Scikit-learn 机器学习库
Scikit-learn概述

Scikit-learn 是 Python 最流行的机器学习库之一,提供高效的算法实现和数据处理工具。
官网:https://scikit-learn.org/stable/
- Python语⾔的机器学习⼯具
- Scikit-learn包括许多知名的机器学习算法的实现
- Scikit-learn⽂档完善,容易上⼿,丰富的API
- ⽬前稳定版本1.6.1
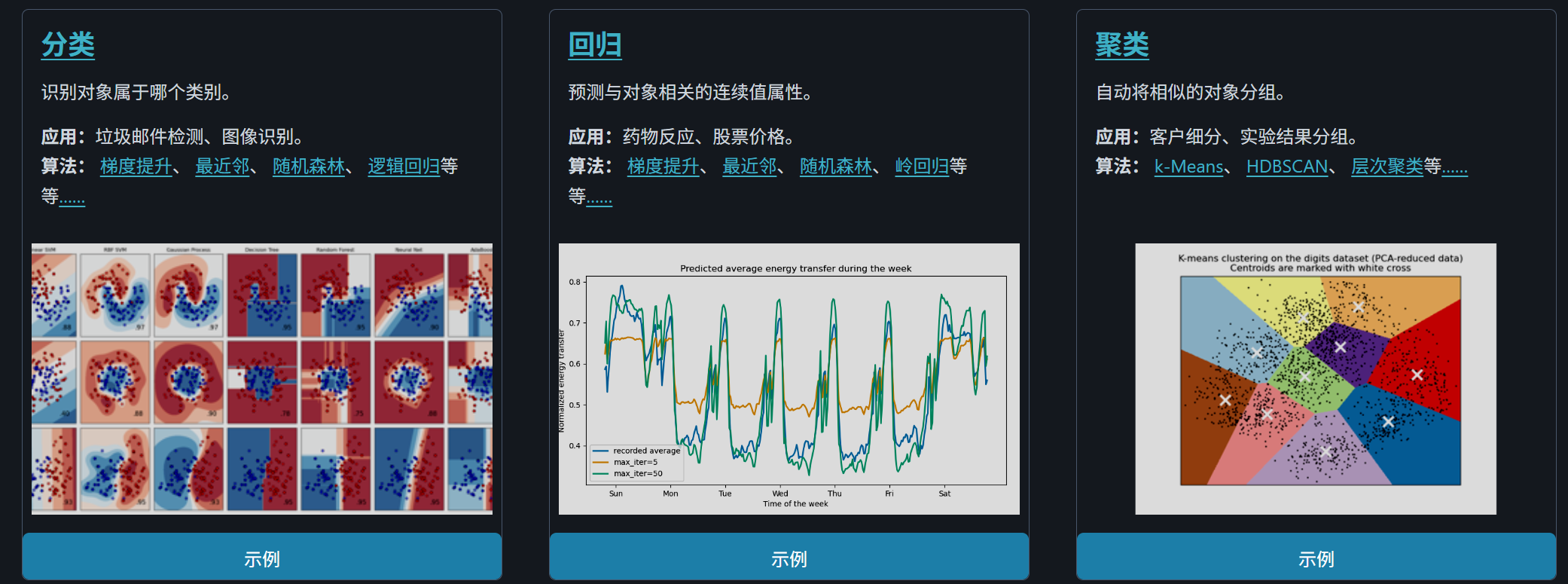
功能
| 模块 | 功能 | 典型类/函数示例 |
|---|---|---|
| 数据预处理 | 标准化、缺失值填充、编码 | StandardScaler, OneHotEncoder |
| 特征工程 | 特征选择、降维、生成多项式特征 | SelectKBest, PCA, PolynomialFeatures |
| 监督学习 | 分类、回归 | LinearRegression, SVM, RandomForestClassifier |
| 无监督学习 | 聚类、降维、异常检测 | KMeans, DBSCAN, IsolationForest |
| 模型评估 | 交叉验证、指标计算 | cross_val_score, confusion_matrix |
| 超参数调优 | 网格搜索、随机搜索 | GridSearchCV, RandomizedSearchCV |
| 流水线(Pipeline) | 组合多个步骤 | Pipeline, make_pipeline |
安装
pip3 install scikit-learn==1.6.1安装好之后可以通过以下命令查看是否安装成功
import sklearn注:安装scikit-learn需要Numpy, Scipy等库
数据集API
Scikit-learn 提供了多种加载数据集的方式,涵盖内置小型数据集、标准基准数据集(大数据集)和模拟数据生成。
加载内置小型数据集
适用于快速测试和教学,数据集直接包含在 Scikit-learn 中,无需下载。
API
- sklearn.datasets
- 加载获取流⾏数据集
- datasets.load_*()
- 获取⼩规模数据集,数据包含在datasets⾥
参数
-
return_X_y(布尔值):True: 直接返回(data, target),跳过Bunch对象。False(默认): 返回包含数据和元信息的Bunch对象。
-
as_frame(布尔值):True: 返回 Pandas DataFrame/Series。False(默认): 返回 NumPy 数组。
返回值
返回值为 Bunch 对象(datasets.base.Bunch(字典格式)),包含以下属性:
-
data: 特征矩阵(DataFrame 或 NumPy 数组)。 -
target: 目标值(Series 或 NumPy 数组)。 -
feature_names: 特征名称列表。(⼿写数字、回归数据集没有) -
target_names: 目标列名称(仅分类任务)。 -
DESCR: 数据集描述文本。 -
details: 数据集的 OpenML 元信息(如上传者、许可证等)。
常用数据集列表
| 函数名 | 数据集说明 | 样本数 | 特征数 | 任务类型 |
|---|---|---|---|---|
load_iris() |
鸢尾花数据集 | 150 | 4 | 分类 |
load_digits() |
手写数字数据集 | 1797 | 64 | 分类 |
load_wine() |
葡萄酒数据集 | 178 | 13 | 分类 |
load_breast_cancer() |
乳腺癌数据集 | 569 | 30 | 分类 |
load_diabetes() |
糖尿病数据集 | 442 | 10 | 回归 |
示例代码
sklearn.datasets.load_iris()加载并返回鸢尾花数据集。
from sklearn.datasets import load_iris
# 加载数据
iris = load_iris()
X, y = iris.data, iris.target # 特征矩阵 (150x4), 目标值 (150,)
# 返回 Pandas DataFrame 格式(需 as_frame=True)
iris_df = load_iris(as_frame=True)
X_df = iris_df.data # DataFrame
y_series = iris_df.target # Series
# 直接返回 X 和 y(跳过 Bunch 对象)
X, y = load_iris(return_X_y=True)鸢尾花数据集介绍
Iris数据集是常⽤的分类实验数据集,由Fisher, 1936收集整理。Iris也称鸢尾花卉数据集,是⼀类多重变量分析的数据集。关于数据集的具体介绍:

| 名称 | 数量 |
| 类别 | 3 |
| 特征 | 4 |
| 样本数量 | 150 |
| 每个类别数量 | 50 |
数据集详述示例代码:
from sklearn import datasets
# 加载小数据集
# 加载鸢尾花数据集
iris = datasets.load_iris()
# 返回值是⼀个继承⾃字典的Bench
print("数据集的特征名:\n",iris.feature_names)
print("数据集的特征数据:\n",iris.data)
print("数据集的标签名:\n",iris.target_names)
print("数据集的标签数组:\n",iris.target)
print("数据集的数据描述:\n",iris.DESCR) D:\learn\Python-卢战士优选\learncode\MachineLearning\.venv\Scripts\python.exe D:\learn\Python-卢战士优选\learncode\MachineLearning\K-近邻算法API.py
数据集的特征名:
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
数据集的特征数据:
[[5.1 3.5 1.4 0.2]
...共计150条
[6.2 3.4 5.4 2.3]
[5.9 3. 5.1 1.8]]
数据集的标签名:
['setosa' 'versicolor' 'virginica']
数据集的标签数组:
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
数据集的数据描述:
.. _iris_dataset:
**Data Set Characteristics:**
:Number of Instances: 150 (50 in each of three classes)
:Number of Attributes: 4 numeric, predictive attributes and the class
:Attribute Information:
- sepal length in cm
- sepal width in cm
- petal length in cm
- petal width in cm
- class:
- Iris-Setosa
- Iris-Versicolour
- Iris-Virginica
:Summary Statistics:
============== ==== ==== ======= ===== ====================
Min Max Mean SD Class Correlation
============== ==== ==== ======= ===== ====================
sepal length: 4.3 7.9 5.84 0.83 0.7826
sepal width: 2.0 4.4 3.05 0.43 -0.4194
petal length: 1.0 6.9 3.76 1.76 0.9490 (high!)
petal width: 0.1 2.5 1.20 0.76 0.9565 (high!)
============== ==== ==== ======= ===== ====================
:Missing Attribute Values: None
:Class Distribution: 33.3% for each of 3 classes.
:Creator: R.A. Fisher
:Donor: Michael Marshall (MARSHALL%PLU@io.arc.nasa.gov)
:Date: July, 1988
The famous Iris database, first used by Sir R.A. Fisher. The dataset is taken
from Fisher's paper. Note that it's the same as in R, but not as in the UCI
Machine Learning Repository, which has two wrong data points.
.. dropdown:: References
- Fisher, R.A. "The use of multiple measurements in taxonomic problems"
Annual Eugenics, 7, Part II, 179-188 (1936); also in "Contributions to
Process finished with exit code 0API
- datasets.fetch_*(data_home=None)
- 获取⼤规模数据集,需要从⽹络上下载,
- 第⼀个参数是
参数
data_home(字符串):- 数据集下载到本地的路径,默认是 ~/scikit_learn_data/;window默认路径:(C:\Users\luzhanshi\scikit_learn_data)
-
return_X_y(布尔值):True: 直接返回(data, target),跳过Bunch对象。False(默认): 返回包含数据和元信息的Bunch对象。
-
as_frame(布尔值):True: 返回 Pandas DataFrame/Series。False(默认): 返回 NumPy 数组。
返回值
返回值为 Bunch 对象(datasets.base.Bunch(字典格式)),包含以下属性:
-
data: 特征矩阵(DataFrame 或 NumPy 数组)。 -
target: 目标值(Series 或 NumPy 数组)。 -
feature_names: 特征名称列表。(⼿写数字、回归数据集没有) -
target_names: 目标列名称(仅分类任务)。 -
DESCR: 数据集描述文本。 -
details: 数据集的 OpenML 元信息(如上传者、许可证等)。
示例代码:
from sklearn.datasets import fetch_california_housing
# 加载加州房价数据集
housing = fetch_california_housing(as_frame=True)
X, y = housing.data, housing.target # DataFrame (20640x8), Seriesfetch_openml函数
fetch_openml 是 Scikit-learn 中用于从 OpenML 平台 加载数据集的函数,支持数千个公开数据集。

1. 核心功能
- 加载数据集:从 OpenML(开放机器学习平台,https://www.openml.org)获取数据集。
- 支持类型:分类、回归、聚类等任务的数据集(如 MNIST、Titanic、Ames 房价等)。
- 返回格式:默认返回 NumPy 数组,可选 Pandas DataFrame(需
as_frame=True)。
2. 特有参数说明
| 参数名 | 类型 | 默认值 | 说明 | 代码示例 |
|---|---|---|---|---|
name |
str |
None |
数据集的名称(如 "titanic"),与 data_id 二选一。 |
|
data_id |
int |
None |
数据集的 OpenML ID(如 420),与 name 二选一。 |
|
version |
int 或 "active" |
"active" |
数据集版本。推荐指定固定版本以保证可复现性。 |
|
as_frame |
bool |
False |
是否返回 Pandas DataFrame(特征)和 Series(目标)。需安装 Pandas。 | |
target_column |
str |
"default-target" |
指定目标列名称。若未指定,自动检测目标列。 |
|
cache |
bool |
True |
是否缓存数据集到本地目录(默认路径:~/scikit_learn_data)。 |
|
parser |
str |
"auto" |
数据解析器: - "liac-arff":传统 ARFF 格式解析。- "pandas":强制使用 Pandas 解析(处理混合数据类型更灵活)。 |
3. 使用示例
(1) 按名称加载 Ames 房价数据集(推荐)
最佳实践:
- 固定数据集版本以保证实验可复现。
- 使用
as_frame=True和parser="pandas"简化特征处理。 - 加载后检查数据分布和缺失值。
20news案例
- sklearn.datasets.fetch_20newsgroups(data_home=None,subset=‘train’)
- subset:'train'或者'test','all',可选,选择要加载的数据集:训练集、测试集、全部
20news数据集简介
以下内容根据数据集的DESCR属性内容总结
20 Newsgroups 是经典的文本分类数据集,适用于教学和实验,但需注意数据清洗与伦理问题。其核心价值在于模拟真实文本分布,帮助开发者验证算法在复杂语言环境中的鲁棒性。
- 来源:20 个不同主题的新闻组帖子(如科技、宗教、体育等),共约 18,846 篇文档。
- 划分:按发布时间分为 训练集(约 11,314 篇) 和 测试集(约 7,532 篇)。
- 用途:文本分类、聚类、自然语言处理(NLP)任务的基准数据集。
原始文本加载:
# 加载大数据集
# data_home:指定下载的路径
# subset=test、train、all。指定下载测试集还是训练集还是全部下载
newsgroups = datasets.fetch_20newsgroups(data_home=r'D:\learn\000人工智能数据大全\黑马数据\科学计算数据\20news', subset='all')
# print("数据集的特征名:\n",newsgroups.feature_names)#直接打印特征名会报错:fetch_20newsgroups 返回的是 原始文本数据(未向量化),而 feature_names 属性仅在文本被转换为数值特征(如 TF-IDF 或词频向量)后才会存在。
# 由于数据量太大,data数据只打印前5条文本数据及其类别
for i in range(5):
print(f"===== 第 {i+1} 条数据 =====")
print("内容:", newsgroups.data[i][:200] + "...") # 截取前100字符避免过长
print("类别:", newsgroups.target_names[newsgroups.target[i]])
print("\n")
print("数据集的标签名:\n",newsgroups.target_names)
print("数据集的标签数组:\n",newsgroups.target)
print("数据集的数据描述:\n",newsgroups.DESCR)- 支持按类别筛选(如
categories=['alt.atheism', 'sci.space'])。
查看打印内容
数据集的特征名:
报错未打印,参看下文解决
===== 第 1 条数据 =====
内容: From: Mamatha Devineni Ratnam <mr47+@andrew.cmu.edu>
Subject: Pens fans reactions
Organization: Post Office, Carnegie Mellon, Pittsburgh, PA
Lines: 12
NNTP-Posting-Host: po4.andrew.cmu.edu
I am sur...
类别: rec.sport.hockey
..............................................................
数据集的标签名:
['alt.atheism', 'comp.graphics', 'comp.os.ms-windows.misc', 'comp.sys.ibm.pc.hardware', 'comp.sys.mac.hardware', 'comp.windows.x', 'misc.forsale', 'rec.autos', 'rec.motorcycles', 'rec.sport.baseball', 'rec.sport.hockey', 'sci.crypt', 'sci.electronics', 'sci.med', 'sci.space', 'soc.religion.christian', 'talk.politics.guns', 'talk.politics.mideast', 'talk.politics.misc', 'talk.religion.misc']
数据集的标签数组:
[10 3 17 ... 3 1 7]
数据集的数据描述:
**Data Set Characteristics:**
================= ==========
Classes 20
Samples total 18846
Dimensionality 1
Features text
================= ==========
.. dropdown:: Usage
The :func:`sklearn.datasets.fetch_20newsgroups` function is a data
fetching / caching functions that downloads the data archive from直接获取向量化特征
from sklearn.datasets import fetch_20newsgroups_vectorized
newsgroups = fetch_20newsgroups_vectorized(subset='train')
# 特征名太多,采用如下方式打印:
print('总特征数:',len(newsgroups.feature_names))
for item in newsgroups.feature_names:
print(item,end=' ')
print("数据集的特征数据:\n",newsgroups.data)
print("数据集的标签名:\n",newsgroups.target_names)
print("数据集的标签数组:\n",newsgroups.target)
print("数据集的数据描述:\n",newsgroups.DESCR)- 返回 TF-IDF 或词频矩阵,跳过手动向量化步骤。
查看打印结果
总特征数: 130107
00 000 0000 00000 000000 00000000 0000000004 0000000005 00000000b 00000001 00000001b 0000000667 00000010 00000010b 00000011 00000011b 0000001200 00000074 00000093 000000e5 00000100 00000100b 00000101 00000101b 00000110 00000110b 00000111 00000111b 00000315 000005102000 00000510200001 000007 00000ee5 00001000 00001000b 00001001 00001001b 00001010 00001010b 00001011 00001011b
...
zwl76 zwo2bz zwow zwp4q zwr zwrf zwrm zws zwt zwx zx zx0 zx3k zx6wre zx8 zx900 zx900a zxgxrggwf6wp2edst zxl0 zxmkr08 zxp zxqi zxrm5v zxu_z_a zxw zxxst zxyiss zxz zy zy1 zy15 zy4 zy5 zya7hp zyc zycg zyckp zydjepqzl2 zye zyeh zyg zygot zyj zyjb6 zyklon zymmr zyr zyra zysec zysgm3r zysv zyt zyu zyv zyxel zyxel1496b zz zz20d zz93sigmc120 zz_g9q3 zzcrm zzd zzg6c zzi776 zzneu zznki zznkj zznkjz zznkzz zznp zzo zzr11 zzr1100 zzrk zzt zztop zzy_3w zzz zzzoh zzzz zzzzzz zzzzzzt ªl ³ation º_________________________________________________º_____________________º ºnd çait çon ère ée égligent élangea érale ête íålittin ñaustin ýé
数据集的特征数据:
<Compressed Sparse Row sparse matrix of dtype 'float64'
with 1787565 stored elements and shape (11314, 130107)>
Coords Values
(0, 5022) 0.017109647770728872
(0, 5886) 0.017109647770728872
(0, 6214) 0.017109647770728872
...
