线性回归
线性回归简介
线性回归应⽤场景
- 房价预测
- 销售额度预测
- 贷款额度预测
举例:

什么是线性回归
定义与公式
线性回归(Linear regression)是利⽤回归⽅程(函数)对⼀个或多个⾃变量(特征值)和因变量(⽬标值)之间关系进⾏建模的⼀种分析⽅式。
特点:只有⼀个⾃变量的情况称为单变量回归,多于⼀个⾃变量情况的叫做多元回归
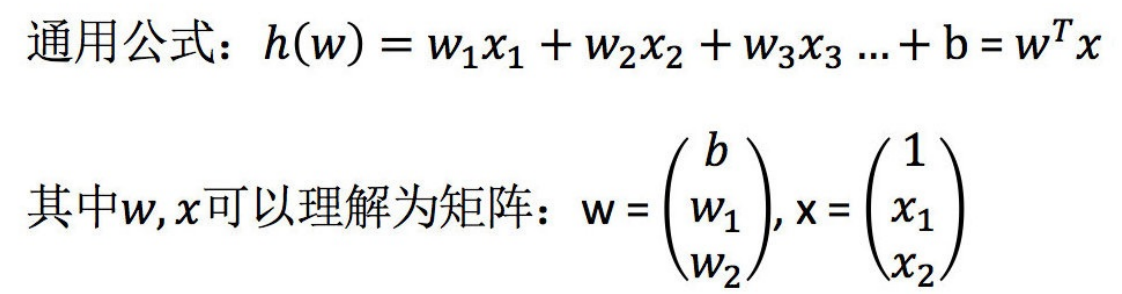
线性回归⽤矩阵表示举例:
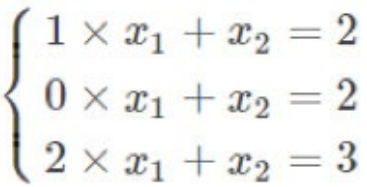
写成矩阵:

从列的角度看:
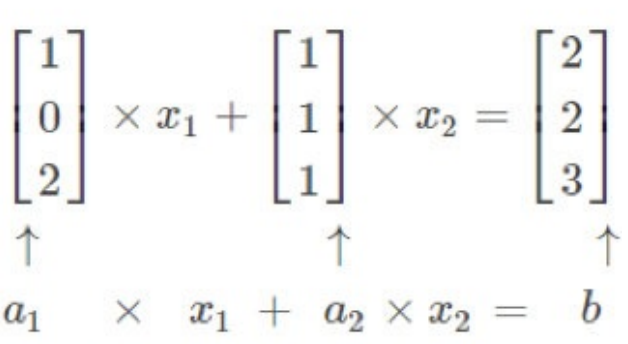
辅助理解,我们来看⼏个例⼦:
- 期末成绩:0.7×考试成绩+0.3×平时成绩
- 房⼦价格 = 0.02×中⼼区域的距离 + 0.04×城市⼀氧化氮浓度 + (-0.12×⾃住房平均房价) + 0.254×城镇犯罪率
上⾯两个例⼦,我们看到特征值与⽬标值之间建⽴了⼀个关系,这个关系可以理解为线性模型。
回归关系分类
线性回归当中主要有两种模型,⼀种是线性关系,另⼀种是⾮线性关系。在这⾥我们只能画⼀个平⾯更好去理解,所以都⽤单个特征或两个特征举例⼦。
线性关系
-
单变量线性关系:

-
多变量线性关系

注释:单特征与⽬标值的关系呈直线关系,或者两个特征与⽬标值呈现平⾯的关系,更⾼维度的我们不⽤⾃⼰去想,记住这种关系即可
⾮线性关系

注释:为什么会这样的关系呢?原因是什么?
如果是⾮线性关系,那么回归⽅程可以理解为:
线性回归的损失和优化
学习⽬标
- 知道线性回归中损失函数
- 知道使⽤正规⽅程对损失函数优化的过程
- 知道使⽤梯度下降法对损失函数优化的过程
假设刚才的房⼦例⼦,真实的数据之间存在这样的关系:
真实关系:真实房⼦价格 = 0.02×中⼼区域的距离 + 0.04×城市⼀氧化氮浓度 + (-0.12×⾃住房平均房价) + 0.254×城镇犯罪率
那么现在呢,我们随意指定⼀个关系(猜测)
随机指定关系:预测房⼦价格 = 0.25×中⼼区域的距离 + 0.14×城市⼀氧化氮浓度 + 0.42×⾃住房平均房价 + 0.34×城镇犯罪率
请问这样的话,会发⽣什么?真实结果与我们预测的结果之间是不是存在⼀定的误差呢?类似这样样⼦:

