03.深度学习框架-TensorFlow
讲在前面
本文在TensorFlow 2.0基础上进行讲解,TensorFlow 2.0和TensorFlow 1.0之间存在较多差异,请谨慎识别!(版本更新详参文末:版本更新)
TensorFlow介绍

深度学习框架TensorFlow一经发布,就受到了广泛的关注,并在计算机视觉、音频处理、推荐系统和自然语言处理等场景下都被大面积推广使用,现在已发布2.19版本,接下来我们深入浅出的介绍Tensorflow的相关应用。
TensorFlow的特点:
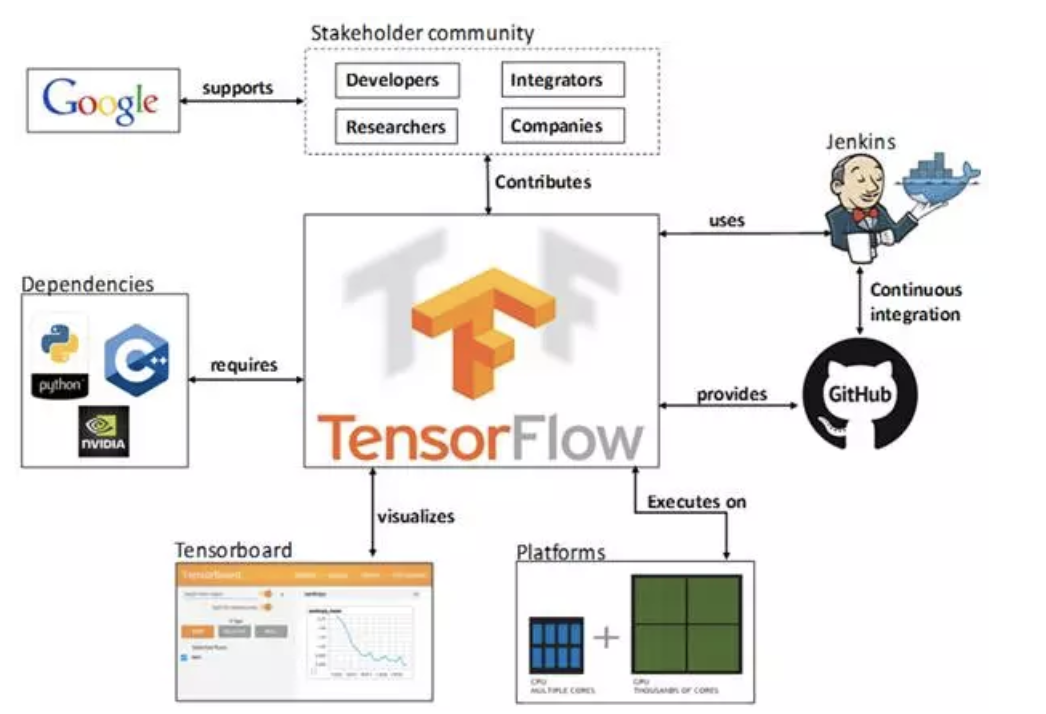
- 托管在github平台,有google groups和contributors共同维护。
- 提供了丰富的深度学习相关的API,支持Python和C/C++接口。
- 语言多样(Language Options)
- TensorFlow使用C++实现的,然后用Python封装。google号召社区通过SWIG开发更多的语言接口来支持TensorFlow。
- 提供了可视化分析工具Tensorboard,方便分析和调整模型。
- TensorBoard是TensorFlow的一组Web应用,用来监控TensorFlow运行过程,或可视化Computation Graph。
- TensorBoard目前支持5种可视化:标量(scalars)、图片(images)、音频(audio)、直方图(histograms)和计算图(Computation Graph)。
- TensorBoard的Events Dashboard可以用来持续地监控运行时的关键指标,比如loss、学习速率(learningrate)或是验证集上的准确率(accuracy)。
- 设备支持
- 支持Linux平台,Windows平台,Mac平台,甚至手机移动设备等各种平台。
- TensorFlow可以运行在各种硬件上,同时根据计算的需要,合理将运算分配到相应的设备,比如卷积就分配到GPU上,也允许在 CPU 和 GPU 上的计算分布,甚至支持使用 gRPC 进行水平扩展。
- 高度灵活(Deep Flexibility)
- 它不仅可以用来做神经网络算法研究,也可以用来做普通的机器学习算法,甚至是只要把计算表示成数据流图,都可以用TensorFlow。
TensorFlow 2.0 将专注于简单性和易用性,工作流程如下所示:
1、使用tf.data加载数据。 使用tf.data实例化读取训练数据和测试数据
2、模型的建立与调试: 使用动态图模式 Eager Execution 和著名的神经网络高层 API 框架 Keras,结合可视化工具 TensorBoard,简易、快速地建立和调试模型;
3、模型的训练: 支持 CPU / 单 GPU / 单机多卡 GPU / 多机集群 / TPU 训练模型,充分利用海量数据和计算资源进行高效训练;
4、预训练模型调用: 通过 TensorFlow Hub,可以方便地调用预训练完毕的已有成熟模型。