(11313, 128420) 0.035555906726738896
(11313, 128436) 0.035555906726738896
数据集的标签名:
['alt.atheism', 'comp.graphics', 'comp.os.ms-windows.misc', 'comp.sys.ibm.pc.hardware', 'comp.sys.mac.hardware', 'comp.windows.x', 'misc.forsale', 'rec.autos', 'rec.motorcycles', 'rec.sport.baseball', 'rec.sport.hockey', 'sci.crypt', 'sci.electronics', 'sci.med', 'sci.space', 'soc.religion.christian', 'talk.politics.guns', 'talk.politics.mideast', 'talk.politics.misc', 'talk.religion.misc']
数据集的标签数组:
[17 7 10 ... 14 12 11]
数据集的数据描述:
.. _20newsgroups_dataset:
The 20 newsgroups text dataset
------------------------------
The 20 newsgroups dataset comprises around 18000 newsgroups posts on
20 topics split in two subsets: one for training (or development)预处理关键建议
- 过滤元数据:使用
remove=('headers', 'footers', 'quotes')移除页眉、页脚和引用内容,避免模型过拟合无关信息(如发件人、时间戳)。
data = fetch_20newsgroups(subset='train', remove=('headers', 'footers', 'quotes')) 向量化处理:常用 TfidfVectorizer 将文本转为数值特征(如示例中生成长度为 34,118 维的稀疏矩阵)。
典型问题与注意事项
- 过拟合风险:原始数据中的元数据(如邮件头)可能被模型误用,导致评估结果虚高(如 F1 从 0.88 降至 0.77 清理后)。
- 文化偏见:数据集包含历史文本(如涉及种族敏感内容),需警惕在 NLP 任务中传播偏见。
- 高维度稀疏性:文本向量化后特征维度极高(如 3 万+),但稀疏性强(平均每样本仅 159 个非零值)。
应用场景
- 文本分类:如区分科技与体育新闻。
- 模型对比:测试不同分类器(如朴素贝叶斯、SVM)在文本任务中的表现。
- 特征工程研究:探索词袋模型、哈希技巧、主题建模等方法的效果。
生成模拟数据集
用于自定义数据分布或测试模型。
常用函数
| 函数名 | 用途 | 关键参数 |
|---|---|---|
make_classification() |
生成分类数据 | n_samples, n_features, n_classes |
make_regression() |
生成回归数据 | n_samples, n_features, noise |
make_blobs() |
生成聚类数据 | n_samples, centers, cluster_std |
make_circles() |
生成非线性可分数据 | n_samples, noise, factor |
生成分类数据
from sklearn.datasets import make_classification
# 生成分类数据(1000样本,20特征,3类别)
X, y = make_classification(
n_samples=1000,
n_features=20,
n_classes=3,
n_informative=5,
random_state=42
)
# 生成回归数据(带噪声)
X_reg, y_reg = make_regression(
n_samples=200,
n_features=10,
noise=0.1,
random_state=42
)生成聚类数据
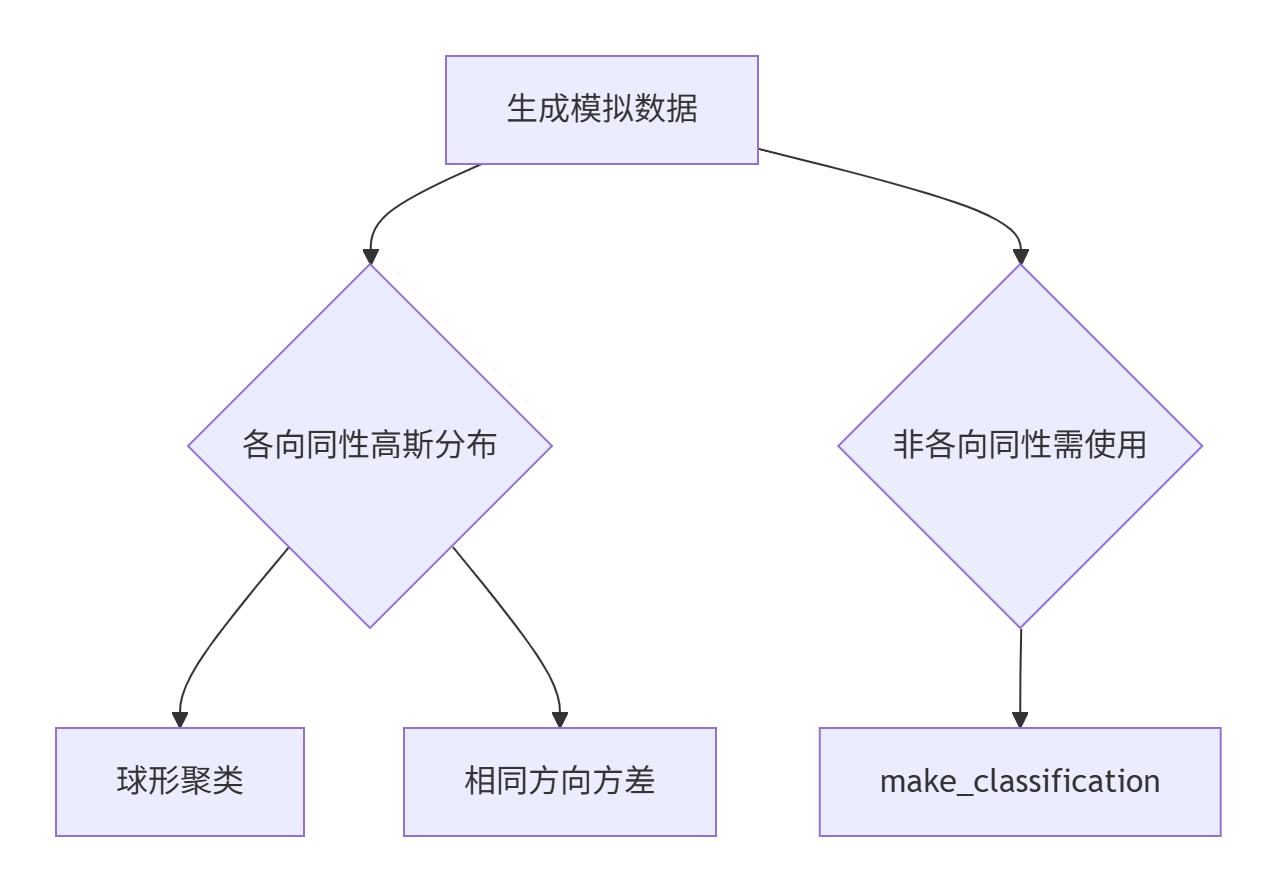
make_blobs 是 scikit-learn 中用于生成模拟聚类数据的关键工具函数,特别适用于机器学习算法的测试和可视化。
核心功能解析
make_blobs 生成各向同性的高斯分布数据集,这意味着数据集中的每个聚类呈球形分布(在各维度上具有相同的方差)。
参数详细说明
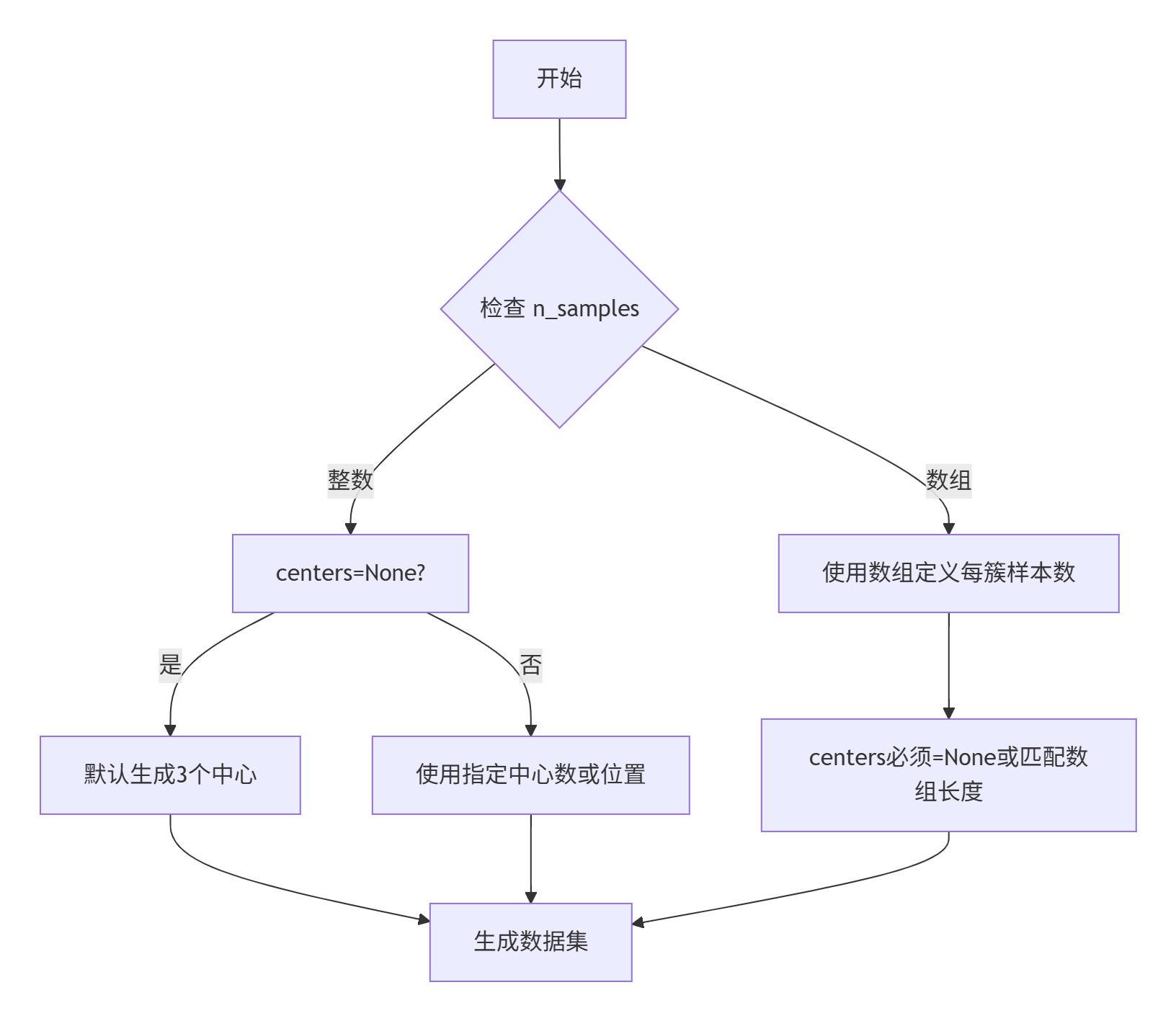
1. 基础参数
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
n_samples |
int 或 array-like | 100 | 总样本数或每簇样本数 |
n_features |
int | 2 | 每个样本的特征数 |
centers |
int 或 array-like | None | 聚类中心数或中心位置 |
cluster_std |
float 或 array-like | 1.0 | 聚类的标准差(控制紧密程度) |
center_box |
tuple | (-10.0, 10.0) | 中心生成的边界框 |
shuffle |
bool | True | 是否打乱样本顺序 |
random_state |
int/None | None | 随机数种子 |
return_centers |
bool | False | 是否返回中心坐标 |
2. 参数交互逻辑
典型使用场景
1. 基础聚类测试
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
# 生成400个样本,4个聚类
X, y = make_blobs(n_samples=400, centers=4,
cluster_std=0.8, random_state=0)
plt.figure(figsize=(8, 6))
plt.scatter(X[:, 0], X[:, 1], c=y, cmap='viridis', s=50, alpha=0.8)
plt.title("基本聚类数据集")
plt.xlabel("特征1")
plt.ylabel("特征2")
plt.show() 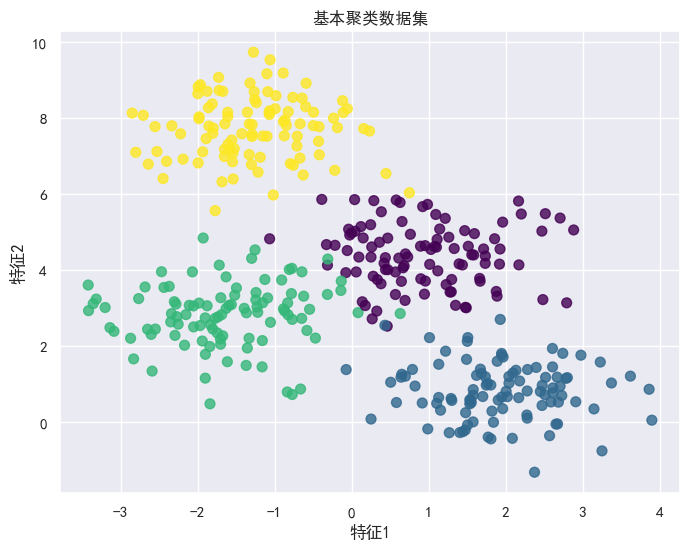
2. 不同聚类密度
# 不同聚类的不同样本数
X, y = make_blobs(n_samples=[100, 200, 150], centers=None,
cluster_std=[0.5, 1.0, 1.5], random_state=42)
plt.figure(figsize=(10, 8))
for i in range(3):
cluster_mask = (y == i)
plt.scatter(X[cluster_mask, 0], X[cluster_mask, 1],
s=50, label=f'簇 {i}')
plt.legend()
plt.title("不同大小的聚类")
plt.xlabel("特征1")
plt.ylabel("特征2")
plt.grid(alpha=0.3)
plt.show() 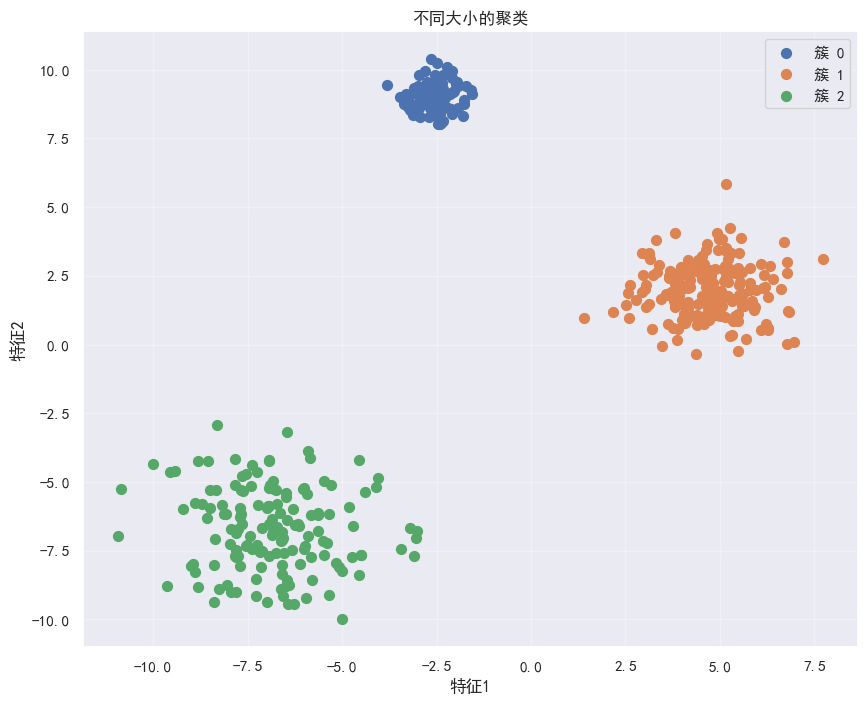
3. 多类分类问题
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
# 生成5类数据集
X, y = make_blobs(n_samples=1000, centers=5,
n_features=3, cluster_std=0.9, random_state=7)
# 划分训练测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 训练模型
clf = RandomForestClassifier(random_state=42)
clf.fit(X_train, y_train)
print(f"准确率: {clf.score(X_test, y_test):.2f}")4. 高维数据可视化
from sklearn.decomposition import PCA
# 生成100维数据
X, y = make_blobs(n_samples=500, centers=3,
n_features=100, random_state=3)
# 降维可视化
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
plt.figure(figsize=(8, 6))
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=y, cmap='viridis', s=50)
plt.title("100维数据在PCA空间中的分布")
plt.xlabel("主成分1")
plt.ylabel("主成分2")
plt.show()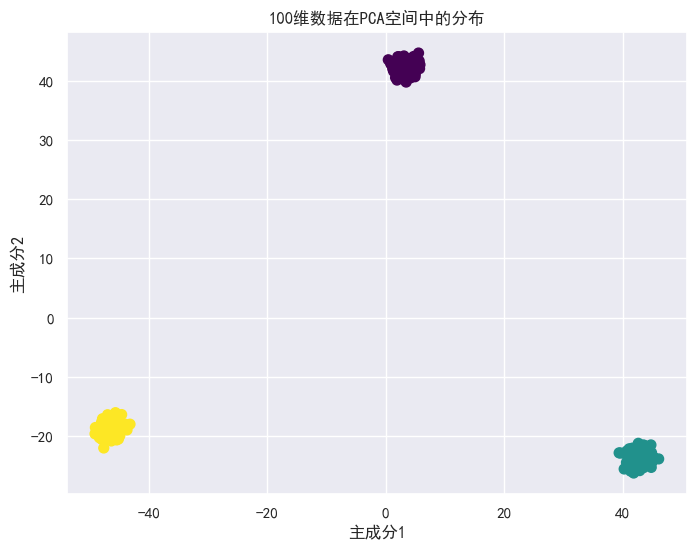
高级应用技巧
1. 创建非线性可分数据
import numpy as np
# 生成同心圆数据(使用坐标变换)
def make_concentric_blobs(n_samples=500):
# 生成基础数据
X, y = make_blobs(n_samples=n_samples, centers=1,
cluster_std=0.3, random_state=1)
# 添加第二圈
X2, y2 = make_blobs(n_samples=n_samples, centers=1,
cluster_std=0.7, random_state=2)
# 合并并变换为圆环状
X_combined = np.vstack((X, X2 * 2))
y_combined = np.hstack((np.zeros(n_samples), np.ones(n_samples)))
return X_combined, y_combined
# 可视化同心圆数据
X_c, y_c = make_concentric_blobs()
plt.scatter(X_c[:, 0], X_c[:, 1], c=y_c, cmap='bwr', s=30)
plt.title("非线性可分数据")
plt.show() 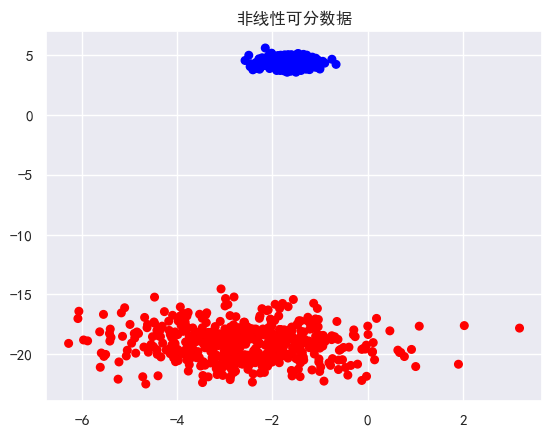
2. 复杂聚类形状
# 创建复杂形状聚类
def make_complex_clusters():
# 第一组:大范围聚类
X1, y1 = make_blobs(n_samples=300, centers=1,
cluster_std=0.8, center_box=(-2, 0), random_state=0)
# 第二组:密集聚类
X2, y2 = make_blobs(n_samples=200, centers=1,
cluster_std=0.2, center_box=(1, 3), random_state=1)
# 第三组:椭圆状聚类(拉伸)
X3, y3 = make_blobs(n_samples=200, centers=1,
cluster_std=0.5, center_box=(-1, 4), random_state=2)
X3 = np.dot(X3, np.array([[0.6, 0.8], [0.8, 0.6]])) # 线性变换
# 合并数据
X_combined = np.vstack((X1, X2, X3))
y_combined = np.hstack((
np.zeros(300),
np.ones(200),
np.full(200, 2)
))
return X_combined, y_combined
# 可视化复杂聚类
X_cc, y_cc = make_complex_clusters()
plt.scatter(X_cc[:, 0], X_cc[:, 1], c=y_cc, cmap='viridis', s=30, alpha=0.7)
plt.title("复杂形状聚类数据集")
plt.show()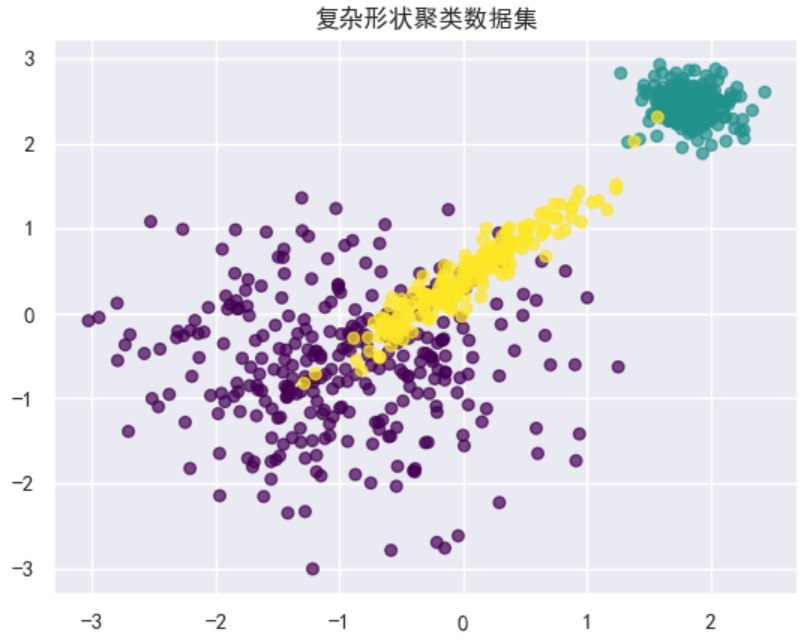
与 make_classification 的对比
| 特性 | make_blobs |
make_classification |
|---|---|---|
| 聚类形状 | 各向同性(球形) | 任意方向 |
| 数据结构 | 简单高斯分布 | 复杂结构(冗余/无关特征) |
| 类间关系 | 无类间依赖 | 可添加类间依赖 |
| 特征性质 | 所有特征相关 | 可添加无关/冗余特征 |
| 适用场景 | 基础聚类/分类 | 复杂分类任务测试 |
| 可视化 | 2D/3D直观 | 高维复杂 |
| 生成速度 | 快 | 较慢 |
注意事项
-
特征空间理解:
- 当
n_features > 3时,数据难以直接可视化 - 使用降维技术(PCA、t-SNE)探索高维结构
- 当
-
算法适用性
局限性补充:
make_blobs生成线性可分的球形聚类- 对于需要测试复杂边界的算法,需使用
make_moons或make_circles - 对噪声敏感的算法,可手动添加噪声点:
X, y = make_blobs(n_samples=490, centers=3, random_state=1) noise = np.random.uniform(low=X.min(), high=X.max(), size=(10, 2)) X_noise = np.vstack([X, noise]) y_noise = np.hstack([y, np.zeros(10) - 1]) # 标记噪声为-1
加载已弃用数据集(不推荐)
如波士顿房价数据集 (load_boston),因伦理问题已移除。若需使用,需手动加载:
import pandas as pd
import numpy as np
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
feature_names = ["CRIM", "ZN", "INDUS", "CHAS", "NOX", "RM", "AGE",
"DIS", "RAD", "TAX", "PTRATIO", "B", "LSTAT"]
X_boston = pd.DataFrame(data, columns=feature_names)
y_boston = pd.Series(target, name="MEDV")注意事项
- 数据标准化:加载后需标准化(如