既然存在这个误差,那我们就将这个误差给衡量出来
损失函数
损失函数(Loss Function)是机器学习和深度学习的核心组件,用于量化模型预测结果与真实值之间的差异。通过最小化损失函数,模型逐步优化参数,提升预测能力。
总损失定义为:

注:不同的算法适合不同的损失函数,关于损失函数分类与详解,参照文末预备知识-损失函数
如何去减少这个损失,使我们预测的更加准确些?这⾥可以通过⼀些优化⽅法去优化(其实是数学当中的求导功能)回归的总损失!!!
优化算法
如何去求模型当中的W,使得损失最⼩?(⽬的是找到最⼩损失对应的W值)
线性回归经常使⽤的两种优化算法
- 最小二乘法
- 梯度下降法
最小二乘法
什么是最小二乘法
直接通过矩阵运算求解线性回归参数,又称正规⽅程:
![]()
X为特征值矩阵,y为⽬标值矩阵。直接根据求出到
缺点:当特征过多过复杂时,求解速度太慢并且得不到结果

最小二乘法求解举例
以下表示数据为例:

即:
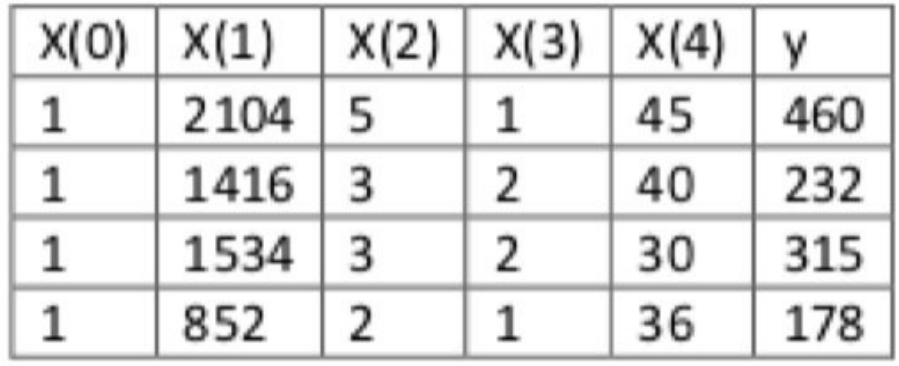
运⽤正规⽅程⽅法求解参数:

由以上式子可见正规方程的计算量巨大。
梯度下降(Gradient Descent)
梯度的概念
梯度是微积分中⼀个很重要的概念
在单变量的函数中,梯度其实就是函数的微分(导数),代表着函数在某个给定点的切线的斜率;
在多变量函数中,梯度是⼀个向量,向量有⽅向,梯度的⽅向就指出了函数在给定点的上升最快的⽅向;
在微积分⾥⾯,对多元函数的参数求∂偏导数,把求得的各个参数的偏导数以向量的形式写出来,就是梯度。
这也就说明了为什么我们需要千⽅百计的求取梯度!我们需要到达⼭底,就需要在每⼀步观测到此时最陡峭的地⽅,梯度就恰巧告诉了我们这个⽅向。梯度的⽅向是函数在给定点上升最快的⽅向,那么梯度的反⽅向就是函数在给定点下降最快的⽅向,这正是我们所需要的。所以我们只要沿着梯度的反⽅向⼀直⾛,就能⾛到局部的最低点!
什么是梯度下降
梯度下降法的基本思想可以类⽐为⼀个下⼭的过程。
假设这样⼀个场景:
⼀个⼈被困在⼭上,需要从⼭上下来(找到⼭的最低点,也就是⼭⾕)。但此时⼭上的浓雾很⼤,导致可视度很低。因此,下⼭的路径就⽆法确定,他必须利⽤⾃⼰周围的信息去找到下⼭的路径。这个时候,他就可以利⽤梯度下降算法来帮助⾃⼰下⼭。
具体来说就是,以他当前的所处的位置为基准,寻找这个位置最陡峭的地⽅,然后朝着⼭的⾼度下降的地⽅⾛,(同理,如果我们的⽬标是上⼭,也就是爬到⼭顶,那么此时应该是朝着最陡峭的⽅向往上⾛)。然后每⾛⼀段距离,都反复采⽤同⼀个⽅法,最后就能成功的抵达⼭⾕。