5、模型的部署: 通过 TensorFlow Serving、TensorFlow Lite、TensorFlow.js 等组件,可以将TensorFlow 模型部署到服务器、移动端、嵌入式端等多种使用场景;
TensorFlow的安装
在64 位系统上测试下面这些系统支持 TensorFlow:
- Ubuntu 16.04 或更高版本
- Windows 7 或更高版本
- macOS 10.12.6 (Sierra) 或更高版本(不支持 GPU)
进入虚拟环境当中再安装。推荐使用anoconda进行安装
- 1、非GPU版本安装
ubuntu(win和MAC同)安装
pip install tensorflow==2.19 -i https://pypi.tuna.tsinghua.edu.cn/simple- 2、GPU版本安装
pip install tensorflow-gpu==2.19. -i https://pypi.tuna.tsinghua.edu.cn/simple注:如果需要下载GPU版本的(TensorFlow只提供windows和linux版本的,没有Macos版本的)。
官网参考链接:
CPU与GPU的对比
- CPU:诸葛亮
- 核芯的数量更少
- 但是每一个核芯的速度更快,性能更强, 综合能力比较强
- 更适用于处理连续性(sequential)任务
- GPU:臭皮匠
- 专做某一个事情很好
- 核芯的数量更多
- 但是每一个核芯的处理速度较慢
- 更适用于并行(parallel)任务
张量及其操作
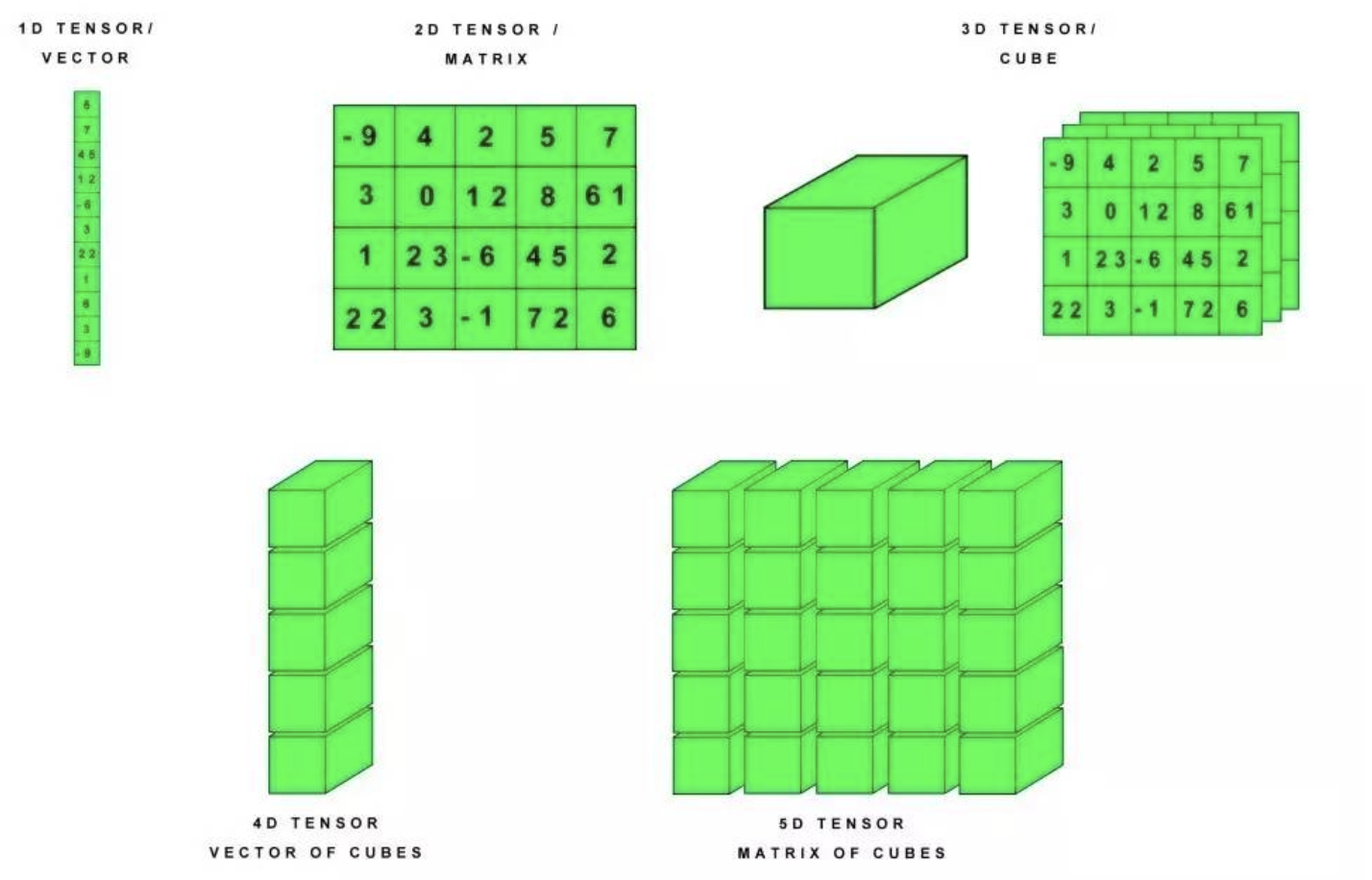
张量(Tensor)是一个多维数组。 与NumPy ndarray对象类似,tf.Tensor对象也具有数据类型和形状。如下图所示:
此外,tf.Tensors可以保留在GPU中。 TensorFlow提供了丰富的操作库(tf.add,tf.matmul,tf.linalg.inv等),它们使用和生成tf.Tensor。在进行张量操作之前先导入相应的工具包:
import tensorflow as tf
import numpy as np1.基本方法
首先让我们创建基础的张量:
# 创建int32类型的0维张量,即标量
rank_0_tensor = tf.constant(4)
print(rank_0_tensor)
# 创建float32类型的1维张量
rank_1_tensor = tf.constant([2.0, 3.0, 4.0])
print(rank_1_tensor)
# 创建float16类型的二维张量
rank_2_tensor = tf.constant([[1, 2],
[3, 4],
[5, 6]], dtype=tf.float16)
print(rank_2_tensor)输出结果为:
tf.Tensor(4, shape=(), dtype=int32)
tf.Tensor([2. 3. 4.], shape=(3,), dtype=float32)
tf.Tensor(
[[1. 2.]
[3. 4.]
