

配置BeautifulSoup4+lxml+html5lib
序
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间。
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,其中一个是 lxml 。
另一个可供选择的解析器是纯Python实现的 html5lib , html5lib的解析方式与浏览器相同。

Windows平台 + Python3.5
安装BeautifulSoup4
方法一:打开cmd,运行pip install BeautifulSoup4

如上图所示,由于我已经安装过了。可以使用 --upgrade来升级为最新版本。
方法二:去官网BeautifulSoup4源码下载 -- 戳我吧!下载源码,编译运行。
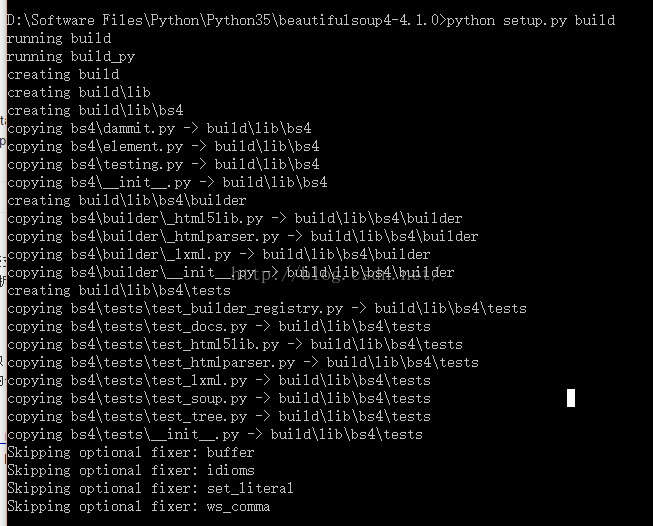
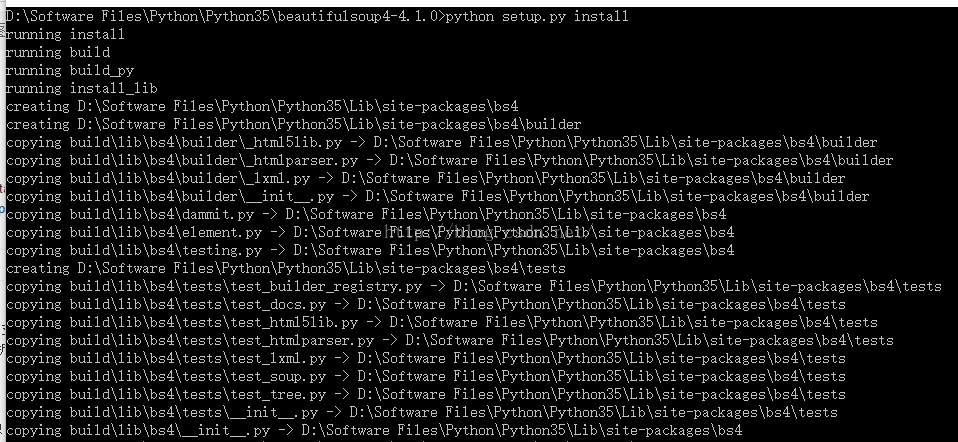
至此,便安装完毕。
验证成功,编译一个.py文件,输入from bs4 import BeautifulSoup4,不会报错即代表安装成功。
安装html5lib
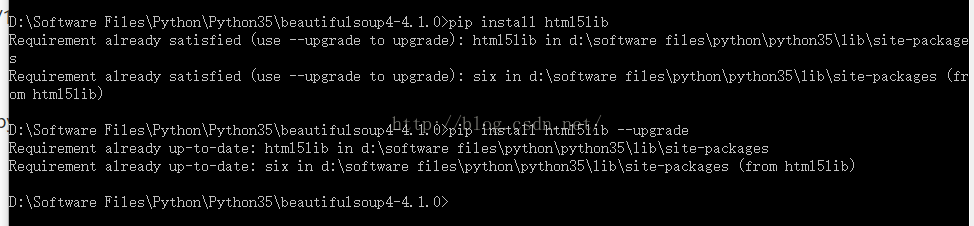
第二步,我们安装网页文件解析器htm5lib,只需直接运行pip install html5lib即可:
安装lxml
在Windows下,安装lxml费了一点劲儿,不能直接通过命令成功安装。我们需要去官方网站下载与平台完全一致的版本,手动安装。
首先,查看我们的平台依赖的工具版本:
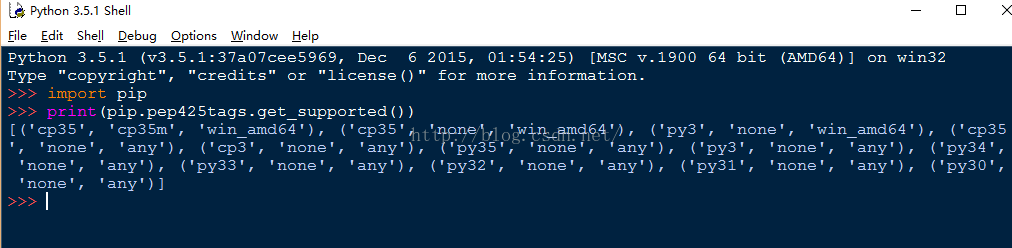
然后,去官网下载对应的.whl文件。lxml 官方下载链接,请猛戳我~~~
Ctrl + F,输入lxml,找到下面这段:
Lxml, a binding for the libxml2 and libxslt libraries.
lxml‑3.4.4‑cp27‑none‑win32.whl
lxml‑3.4.4‑cp27‑none‑win_amd64.whl
lxml‑3.4.4‑cp33‑none‑win32.whl
lxml‑3.4.4‑cp33‑none‑win_amd64.whl