梯度下降的基本过程就和下⼭的场景很类似。
⾸先,我们有⼀个可微分的函数。这个函数就代表着⼀座⼭。
我们的⽬标就是找到这个函数的最⼩值,也就是⼭底。
根据之前的场景假设,最快的下⼭的⽅式就是找到当前位置最陡峭的⽅向,然后沿着此⽅向向下⾛,对应到函数中,就是找到给定点的梯度 ,然后朝着梯度相反的⽅向,就能让函数值下降的最快!因为梯度的⽅向就是函数值变化最快的⽅向。 所以,我们重复利⽤这个⽅法,反复求取梯度,最后就能到达局部的最⼩值,这就类似于我们下⼭的过程。⽽求取梯度就确定了最陡峭的⽅向,也就是场景中测量⽅向的⼿段。
阅读下面内容如果困惑,可以先阅读详解梯度下降
梯度下降的基本原理
- 目标:寻找损失函数 的最小值,其中 为模型参数。
- 梯度方向:梯度 指向函数增长最快的方向,负梯度方向则是下降最快的方向。
- 参数更新公式:

其中 为学习率,控制步长。
梯度下降(Gradient Descent)公式

1) α是什么含义?
α在梯度下降算法中被称作为学习率或者步⻓,意味着我们可以通过α来控制每⼀步⾛的距离,以保证不要步⼦跨的太⼤扯着蛋,哈哈,其实就是不要⾛太快,错过了最低点。同时也要保证不要⾛的太慢,导致太阳下⼭了,还没有⾛到⼭下。所以α的选择在梯度下降法中往往是很重要的!α不能太⼤也不能太⼩,太⼩的话,可能导致迟迟⾛不到最低点,太⼤的话,会导致错过最低点!
学习率与收敛性
- 学习率选择:过大导致震荡或不收敛,过小则收敛慢。
收敛性分析:
- 凸函数:保证收敛到全局最优。
- 非凸函数:可能陷入局部最优或鞍点,高维问题中鞍点常见。