StandardScaler),尤其是使用 SVM 或神经网络时。 - 类别特征处理:文本或类别型数据需编码(如
OneHotEncoder)。 - 大数据集内存问题:MNIST 等大型数据集加载时可能消耗较多内存,建议使用
as_frame=False。 - 网络依赖:
fetch_*方法需联网下载数据,首次使用可能较慢。
总结
| 场景 | 推荐方法 |
|---|---|
| 快速测试/教学 | load_iris(), load_digits() |
| 回归任务 | fetch_california_housing() |
| 大规模分类 | fetch_openml(name="mnist_784") |
| 生成自定义数据 | make_classification() |
| 研究伦理问题(不推荐) | 手动加载波士顿数据集 |
数据预处理
缺失值处理
填充缺失值
SimpleImputer 是 scikit-learn 中用于填充缺失值的核心工具,它提供了多种简单而有效的策略来处理数据中的 NaN 值。
基本参数详解
| 参数 | 默认值 | 描述 |
|---|---|---|
missing_values |
np.nan |
标识缺失值的标记(可自定义) |
strategy |
'mean' |
填充策略:mean/median/most_frequent/constant |
fill_value |
None |
常量填充时的指定值 |
copy |
True |
是否创建数据副本 |
add_indicator |
False |
是否添加缺失值指示器 |
填充策略对比
| 策略 | 适用场景 | 特点 | 注意事项 |
|---|---|---|---|
'mean' |
连续数值特征 | 使用列平均值填充 | 对异常值敏感 |
'median' |
连续数值特征 | 使用列中位数填充 | 鲁棒性更强 |
'most_frequent' |
分类或离散数值 | 使用列众数填充 | 适用于低基数特征 |
'constant' |
所有类型 | 自定义固定值填充 | 需指定fill_value |
完整使用示例
1. 基本数值填充
import numpy as np
from sklearn.impute import SimpleImputer
# 创建带缺失值的示例数据
X = np.array([[1, 2, np.nan],
[3, np.nan, 4],
[np.nan, 5, 6]])
# 使用中位数填充
imputer = SimpleImputer(strategy='median')
X_filled = imputer.fit_transform(X)
"""
原始数据:
[[ 1. 2. nan]
[ 3. nan 4.]
[nan 5. 6.]]
填充后:
[[1. 2. 5.] # 第三列中位数 = (4+6)/2 = 5
[3. 3.5 4.] # 第二列中位数 = 3.5
[2. 5. 6.]] # 第一列中位数 = 2
"""2. 分类特征处理
# 分类特征数据
cat_data = np.array([['A', np.nan, 'B'],
[np.nan, 'C', 'B'],
['A', 'C', np.nan]])
# 使用众数填充
cat_imputer = SimpleImputer(strategy='most_frequent')
cat_filled = cat_imputer.fit_transform(cat_data)
"""
原始数据:
[['A' nan 'B']
[nan 'C' 'B']
['A' 'C' nan]]
填充后:
[['A' 'C' 'B'] # 第二列众数=C, 第三列众数=B
['A' 'C' 'B'] # 第一列众数=A
['A' 'C' 'B']]
"""3. 高级功能:缺失值指示器
# 添加缺失值指示器
imputer = SimpleImputer(
strategy='constant',
fill_value=-1,
add_indicator=True # 添加指示器列
)
X_indicator = imputer.fit_transform(X)
"""
输出:
[[ 1. 2. -1. 0. 0. 1.] # 原始列 + 指示器列
[ 3. -1. 4. 0. 1. 0.]
[-1. 5. 6. 1. 0. 0.]]
指示器列说明:
末三列为: [第一列缺失?, 第二列缺失?, 第三列缺失?]
"""实际应用场景
1. 在Pipeline中集成
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
# 创建数据处理管道
pipeline = Pipeline([
('imputer', SimpleImputer(strategy='mean')),
('scaler', StandardScaler()),
('classifier', RandomForestClassifier())
])
# 训练模型(自动处理缺失值)
pipeline.fit(X_train, y_train)2. 不同列使用不同策略
from sklearn.compose import ColumnTransformer
# 指定数值列和分类列
numeric_features = ['age', 'income']
categorical_features = ['gender', 'city']
# 为不同类型列创建不同处理器
preprocessor = ColumnTransformer([
('num', SimpleImputer(strategy='median'), numeric_features),
('cat', SimpleImputer(strategy='most_frequent'), categorical_features)
])
# 应用转换器
X_processed = preprocessor.fit_transform(X)最佳实践指南
-
数据探索先行
# 计算每列缺失率
missing_ratio = X.isna().mean(axis=0)
# 可视化缺失值分布
import seaborn as sns
sns.heatmap(X.isna(), cbar=False)-
策略选择建议
- 连续特征:
median(抗异常值)或mean - 分类特征:
most_frequent - 时间序列:前向填充(
ffill)或后向填充(bfill)-
# 使用插值代替SimpleImputer X['timestamp'].fillna(method='ffill', inplace=True)
-
- 连续特征:
-
处理高缺失率特征
# 若缺失率>60%,考虑删除该列
high_missing_cols = [col for col in X.columns if X[col].isna().mean() > 0.6]
X.drop(columns=high_missing_cols, inplace=True)
多列不同处理策略
ColumnTransformer 是 scikit-learn 中用于对数据集的不同列应用不同预处理流程的核心工具。它完美解决了混合类型数据(数值型、分类型、文本型等)的预处理问题。
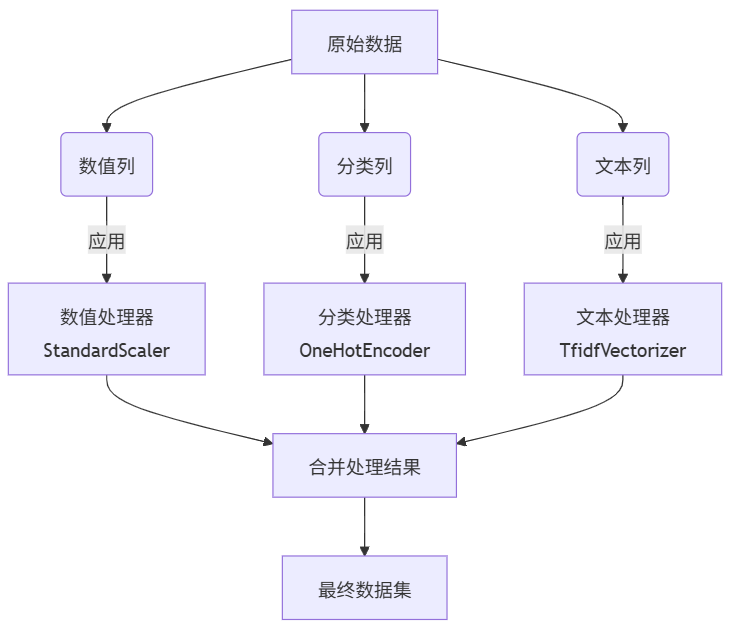
基础参数解析
| 参数 | 描述 | 常用选项 |
|---|---|---|
transformers |
转换器列表 | ('name', transformer, columns) |
remainder |
未指定列的处理 | 'drop' 或 'passthrough' |
sparse_threshold |
稀疏矩阵处理阈值 | 0.0-1.0 |
n_jobs |
并行作业数 | None 或整数 |
verbose |
输出详细程度 | True/False |
verbose_feature_names_out |
输出特征名详细程度 | True/False |
完整使用示例
示例数据准备
import pandas as pd
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
# 创建示例数据
data = pd.DataFrame({
'age': [25, 30, 35],
'income': [50000, 80000, 120000],
'gender': ['M', 'F', 'M'],
'city': ['NY', 'LA', 'SF']
})基础应用
# 定义列处理规则
preprocessor = ColumnTransformer(
transformers=[
('num', StandardScaler(), ['age', 'income']), # 数值列:标准化
('cat', OneHotEncoder(), ['gender', 'city']) # 分类列:独热编码
],
remainder='drop' # 未提及的列丢弃
)
# 应用转换
transformed_data = preprocessor.fit_transform(data)
# 查看处理后的特征名
print(preprocessor.get_feature_names_out())
# 输出: ['num__age', 'num__income', 'cat__gender_F', 'cat__gender_M', 'cat__city_LA', 'cat__city_NY', 'cat__city_SF']高级应用:保留原始列+自定义列
# 创建包含自定义转换的复杂处理器
from sklearn.preprocessing import FunctionTransformer
# 定义日志转换器
log_transformer = FunctionTransformer(np.log1p, validate=True)
preprocessor = ColumnTransformer(
transformers=[
('num_scale', StandardScaler(), ['age']), # 年龄标准化
('num_log', log_transformer, ['income']), # 收入取对数
('cat_ohe', OneHotEncoder(drop='first'), ['city']), # 城市首类丢弃
('cat_target', 'passthrough', ['gender']) # 性别列保留原始值
],
remainder='passthrough' # 保留未提及列
)
# 处理数据
processed_data = preprocessor.fit_transform(data)
# 查看输出维度
print(f"处理前形状: {data.shape}, 处理后形状: {processed_data.shape}")
# 输出: 处理前形状: (3, 4), 处理后形状: (3, 6)应用场景
场景1:混合类型特征处理
# 数值特征:标准化/归一化
# 分类特征:独热编码/目标编码
# 文本特征:TF-IDF/词嵌入
preprocessor = ColumnTransformer([
('num', StandardScaler(), num_cols),
('cat', OneHotEncoder(), cat_cols),
('text', TfidfVectorizer(), 'review_text')
])
数据集的划分
机器学习⼀般的数据集会划分为两个部分:
- 训练数据:⽤于训练,构建模型
- 测试数据:在模型检验时使⽤,⽤于评估模型是否有效
划分⽐例:
- 训练集:70% 80% 75%
- 测试集:30% 20% 25%
数据集划分api
train_test_split
sklearn.model_selection.train_test_split(arrays, *options)参数:
- x 数据集的特征值
- y 数据集的标签值
- test_size 测试集的⼤⼩,⼀般为float
- random_state 随机数种⼦,不同的种⼦会造成不同的随机采样结果。相同的种⼦采样结果相同。
return:
- data_train, data_test, target_train, target_test
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
import pandas as pd
import numpy as np
# 获取数据
iris = load_iris()
# 测试集训练集拆分
data_train, data_test, target_train, target_test = train_test_split(iris.data, iris.target, test_size=0.2,random_state=42)
print("训练集数据:\n", data_train)
print("测试集数据:\n", data_test)
print("训练集标签:\n", target_train)
print("测试集标签:\n", target_test)
print('*' * 50)
# 数据加工为Dataframe类型,然后拆分
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df['target'] = iris.target
test, train = train_test_split(df, test_size=0.2)
# print('测试集:\n',test)
# print('训练集:\n',train)
print('=' * 50)
# 随机种子
# 测试集训练集拆分
data_train1, data_test1, target_train1, target_test1 = train_test_split(iris.data, iris.target, test_size=0.2,random_state=666)
data_train2, data_test2, target_train2, target_test2 = train_test_split(iris.data, iris.target, test_size=0.2,random_state=666)
print("随机数种子不同的情况,获取数据是否相同:", np.all(data_test == data_test1))
print("随机数种子相同的情况,获取数据是否相同:", np.all(data_test2 == data_test1))查看打印结果
训练集数据:
[[4.6 3.6 1. 0.2]
[5.7 4.4 1.5 0.4]
[6.7 3.1 4.4 1.4]
...共计120条...
[7.1 3. 5.9 2.1]]
测试集数据:
[[6.1 2.8 4.7 1.2]
...共计30条...