[5. 6.]], shape=(3, 2), dtype=float16)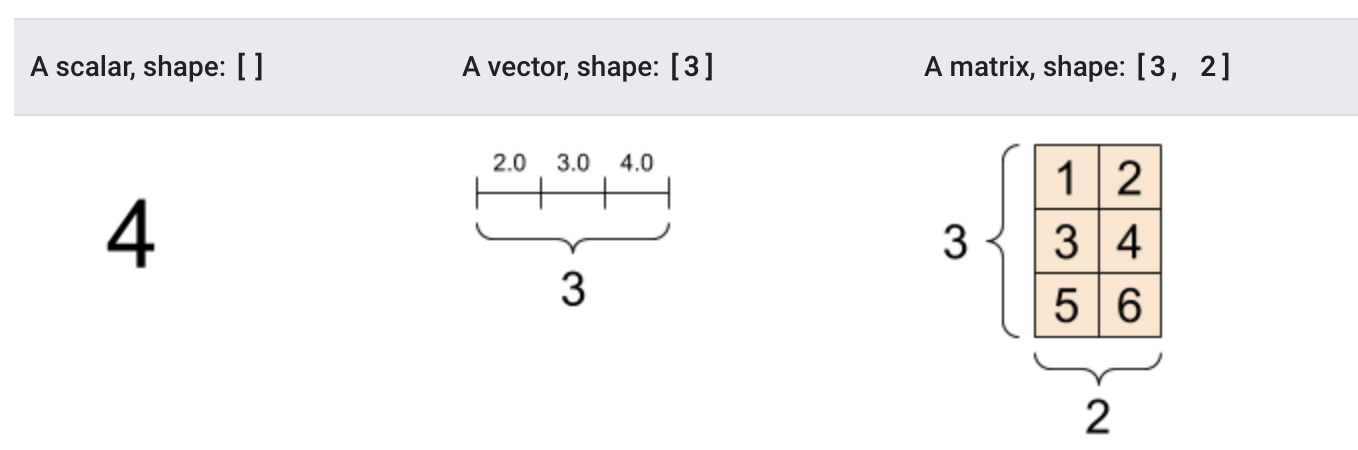
我们也可以创建更高维的张量:
# 创建float32类型的张量
rank_3_tensor = tf.constant([
[[0, 1, 2, 3, 4],
[5, 6, 7, 8, 9]],
[[10, 11, 12, 13, 14],
[15, 16, 17, 18, 19]],
[[20, 21, 22, 23, 24],
[25, 26, 27, 28, 29]],])
print(rank_3_tensor)该输出结果我们有更多的方式将其展示出来:
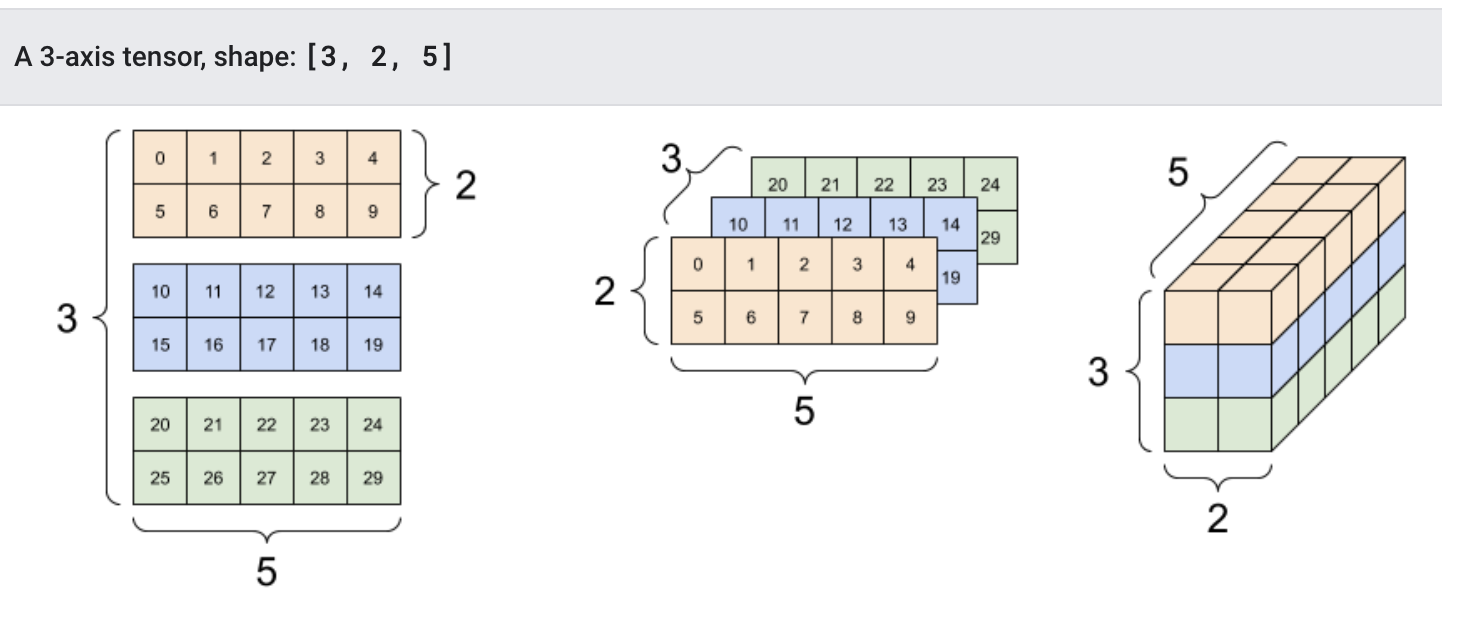
2.转换成numpy
我们可将张量转换为numpy中的ndarray的形式,转换方法有两种,以张量rank_2_tensor为例:
- np.array
np.array(rank_2_tensor)- Tensor.numpy()
rank_2_tensor.numpy()3.常用函数
我们可以对张量做一些基本的数学运算,包括加法、元素乘法和矩阵乘法等:
# 定义张量a和b
a = tf.constant([[1, 2],
[3, 4]])
b = tf.constant([[1, 1],
[1, 1]])
print(tf.add(a, b), "\n") # 计算张量的和
print(tf.multiply(a, b), "\n") # 计算张量的元素乘法
print(tf.matmul(a, b), "\n") # 矩阵乘法输出结果为:
tf.Tensor(
[[2 3]
[4 5]], shape=(2, 2), dtype=int32)
tf.Tensor(
[[1 2]
[3 4]], shape=(2, 2), dtype=int32)
tf.Tensor(
[[3 3]
[7 7]], shape=(2, 2), dtype=int32) 另外张量也可用于各种聚合运算:
tf.reduce_sum() # 求和
tf.reduce_mean() # 平均值
tf.reduce_max() # 最大值
tf.reduce_min() # 最小值
tf.argmax() # 最大值的索引
tf.argmin() # 最小值的索引例如:
c = tf.constant([[4.0, 5.0], [10.0, 1.0]])
# 最大值
print(tf.reduce_max(c))
# 最大值索引
print(tf.argmax(c))
# 计算均值
print(tf.reduce_mean(c))输出为:
tf.Tensor(10.0, shape=(), dtype=float32)
tf.Tensor([1 0], shape=(2,), dtype=int64)
tf.Tensor(5.0, shape=(), dtype=float32)4.变量
变量是一种特殊的张量,形状是不可变,但可以更改其中的参数(值)。定义时的方法是:
my_variable = tf.Variable([[1.0, 2.0], [3.0, 4.0]])我们也可以获取它的形状,类型及转换为ndarray:
print("Shape: ",my_variable.shape)
print("DType: ",my_variable.dtype)
print("As NumPy: ", my_variable.numpy)输出为:
Shape: (2, 2)
DType: <dtype: 'float32'>
As NumPy: <bound method BaseResourceVariable.numpy of <tf.Variable 'Variable:0' shape=(2, 2) dtype=float32, numpy=
array([[1., 2.],
[3., 4.]], dtype=float32)>>改变原变量的值:
var.assign([[2, 2],
[2, 2]])
var<tf.Variable 'Variable:0' shape=(2, 2) dtype=int32, numpy=
array([[2, 2],
[2, 2]])>如果改变变量的形状,会报错:
var.assign([[2, 2]])
# ValueError: Cannot assign value to variable ' Variable:0': Shape mismatch.The variable shape (2, 2), and the assigned value shape (1, 2) are incompatible.tf.keras介绍
tf.keras是TensorFlow 2.0的高阶API接口,为TensorFlow的代码提供了新的风格和设计模式,大大提升了TF代码的简洁性和复用性,官方也推荐使用tf.keras来进行模型设计和开发。
Keras是一个由Python编写的开源人工神经网络库,可以作为Tensorflow、Microsoft-CNTK和Theano的高阶应用程序接口,进行深度学习模型的设计、调试、评估、应用和可视化。
可以想象 TensorFlow 是一个功能强大的发动机工厂和各种精密零部件(低级API、数学运算、硬件管理、分布式框架等)。
tf.keras则像这个工厂提供的标准化的、易于使用的汽车组装套件和说明书(高阶API)。你可以按照说明书快速组装出功能完善的汽车(模型),但如果需要极端定制化或性能优化,你也可以深入工厂,利用原始发动机和零件进行手工打造(直接使用低级API)。但你很清楚,使用工厂提供的标准化套件(tf.keras)通常是开始项目最高效、最不容易出错的方式,并且它能无缝享受工厂的所有先进技术(TF特性)。同时,这个套件是工厂自己设计生产的,与工厂环境完美适配,而不是从外部购买的通用套件(独立Keras)。因此,在现代TensorFlow (2.x+) 中进行深度学习开发,
tf.keras是你最常用、最强大的工具和入口点。

kekras在模型构建(Sequential模型序列)比较有优势,TensorFlow在模型训练和部署的时候比较高效,所以两者有机结合,优势互补。
常用模块
tf.keras中常用模块如下表所示:
| 模块 | 概述 |
|---|---|
| activations | 激活函数 |
| applications | 预训练网络模块 |
| Callbacks | 在模型训练期间被调用 |
| datasets | tf.keras数据集模块,包括boston_housing,cifar10,fashion_mnist,imdb ,mnist |
| layers | Keras层API |
| losses | 各种损失函数 |
| metircs | 各种评价指标 |
| models | 模型创建模块,以及与模型相关的API |
| optimizers | 优化方法 |
| preprocessing | Keras数据的预处理模块 |
| regularizers | 正则化,L1,L2等 |
| utils | 辅助功能实现 |
常用方法
深度学习实现的主要流程:1.数据获取,2.数据处理,3.模型创建与训练,4.模型测试与评估,5.模型预测

1.导入tf.keras
使用 tf.keras,首先需要在代码开始时导入tf.keras
import tensorflow as tf
from tensorflow import keras2.数据输入
对于小的数据集,可以直接使用numpy格式的数据进行训练、评估模型,对于大型数据集或者要进行跨设备训练时使用tf.data.datasets来进行数据输入。
3.模型构建
- 简单模型使用Sequential进行构建
- 复杂模型使用函数式编程来构建
- 自定义layers
4.训练与评估
- 模型配置:
# 配置优化方法,损失函数和评价指标
model.compile(optimizer=tf.train.AdamOptimizer(0.001),
loss='categorical_crossentropy',
metrics=['accuracy'])- 模型训练
# 指明训练数据集,训练epoch,批次大小和验证集数据
model.fit/fit_generator(dataset,
epochs=10,
batch_size=3,
validation_data=val_dataset,
)- 模型评估
# 指明评估数据集和批次大小
model.evaluate(x, y, batch_size=32)- 模型预测
# 对新的样本进行预测
model.predict(x, batch_size=32)5.回调函数(callbacks)
回调函数用在模型训练过程中,来控制模型训练行为,可以自定义回调函数,也可使用tf.keras.callbacks 内置的 callback :
- ModelCheckpoint:定期保存 checkpoints。
- LearningRateScheduler:动态改变学习速率。
- EarlyStopping:当验证集上的性能不再提高时,终止训练。
- TensorBoard:使用 TensorBoard 监测模型的状态。
6.模型的保存和恢复
- 只保存参数
# 只保存模型的权重
model.save_weights('./my_model')
# 加载模型的权重
model.load_weights('my_model')- 保存整个模型
# 保存模型架构与权重在h5文件中
model.save('my_model.h5')
# 加载模型:包括架构和对应的权重
model = keras.models.load_model('my_model.h5')
注意:(.keras)是新的默认格式,详情参照《神经网络案例-mnist手写数字识别》-模型保存
总结
-
了解Tensorflow2.0框架的用途及流程
1.使用tf.data加载数据
2、模型的建立与调试
3、模型的训练
4、预训练模型调用
5、模型的部署
-
知道tf2.0的张量及其操作
张量是多维数组。
1、创建方法:tf.constant()
2、转换为numpy: np.array()或tensor.asnumpy()
3、常用函数:加法,乘法,及各种聚合运算
4、变量:tf.Variable()
-
知道tf.keras中的相关模块及常用方法
常用模块:models,losses,application等
快速入门模型
学习目标
- 知道使用tf.keras的基本流程
- 了解tf.keras实现模型构建的方法
- 了解tf.keras中模型训练验证的相关方法

今天我们通过鸢尾花分类案例,来给大家介绍tf.keras的基本使用流程。tf.keras 是 TensorFlow 的高级 API ,依托 TensorFlow 运行,为其提供便捷构建、训练模型的高层接口,让用户无需深入 TensorFlow 底层就能开发深度学习模型。我们调用它即可完成:
- 导入和解析数据集
- 构建模型
- 使用样本数据训练该模型
- 评估模型的效果。
由于与scikit -learn的相似性,接下来我们将通过将Keras与scikit -learn进行比较,介绍tf.Keras的相关使用方法。
1.相关的库的导入
在这里使用sklearn和tf.keras完成鸢尾花分类,导入相关的工具包:
# 绘图
import seaborn as sns
# 数值计算
import numpy as np
# sklearn中的相关工具
# 划分训练集和测试集
from sklearn.model_selection import train_test_split
# 逻辑回归
from sklearn.linear_model import LogisticRegressionCV
# tf.keras中使用的相关工具
# 用于模型搭建
from tensorflow.keras.models import Sequential
# 构建模型的显式的 Input 层(指定输入参数的形状),全连接层和激活方法
from tensorflow.keras.layers import Input,Dense,Activation
# 数据处理的辅助工具
from tensorflow.keras import utils2.数据展示和划分
利用seborn导入相关的数据,iris数据以dataFrame的方式在seaborn进行存储,我们读取后并进行展示:
# 读取数据
iris = sns.load_dataset("iris")
