,最大为cpu数目
storage:存储地址,使用字典格式。key为root_dir
keyword:浏览器搜索框输入的关键词
max_num:最大下载图片数目
"""
#谷歌图片爬虫
google_storage = {'root_dir': '/Users/suosuo/Desktop/icrawler学习/google'}
google_crawler = GoogleImageCrawler(parser_threads=4,
downloader_threads=4,
storage=google_storage)
google_crawler.crawl(keyword='beauty',
max_num=10)
#必应图片爬虫
bing_storage = {'root_dir': '/Users/suosuo/Desktop/icrawler学习/bing'}
bing_crawler = BingImageCrawler(parser_threads=2,
downloader_threads=4,
storage=bing_storage)
bing_crawler.crawl(keyword='beauty',
max_num=10)
#百度图片爬虫
baidu_storage = {'root_dir': '/Users/suosuo/Desktop/icrawler学习/baidu'}
baidu_crawler = BaiduImageCrawler(parser_threads=2,
downloader_threads=4,
storage=baidu_storage)
baidu_crawler.crawl(keyword='美女',
max_num=10)
注:google页面升级,上面方法暂时不可用
GreedyImageCrawler
如果你想爬某一个网站,不属于以上的网站的图片,可以使用贪婪图片爬虫类,输入目标网址。
from icrawler.builtin import GreedyImageCrawler
storage= {'root_dir': '/Users/suosuo/Desktop/icrawler学习/greedy'}
greedy_crawler = GreedyImageCrawler(storage=storage)
greedy_crawler.crawl(domains='http://desk.zol.com.cn/bizhi/7176_88816_2.html',
max_num=6)
UrlListCrawler
如果你已经拥有了图片的下载地址,可以直接使用UrlListCrawler,为了高效抓取,可以使用多线程方式下载,快速抓取目标数据。
from icrawler.builtin import UrlListCrawler
storage={'root_dir': '/Users/suosuo/Desktop/icrawler学习/urllist'}
urllist_crawler = UrlListCrawler(downloader_threads=4,
storage=storage)
#输入url的txt文件。
urllist_crawler.crawl('url_list.txt')
详细:https://www.ctolib.com/topics-125069.html
google抓取
我们在上面提到google图片无法抓取,然后我们接着往下面看看方法。
链接:https://pan.baidu.com/s/1gunLzHq4B-d-oPorzHiU3g
提取码:e5na
先去我的网盘下载到本地,接着看目录结构,注意抓取goole用的是 selenium,这个包安装方法及环境设置需要自己搞定!!!
运行看看页面,是可视化的哦
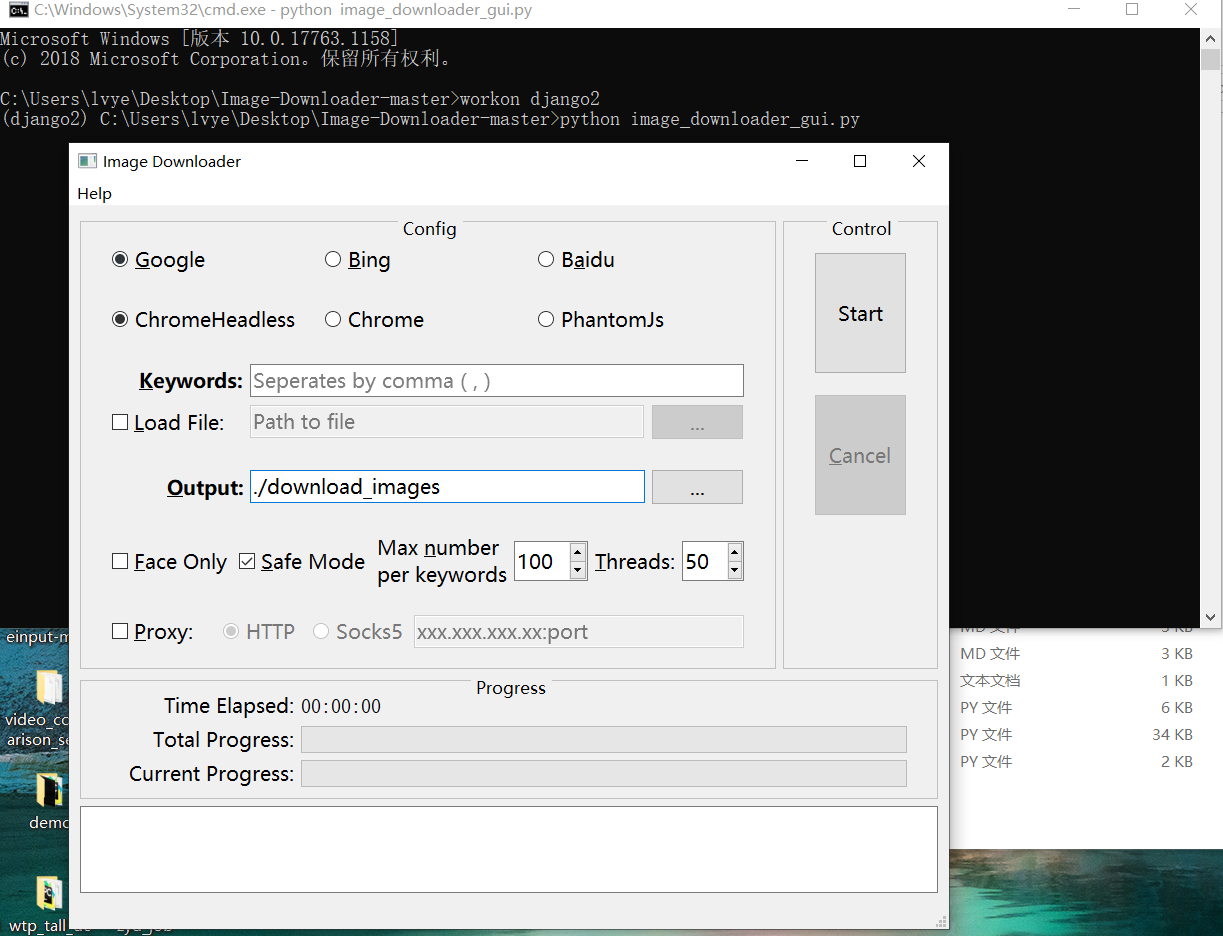