[4.8 3.1 1.6 0.2]]
训练集标签:
[0 0 1 0 0 2 1 0 0 0 2 1 1 0 0 1 2 2 1 2 1 2 1 0 2 1 0 0 0 1 2 0 0 0 1 0 1
2 0 1 2 0 2 2 1 1 2 1 0 1 2 0 0 1 1 0 2 0 0 1 1 2 1 2 2 1 0 0 2 2 0 0 0 1
2 0 2 2 0 1 1 2 1 2 0 2 1 2 1 1 1 0 1 1 0 1 2 2 0 1 2 2 0 2 0 1 2 2 1 2 1
1 2 2 0 1 2 0 1 2]
测试集标签:
[1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0]
**************************************************
==================================================
随机数种子不同的情况,获取数据是否相同: False
随机数种子相同的情况,获取数据是否相同: TrueStratifiedShuffleSplit
train_test_split 和 StratifiedShuffleSplit 是 scikit-learn 库中两个常用的数据集划分工具,它们有不同的应用场景。
核心区别:
-
train_test_split: 进行简单随机分割。它随机打乱数据,然后按指定比例(如 80%训练,20%测试)进行划分。它不保证训练集和测试集中目标变量(通常是分类标签)的分布与原始数据集相同。 -
StratifiedShuffleSplit: 进行分层随机分割。它在划分时会确保训练集和测试集中目标变量(分类标签)的类别比例与原始数据集中的比例保持一致。
详细对比:
| 特性 | train_test_split (from sklearn.model_selection) |
StratifiedShuffleSplit (from sklearn.model_selection) |
|---|---|---|
| 分割类型 | 简单随机分割 | 分层随机分割 |
| 目标变量处理 | 不考虑目标变量的分布。 | 强制保持训练集和测试集中目标变量类别的分布比例一致。 |
| 主要用途 | 通用数据集划分,尤其当目标变量分布均匀或用于回归问题时。 | 分类问题,特别是当目标变量类别分布不平衡时至关重要。 |
| 输出 | 直接返回划分好的 X_train, X_test, y_train, y_test 数组。 |
返回一个生成器,产生多个 (train_index, test_index) 元组。需要循环获取索引,然后手动用索引分割数据。 |
| 单次/多次划分 | 单次划分。 | 默认进行多次划分(n_splits 参数控制次数)。 |
| 关键参数 | test_size/train_size, random_state, shuffle |
n_splits, test_size/train_size, random_state |
| 数据打乱 | 默认打乱 (shuffle=True)。 |
总是打乱数据。 |
| 适用场景 | * 回归问题。 * 分类问题且目标类别分布非常均匀。 * 快速简单的单次划分。 |
* 分类问题且目标类别分布不平衡。 * 需要确保评估集能代表所有类别。 * 需要多次随机划分(如交叉验证的一种形式)。 |
为什么“分层”很重要(尤其是在分类问题中)?
想象一个数据集,其中 95% 的样本属于类别 A,只有 5% 属于类别 B(这是一个典型的不平衡数据集)。
- 使用
train_test_split:由于是随机分割,测试集中类别 B 的样本比例可能远低于 5%(甚至可能为 0%!),或者远高于 5%。这会导致严重问题:- 如果测试集中 B 类样本太少,模型在 B 类上的性能评估就不可靠(可能高估或低估)。
- 如果测试集中 B 类样本比例过高(纯随机也可能发生),模型在 A 类上的性能评估可能不准确。
- 总之,评估结果不能真实反映模型处理实际数据分布(95% A, 5% B)的能力。
- 使用
StratifiedShuffleSplit:它会确保无论你划分多少次,训练集和测试集中都精确地包含大约 95% 的 A 类样本和 5% 的 B 类样本(比例与原始数据一致)。这保证了:- 模型在训练时能看到各类别的代表性样本。
- 模型在测试集上的性能评估(如准确率、召回率、F1)能更真实地反映其在实际数据分布上的表现。
使用示例:
-
train_test_split(简单随机分割): -
StratifiedShuffleSplit(分层随机分割):
总结与选择建议:
- 使用
train_test_split:- 当你进行回归任务时。
- 当你的分类任务的目标类别分布非常均匀时。
- 当你只需要一个快速、简单的单次训练/测试划分时。
- 使用
StratifiedShuffleSplit:- 当你进行分类任务,并且目标类别分布不平衡时(强烈推荐)。
- 当你需要确保训练集和测试集能准确反映原始数据的类别分布时。
- 当你需要多次随机划分(例如,进行类似交叉验证的多次评估)时。
简单来说: 如果你的数据是分类数据且类别不平衡,StratifiedShuffleSplit 是更安全、更能提供可靠评估结果的选择。train_test_split 则是一个更通用、更简单的工具,适用于不需要考虑类别比例或做回归的情况。
n_splits 的意义
-
重复划分的次数
n_splits指定算法执行随机分层划分的次数。每次划分都会产生一组不同的训练集和测试集索引组合。 -
类似交叉验证的模式
虽然名称不同,但设置n_splits>1使StratifiedShuffleSplit的工作方式类似交叉验证:- 每次划分都是独立的随机分层抽样
- 可以计算多个划分的平均性能(减少随机性的影响)
当需要多次划分评估模型稳定性时:
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
sss = StratifiedShuffleSplit(n_splits=5, # ← 进行5次独立划分
test_size=0.2,
random_state=42)
scores = []
# 遍历每次划分
for fold, (train_index, test_index) in enumerate(sss.split(X, y), 1):
# 获取数据
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
# 训练模型
model = RandomForestClassifier()
model.fit(X_train, y_train)
# 评估
y_pred = model.predict(X_test)
acc = accuracy_score(y_test, y_pred)
scores.append(acc)
print(f"Fold {fold} - Accuracy: {acc:.4f}")
# 计算平均性能
print(f"\nAverage Accuracy: {np.mean(scores):.4f} ± {np.std(scores):.4f}")n_splits 值 |
应用场景 | 优点 |
|---|---|---|
| 1 | 简单分割为训练集/测试集 | 快速简单,类似train_test_split但分层 |
| 5-10 | 评估模型稳定性 | 减少随机划分带来的方差 |
| >10 | 小样本数据集评估 | 最大化利用有限数据 |
StratifiedKFold
核心概念
StratifiedKFold 是 scikit-learn 中用于分类任务的交叉验证方法,其核心特点是:
- 分层保留 (Stratification):保持每个数据子集中类别比例与原始数据集一致
- K 折划分 (K-Folding):将数据平均分为 K 份("折")
- 交叉验证 (Cross-Validation):每份数据轮流作为测试集,其余作为训练集
✅ 主要应用场景:分类问题(尤其类别不平衡的数据集)
关键参数
| 参数 | 默认值 | 说明 |
|---|---|---|
n_splits |
5 | 交叉验证的折数 (K 值) |
shuffle |
False | 是否在划分前随机打乱数据 |
random_state |
None | 随机种子(确保结果可复现) |
分层特性示例
假设原始数据集:🍎苹果(60%) + 🍊橘子(40%)
代码实现
from sklearn.model_selection import StratifiedKFold
import numpy as np
# 示例数据(3个苹果,2个橘子)
X = np.array([[1], [2], [3], [4], [5]])
y = np.array(['🍎','🍎','🍎','🍊','🍊']) # 60%苹果,40%橘子
# 创建验证器(3折交叉验证)
skf = StratifiedKFold(n_splits=3, shuffle=True, random_state=42)
# 遍历每一折
for fold_idx, (train_idx, test_idx) in enumerate(skf.split(X, y)):
print(f"\nFold {fold_idx}:")
print(f"训练集索引: {train_idx} -> 标签: {y[train_idx]}")
print(f"测试集索引: {test_idx} -> 标签: {y[test_idx]}")查看打印结果
Fold 0:
训练集索引: [0 1 3] -> 标签: ['🍎' '🍎' '🍊']
测试集索引: [2 4] -> 标签: ['🍎' '🍊'] # 保持苹果:橘子=1:1
Fold 1:
训练集索引: [0 2 4] -> 标签: ['🍎' '🍎' '🍊']
测试集索引: [1 3] -> 标签: ['🍎' '🍊'] # 保持比例
Fold 2:
训练集索引: [1 2 3 4] -> 标签: ['🍎' '🍎' '🍊' '🍊']
测试集索引: [0] -> 标签: ['🍎'] # 测试集100%苹果是允许的(因样本量小)重要特性对比
| 方法 | 分层特性 | 数据重叠 | 适用场景 |
|---|---|---|---|
StratifiedKFold |
✅ 强制保持类别比例 | 测试集不重叠 | 标准交叉验证 |
KFold |
❌ 不保持比例 | 测试集不重叠 | 回归/平衡分类 |
StratifiedShuffleSplit |
✅ 保持比例 | 测试集可能重叠 | 自定义测试大小/多次划分 |
实践建议
-
处理不平衡数据首选
# 处理信用卡欺诈检测(欺诈<1%)
skf = StratifiedKFold(n_splits=5)结合评价指标使用
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import f1_score
f1_scores = []
for train_idx, test_idx in skf.split(X, y):
model = RandomForestClassifier().fit(X[train_idx], y[train_idx])
pred = model.predict(X[test_idx])
f1_scores.append(f1_score(y[test_idx], pred)) # 使用F1而非准确率
特征征程-特征预处理
什么是特征预处理
scikit-learn的解释
provides several common utility functions and transformer classes to change raw feature vectors into a
representation that is more suitable for the downstream estimators.
翻译过来:通过⼀些转换函数将特征数据转换成更加适合算法模型的特征数据过程

归⼀化/标准化
为什么我们要进⾏归⼀化/标准化?
特征的单位或者⼤⼩相差较⼤,或者某特征的⽅差相⽐其他的特征要⼤出⼏个数量级,容易影响(⽀配)⽬标结果,使得⼀些算法⽆法学习到其它的特征。
举例:约会对象数据
相亲约会对象数据,这个样本是男性的特征数据和评价数据,共三个特征:每年获得的飞行常客里程数、每周消费的冰淇淋公升数、玩游戏所消耗时间的百分比。标签为被女士评价的三个类别:1、不喜欢:2、魅力一般:3、极具魅力。原始数据里,飞行里程数对于结算结果或者说相亲结果影响较大,但是这三个特征同等重要。
data=pd.read_csv(r'D:\learn\000人工智能数据大全\黑马数据\科学计算数据\dating.txt',sep=',')
data.columns=['飞行里程','消耗冰激凌公升数','玩游戏时间占比','女士评价']
data
我们需要⽤到⼀些⽅法进⾏⽆量纲化,使不同规格的数据转换到同⼀规格。即,数值型数据的⽆量纲化。
归⼀化
通过对原始数据进⾏变换把数据映射到指定区间(默认为[0,1])之间:
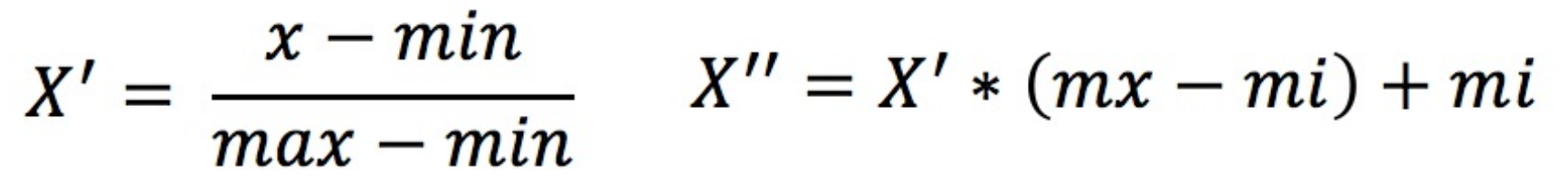
作⽤于每⼀列,max为⼀列的最⼤值,min为⼀列的最⼩值,那么 X″为最终结果,mx,mi分别为指定区间值。默认mx为1,mi为0。
API
- sklearn.preprocessing.MinMaxScaler (feature_range=(0,1)… )
- MinMaxScalar.fit_transform(X)
- X:numpy array格式的数据[n_samples,n_features]
- 返回值:转换后的形状相同的array
- MinMaxScalar.fit_transform(X)
from sklearn.preprocessing import MinMaxScaler
import pandas as pd
# 读取原始数据
data = pd.read_csv(r'D:\learn\000人工智能数据大全\黑马数据\科学计算数据\dating.txt', sep=',')
print(data.head())
print('=' * 50)
# 实例化转换器(定位器),指定要归一的范围大小(默认[0-1])
scaler = MinMaxScaler(feature_range=(0, 1))
# 归一化处理
fitdata = scaler.fit_transform(data[['milage', 'Liters', 'Consumtime']])
print(fitdata)查看打印结果
milage Liters Consumtime target
0 40920 8.326976 0.953952 3
1 14488 7.153469 1.673904 2
2 26052 1.441871 0.805124 1
3 75136 13.147394 0.428964 1
4 38344 1.669788 0.134296 1
==================================================
[[0.44832535 0.39805139 0.56233353]
[0.15873259 0.34195467 0.98724416]
[0.28542943 0.06892523 0.47449629]
...
[0.29115949 0.50910294 0.51079493]
[0.52711097 0.43665451 0.4290048 ]
[0.47940793 0.3768091 0.78571804]]
Process finished with exit code 0问题:如果数据中异常点较多,会有什么影响?

如果数据是动态的,那么最⼤值最⼩值是变化的,另外,最⼤值与最⼩值⾮常容易受异常点影响,所以这种⽅法鲁棒性较差,只适合传统精确⼩数据场景。
怎么办呢?在实际场景中应用较多的是标准化:
标准化
通过训练集的均值和标准差对数据进行线性变换,使得训练集的每个特征均值为0、标准差为1,并将此变换一致应用于测试集或其他新数据(均值不一定为0、标准差不一定为1)。
注意:
- 标准化 ≠ 正态化:标准化仅调整数据的均值和标准差。标准正态分布要求数据不仅均值为0、标准差为1,还需满足钟形对称的概率密度分布。
Z-Score(标准分数)是一种统计度量,用于描述数据点与数据集的均值之间的偏离程度,以标准差为单位。它是数据标准化(Standardization)的核心方法之一。
定义:
Z-Score表示某个数据点距离均值的标准差倍数。
公式:
![]()
其中:
- X:原始数据点,
- μ:数据集的均值,
- σ:数据集的标准差
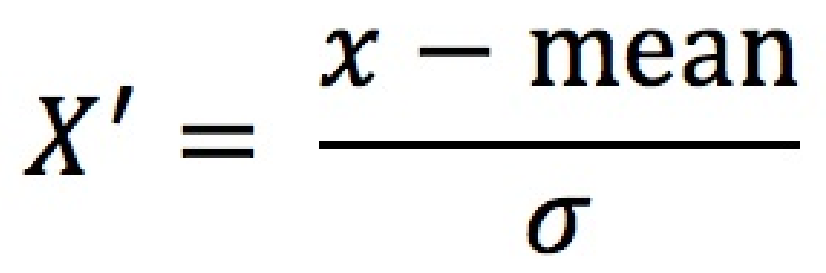
作⽤于每⼀列,mean为平均值,σ为标准差
所以回到刚才异常点的地⽅,我们再来看看归一化和标准化对比:
- 对于归⼀化来说:如果出现异常点,影响了最⼤值和最⼩值,那么结果显然会发⽣改变
- 对于标准化来说:如果出现异常点,由于具有⼀定数据量,少量的异常点对于平均值的影响并不⼤,从⽽⽅差改变较⼩。
API
(仅适用于训练集或者不区分训练集和测试集的数据)
- sklearn.preprocessing.StandardScaler( )
- 处理之后每列来说所有数据都聚集在均值0附近,标准差差为1
- StandardScaler.fit_transform(X)
- X:numpy array格式的数据[n_samples,n_features]
- 返回值:转换后的形状相同的array
from sklearn.preprocessing import StandardScaler
import pandas as pd
# 读取原始数据
data = pd.read_csv(r'D:\learn\000人工智能数据大全\黑马数据\科学计算数据\dating.txt', sep=',')
print(data.head())
print('=' * 50)
scaler = StandardScaler()
transformadata = scaler.fit_transform(data[['milage', 'Liters', 'Consumtime']])
print(transformadata)查看打印结果
milage Liters Consumtime target
0 40920 8.326976 0.953952 3
1 14488 7.153469 1.673904 2
2 26052 1.441871 0.805124 1
3 75136 13.147394 0.428964 1
4 38344 1.669788 0.134296 1
==================================================
[[ 0.33193158 0.41660188 0.24523407]
[-0.87247784 0.13992897 1.69385734]
[-0.34554872 -1.20667094 -0.05422437]
...
[-0.32171752 0.96431572 0.06952649]
[ 0.65959911 0.60699509 -0.20931587]
[ 0.46120328 0.31183342 1.00680598]]标准化在已有样本⾜够多的情况下⽐较稳定,适合现代嘈杂⼤数据场景。
数据泄露
先看一个例子
场景设定:学校考试分数标准化
假设你是老师,要将两个班级(训练集班级A和测试集班级B)的数学成绩转换成标准分,以便公平比较。
-
正确做法(用班级A的参数处理班级B)
- 步骤1:计算班级A的平均分(比如70分)和标准差(比如10分)。
- 步骤2:班级A的学生小明的分数是80分,他的标准分为:
z=(80−70)/10=1.0 - 步骤3:班级B的学生小红的分数是90分,但用班级A的参数转换:
z=(90−70)/10=2.0 - 意义:小红的标准分是2.0,说明她比班级A的平均分高2个标准差,这样两个班级的成绩可比。(假设A班成绩乘以5,B班成绩乘以1000,也就是两班的标准化参数不同,请问两班成绩还有可比性吗?)
-
错误做法(班级B独立标准化)
- 如果班级B自己计算平均分(比如85分)和标准差(比如5分),小红的分数转换后是:
z=(90−85)/5=1.0 - 后果:小红的标准分变成1.0,与班级A的小明“看起来”水平相同,但实际上她的绝对分数更高。这种比较是误导性的!