# 展示数据的前五行
iris.head()| sepal_length | sepal_width | petal_length | petal_width | species | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | setosa |
另外,利用seaborn中pairplot函数探索数据特征间的关系:
# 将数据之间的关系进行可视化
sns.pairplot(iris, hue='species')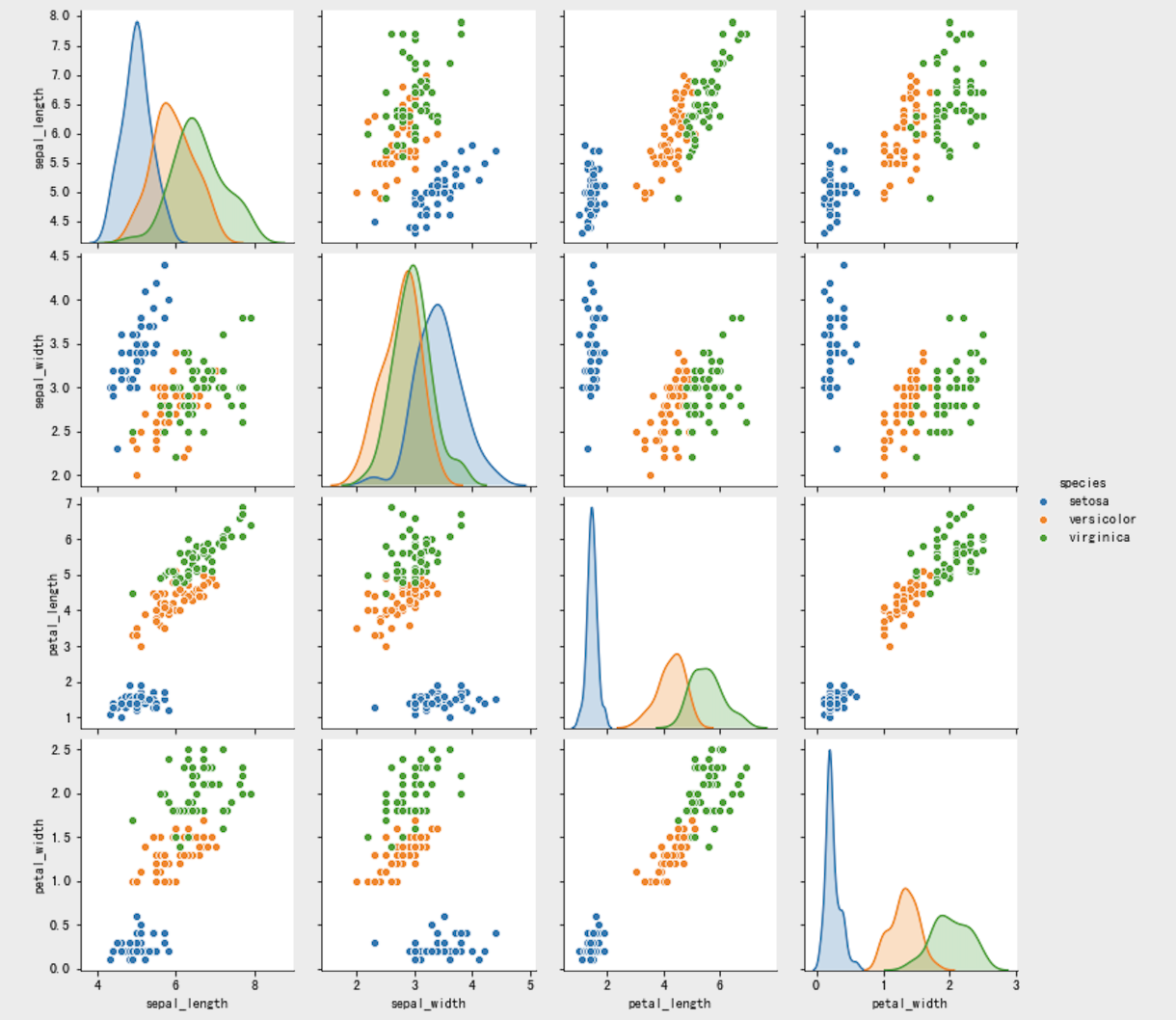
确定特征值、目标值:从iris dataframe中提取原始数据,将花瓣和萼片数据保存在数组X中,标签保存在相应的数组y中:
# 花瓣和花萼的数据
X = iris.values[:, :4]
# 标签值
y = iris.values[:, 4]利用train_test_split将数据划分为训练集和测试集:
# 将数据集划分为训练集和测试集
train_X, test_X, train_y, test_y = train_test_split(X, y, train_size=0.5, test_size=0.5, random_state=0)接下来,我们就可以使用sklearn和tf.keras来完成预测
3.sklearn实现
利用逻辑回归的分类器,并使用交叉验证的方法来选择最优的超参数,实例化LogisticRegressionCV分类器,并使用fit方法进行训练:
# 实例化分类器
lr = LogisticRegressionCV()
# 训练
lr.fit(train_X, train_y)利用训练好的分类器进行预测,并计算准确率:
# 计算准确率并进行打印
print("Accuracy = {:.2f}".format(lr.score(test_X, test_y)))逻辑回归的准确率为:
Accuracy = 0.934.tf.keras实现
在sklearn中我们只要实例化分类器并利用fit方法进行训练,最后衡量它的性能就可以了,那在tf.keras中与在sklearn非常相似,不同的是:
- 构建分类器时需要进行模型搭建
- 数据采集时,sklearn可以接收字符串型的标签,如:“setosa”,但是在tf.keras中需要对标签值进行热编码,如下所示:

热编码one-hot特殊说明
有很多方法可以实现热编码,比如pandas中的get_dummies(),在这里我们使用tf.keras中的方法进行热编码:
# 进行热编码
def one_hot_encode_object_array(arr):
# 去重获取全部的类别
uniques, ids = np.unique(arr, return_inverse=True)
# 返回热编码的结果
return utils.to_categorical(ids, len(uniques))补充说明:
return_inverse=True参数表示返回两个结果:
uniques:数组中的唯一值(去重后的类别)ids:原始数组中每个元素在uniques中的索引位置uniques:
array(['setosa', 'versicolor', 'virginica'], dtype=object)ids:
array([2, 1, 0, 0, 1, 0, 2, 2, 1, 2, 0, 2, 2, 0, 1, 1, 1, 0, 1, 2, 2, 0, 1, 1, 0, 1, 1, 0, 1, 0, 0, 0, 2, 0, 2, 1, 1, 2, 2, 1, 0, 1, 0, 0, 2, 2, 0, 2, 1, 0, 2, 0, 2, 1, 2, 1, 1, 0, 2, 2, 1, 0, 0, 2, 1, 1, 1, 2, 1, 0, 2, 0, 2, 0, 1, 1, 2, 0, 0, 0, 2, 0, 1, 1, 1, 0, 0, 0, 0, 2, 0, 2, 2, 2, 0, 2, 0, 2, 2, 1, 0, 1, 1, 1, 1, 2, 1, 1, 2, 2, 0, 1, 2, 0, 0, 2, 2, 2, 1, 2], dtype=int64)
4.1 数据处理
接下来对标签值进行热编码:
# 训练集热编码
train_y_ohe = one_hot_encode_object_array(train_y)
# 测试集热编码
test_y_ohe = one_hot_encode_object_array(test_y)热编码补充说明
对鸢尾花目标值热编码的时候采取上面的方式,但是在处理手写字数据集MNIST的目标值时(目标值y∈[1~10]),采取下面的方式:
from tensorflow.keras.datasets import mnist # 加载示例数据集(MNIST 手写数字) (x_train, y_train), (x_test, y_test) = mnist.load_data() # 数据预处理 x_train = x_train / 255.0 x_test = x_test / 255.0 y_train = tf.keras.utils.to_categorical(y_train, 10) y_test = tf.keras.utils.to_categorical(y_test, 10)这两种热编码方式的核心区别在于标签数据类型和类别数量的处理,适用于不同的数据场景:
核心区别分析
数据类型处理不同:
方式1(鸢尾花案例):
使用np.unique(arr, return_inverse=True)先处理非数值型标签(如字符串类别)。
→ 将字符串标签(如 "setosa")映射为整数索引,再进行热编码。方式2(MNIST案例):
直接使用tf.keras.utils.to_categorical()处理数值型标签(如整数 0-9)。
→ 无需额外转换,直接编码。类别数量确定方式不同:
方式1:通过
len(uniques)动态计算数据中的实际类别数(依赖数据本身)。
→ 适用于未知类别总数的场景。方式2:显式指定类别数量(如
10)。
→ 适用于已知固定类别数的场景。最佳实践建议
- 处理非数值标签(如字符串):