当然,这个你还有什么看不懂的直接到github上看看,https://github.com/sczhengyabin/Image-Downloader,亲测可用。
yahoo抓取
mport requests
import re
import os
class Yahoo_spider():
def __init__(self):
self.headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36",
}
self.keyword = "诈骗信息"
self.path = ''
self.count = 0
self.max_page = 700
def start_one_parse(self):
"""该请求为第一页静态数据"""
print('开始抓取第1页')
url = 'https://images.search.yahoo.com/search/images;_ylt=Awr9FqqfDqVeFy4AT7SJzbkF?p='+ self.keyword +'&fr2=p%3As%2Cv%3Ai'
response = requests.get(url = url,headers = self.headers)
pic_list = re.findall(r'data-src=\'(.*?)\'', response.text, re.S)
self.save_pic(pic_list)
def start_two_parse(self):
"""请求第二页为动态接口数据"""
for page in range(61,self.max_page,61):
print('开始抓取第{}页'.format(page // 61 + 1))
url = "https://images.search.yahoo.com/search/images?fr2=p%3As%2Cv%3Ai&o=js&p="+self.keyword+"&tmpl=&nost=1&b="+str(page)+"&iid=Y.2&ig=0afd1ebeedac47e896000000003f9432&rand=1587876278637"
response = requests.get(url=url, headers=self.headers).json()['html']
pic_list = re.findall(r'data-src=\'(.*?)\'', response, re.S)
self.save_pic(pic_list)
def save_pic(self,pic_list):
"""保存图片"""
for pic in pic_list:
try:
self.count += 1
url = pic.replace('&w=300&h=300', '&w=10000&h=10000') #处理尺寸
pic_path = os.path.join(self.path,'yahoo_'+ str(self.count) + '.jpg')
response = requests.get(url=url,headers = self.headers,timeout = 10)
with open(pic_path,'wb') as f:
f.write(response.content)
print('序号:{},图片链接;{},保存成功'.format(self.count,url))
except:
pass
if __name__ == '__main__':
spider = Yahoo_spider()
spider.start_one_parse()
spider.start_two_parse()
yahoo没什么难度,看看代码很简单就懂了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号