- 如果班级B自己计算平均分(比如85分)和标准差(比如5分),小红的分数转换后是:
无论是归一化还是标准化,如果对测试集和训练集都使用fit_transform()方法,那么就会出现数据泄露。以下案例以标准化为例进行讲解(归一化,同)。
我们先来看,对数据的训练集和测试集进行标准化,代码的正确写法和错误写法,然后再进一步解释:
# 正确流程
scaler.fit(train_data) # 训练集计算参数
#训练集和测试集使用共同的参数进行标准化(这样才有可比性)
train_scaled = scaler.transform(train_data)
test_scaled = scaler.transform(test_data)
# 错误流程(测试集用fit_transform会导致数据泄露)
test_scaled = scaler.fit_transform(test_data) # ❌ 绝对禁止!上面的正确等价写法:
scaler = StandardScaler()
train_scaled = scaler.fit_transform(train_data) # 训练集:计算参数并转换
test_scaled = scaler.transform(test_data) # 测试集:(使用上面的参数)直接标准化数据fit(data)
- 作用:计算数据的均值和标准差(用于后续标准化),但不转换数据。
- 返回值:返回
StandardScaler对象本身(可链式调用)。 - 用途:当需要先计算参数,再对不同数据集(如训练集和测试集)应用相同标准化时使用。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(train_data) # 计算训练集的均值和标准差
# 对训练集和测试集使用相同的均值和标准差进行标准化
train_scaled = scaler.transform(train_data)
test_scaled = scaler.transform(test_data)transform(data)
- 作用:使用
fit()阶段计算的均值和标准差,对数据进行标准化。 - 返回值:转换后的数据(NumPy数组或稀疏矩阵)。
- 用途:在已调用
fit()后,对数据应用标准化。
fit_transform(data)
- 作用:一次性完成两步操作:
-
fit(data):计算数据的均值和标准差。 -
transform(data):用刚计算的参数标准化数据。
-
- 返回值:转换后的数据(NumPy数组或稀疏矩阵)。
- 用途:仅适用于训练集,因为测试集应使用训练集的fit参数,避免数据泄露。
示例:
scaler = StandardScaler()
train_scaled = scaler.fit_transform(train_data) # 训练集:计算参数并标准化数据
test_scaled = scaler.transform(test_data) # 测试集:(使用上面的参数)直接标准化数据结果特性:
- 训练集:每个特征均值为0,标准差为1。
- 测试集:均值和标准差不一定为0和1,但保持了与训练集一致的尺度转换。
标准化的本质
公式:
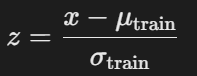
- 其中,μtrain 和 σtrain 是训练集的均值和标准差。
- 核心目的:消除特征量纲差异,使模型学习到稳定的统计规律。
错误做法:独立标准化训练集和测试集
# 错误!测试集独立标准化
X_train_scaled = scaler.fit_transform(X_train) # 训练集均值和标准差:μ1, σ1
X_test_scaled = scaler.fit_transform(X_test) # 测试集均值和标准差:μ2, σ2后果:
- 测试集被标准化为均值为0(基于自身 μ2)方差为1,但模型在训练时学习的是基于 μ1 的分布。
-
模型误以为测试集数据分布与训练集一致(不理解的话查看下面的解释)
案例解释
场景设定
- 训练集:某城市A的房价数据(单位:万元),均值为200万,标准差50万。
- 测试集:城市B的房价数据(单位:万元),均值为500万,标准差100万。
- 任务:预测房价。
正确做法(测试集复用城市A的参数)
- 训练集标准化:
- 城市A的房价标准化后均值为0,标准差为1。
- 测试集标准化(使用城市A的均值和标准差):
- 城市B的房价标准化后均值为 (500−200)/50=6,标准差为 (100)/50=2。
- 模型效果:
- 模型知道城市B的房价整体更高(均值6)、波动更大(标准差2),会调整预测策略,评估结果反映真实泛化能力。
错误做法(测试集独立标准化)
- 测试集独立标准化:
- 城市B的房价标准化后均值为0,标准差为1。
- 模型效果:
- 模型误以为城市B的房价分布与城市A相同(均值为0,标准差为1),预测时忽略实际高价,结果严重低估房价。
正确做法:训练集计算参数,测试集复用参数
# 正确!测试集复用训练集的参数
X_train_scaled = scaler.fit_transform(X_train) # 计算 μ1, σ1
X_test_scaled = scaler.transform(X_test) # 应用 μ1, σ1结果:

标准化参数必须来自训练集:测试集应视为“未来未知数据”,禁止使用其自身统计量。
- 数据泄露:测试集独立标准化会导致模型“作弊”,破坏评估可信度。
- 测试集标准化后的分布:均值不一定为0,标准差不一定为1,但这是正确且必要的。
数据泄露的本质
- 泄露形式:测试集独立标准化时,其自身统计量(均值、标准差)被隐式用于模型训练(如特征工程)。
分类标签转换为数值型标签
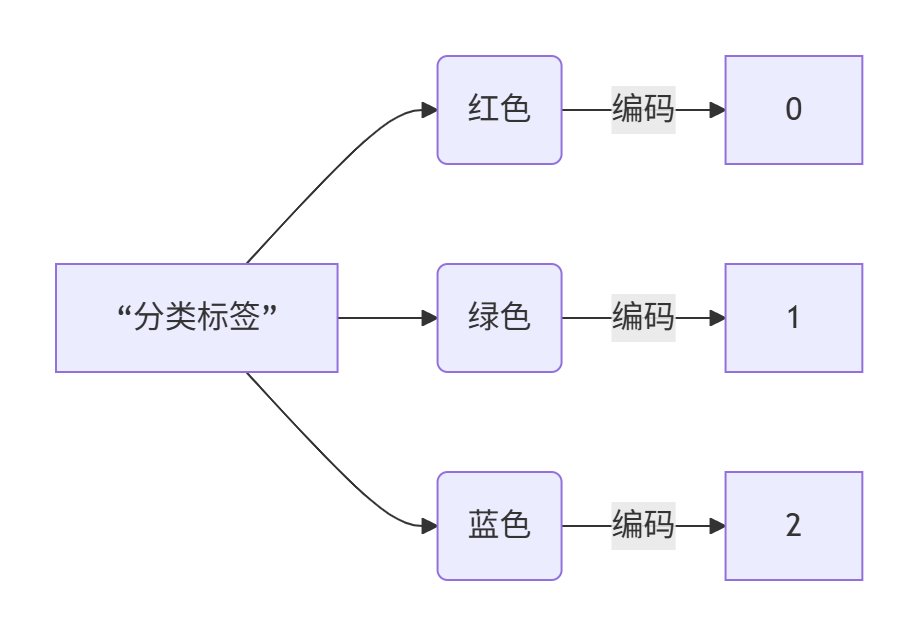
LabelEncoder 是 scikit-learn 库中的一个工具,用于将分类标签(字符串或整数)转换为数值型标签。在机器学习任务中,大多数算法要求目标变量(标签)是数值型的,因此标签编码是数据预处理的重要步骤。
核心功能与原理
基本用法
from sklearn.preprocessing import LabelEncoder
# 创建示例标签数据
labels = ['红色', '绿色', '蓝色', '绿色', '红色']
# 创建编码器
le = LabelEncoder()
# 拟合并转换数据
encoded_labels = le.fit_transform(labels)
print(encoded_labels) # 输出: [2 1 0 1 2]实际案例
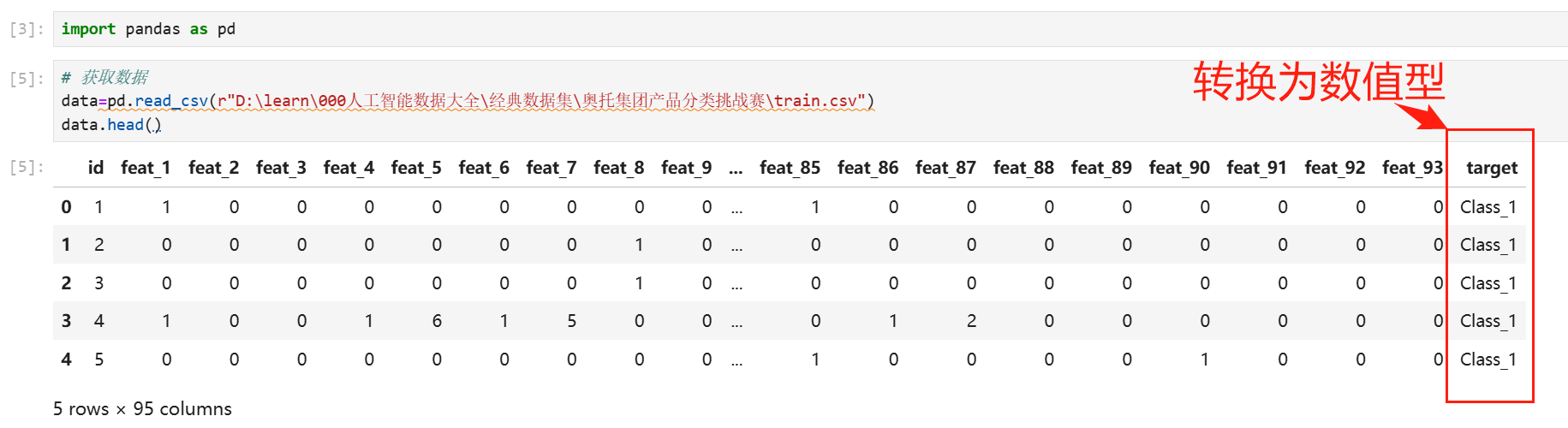
关键方法
| 方法 | 功能 | 示例 |
|---|---|---|
fit() |
学习标签的唯一值 | le.fit(['A','B','C']) |
transform() |
转换标签为编码值 | le.transform(['A','B']) → [0,1] |
fit_transform() |
拟合并转换一步完成 | le.fit_transform(labels) |
inverse_transform() |
还原编码为原始标签 | le.inverse_transform([0,1]) → ['A','B'] |
属性解析
| 属性 | 描述 | 示例 |
|---|---|---|
classes_ |
存储所有唯一类标签(按字母排序) | ['blue', 'green', 'red'] |
n_classes |
标签唯一值的数量 | 3 |
完整使用示例
from sklearn.preprocessing import LabelEncoder
# 示例数据:三种水果类型
fruits = ['apple', 'banana', 'cherry', 'apple', 'banana', 'cherry', 'apple']
# 初始化编码器
le = LabelEncoder()
# 训练并转换数据
encoded_fruits = le.fit_transform(fruits)
# 查看结果
print("原始数据:", fruits)
print("编码结果:", encoded_fruits) # [0 1 2 0 1 2 0]
print("类别映射:", le.classes_) # ['apple' 'banana' 'cherry']
print("苹果编码:", le.transform(['apple'])) # [0]
print("解码2:", le.inverse_transform([2])) # ['cherry']
注意事项与限制
-
顺序性假设问题:
- LabelEncoder 会对类别自动排序(按字母顺序)
- 可能引入人为的顺序关系(如:0<1<2)
- 解决方案:对于无序特征,使用
OneHotEncoder代替
-
缺失值处理:
新类别问题:
# 尝试编码未知标签会引发错误
try:
le.transform(['new_category'])
except ValueError as e:
print(e) # 'y contains previously unseen labels: ['new_category']'替代方案比较
| 工具 | 适用场景 | 特点 |
|---|---|---|
| LabelEncoder | 目标变量编码 | 简单快速,创建单一数值列 |
| OrdinalEncoder | 特征编码 | 专门处理特征而非标签 |
| OneHotEncoder | 分类特征 | 创建二值列,避免顺序假设 |
| pd.factorize() | Pandas环境 | 类似LabelEncoder但返回元组 |
何时使用 OneHotEncoder
当类别是名义变量(无序)时:
from sklearn.preprocessing import OneHotEncoder
import numpy as np
# 无序颜色数据
colors = np.array(['red', 'green', 'blue']).reshape(-1,1)
# 使用OneHotEncoder
ohe = OneHotEncoder(sparse=False)
encoded_colors = ohe.fit_transform(colors)
"""
输出:
array([[0., 0., 1.], # red
[0., 1., 0.], # green
[1., 0., 0.]]) # blue
"""分类特征编码为整数数组
OrdinalEncoder 是 scikit-learn 中用于将分类特征编码为整数数组的工具。与 LabelEncoder(仅适用于单个目标变量)不同,它专门设计用于处理特征矩阵中的分类特征。

基本用法
from sklearn.preprocessing import OrdinalEncoder
import numpy as np
# 示例特征数据:包含两个分类特征
X = np.array([
['small', 'red'],
['medium', 'green'],
['large', 'blue'],
['medium', 'red']
])
# 创建编码器
encoder = OrdinalEncoder()
# 拟合并转换数据
X_encoded = encoder.fit_transform(X)
print(X_encoded)
# 输出: [[0. 2.] -> small对应0, red对应2(因为按字母排序blue、green、red,所以red是2)
# [1. 1.] -> medium对应1, green对应1
# [2. 0.] -> large对应2, blue对应0
# [1. 2.]] -> medium对应1, red对应2关键参数
| 参数 | 默认值 | 描述 |
|---|---|---|
categories |
'auto' |
指定每个特征的类别列表(列表的列表) |
dtype |
np.float64 |
所需的输出数据类型 |
handle_unknown |
'error' |
处理未知类别(可设为 'use_encoded_value') |
unknown_value |
None |
当 handle_unknown='use_encoded_value' 时的值 |
encoded_missing_value |
np.nan |
缺失值的编码 |
完整使用示例(含参数配置)
from sklearn.preprocessing import OrdinalEncoder
import numpy as np
# 手动指定类别顺序(避免自动按字母排序)
categories = [
['small', 'medium', 'large'], # 特征0的顺序
['red', 'green', 'blue'] # 特征1的顺序
]
# 创建编码器并指定参数
encoder = OrdinalEncoder(
categories=categories,
dtype=np.int64,
handle_unknown='use_encoded_value', # 遇到未知类别时使用unknown_value
unknown_value=-1 # 未知类别编码为-1
)
# 使用指定的顺序拟合并转换
X_encoded = encoder.fit_transform(X)
print(X_encoded)
# 输出:[[0 0] -> small(0), red(0)
# [1 1] -> medium(1), green(1)
# [2 2] -> large(2), blue(2)
# [1 0]] -> medium(1), red(0)
# 处理未知值
test_data = [['tiny', 'yellow']]
test_encoded = encoder.transform(test_data)
print(test_encoded) # [[-1 -1]]属性与方法
| 属性/方法 | 描述 | 示例 |
|---|---|---|
categories_ |
每个特征的类别列表 | [array(['small','medium','large']), ...] |
fit(X) |
学习类别 | encoder.fit(X) |
transform(X) |
转换数据 | X_enc = encoder.transform(X) |
fit_transform(X) |
拟合并转换 | X_enc = encoder.fit_transform(X) |
inverse_transform(X) |
反转编码 | orig = encoder.inverse_transform(X_enc) |
应用场景
1. 有序分类特征编码
适用于具有内在顺序的分类特征(如尺寸、等级):
# 尺寸特征:小 < 中 < 大
# 等级特征:低 < 中 < 高
# 使用默认顺序(按字母排序)
encoder = OrdinalEncoder()
# 手动指定顺序
size_order = [['XS', 'S', 'M', 'L', 'XL']]
level_order = [['low', 'medium', 'high']]
encoder = OrdinalEncoder(categories=size_order+level_order)2. 树模型的特征预处理
树模型如随机森林可以直接处理有序编码:
from sklearn.ensemble import RandomForestClassifier
# 创建处理分类特征的pipeline(流水线)
from sklearn.pipeline import Pipeline
pipeline = Pipeline([
('encoder', OrdinalEncoder(handle_unknown='use_encoded_value', unknown_value=-1)),
('classifier', RandomForestClassifier())
])注意事项
-
与LabelEncoder的区别:
特性 OrdinalEncoder LabelEncoder 输入维度 2D数组(n_samples, n_features) 1D数组 适用对象 特征矩阵 目标变量 多列处理 是 否 类别顺序 每列可自定义 全列统一排序 未知值处理 支持 不支持
无序特征问题:
- 当特征没有内在顺序时,使用
OneHotEncoder
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder(sparse_output=False) # 返回密集矩阵# 使用sklearn的SimpleImputer处理缺失值
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
pipeline = Pipeline([
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('encoder', OrdinalEncoder(handle_unknown='use_encoded_value', unknown_value=-1))
])测试集中的未知类别:
# 使用参数处理未知类别
encoder = OrdinalEncoder(
handle_unknown='use_encoded_value',
unknown_value=-1
)
encoder.fit(X_train)
X_test_enc = encoder.transform(X_test) # 未知类别变为-1最佳实践
1. 在ColumnTransformer中使用
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import StandardScaler, OrdinalEncoder
# 为不同特征指定不同的转换器
preprocessor = ColumnTransformer(
transformers=[
('num', StandardScaler(), ['age', 'income']),
('cat', OrdinalEncoder(handle_unknown='use_encoded_value', unknown_value=-1),
['size', 'color'])
])
# 在管道中使用
from sklearn.pipeline import Pipeline
from sklearn.ensemble import RandomForestClassifier
pipeline = Pipeline([
('preprocessor', preprocessor),
('classifier', RandomForestClassifier())
])何时使用OrdinalEncoder vs OneHotEncoder
| 场景 | 推荐编码器 |
|---|---|
| 特征具有内在顺序(如尺寸、等级) | ✅ OrdinalEncoder |
| 特征没有顺序关系 | ✅ OneHotEncoder |
| 类别基数很高(唯一值很多) | ⚠️ 考虑 TargetEncoder 或 CatBoost |
| 树模型(RF、XGBoost) | ✅ 两者都可用 |
| 线性模型 | ✅ OneHotEncoder(避免人为顺序) |
OrdinalEncoder 是一种高效的处理分类特征的方法,特别适用于树模型和具有内在顺序的分类变量。正确使用可以显著简化数据预处理流程并提高模型性能。
特征工程-特征提取
什么是特征提取呢?