# 步骤1:将字符串标签转换为整数索引 from sklearn.preprocessing import LabelEncoder le = LabelEncoder() train_y_int = le.fit_transform(train_y) # 训练集转换 test_y_int = le.transform(test_y) # 测试集使用相同映射 # 步骤2:热编码(显式指定类别数) num_classes = len(le.classes_) # 获取实际类别数 train_y_ohe = tf.keras.utils.to_categorical(train_y_int, num_classes) test_y_ohe = tf.keras.utils.to_categorical(test_y_int, num_classes)
- 处理数值标签(已知类别数):
# 直接热编码(推荐) train_y_ohe = tf.keras.utils.to_categorical(train_y, num_classes=10) test_y_ohe = tf.keras.utils.to_categorical(test_y, num_classes=10)
- 处理数值标签(未知类别数):
# 动态获取类别数(谨慎使用) num_classes = len(np.unique(train_y)) # 仅用训练集计算 train_y_ohe = tf.keras.utils.to_categorical(train_y, num_classes) test_y_ohe = tf.keras.utils.to_categorical(test_y, num_classes)⚠️ 关键注意事项:
若测试集可能出现训练集未包含的类别,必须显式指定类别数(如方式2),否则会导致维度不一致错误。
在生产环境中,建议始终显式传递
num_classes而非依赖数据动态计算。
4.2 模型搭建
在sklearn中,模型都是现成的。tf.Keras是一个神经网络库,我们需要根据数据和标签值构建神经网络。神经网络可以发现特征与标签之间的复杂关系。神经网络是一个高度结构化的图,其中包含一个或多个隐藏层。每个隐藏层都包含一个或多个神经元。神经网络有多种类别,该程序使用的是密集型神经网络,也称为全连接神经网络:一个层中的神经元将从上一层中的每个神经元获取输入连接。例如,图 2 显示了一个密集型神经网络,其中包含 1 个输入层、2 个隐藏层以及 1 个输出层,如下图所示:
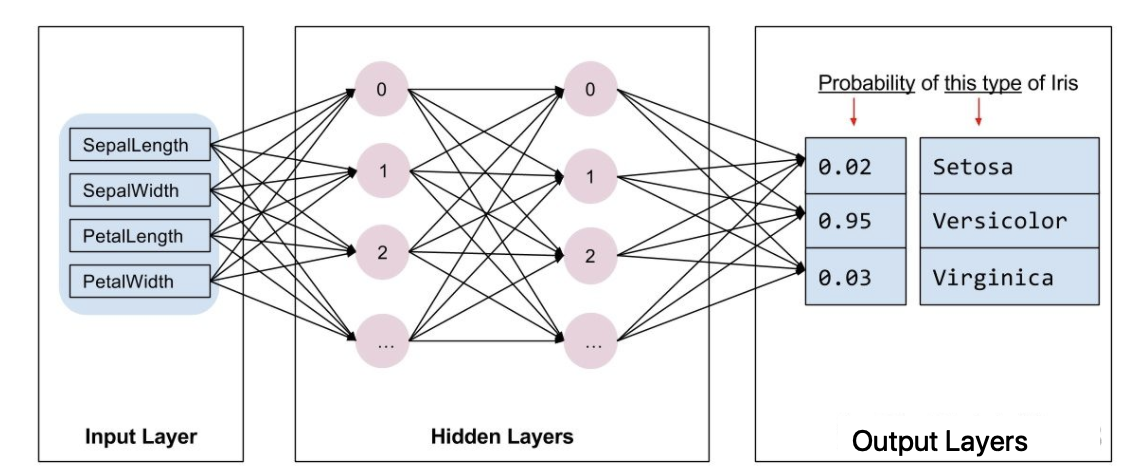
上图 中的模型经过训练并馈送未标记的样本时,它会产生 3 个预测结果:相应鸢尾花属于指定品种的可能性。对于该示例,输出预测结果的总和是 1.0。该预测结果分解如下:山鸢尾为 0.02,变色鸢尾为 0.95,维吉尼亚鸢尾为 0.03。这意味着该模型预测某个无标签鸢尾花样本是变色鸢尾的概率为 95%。
TensorFlow tf.keras API 是创建模型和层的首选方式。通过该 API,您可以轻松地构建模型并进行实验,而将所有部分连接在一起的复杂工作则由 Keras 处理。
tf.keras.Sequential 模型是层的线性堆叠。该模型的构造函数会采用一系列层实例;在本示例中,采用的是 2 个密集层(分别包含 10 个节点)以及 1 个输出层(包含 3 个代表标签预测的节点)。第一个层的 input_shape 参数对应该数据集中的特征数量:
# 利用sequential方式构建模型
model = Sequential([
# # 显式定义输入层(指定输入参数形状)
Input(shape=(4,)),
# 隐藏层1,激活函数是relu
Dense(10, activation="relu"),
# 隐藏层2,激活函数是relu
Dense(10, activation="relu"),
# 输出层
Dense(3,activation="softmax")
])通过model.summary可以查看模型的架构:
model.summary()Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 10) 50
_________________________________________________________________
dense_1 (Dense) (None, 10) 110
_________________________________________________________________
dense_2 (Dense) (None, 3) 33
=================================================================
Total params: 193
Trainable params: 193
Non-trainable params: 0
_________________________________________________________________ 激活函数可决定层中每个节点的输出形状。这些非线性关系很重要,如果没有它们,模型将等同于单个层。激活函数有很多,但隐藏层通常使用 ReLU。
隐藏层和神经元的理想数量取决于问题和数据集。与机器学习的多个方面一样,选择最佳的神经网络形状需要一定的知识水平和实验基础。一般来说,增加隐藏层和神经元的数量通常会产生更强大的模型,而这需要更多数据才能有效地进行训练。
4.3 模型训练和预测
在训练和评估阶段,我们都需要计算模型的损失。这样可以衡量模型的预测结果与预期标签有多大偏差,也就是说,模型的效果有多差。我们希望尽可能减小或优化这个值,所以我们设置优化策略和损失函数,以及模型精度的计算方法:
# 设置模型的相关参数:优化器,损失函数和评价指标
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=["accuracy"])接下来与在sklearn中相同,分别调用fit和predict方法进行预测即可。
# 模型训练:epochs:训练样本送入到网络中的次数,batch_size:每次训练的送入到网络中的样本个数,verbose:输出训练过程
model.fit(x_train.astype('float32'),y_train_onehot,epochs=10,batch_size=1,verbose=1)
