大语言模型能力评估
根据标准答案评估




https://arxiv.org/abs/2009.03300

https://huggingface.co/blog/evaluating-mmlu-leaderboard


把正确答案都移动到A的话,测试结果又不一样:



BLEU,ROUGE是两款不同的工具
人类评估语言模型
大语言模型评比网站Chatbot Arena
https://lmarena.ai/(原网址https://chat.lmsys.org/ )

模型比拼排行榜
https://lmarena.ai/leaderboard

并且支持各种类型模型的排行榜:

语言模型来评估语言模型
https://arxiv.org/abs/2305.01937
https://arxiv.org/abs/2310.05657

- MT-Bench
https://arxiv.org/abs/2306.05685

Arena-Hard
https://lmsys.org/blog/2024-04-19-arena-hard/
https://github.com/tatsu-lab/alpaca_eva
各个不同领域测评
大型語言模型本身会不会偏袒特定类型的答案?
https://arxiv.org/abs/2404.04475

各种NLP评估数据集中的任务数量:
https://arxiv.org/abs/2204.07705
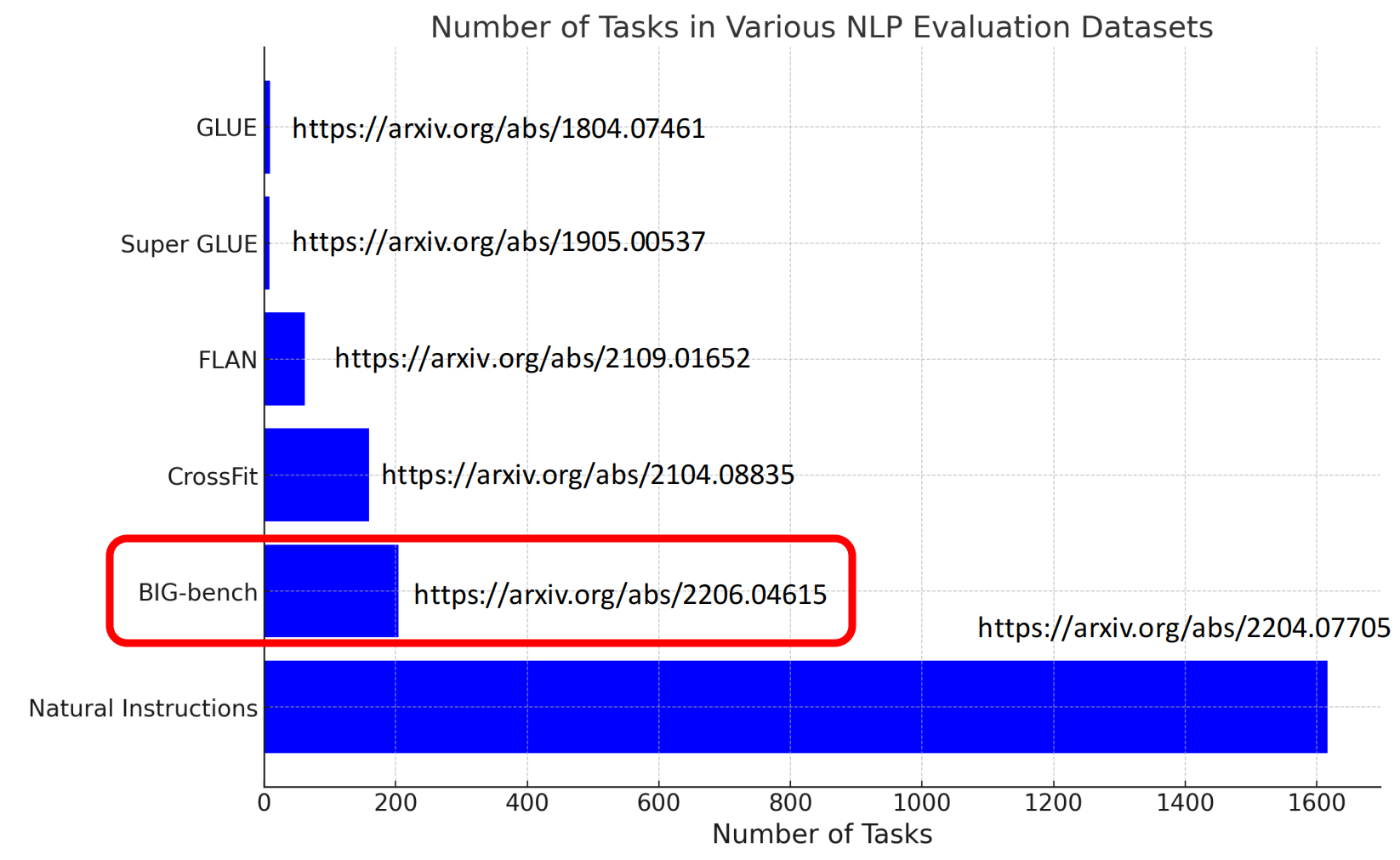
BIG-bench:
444 authors across 132 institutions
https://github.com/google/BIG-bench

- Emoji Movie

🐰🦊🚔🏙
🤠❤️🤠
- Checkmate In One Move


- ASCII word recognition

阅读长文的能力
Greg Kamradt
https://youtu.be/KwRRuiCCdmc?si=eRYBvVl2gTclSX1A
https://github.com/gkamradt/LLMTest_NeedleInAHaystack
大海撈針 (Needle in a Haystack)

https://github.com/gkamradt/LLMTest_NeedleInAHaystack

Claude以处理长文本著称,该论文测试Claude模型的处理长文本能力,结果非常不尽人意(红色代表表现很差)
https://github.com/gkamradt/LLMTest_NeedleInAHaystack

Claude团队看到这个结果坐不住了,于是自己赶紧出来测试,并且发布论文,称原来的测试方法不正确,因为他们没有使用正确的提示词,使用了正确提示词之后,效果很明显:
https://www.anthropic.com/news/claude-2-1-prompting

模型会不会为了目的不择手段
https://arxiv.org/abs/2304.03279

根据研究表明,ChatGpt并没有完全丧失道德底线:
https://arxiv.org/abs/2304.03279

机器有没有心智理论
https://uniform.wingzero.tw/acg/character/516/1743/1
https://baike.baidu.hk/item/%E7%99%BD%E9%8A%80%E5%BE%A1%E8%A1%8C/22622889

莎莉与小安测验(Sally–Anne test)
https://arxiv.org/abs/2303.12712
https://arxiv.org/abs/2302.02083


不过莎莉与小安这个问题时从网上抄来的,大模型会不会早就看过了?
https://arxiv.org/abs/2310.15421 :


关于心智的测试,语言模型和人类还有很大差距
https://arxiv.org/abs/2310.15421

不要尽信 Benchmark 的结果 ,因为Benchmark 上的题目都是公开的,大语言模型可能早就已经知道答案了:
偷偷搜集跟 Benchmark 类似的考古題 :
https://arxiv.org/abs/2311.04850
https://lmsys.org/blog/2023-11-14-llm-decontaminator/


https://arxiv.org/abs/2312.16337


价格和速度的评估
https://artificialanalysis.ai/


 浙公网安备 33010602011771号
浙公网安备 33010602011771号