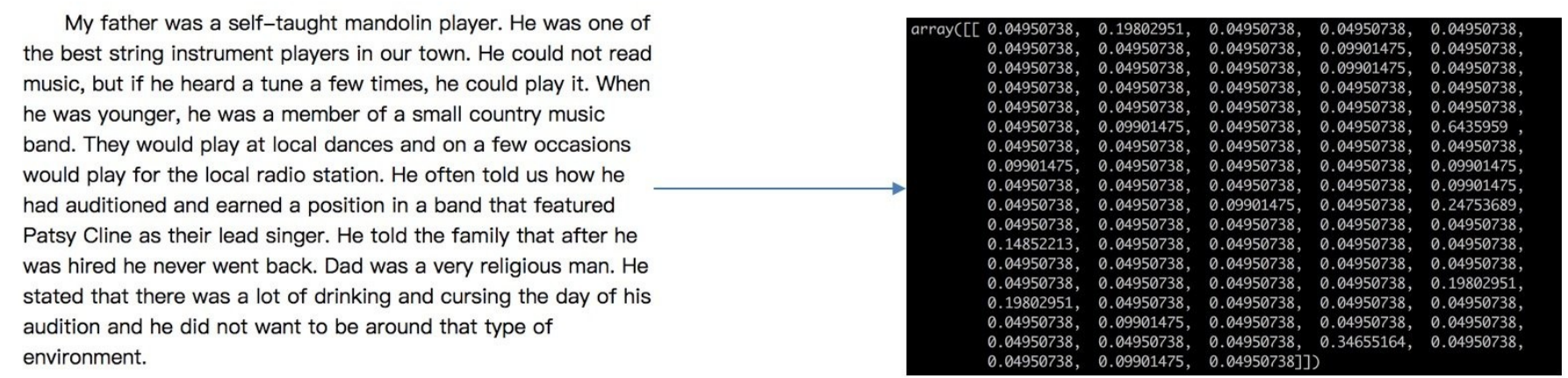
1.1 定义
将任意数据(如⽂本或图像)转换为可⽤于机器学习的数字特征
注:特征值化是为了计算机更好的去理解数据
特征提取分类:
- 字典特征提取(特征离散化)
- ⽂本特征提取
- 图像特征提取(在深度学习时将介绍)
1.2 特征提取API
sklearn.feature_extraction 是 scikit-learn (sklearn) 库中专门用于从非结构化或半结构化数据(特别是文本和图像)中自动提取机器学习算法可用的数值特征的核心模块。
它提供了一套高效、易用的工具,将原始数据(如文本文档、图像像素、字典格式数据)转换为数值特征矩阵(通常是 scipy.sparse 稀疏矩阵格式,节省内存),这些矩阵就可以直接输入到各种分类、回归或聚类模型中(如 SVM、Naive Bayes、Logistic Regression、K-Means 等)。
sklearn.feature_extraction 主要包含以下几个子模块:
字典特征提取
sklearn.feature_extraction.DictVectorizer:
专注于将类似字典 (dict-like) 结构(如 CSV 或 JSON 中的记录)转换为数值特征矩阵。
- 核心功能:处理类别型特征 (categorical features)。
- 将字典列表(每个字典代表一个样本,键为特征名,值为特征值)转换为数值矩阵。
- 如何处理类型:
- 数值型值: 直接复制到特征矩阵的对应位置。
- 字符串值 / 类别型值: 进行 One-Hot 编码 (虚拟变量 Dummy Variables)。字典键会被拆分,每个可能的类别值会生成一个独立的二元特征(0 表示不存在,1 表示存在)。
- 关键参数:
dtype=np.float64(默认特征数据类型),sparse=True(默认生成稀疏矩阵,节省内存)。separator="="(可选,用于连接字典键和分类值创建特征名)。 - 方法:
fit(X_dicts)/fit_transform(X_dicts)/transform(X_dicts):X_dicts是一个字典列表。- DictVectorizer.get_feature_names() 返回类别(特征)名称
代码示例:
from sklearn.feature_extraction import DictVectorizer
# 加载数据
data = [{'city': '北京', 'temperature': 100},
{'city': '上海', 'temperature': 60},
{'city': '深圳', 'temperature': 30}]
# 实例化一个转换器
transform = DictVectorizer(sparse=False)#sparse=False,不输出稀疏矩阵
# 特征提取
fitdata = transform.fit_transform(data)
# 获取特征名称
print(transform.get_feature_names_out())
# 打印特征值one-hot编码矩阵
print(fitdata)['city=上海' 'city=北京' 'city=深圳' 'temperature']
[[ 0. 1. 0. 100.]
[ 1. 0. 0. 60.]
[ 0. 0. 1. 30.]]上述代码如果不添加sparse=False ,则会返回稀疏矩阵:
查看打印结果['city=上海' 'city=北京' 'city=深圳' 'temperature']
<Compressed Sparse Row sparse matrix of dtype 'float64'
with 6 stored elements and shape (3, 4)>
Coords Values
(0, 1) 1.0
(0, 3) 100.0
(1, 0) 1.0
(1, 3) 60.0
(2, 2) 1.0
(2, 3) 30.0上面的数据存储形式,非常节约内存空间,不过这个结果并不是我们想要看到的,可读性很差,对于特征当中存在类别信息的我们都会做one-hot编码处理。
例子2:
data = [{'feature1': 5.0, 'feature2': 'A'},
{'feature1': 3.0, 'feature2': 'B'},
{'feature1': 1.5, 'feature2': 'A'}]
vect = DictVectorizer(sparse=False)
X = vect.fit_transform(data)
print(X) # 可能输出: [[5. 1. 0.] [3. 0. 1.] [1.5 1. 0.]]
print(vect.get_feature_names_out()) # 输出: ['feature1', 'feature2=A', 'feature2=B'] 优点: 非常方便地处理混合了数值型和类别型的表格数据,且自动进行 One-Hot 编码。替代方案 ColumnTransformer + OneHotEncoder 更灵活但更复杂。
文本特征提取
作⽤:对⽂本数据进⾏特征值化
sklearn.feature_extraction.text:
专注于从文本文档中提取特征。下面是最常用的子模块:
-
CountVectorizer:- 核心功能:词袋模型 (Bag-of-Words, BoW)。
- 将一系列文本文档转换为单词/词条(token)的计数矩阵。(词频矩阵)
- 每个文档表示为一行向量,向量的长度是词汇表的大小(所有出现在文本集合中的唯一 token 数量)。
- 向量中的每个元素代表对应 token 在该文档中出现的频次 (count)。
- 关键参数:
stop_words:指定停用词列表(如 'the', 'is', 'and')【了、的、在...】,这些词会被忽略。ngram_range:指定提取 n-gram 的范围(如(1, 1)表示只取单个词;(1, 2)表示同时取单个词和双词组合 bigram)。max_features:限制词汇表的最大特征数(按频率排序)。min_df,max_df:设定词条的最小/最大文档频率,用于过滤罕见词和常见词。token_pattern,tokenizer:自定义分词规则或函数。
- 方法:
fit_transform(raw_documents):学习词汇表并返回特征矩阵。transform(raw_documents):对新文档应用学习到的词汇表转换。get_feature_names_out():获取词汇表(特征名称列表)。-
-
CountVectorizer.fit_transform(X)
X:⽂本或者包含⽂本字符串的可迭代对象
-
返回值:返回sparse矩阵
-
-
英文文本
from sklearn.feature_extraction.text import CountVectorizer
# 加载数据
data = ["life is short,i like python",
"life is too long,i dislike python"]
# 实例化转换器
tranfrom = CountVectorizer() # 注意,没有sparse=False这个参数,所以只能输出稀疏矩阵
# 特征提取
transformdata = tranfrom.fit_transform(data)
# 打印特征列表
print("特征列表:\n", tranfrom.get_feature_names_out())
# 打印特征值稀疏矩阵
print("稀疏矩阵格式:\n", transformdata)
print("转换为onehot编码格式:\n", transformdata.toarray())特征列表:
['dislike' 'is' 'life' 'like' 'long' 'python' 'short' 'too']
稀疏矩阵格式:
<Compressed Sparse Row sparse matrix of dtype 'int64'
with 11 stored elements and shape (2, 8)>
Coords Values
(0, 2) 1
(0, 1) 1
(0, 6) 1
(0, 3) 1
(0, 5) 1
(1, 2) 1
(1, 1) 1
(1, 5) 1
(1, 7) 1
(1, 4) 1
(1, 0) 1
转换为onehot编码格式:
[[0 1 1 1 0 1 1 0]
[1 1 1 0 1 1 0 1]]中文文本
问题:如果我们将上面的英文数据替换成中⽂?
"⼈⽣苦短,我喜欢Python","⽣活太⻓久,我不喜欢Python"
那么最终得到的结果是:
查看中文默认处理结果 特征列表:
['我不喜欢python' '我喜欢python' '活太' '苦短']
稀疏矩阵格式:
<Compressed Sparse Row sparse matrix of dtype 'int64'
with 4 stored elements and shape (2, 4)>
Coords Values
(0, 3) 1
(0, 1) 1
(1, 2) 1
(1, 0) 1
转换为onehot编码格式:
[[0 1 0 1]
[1 0 1 0]]为什么会得到这样的结果呢,是因为CountVectorizer默认使用基于空格分词的策略,而中文文本没有明显的空格分隔符,导致特征提取结果不符合中文习惯。仔细分析之后会发现英⽂默认是以空格分开的。所以我们要对中⽂进⾏分词处理:
jieba分词处理
- jieba.cut()
返回词语组成的⽣成器
需要安装下jieba库
pip3 install jieba
# 使用jieba进行中文分词
words = jieba.cut(text)
text = "今天很残酷,明天更残酷,后天很美好,但绝对⼤部分是死在明天晚上,所以每个⼈不要放弃今天。"
words=chinese_tokenizer(text)
for w in words:
print(w,end=" ")
#今天 很 残酷 , 明天 更 残酷 , 后天 很 美好 , 但 绝对 ⼤ 部分 是 死 在 明天 晚上 , 所以 每个 ⼈ 不要 放弃 今天 。3.4 案例分析
对以下三句话进⾏特征值化
今天很残酷,明天更残酷,后天很美好,但绝对⼤部分是死在明天晚上,所以每个⼈不要放弃今天。
我们看到的从很远星系来的光是在⼏百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。
如果只⽤⼀种⽅式了解某样事物,你就不会真正了解它,了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。
分析
- 准备句⼦,自定义分词器方法并利⽤jieba.cut进⾏分词
- 实例化CountVectorizer,并指定分词器
- 特征提取
from sklearn.feature_extraction.text import CountVectorizer
import jieba
# 定义中文分词函数
def chinese_tokenizer(text):
# 使用jieba进行中文分词
words = jieba.cut(text)
# 过滤掉标点符号和空格
filtered_words = [word for word in words if word.strip() and word not in ",。、!“”"]
print(filtered_words)
return list(filtered_words)
#中文特征提取方法
def text_Chinese():
# 加载数据
data = ["今天很残酷,明天更残酷,后天很美好,但绝对⼤部分是死在明天晚上,所以每个⼈不要放弃今天。",
"我们看到的从很远星系来的光是在⼏百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。",
"如果只⽤⼀种⽅式了解某样事物,你就不会真正了解它,了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]
# 实例化转换器,并添加自定义中文分词器
tranfrom = CountVectorizer(tokenizer=chinese_tokenizer)
# 特征提取
transformdata = tranfrom.fit_transform(data)
# 打印特征列表
print("特征列表:\n", tranfrom.get_feature_names_out())
# 打印特征值稀疏矩阵
print("稀疏矩阵格式:\n", transformdata)
# 转换为可读的稠密矩阵
print("转换为onehot编码格式:\n", transformdata.toarray())
if __name__ == '__main__':
text_Chinese()['今天', '很', '残酷', '明天', '更', '残酷', '后天', '很', '美好', '但', '绝对', '⼤', '部分', '是', '死', '在', '明天', '晚上', '所以', '每个', '⼈', '不要', '放弃', '今天']
['我们', '看到', '的', '从', '很', '远', '星系', '来', '的', '光是在', '⼏', '百万年', '之前', '发出', '的', '这样', '当', '我们', '看到', '宇宙', '时', '我们', '是', '在', '看', '它', '的', '过去']
['如果', '只', '⽤', '⼀', '种', '⽅', '式', '了解', '某样', '事物', '你', '就', '不会', '真正', '了解', '它', '了解', '事物', '真正', '含义', '的', '秘密', '取决于', '如何', '将', '其', '与', '我们', '所', '了解', '的', '事物', '相', '联系']
特征列表:
['⼀' '⼈' '⼏' '⼤' '⽅' '⽤' '不会' '不要' '与' '之前' '了解' '事物' '今天' '从' '但' '你' '光是在' '其' '发出' '取决于' '只' '后天' '含义' '在' '如何' '如果' '它' '宇宙' '将' '就' '式' '当' '很' '我们' '所' '所以' '放弃' '时' '明天' '星系' '是' '晚上' '更' '来' '某样' '死' '残酷' '每个' '百万年' '的' '相' '看' '看到' '真正' '种' '秘密' '绝对' '美好' '联系' '过去' '这样' '远' '部分']
稀疏矩阵格式:
<Compressed Sparse Row sparse matrix of dtype 'int64' with 69 stored elements and shape (3, 63)>
Coords Values
(0, 12) 2
(0, 32) 2
(0, 46) 2
: :
(2, 8) 1
(2, 34) 1
(2, 50) 1
(2, 58) 1
转换为onehot编码格式:
[[0 1 0 1 0 0 0 1 0 0 0 0 2 0 1 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 0 2 0 0 1 1 0 2 0 1 1 1 0 0 1 2 1 0 0 0 0 0 0 0 0 1 1 0 0 0 0 1]
[0 0 1 0 0 0 0 0 0 1 0 0 0 1 0 0 1 0 1 0 0 0 0 1 0 0 1 1 0 0 0 1 1 3 0 0 0 1 0 1 1 0 0 1 0 0 0 0 1 4 0 1 2 0 0 0 0 0 0 1 1 1 0]
[1 0 0 0 1 1 1 0 1 0 4 3 0 0 0 1 0 1 0 1 1 0 1 0 1 1 1 0 1 1 1 0 0 1 1 0 0 0 0 0 0 0 0 0 1 0 0 0 0 2 1 0 0 2 1 1 0 0 1 0 0 0 0]]替代方案:使用专门的中文处理库(安装比较麻烦,并且依赖C++库和numpy)
如果您需要更专业的中文NLP处理,可以考虑:
from sklearn.feature_extraction.text import CountVectorizer
import pkuseg # 北大中文分词工具
# 使用pkuseg分词器
seg = pkuseg.pkuseg()
vectorizer = CountVectorizer(tokenizer=seg.cut)
# 其他处理相同...中文停用词表
- 创建文件
chinese_stopwords.txt - 内容包含常见虚词:的、了、在、是、我、你...
- 统一停用词表格式:确保每行一个词,使用UTF-8编码保存文件
- 使用开源停用词表:如清华大学的中文停用词表
- 添加同义词处理:将"今日"、"本日"等变体也加入停用词表
完整预处理代码
import jieba
from sklearn.feature_extraction.text import CountVectorizer
# 加载中文停用词表
def load_stopwords(file_path='chinese_stopwords.txt'):
with open(file_path, 'r', encoding='utf-8') as f:
return set([line.strip() for line in f])
stopwords = load_stopwords()
# 增强版中文分词器
def advanced_chinese_tokenizer(text):
# 去除非中文字符(这行代码用于清理文本,只保留中文字符和字母数字字符。)
cleaned_text = ''.join(char for char in text if '\u4e00' <= char <= '\u9fff' or char.isalnum())
words = jieba.cut(cleaned_text)
return [word for word in words if word not in stopwords and len(word) > 1]
# 实例化向量化器
vectorizer = CountVectorizer(
tokenizer=advanced_chinese_tokenizer,
lowercase=False, # 保持Python/Python等专有名词大小写
max_features=1000 # 限制特征数量
)
# 后续处理不变...上述代码详解:
cleaned_text = ''.join(char for char in text if '\u4e00' <= char <= '\u9fff' or char.isalnum())
\u4e00和\u9fff
- 是Unicode编码值,代表中文及相关字符的范围(具体范围:U+4E00 - U+9FFF(扩展A区),该范围覆盖了基本汉字和扩展汉字(简体、繁体常用字))
char.isalnum()
- Python字符串的内置方法:检查字符是否是字母(包括英文字母)或数字,等价于:char.isalpha() or char.isdigit()
所以整个条件的意思是:"保留所有中文字符(在\u4e00到\u9fff范围内),以及所有字母(包括非中文)和数字"
被过滤掉的字符:标点符号、空格、表情符号、特殊字符等所有非字母数字和中文字符''.join(...)
- 将经过过滤的字符重新组合成一个新字符串,生成连续不带分隔符的新字符串
实际效果示例:
输入:"人生苦短,我 #喜欢Python! 123👍"
输出:"人生苦短我喜欢Python123"
[word for word in words if word not in stopwords and len(word) > 1]
len(word) > 1在这个代码中的主要作用是过滤掉单字词(单个字符的词),确保最终保留的特征只包含两个或以上字符的词语。这是中文文本处理中一个常见且重要的预处理步骤。具体作用和原因:
过滤无用单字:
- 中文中许多单字词(如"我"、"你"、"是"等)通常是停用词或包含信息量少的词语
- 它们虽然可能已经包含在停用词表中,但添加
len(word) > 1作为额外保障提高特征质量:
- 两字及以上的词语(如"明天"、"残酷"、"了解")通常包含更多语义信息
- 避免模型被大量无意义单字噪声干扰
减少特征维度:
- 过滤单字词可以显著减少特征空间
- 在中文中,单字词的数量可能占词汇总量的30-50%
解决分词边界问题:
- 对于某些未登录词或专有名词,分词器可能错误地切分为单字
- 直接过滤比错误保留更安全
具体效果示例:
假设分词结果:
["今天", "很", "残酷", ",", "明天", "更", "残酷"]经过过滤:
# 过滤过程: "今天" → len=2 → 保留 "很" → len=1 → 丢弃 (即使不在停用词表) "残酷" → len=2 → 保留 "," → len=1 → 丢弃 "明天" → len=2 → 保留 "更" → len=1 → 丢弃 "残酷" → len=2 → 保留 # 最终结果:["今天", "残酷", "明天", "残酷"]注意事项和最佳实践:
与停用词表的协作:
- 大多数停用词是单字(如"的"、"了")
- 但仍有部分停用词是多字词(如"但是"、"然而")
- 两者结合使用更全面
例外情况处理:
- 特殊场景可能需要保留单字词:
- 诗词分析("床前明月光")
- 专有名词("鲁迅"的"鲁")
- 可以添加例外处理:
[word for word in words if (word not in stopwords and len(word) > 1) or word in special_words] # 特殊保留词
字符型语言的特殊性:
- 中文不同于英文,英文单词有空格分隔
- 中文单字词占比高,过滤更重要
可调整的参数:
- 对某些任务可能放宽到
len(word) >= 1- 对专业文本可能收紧到
len(word) >= 3总之,
len(word) > 1是中文文本特征工程中一个简单但有效的技术,能显著提升特征质量、减少噪音、降低维度。它是中文NLP处理中与停用词过滤配套使用的最佳实践之一。
注意事项:
1.中文范围补充:
-
- 严格来说,完整中文范围应包含:
- 基本汉字:U+4E00-U+9FFF
- 扩展A区:U+3400-U+4DBF
- 扩展B-F区:U+20000-U+2EBEF
- 更全面的处理可考虑正则表达式:
re.compile(r'[\u4e00-\u9fff\u3400-\u4dbf\U00020000-\U0002EBEF]')
- 严格来说,完整中文范围应包含:
2.其他语言:
-
- 此代码不保留韩文、日文等其他非中文字符
- 若需要可添加额外条件,如日文范围
\u3040-\u30FF
3.优化建议:
对于超长文本,可考虑使用正则表达式替换
4.应用场景:
-
- 中文文本分类/聚类前的预处理
- 提高分词效果(减少干扰字符)
- 构造"干净"的特征(如词袋模型)
这个操作是中文NLP处理中非常基础的清洁步骤,能有效去除大部分干扰符号,保留核心语义内容。
但如果把这样的词语特征⽤于分类,会出现什么问题?