参数
含义
说明
备注
train_X训练数据特征
输入数据,通常是 NumPy 数组或 TensorFlow 张量
train_y_ohe训练数据标签
目标输出,使用了独热编码格式
epochs=10训练轮数
整个数据集将被遍历10次
- 参数意义:
- 值太小 → 模型未充分学习 (欠拟合)
- 值太大 → 可能过拟合且耗时增加
- 通常根据验证集性能调整
batch_size=1批量大小
每次梯度更新使用1个样本
- 常见值:32、64、128 等(批梯度下降)
verbose=1日志显示模式
显示进度条和指标
- 控制训练信息的显示方式:
0:静默模式(无输出)1:显示进度条和指标(默认)2:只显示每个epoch的指标(无进度条)
上述代码完整的执行流程是:
- 在一个epoch中,遍历训练 Dataset 中的每个样本,并获取样本的特征 (x) 和标签 (y)。
- 根据样本的特征进行预测,并比较预测结果和标签。衡量预测结果的不准确性,并使用所得的值计算模型的损失和梯度。
- 使用 optimizer 更新模型的变量。
- 对每个epoch重复执行以上步骤,直到模型训练完成。
训练过程展示如下:
Epoch 1/10
120/120 ━━━━━━━━━━━━━━━━━━━━ 1s 1ms/step - accuracy: 0.1944 - loss: 1.5944
Epoch 2/10
120/120 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - accuracy: 0.7763 - loss: 0.6720
Epoch 3/10
120/120 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - accuracy: 0.8680 - loss: 0.5452
Epoch 4/10
120/120 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - accuracy: 0.8293 - loss: 0.4140
Epoch 5/10
120/120 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - accuracy: 0.9323 - loss: 0.4386
Epoch 6/10
120/120 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - accuracy: 0.8691 - loss: 0.4030
Epoch 7/10
120/120 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - accuracy: 0.9277 - loss: 0.3466
Epoch 8/10
120/120 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - accuracy: 0.9215 - loss: 0.3524
Epoch 9/10
120/120 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - accuracy: 0.8867 - loss: 0.3099
Epoch 10/10
120/120 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - accuracy: 0.9480 - loss: 0.2660<keras.src.callbacks.history.History at 0x1deb9cd26f0>与sklearn中不同,对训练好的模型进行评估时,与sklearn.score方法对应的是tf.keras.evaluate()方法,返回的是损失函数和在compile模型时要求的指标:
# 计算模型的损失和准确率
loss, accuracy = model.evaluate(test_X, test_y_ohe, verbose=1)
print("Accuracy = {:.2f}".format(accuracy))分类器的评估结果为:
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 163ms/step - accuracy: 0.9667 - loss: 0.0731(0.07306092232465744, 0.9666666388511658)到此我们对tf.kears的使用有了一个基本的认知,在接下来的课程中会给大家解释神经网络以及在计算机视觉中的常用的CNN的使用。
补充:实际应用建议
# 更好的配置示例: model.fit( train_X, train_y_ohe, epochs=50, # 根据验证损失调整 batch_size=32, # 更常用的批大小 validation_split=0.2, # 添加验证集 verbose=1, callbacks=[ # 添加回调函数 EarlyStopping(patience=5), # 早停 ModelCheckpoint('best_model.h5') # 保存最佳模型 ] )
总结
1.使用tf.keras进行分类时的主要流程:
数据处理-构建模型-模型训练-模型验证
2.tf.keras中构建模型可通过squential()来实现并利用.fit()方法进行训练
3.使用evaluate()方法计算损失函数和准确率
补充内容
优化警告信息
运行TensorFlow代码,控制台出现警告信息:
D:\install\tools\Anaconda312\python.exe D:\learn\00AI学习终极版学习顺序\5.深度学习\Python深度之神经网络资料\深度day1资料\02-����\day01_deeplearning_-luzhanshi.py
2025-06-24 15:09:25.740436: I tensorflow/core/util/port.cc:153] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable `TF_ENABLE_ONEDNN_OPTS=0`.