lxml‑3.4.4‑cp34‑none‑win32.whl
lxml‑3.4.4‑cp34‑none‑win_amd64.whl
lxml‑3.4.4‑cp35‑none‑win32.whl
lxml‑3.4.4‑cp35‑none‑win_amd64.whl
cp后面是Python的版本号,27表示2.7,根据你的Python版本选择下载。
Lxml, a binding for the libxml2 and libxslt libraries.
lxml‑3.4.4‑cp27‑none‑win32.whl
lxml‑3.4.4‑cp27‑none‑win_amd64.whl
lxml‑3.4.4‑cp33‑none‑win32.whl
lxml‑3.4.4‑cp33‑none‑win_amd64.whl
lxml‑3.4.4‑cp34‑none‑win32.whl
lxml‑3.4.4‑cp34‑none‑win_amd64.whl
lxml‑3.4.4‑cp35‑none‑win32.whl
lxml‑3.4.4‑cp35‑none‑win_amd64.whl
cp后面是Python的版本号,27表示2.7,根据你的Python版本选择下载。
最后进行安装,打开cmd,先运行pip install wheel安装wheel工具,做好准备工作。
接着运行pip install *.whl文件,我的对应版本为lxml-3.6.0-cp35-cp35m-win_amd64.whl即可成功安装lxml解析器。
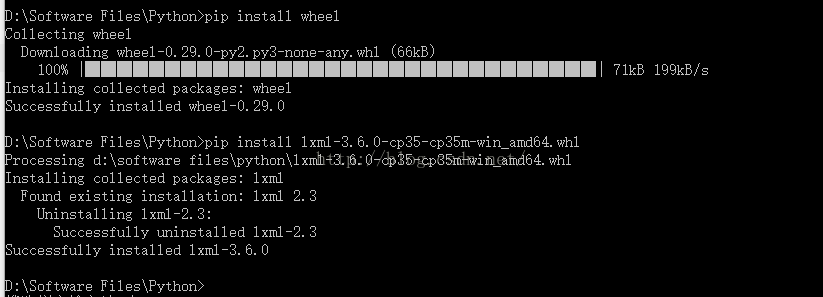
至此,三个工具都安装完毕。
对于Linux平台下,安装就很简单了,直接利用三个命令即可完成:
- pip install BeautifulSoup4 或 easy_install BeautifulSoup4
- pip install html5lib
- pip install lxml
使用BeautifulSoup
我们编辑一段html文档,利用BeautifulSoup库进行解析:
-
html = """
-
<html><head><title>The Dormouse's story</title></head>
-
<body>
-