该如何处理某个词或短语在多篇⽂章中出现的次数⾼这种情况?
TF-IDF 特征矩阵
TF-IDF的主要思想是:如果某个词或短语在⼀篇⽂章中出现的概率⾼,并且在其他⽂章中很少出现,则认为此词或者短语具有很好的类别区分能⼒,适合⽤来分类。
TF-IDF作⽤:⽤以评估⼀字词对于⼀个⽂件集或⼀个语料库中的其中⼀份⽂件的重要程度。
公式
- 词频(term frequency,tf)指的是某⼀个给定的词语在该⽂件中出现的频率。有多种计算方法(如 raw count, log scaled, augmented)。
- 逆向⽂档频率(inverse document frequency,idf)是⼀个词语普遍重要性的度量。某⼀特定词语的idf,可以由总⽂件数⽬除以包含该词语⽂件的数⽬,再将得到的商取以10为底的对数得到。衡量词在整个文档集合中的罕见程度。出现在很多文档中的词(如 "the")其IDF值低,反之则高。
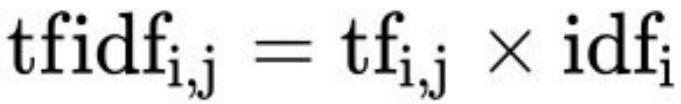
最终得出结果可以理解为重要程度。
举例:
假如⼀篇⽂章的总词语数是100个,⽽词语"⾮常"出现了5次,那么"⾮常"⼀词在该⽂件中的词频tf就是5/100=0.05。
⽽计算⽂件频率(IDF)的⽅法是以⽂件集的⽂件总数,除以出现"⾮常"⼀词的⽂件数。
所以,如果"⾮常"⼀词在10份⽂件出现过,⽽⽂件总数是10,000份的话,
其逆向⽂件频率idf就是lg(10,000 / 1,0)=3。
最后"⾮常"对于这篇⽂档的tf-idf的分数为0.05 * 3=0.15
API
sklearn.feature_extraction.text:
-
TfidfTransformer:- 作用: 将
CountVectorizer(或其他计数向量器)生成的词频计数矩阵转换为其 TF-IDF 表示形式。 - TF-IDF = TF * IDF: 同时考虑了词在文档内的频率和其在整个语料库中的重要性。
- 关键参数:
use_idf=True(启用 IDF),smooth_idf=True(平滑 IDF),norm='l2'(对特征向量进行 L2 归一化)。 - 方法:
fit(X_counts)/fit_transform(X_counts)/transform(X_counts)X_counts通常是CountVectorizer的输出。
- 作用: 将
-
TfidfVectorizer:- 核心功能:整合版 TF-IDF 向量化器。
- 直接一步到位将原始文档集合转换为 TF-IDF 特征矩阵。相当于
CountVectorizer+TfidfTransformer的组合(但更高效)。 - 具有
CountVectorizer的所有分词、过滤参数 (stop_words,ngram_range,max_features等) 和TfidfTransformer的所有 TF-IDF 相关参数 (use_idf,norm等)。 - 方法:
fit_transform(raw_documents):学习词汇表并返回 TF-IDF 矩阵。
# 加载中文停用词表
def load_stopwords(file_path=r'D:\data\机器学习\chinese_stopwords.txt'):
with open(file_path, 'r', encoding='utf-8') as f:
return set([line.strip() for line in f])
# 增强版中文分词器
def advanced_chinese_tokenizer(text):
print("stopwords:",stopwords)#stopwords: {'了', '的', '今天'}
# 去除非中文字符(这行代码用于清理文本,只保留中文字符和字母数字字符。)
cleaned_text = ''.join(char for char in text if '\u4e00' <= char <= '\u9fff' or char.isalnum())
words = jieba.cut(cleaned_text)
return [word for word in words if word not in stopwords and len(word) > 1]
def text_Chinese_tfidf():
# 加载数据
data = ["今天很残酷,明天更残酷,后天很美好,但绝对⼤部分是死在明天晚上,所以每个⼈不要放弃今天。",
"我们看到的从很远星系来的光是在⼏百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。",
"如果只⽤⼀种⽅式了解某样事物,你就不会真正了解它,了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]
# 实例化转换器,并添加自定义中文分词器
tranfrom = TfidfVectorizer(tokenizer=advanced_chinese_tokenizer)
# 特征提取
transformdata = tranfrom.fit_transform(data)
# 打印特征列表
print("特征列表:\n", tranfrom.get_feature_names_out())
# 打印特征值稀疏矩阵
print("稀疏矩阵格式:\n", transformdata)
# 转换为可读的稠密矩阵
print("转换为onehot编码格式:\n", transformdata.toarray())
if __name__ == '__main__':
stopwords = load_stopwords()
text_Chinese_tfidf() stopwords: {'了', '的', '今天'}
特征列表:
['不会' '不要' '之前' '了解' '事物' '光是在' '发出' '取决于' '只种' '后天' '含义' '如何' '如果' '宇宙' '我们' '所以' '放弃' '明天' '星系' '晚上' '某样' '残酷' '每个' '百万年' '看到' '真正' '秘密' '绝对' '美好' '联系' '过去' '这样' '部分']
稀疏矩阵格式:
<Compressed Sparse Row sparse matrix of dtype 'float64' with 34 stored elements and shape (3, 33)>
Coords Values
(0, 21) 0.4850712500726659
(0, 17) 0.4850712500726659
(0, 9) 0.24253562503633294
...
(2, 11) 0.16100074927698105
(2, 29) 0.16100074927698105
转换为onehot编码格式:
[[0. 0.24253563 0. 0. 0. 0. 0. 0. 0. 0.24253563 0. 0. 0. 0. 0. 0.24253563 0.24253563 0.48507125 0. 0.24253563 0. 0.48507125 0.24253563 0. 0. 0. 0. 0.24253563 0.24253563 0. 0. 0. 0.24253563]
[0. 0. 0.2410822 0. 0. 0.2410822 0.2410822 0. 0. 0. 0. 0. 0. 0.2410822 0.55004769 0. 0. 0. 0.2410822 0. 0. 0. 0. 0.2410822 0.48216441 0. 0. 0. 0. 0. 0.2410822 0.2410822 0. ]
[0.16100075 0. 0. 0.644003 0.48300225 0. 0. 0.16100075 0.16100075 0. 0.16100075 0.16100075 0.16100075 0. 0.12244522 0. 0. 0. 0. 0. 0.16100075 0. 0. 0. 0. 0.3220015 0.16100075 0. 0. 0.16100075 0. 0. 0. ]]Tf-idf的重要性
分类机器学习算法进⾏⽂章分类中前期数据处理⽅式
典型工作流程示例 (文本分类):
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.svm import LinearSVC
from sklearn.metrics import accuracy_score
# 1. 假设有文本数据 (documents) 和对应标签 (labels)
documents = ["This is document one.", "Here's another text.", ...]
labels = [0, 1, ...] # e.g., 0: spam, 1: ham
# 2. 划分训练集/测试集
X_train, X_test, y_train, y_test = train_test_split(documents, labels, test_size=0.2)
# 3. 使用 TF-IDF 提取特征 (整合了 CountVectorizing 和 TfidfTransforming)
vectorizer = TfidfVectorizer(stop_words='english', max_features=5000)
X_train_tfidf = vectorizer.fit_transform(X_train) # 学习词汇表并转换训练集
X_test_tfidf = vectorizer.transform(X_test) # 用训练集的词汇表转换测试集
# 4. 训练分类器 (如 SVM)
clf = LinearSVC()
clf.fit(X_train_tfidf, y_train)
# 5. 预测并评估
y_pred = clf.predict(X_test_tfidf)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.4f}")
# (可选) 查看重要特征 (词汇)
feature_names = vectorizer.get_feature_names_out()
coef = clf.coef_[0] # 假设是二分类
top_positive_terms = feature_names[coef.argsort()[-10:][::-1]] # 对正类最重要的10个词
top_negative_terms = feature_names[coef.argsort()[:10]] # 对负类最重要的10个词
print("Top positive terms:", top_positive_terms)
print("Top negative terms:", top_negative_terms)
图像特征
sklearn.feature_extraction.image:
专注于从图像中提取原始特征(通常是比较基础的特征)。
-
extract_patches_2d(image, patch_size, ...):- 从单个大图像中提取一组较小的、规则或不规则排列的图像块 (image patches)。
max_patches参数可以控制提取的数量,random_state用于随机采样。 - 输出是一个 3D 数组
(n_patches, patch_height, patch_width)或(n_patches, patch_height, patch_width, n_channels)。
- 从单个大图像中提取一组较小的、规则或不规则排列的图像块 (image patches)。
-
reconstruct_from_patches_2d(patches, image_shape):- 尝试将一组图像块重建回原始图像(或其近似)。
- 需要指定目标图像的形状
image_shape。
-
PatchExtractor:- 提供类似
extract_patches_2d的功能,但作为一个类,适合在数据转换流程(如 Pipeline)中使用。 - 输入可以是一个图像列表。
- 提供类似
- 重要说明: 这个模块主要用于提取原始的像素块,而不是提取复杂的手工特征(如 SIFT, SURF, HOG)或使用深度学习(如 CNN 特征)。它适用于基于原始像素块的学习算法(或作为特征工程的起点)。对于高级图像特征,通常会使用
skimage,opencv或深度学习框架(TensorFlow/PyTorch)进行预处理,然后将特征输入到 sklearn 模型中。
暂时了解,在深度学习课程详细介绍...
交叉验证&⽹格搜索
交叉验证(cross validation)
交叉验证:将拿到的训练数据,分为训练和验证集。以下图为例:将数据分成4份,其中⼀份作为验证集。然后经过4次(组)的测试,每次都更换不同的验证集。即得到4组模型的结果,取平均值作为最终结果。⼜称4折(zhe)交叉验证。

分析
我们之前知道数据分为训练集和测试集,但是为了让从训练得到模型结果更加准确。做以下处理
训练集:训练集+验证集(将训练集再次划分,分成:训练集+验证集)
测试集:测试集
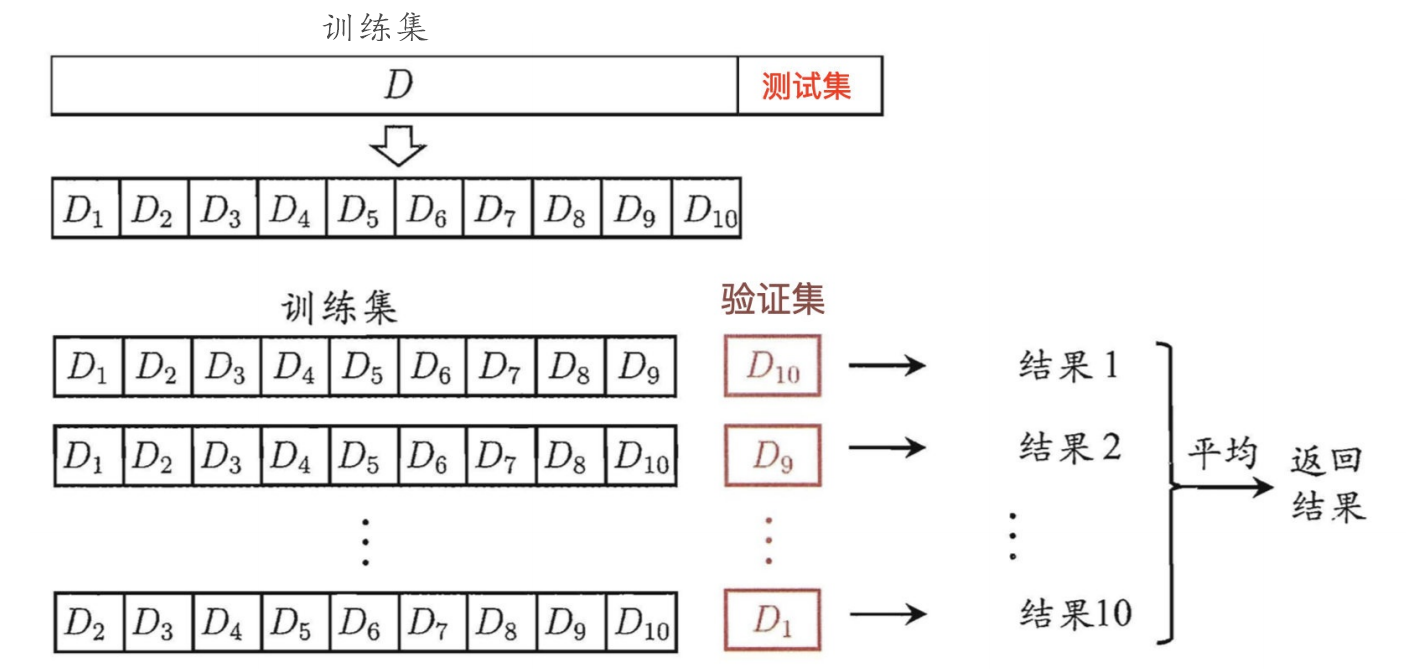
为什么需要交叉验证
交叉验证⽬的:为了让被评估的模型更加准确可信
问题:这个只是让被评估的模型更加准确可信,那么怎么选择或者调优参数呢(邻居个数k)?那就需要网格搜索:
网格搜索(Grid Search)
通常情况下,有很多参数是需要⼿动指定的(如k-近邻算法中的K值),这种叫超参数。但是⼿动过程繁杂,所以需要对模型预设⼏种超参数组合。每组超参数都采⽤交叉验证来进⾏评估。最后选出最优参数组合建⽴模型。

交叉验证,网格搜索(模型选择与调优)API
- sklearn.model_selection.GridSearchCV(estimator, param_grid=None,cv=None)
- 对估计器的指定参数值进⾏详尽搜索
- estimator:估计器对象
- param_grid:估计器参数(dict){“n_neighbors”:[1,3,5]}
- cv:指定⼏折交叉验证
- fit:输⼊训练数据
- score:准确率
- 结果分析:
- bestscore__:在交叉验证中验证的最好结果
- bestestimator:最好的参数模型
- cvresults:每次交叉验证后的验证集准确率结果和训练集准确率结果
鸢尾花案例增加K值调优
使⽤GridSearchCV构建估计器
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
# 1,获取数据集
iris = load_iris()
# 2,数据拆分为测试集和训练集
train_data, test_data, train_target, test_target = train_test_split(iris.data, iris.target, test_size=0.2,
random_state=66)
# 3,数据标准化
scaler = StandardScaler()
transform_train_data = scaler.fit_transform(train_data)
transform_test_data = scaler.transform(test_data)
# 4.KNN机器学习(模型训练)
# 4.1,初始化估计器
estimator = KNeighborsClassifier()
# 4.2 模型选择与调优——⽹格搜索和交叉验证
# 准备要调的超参数
param_dict = {"n_neighbors": [1, 3, 5,7]}
estimator = GridSearchCV(estimator=estimator, param_grid=param_dict, cv=5) # 指定5折交叉验证
# 4.3 fit数据进⾏训练
estimator.fit(transform_train_data, train_target)
# 5、评估模型效果
# ⽅法1:⽐对预测结果和真实值
predict_target = estimator.predict(transform_test_data)
print('预测结果:\n', predict_target)
print('预测结果正确与否:\n', predict_target == test_target)
# 方法2:直接计算准确率
score = estimator.score(transform_test_data, test_target)
print('模型预测准确率:\n', score)预测结果:
[1 1 2 0 1 1 0 0 0 2 2 2 0 1 2 0 1 2 2 2 0 1 1 2 1 2 0 0 2 2]
预测结果正确与否:
[ True True False True True True True True True True True True
True False True True True False True True True True True True
True True True True True True]
模型预测准确率:
0.9查看详细的交叉验证结果,及各种参数对应的得分情况
print("模型最好的参数:\n", estimator.best_params_)
print("交叉验证中模型选择不同参数组合的最高分(该参数对应的n折的平均分)是:\n", estimator.best_score_)
print("最好结果对应的模型的所有参数:\n", estimator.best_estimator_.get_params())#使用 get_params() 方法可查看完整参数。Scikit-learn 在打印模型对象时,默认只显示用户手动修改的参数,未修改的参数(保持默认值)会被省略。
print("每次交叉验证的结果:\n", estimator.cv_results_) 最好的参数:
{'n_neighbors': 5}
交叉验证中模型选择不同参数组合的最高分(该组参数对应的n折的平均分)是:
0.9666666666666666
最好结果对应的模型的所有参数:
{'algorithm': 'auto', 'leaf_size': 30, 'metric': 'minkowski', 'metric_params': None, 'n_jobs': None, 'n_neighbors': 5, 'p': 2, 'weights': 'uniform'}
每次交叉验证的结果:
{
'mean_fit_time': array([0.00061588, 0.00052772, 0.00054846, 0.00053821]),
'std_fit_time': array([9.14052680e-05, 3.37493605e-05, 5.97360307e-05, 3.67098344e-05]),
'mean_score_time': array([0.00204964, 0.00203862, 0.0021708, 0.00198121]),
'std_score_time': array([1.49192235e-04, 1.18470247e-04, 3.49607984e-04, 5.22286685e-05]),
'param_n_neighbors': masked_array(data=[1, 3, 5, 7], mask=[False, False, False, False], fill_value=999999),
'params': [{'n_neighbors': 1}, {'n_neighbors': 3}, {'n_neighbors': 5}, {'n_neighbors': 7}],
'split0_test_score': array([1., 1., 1., 0.95833333]),
'split1_test_score': array([1., 0.95833333, 1., 1.]),
'split2_test_score': array([0.95833333, 0.95833333, 0.95833333, 1.]),
'split3_test_score': array([0.875, 0.91666667, 0.91666667, 0.91666667]),
'split4_test_score': array([0.95833333, 0.95833333, 0.95833333, 0.95833333]),
'mean_test_score': array([0.95833333, 0.95833333, 0.96666667, 0.96666667]),
'std_test_score': array([0.04564355, 0.02635231, 0.03118048, 0.03118048]),
'rank_test_score': array([3, 3, 1, 1], dtype=int32)}
best_score_的定义:best_score_是交叉验证中所有分折(folds)的平均测试准确率,而非单个分折的最高值。
根据你提供的cv_results_,当n_neighbors=5时,各分折的测试准确率为:split0_test_score: 1.0 split1_test_score: 1.0 split2_test_score: 0.9583 split3_test_score: 0.9167 split4_test_score: 0.9583
(1.0+1.0+0.9583+0.9167+0.9583)/ 5=0.96666≈0.9667
模型评估
多分类对数损失log_loss
from sklearn.metrics import log_loss参照:
kaggle-奥托集团产品分类挑战赛-数据不均衡处理、欠采样、随机森林、模型超参数分析、模型调优
知识补充:再议数据分割
前⾯已经讲过,我们可通过实验测试来对学习器的泛化误差进⾏评估并进⽽做出选择。
为此,需使⽤⼀个“测试集”( testing set)来测试学习器对新样本的判别能⼒,然后以测试集上的“测试误差” (testing error)作为泛化误差的近似。
通常我们假设测试样本也是从样本真实分布中独⽴同分布采样⽽得。但需注意的是,测试集应该尽可能与训练集互斥。
互斥,即测试样本尽量不在训练集中出现、未在训练过程中使⽤过。
测试样本为什么要尽可能不出现在训练集中呢?为理解这⼀点,不妨考虑这样⼀个场景:
⽼师出了10道习题供同学们练习,考试时⽼师⼜⽤同样的这10道题作为试题,这个考试成绩能否有效反映出同学们学得好不好呢?