2) 为什么梯度要乘以⼀个负号?
梯度前加⼀个负号,就意味着朝着梯度相反的⽅向前进!我们在前⽂提到,梯度的⽅向实际就是函数在此点上升最快的⽅向!⽽我们需要朝着下降最快的⽅向⾛,⾃然就是负的梯度的⽅向,所以此处需要加上负号
我们通过两个图更好理解梯度下降的过程
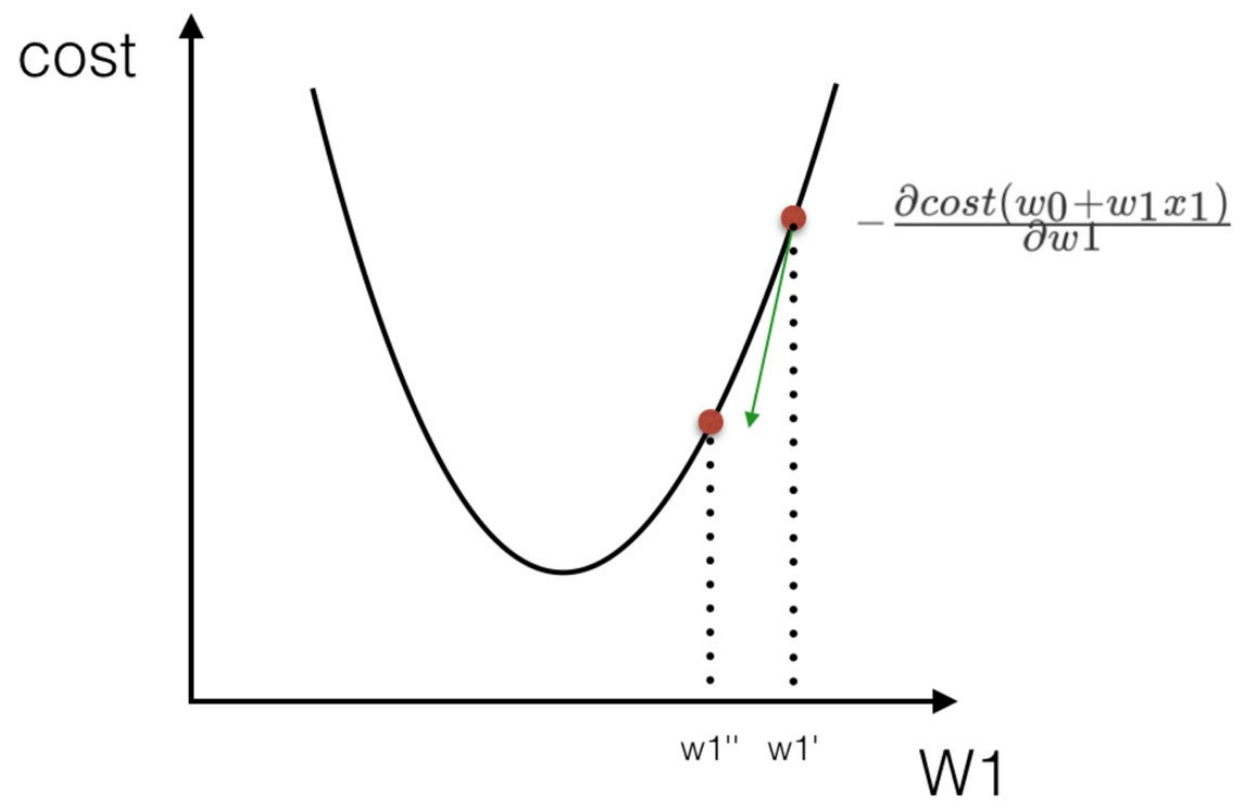
所以有了梯度下降这样⼀个优化算法,回归就有了"⾃动学习"的能⼒
梯度下降举例
1.单变量函数的梯度下降**
我们假设有⼀个单变量的函数 :J(θ) = θ 2
函数的微分(导数):J′(θ) = 2θ
初始化,起点为: θ 0 = 1
学习率:α = 0.4
我们开始进⾏梯度下降的迭代计算过程
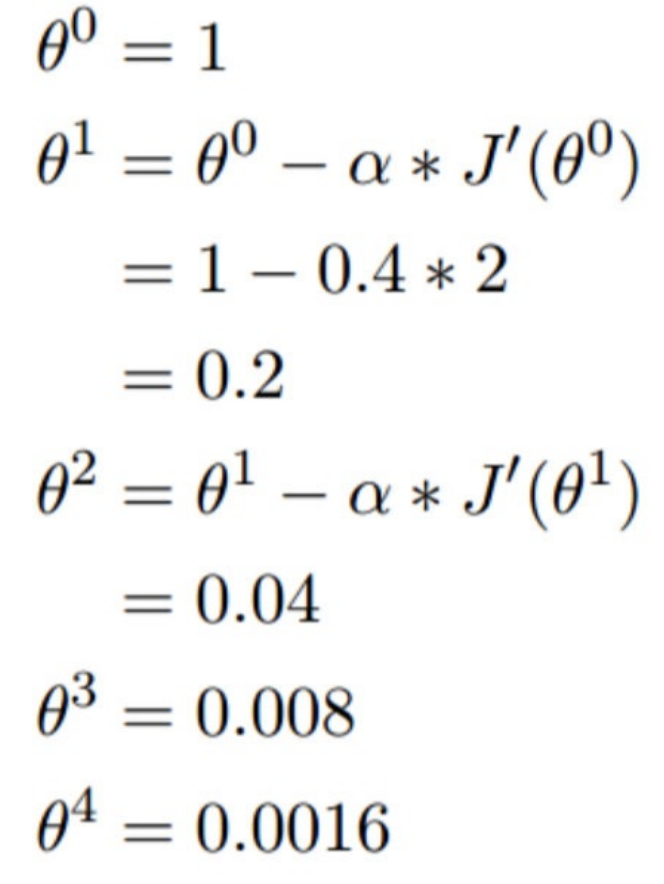
如图,经过四次的运算,也就是⾛了四步,基本就抵达了函数的最低点,也就是⼭底