2025-06-24 15:09:26.741809: I tensorflow/core/util/port.cc:153] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable `TF_ENABLE_ONEDNN_OPTS=0`.
2025-06-24 15:09:29.438363: I tensorflow/core/platform/cpu_feature_guard.cc:210] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: SSE3 SSE4.1 SSE4.2 AVX AVX2 FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.这些警告不会影响 TensorFlow 的正常使用,它们只是提供关于底层优化的信息性提示。如果您不进行大规模模型训练,甚至可以完全忽略它们。
警告分析及解决方案
1. oneDNN 优化警告
2025-06-24 15:03:40.140283: I tensorflow/core/util/port.cc:153] oneDNN custom operations are on...
含义:
- TensorFlow 正在使用 Intel 的 oneDNN 库(深度神经网络库)进行优化加速
- 使用不同计算顺序可能导致微小的浮点数差异(通常在小数点后几位)
影响:
- 这不会影响模型训练或推理结果
- 数值差异在可接受范围内,无需担心
解决方法(如必要,不建议禁用):
import os os.environ['TF_ENABLE_ONEDNN_OPTS'] = '0' # 禁用 oneDNN 优化2. CPU 指令集警告
2025-06-24 15:03:47.619263: I tensorflow/core/platform/cpu_feature_guard.cc:210] This TensorFlow binary is optimized...To enable the following instructions: SSE3 SSE4.1 SSE4.2 AVX AVX2 FMA...
根本原因:
- 您的 CPU 支持高级指令集(AVX/AVX2/FMA)
- 但当前安装的 TensorFlow 版本没有包含这些优化
影响:
- 性能损失:未能充分发挥 CPU 的全部潜力
- 在训练大型模型时可能有 30-50% 的性能差距
- 不影响功能,只是速度稍慢
专业解决方案:
选项1:安装优化版 TensorFlowpip install tensorflow-intel -i https://pypi.tuna.tsinghua.edu.cn/simple验证优化是否有效
# 比较优化前后的性能 import time import numpy as np x = np.random.rand(1000, 1000) start = time.time() for _ in range(100): tf.linalg.matmul(x, x) print("平均计算时间:", (time.time()-start)/100)打印结果对比:
tensorflow:平均计算时间: 0.03132117986679077
tensorflow-intel:平均计算时间: 0.018585708141326904
3. 通用日志设置建议
要减少日志干扰,可设置日志级别:
import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 0=全部日志,1=INFO,2=只警告,3=只错误 import tensorflow as tf🖥 完整解决方案参考
# 在代码最开头添加: import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' # 只显示错误信息 os.environ['TF_ENABLE_ONEDNN_OPTS'] = '1' # 保持 oneDNN 启用(默认状态) # 然后导入 TensorFlow import tensorflow as tf注意,即使安装了TensorFlow-Intel,依然会有上面的打印信息,因为这些打印信息不是报错也不是警告,而是info:
- 开头
I表示信息 (Info),不是警告 (Warning) 或错误 (Error)
版本更新问题
注意:
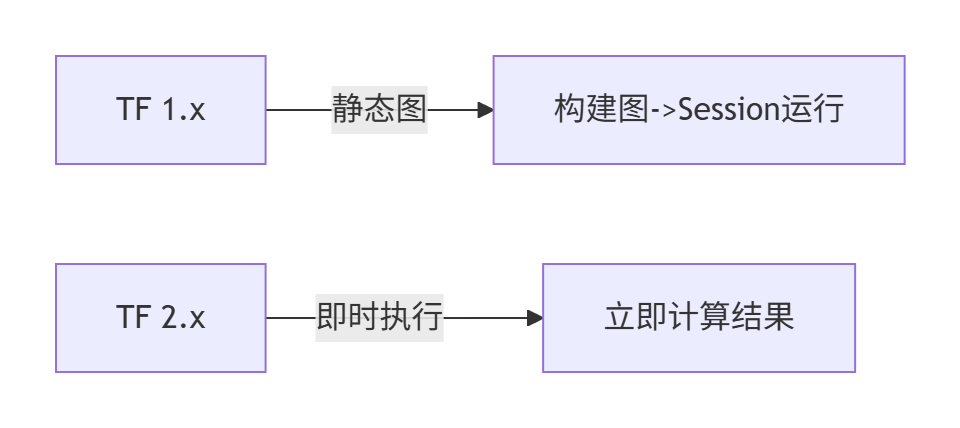
在 TensorFlow 2.0(2019年发布)中,核心 API 进行了重大更新:
- Session 对象被移除 - 改为即时执行(Eager Execution)
- Placeholder 被移除 - 直接使用 Python 变量
- 计算图构建方式改变 - 使用
@tf.function装饰器代替 graph
迁移路径建议:
- 新项目:使用
@tf.function+ 即时执行@tf.function # 使用装饰器显式定义计算图 def add_numbers(a, b): return tf.add(a, b) result = add_numbers(tf.constant(20), tf.constant(30)) print(result.numpy()) # 输出 50完整现代版本代码:
import tensorflow as tf a = 20 b = 30 c = a + b # 普通 Python 操作也可工作 # TensorFlow 张量操作 d = tf.constant(a) e = tf.constant(b) f = tf.add(d, e) # 获取实际值 print("Python 计算结果:", c) print("TensorFlow 计算结果:", f.numpy()) # 使用现代会话替代方案 print("使用 tf.function:", tf.function(lambda: d + e)())为什么 TensorFlow 做这个改变?
- 简化开发:即时执行让调试更直观
- 提高可用性:更接近 Python 原生编程体验
- 保持性能:通过
@tf.function实现图优化建议:如果您在学习教程或书籍,请确认教程基于 TensorFlow 2.x。多数 2020 年后发布的资源都已更新为现代 API。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号