答案是否定的,可能有的同学只会做这10道题却能得⾼分。
回到我们的问题上来,我们希望得到泛化性能强的模型,好⽐是希望同学们对课程学得很好、获得了对所学知识“举⼀反三”的能⼒;训练样本相当于给同学们练习的习题,测试过程则相当于考试。显然,若测试样本被⽤作训练了,则得 到的将是过于“乐观”的估计结果。
可是,我们只有⼀个包含m个样例的数据集,既要训练,⼜要测试,怎样才能做到呢?
![]()
答案是:通过对数据集进⾏适当的处理,从中产⽣出训练集S和测试集T。(这个也是我们前⾯⼀直在做的事情)。
下⾯我们⼀起总结⼀下⼏种常⻅的做法:
- 留出法
- 交叉验证法
- ⾃助法
1 留出法
“留出法”(hold-out)直接将数据集D划分为两个互斥的集合,其中⼀个集合作为训练集S,另⼀个作为测试集T。
在S上训练出模型后,⽤T来评估其测试误差,作为对即泛化误差的估计。
![]()
⼤家在使⽤的过程中,需注意的是,训练/测试集的划分要尽可能保持数据分布的⼀致性,避免因数据划分过程引⼊额外的偏差⽽对最终结果产⽣影响,例如在分类任务中⾄少要保持样本的类别⽐例相似。
如果从采样( sampling)的⻆度来看待数据集的划分过程,则保留类别⽐例的采样⽅式通常称为“分层采样”( stratified sampling)。
例如通过对D进⾏分层样⽽获得含70%样本的训练集S和含30%样本的测试集T,若D包含500个正例、500个反例,则分层采样得到的S应包含350个正例、350个反例,⽽T则包含150个正例和150个反例;
若S、T中样本类别⽐例差别很⼤,则误差估计将由于训练/测试数据分布的差异⽽产⽣偏差。
另⼀个需注意的问题是,即便在给定训练测试集的样本⽐例后,仍存在多种划分⽅式对初始数据集进⾏分割。
例如在上⾯的例⼦中,可以把D中的样本排序,然后把前350个正例放到训练集中,也可以把最后350个正例放到训练集中,这些不同的划分将导致不同的训练/测试集,相应的,模型评估的结果也会有差别。
因此,单次使⽤留出法得到的估计结果往往不够稳定可靠,在使⽤留出法时,⼀般要采⽤若⼲次随机划分、重复进⾏实 验评估后取平均值作为留出法的评估结果。
例如进⾏100次随机划分,每次产⽣⼀个训练/测试集⽤于实验评估,100次后就得到100个结果,⽽留出法返回的则是这100个结果的平均。
此外,我们希望评估的是⽤D训练出的模型的性能,但留出法需划分训练/测试集,这就会导致⼀个窘境:
- 若令训练集S包含绝⼤多数样本,则训练出的模型可能更接近于⽤D训练出的模型,但由于T⽐较⼩,评估结果可能不够稳定准确;
- 若令测试集T多包含⼀些样本,则训练集S与D差别更⼤了,被评估的模型与⽤D训练出的模型相⽐可能有较⼤差别,从⽽降低了评估结果的保真性( fidelity)。
这个问题没有完美的解决⽅案,常⻅做法是将⼤约2/3~4/5的样本⽤于训练,剩余样本⽤于测试。
使⽤Python实现留出法:
from sklearn.model_selection import train_test_split
#使⽤train_test_split划分训练集和测试集
train_X , test_X, train_Y ,test_Y = train_test_split(X, Y, test_size=0.2,random_state=0)在留出法中,有⼀个特例,叫:留⼀法( Leave-One-Out,简称LOO),即每次抽取⼀个样本做为测试集。显然,留⼀法不受随机样本划分⽅式的影响,因为m个样本只有唯⼀的⽅式划分为m个⼦集⼀每个⼦集包含m-1个样本;
使⽤Python实现留⼀法:
from sklearn.model_selection import LeaveOneOut
data = [1, 2, 3, 4]
loo = LeaveOneOut()
for train, test in loo.split(data):
print("%s %s" % (train, test))
'''结果
[1 2 3] [0]
[0 2 3] [1]
[0 1 3] [2]
[0 1 2] [3]
'''留⼀法优缺点:
优点:
- 留⼀法使⽤的训练集与初始数据集相⽐只少了⼀个样本,这就使得在绝⼤多数情况下,留⼀法中被实际评估的模型与期望评估的⽤D训练出的模型很相似。因此,留⼀法的评估结果往往被认为⽐较准确。
缺点:
- 留⼀法也有其缺陷:在数据集⽐较⼤时,训练m个模型的计算开销可能是难以忍受的(例如数据集包含1百万个样本,则需训练1百万个模型,⽽这还是在未考虑算法调参的情况下。
2 交叉验证法
“交叉验证法”( cross validation)先将数据集D划分为k个⼤⼩相似的互斥⼦集,即
![]()
每个⼦集Di 都尽可能保持数据分布的⼀致性,即从D中通过分层抽样得到。
然后,每次⽤k-1个⼦集的并集作为训练集,余下的那个⼦集作为测试集;这样就可获得k组训练/测试集,从⽽可进⾏k次训练和测试,最终返回的是这k个测试结果的均值。
显然,交叉验证法评估结果的稳定性和保真性在很⼤程度上取决于k的取值,为强调这⼀点,通常把交叉验证法称为“k折交叉验证”(k- fold cross validation)。k最常⽤的取值是10,此时称为10折交叉验证;其他常⽤的k值有5、20等。下图给出了10折交叉验证的示意图。
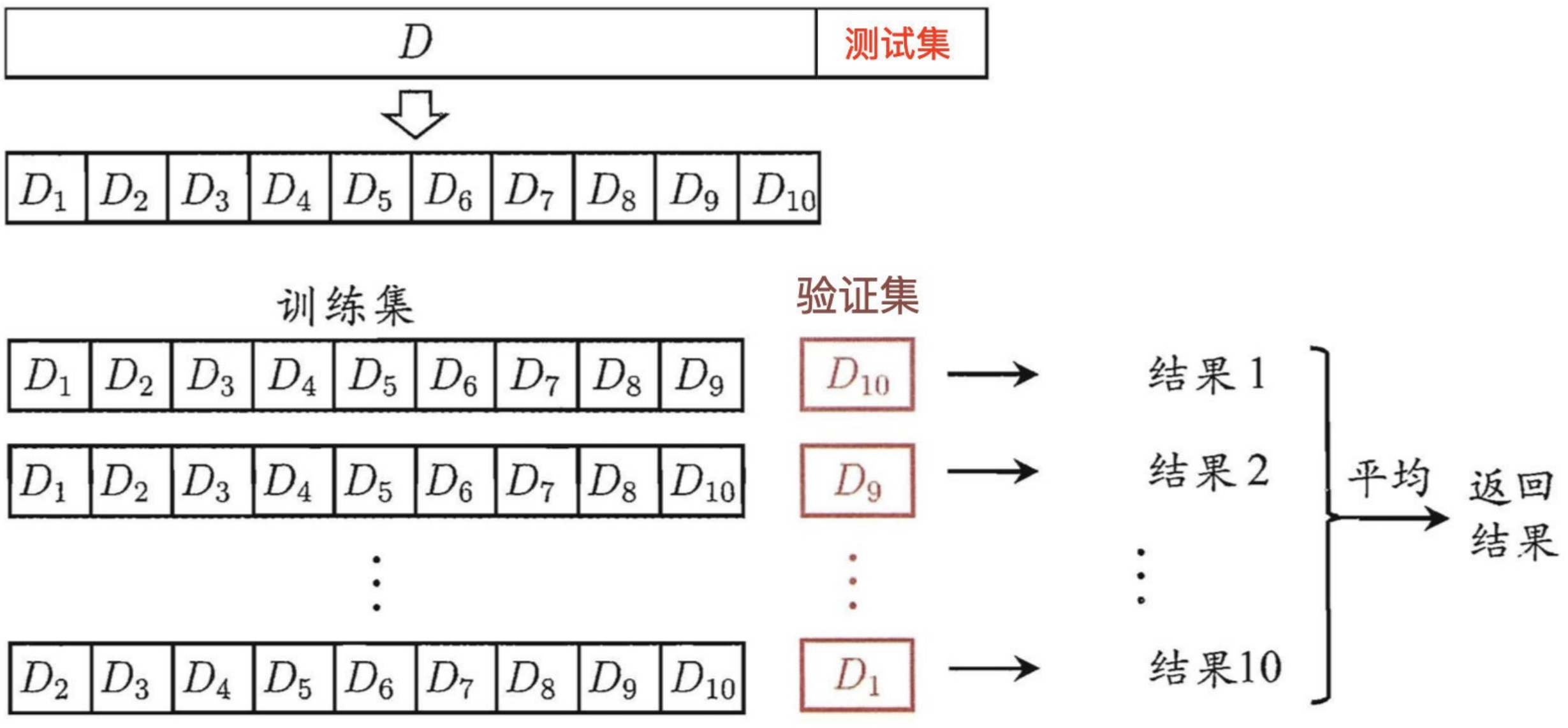
与留出法相似,将数据集D划分为k个⼦集同样存在多种划分⽅式。为减⼩因样本划分不同⽽引⼊的差别,k折交叉验证通常要随机使⽤不同的划分重复p次,最终的评估结果是这p次k折交叉验证结果的均值,例如常⻅的有 “10次10折交叉验证”。
交叉验证实现⽅法,除了咱们前⾯讲的GridSearchCV之外,还有KFold, StratifiedKFold
KFold和StratifiedKFold
from sklearn.model_selection import KFold,StratifiedKFold- ⽤法:
- 将训练/测试数据集划分n_splits个互斥⼦集,每次⽤其中⼀个⼦集当作验证集,剩下的n_splits-1个作为训练集,进⾏n_splits次训练和测试,得到n_splits个结果。
- StratifiedKFold的⽤法和KFold的区别是:SKFold是分层采样,确保训练集,测试集中,各类别样本的⽐例是和原始数据集中的⼀致。
- 注意点:
- 对于不能均等分数据集,其前n_samples % n_splits⼦集拥有n_samples // n_splits + 1个样本,其余⼦集都只有n_samples // n_splits样本。
- 参数说明:
- n_splits:表示划分⼏等份
- shuffle:在每次划分时,是否进⾏洗牌
-
-
- ①若为Falses时,其效果等同于random_state等于整数,每次划分的结果相同
- ②若为True时,每次划分的结果都不⼀样,表示经过洗牌,随机取样的
-
- 属性:
- ①split(x, y=None, groups=None):将数据集划分成训练集和测试集,返回索引⽣成器
from sklearn.model_selection import KFold, StratifiedKFold
import numpy as np
X = np.array([
[1, 2, 3, 4],
[11, 12, 13, 14],
[21, 22, 23, 24],
[31, 32, 33, 34],
[41, 42, 43, 44],
[51, 52, 53, 54],
[61, 62, 63, 64],
[71, 72, 73, 74]
])
y = np.array([1, 1, 0, 0, 1, 1, 0, 0])
k_fold = KFold(n_splits=4, shuffle=False)
split1 = k_fold.split(X, y)
for train_data, test_data in split1:
print(f'训练集:{train_data},测试集:{test_data}')
print('*' * 50)
stratified_k_fold = StratifiedKFold(n_splits=4, shuffle=False)
split2 = stratified_k_fold.split(X, y)
for train_data, test_data in split2:
print(f'训练集:{train_data},测试集:{test_data}')训练集:[2 3 4 5 6 7],测试集:[0 1]
训练集:[0 1 4 5 6 7],测试集:[2 3]
训练集:[0 1 2 3 6 7],测试集:[4 5]
训练集:[0 1 2 3 4 5],测试集:[6 7]
**************************************************
训练集:[1 3 4 5 6 7],测试集:[0 2]
训练集:[0 2 4 5 6 7],测试集:[1 3]
训练集:[0 1 2 3 5 7],测试集:[4 6]
训练集:[0 1 2 3 4 6],测试集:[5 7]可以看出,sfold进⾏4折计算时候,是平衡了测试集中,样本正负的分布的;但是fold却没有。
3 自助法
我们希望评估的是⽤D训练出的模型。但在留出法和交叉验证法中,由于保留了⼀部分样本⽤于测试,因此实际评估的模型所使⽤的训练集⽐D⼩,这必然会引⼊⼀些因训练样本规模不同⽽导致的估计偏差。留⼀法受训练样本规模变化的影响较⼩,但计算复杂度⼜太⾼了。
有没有什么办法可以减少训练样本规模不同造成的影响,同时还能⽐较⾼效地进⾏实验估计呢?
“⾃助法”( bootstrapping)是⼀个⽐较好的解决⽅案,它直接以⾃助采样法( bootstrap sampling)为基础。给定包含m个样本的数据集D,我们对它进⾏采样产⽣数据集D:
每次随机从D中挑选⼀个样本,将其拷⻉放⼊D,然后再将该样本放回初始数据集D中,使得该样本在下次采样时仍有可能被采到;
这个过程重复执⾏m次后,我们就得到了包含m个样本的数据集D′,这就是⾃助采样的结果。
显然,D中有⼀部分样本会在D′中多次出现,⽽另⼀部分样本不出现。可以做⼀个简单的估计,样本在m次采样中始终不被采到的概率是(1 − 1/m )m,取极限得到:
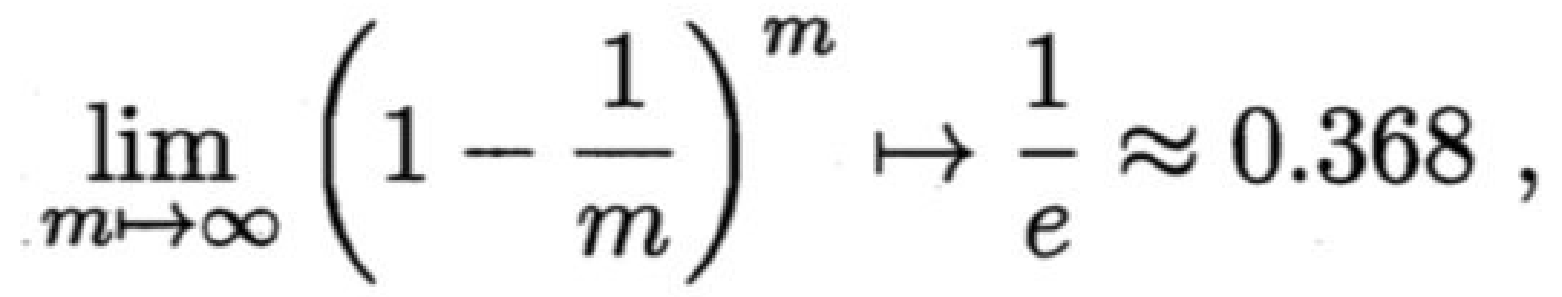

即通过⾃助采样,初始数据集D中约有36.8%的样本未出现在采样数据集D′中。
于是我们可将D′⽤作训练集,D\D′⽤作测试集;这样,实际评估的模型与期望评估的模型都使⽤m个训练样本,⽽我们仍有数据总量约1/3的、没在训练集中出现的样本⽤于测试。
这样的测试结果,亦称“包外估计”(out- of-bagestimate)
⾃助法优缺点:
优点:
- ⾃助法在数据集较⼩、难以有效划分训练/测试集时很有⽤;
- 此外,⾃助法能从初始数据集中产⽣多个不同的训练集,这对集成学习等⽅法有很⼤的好处。
缺点:
- ⾃助法产⽣的数据集改变了初始数据集的分布,这会引⼊估计偏差。因此,在初始数据量⾜够时;留出法和交叉验证法更常⽤⼀些。
4 总结
综上所述:
当我们数据量⾜够时,选择留出法简单省时,在牺牲很⼩的准确度的情况下,换取计算的简便;
当我们的数据量较⼩时,我们应该选择交叉验证法,因为此时划分样本集将会使训练数据过少;
当我们的数据量特别少的时候,我们可以考虑留⼀法。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号