<p class="title"><b>The Dormouse's story</b></p>
-
-
<p class="story">Once upon a time there were three little sisters; and their names were
-
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
-
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
-
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
-
and they lived at the bottom of a well.</p>
-
-
<p class="story">...</p>
-
"""
-
-
from bs4 import BeautifulSoup
-
-
#添加一个解析器
-
soup = BeautifulSoup(html,'html5lib')
-
print(soup.title)
-
print(soup.title.name)
-
print(soup.title.text)
-
print(soup.body)
-
-
#从文档中找到所有<a>标签的内容
-
for link in soup.find_all('a'):
-
print(link.get('href'))
-
-
-
#从文档中找到所有文字内容
-
print(soup.get_text())
在声明BeautifulSoup对象的时候要明确解析器 soup = BeautifulSoup(html,'html5lib'),否则写为 soup = BeautifulSoup(html) 会有警告。
运行上述代码:
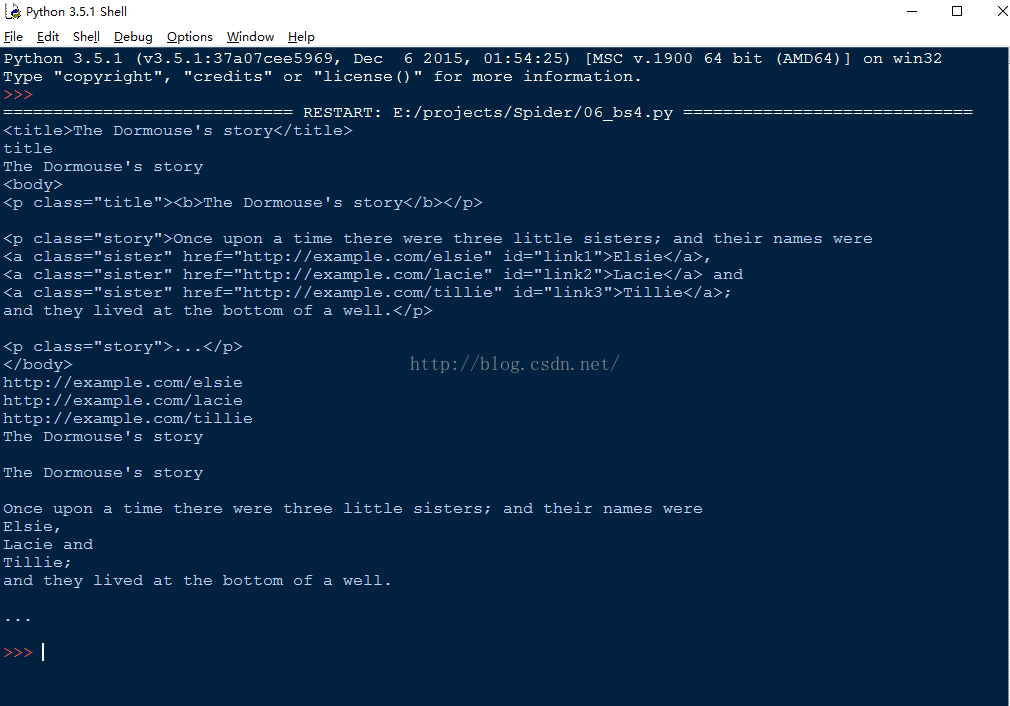
我们发现,BeautifulSoup可以十分方便的提取Html的结构化数据。这就为我们解析网页文件内容,爬取目标元素提供了极大的帮助。
这只是一个小小的例子,BeautifulSoup库的功能十分强大,赶紧去官方文档学习吧~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号