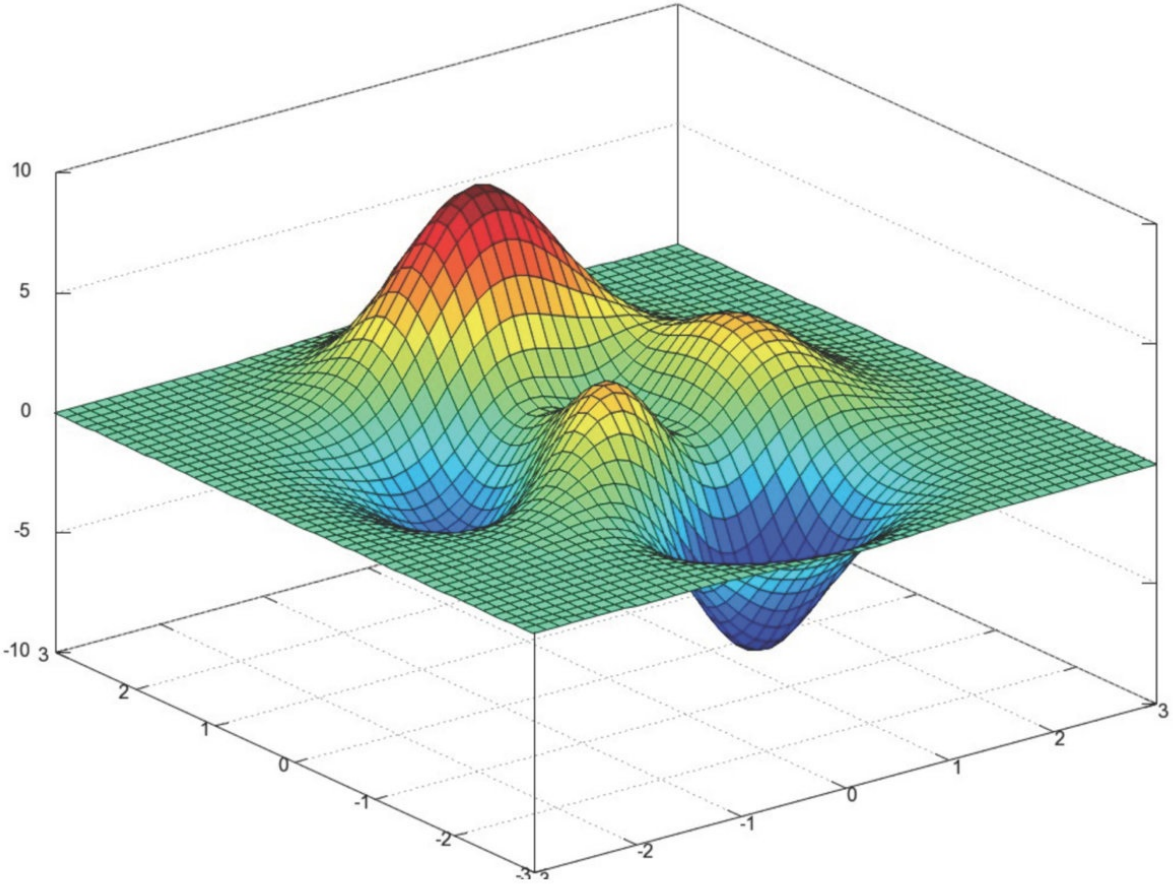
多变量函数的梯度下降
我们假设有⼀个⽬标函数 :![]()
现在要通过梯度下降法计算这个函数的最⼩值。我们通过观察就能发现最⼩值其实就是 (0,0)点。但是接下 来,我们会从梯度下降算法开始⼀步步计算到这个最⼩值! 我们假设初始的起点为: θ 0 = (1, 3)
初始的学习率为:α = 0.1
函数的梯度为:∇J(θ) =< 2θ1 ,2θ2>
进⾏多次迭代:

我们发现,已经基本靠近函数的最⼩值点

梯度下降&最小二乘法对⽐
两种⽅法对⽐
|
梯度下降 |
最小二乘法 |
|
需要选择学习率 |
不需要 |
|
需要迭代求解 |
⼀次运算得出 |
|
特征数量较⼤可以使⽤ |
需要计算⽅程,时间复杂度⾼O(n3) |
经过前⾯的介绍,我们发现最⼩⼆乘法简洁⾼效,⽐梯度下降这样的迭代法似乎⽅便很多。但是这⾥我们就聊聊最⼩⼆乘法的局限性。
⾸先,最⼩⼆乘法需要计算XTX的逆矩阵,有可能它的逆矩阵不存在,这样就没有办法直接⽤最⼩⼆乘法了。
- 此时就需要使⽤梯度下降法。当然,我们可以通过对样本数据进⾏整理,去掉冗余特征。让XTX的⾏列式不为0,然后继续使⽤最⼩⼆乘法。
第⼆,当样本特征n⾮常的⼤的时候,计算XTX的逆矩阵是⼀个⾮常耗时的⼯作(nxn的矩阵求逆),甚⾄不可⾏。
- 此时以梯度下降为代表的迭代法仍然可以使⽤。
- 那这个n到底多⼤就不适合最⼩⼆乘法呢?如果你没有很多的分布式⼤数据计算资源,建议超过10000个特征就⽤迭代法吧。或者通过主成分分析降低特征的维度后再⽤最⼩⼆乘法。
第三,如果拟合函数不是线性的,这时⽆法使⽤最⼩⼆乘法,需要通过⼀些技巧转化为线性才能使⽤,此时梯度下降仍然可以⽤。
第四,以下特殊情况:
- 当样本量m很少,⼩于特征数n的时候,这时拟合⽅程是⽋定的,常⽤的优化⽅法都⽆法去拟合数据。
- 当样本量m等于特征数n的时候,⽤⽅程组求解就可以了。
- 当m⼤于n时,拟合⽅程是超定的,也就是我们常⽤与最⼩⼆乘法的场景了。
算法选择依据:
⼩规模数据:
- 最小二乘法:LinearRegression(不能解决拟合问题)
- 岭回归
⼤规模数据:
- 梯度下降法:SGDRegressor
经过前⾯介绍,我们发现在真正的开发中,我们使⽤梯度下降法偏多(深度学习中更加明显),下⼀节中我们会进⼀步介绍梯度下降法的⼀些原理。
梯度下降的类型
⾸先,我们来看⼀下,常⻅的梯度下降算法有:
- 全梯度下降算法(Full gradient descent),=批量梯度下降(BGD)
- 随机梯度下降算法(Stochastic gradient descent),
- ⼩批量梯度下降算法(Mini-batch gradient descent),
- 随机平均梯度下降算法(Stochastic average gradient descent)
它们都是为了正确地调节权重向量,通过为每个权重计算⼀个梯度,从⽽更新权值,使⽬标函数尽可能最⼩化。其差别在于样本的使⽤⽅式不同。
2.1 全梯度下降算法(FGD)=批量梯度下降(BGD)
- 使用全部数据计算梯度,稳定性高但计算开销大。
批量梯度下降法,是梯度下降法最常⽤的形式,具体做法也就是在更新参数时使⽤所有的样本来进⾏更新。
计算训练集所有样本误差,对其求和再取平均值作为⽬标函数。
权重向量沿其梯度相反的⽅向移动,从⽽使当前⽬标函数减少得最多。
其是在整个训练数据集上计算损失函数关于参数θ 的梯度:

由于我们有m个样本,这⾥求梯度的时候就⽤了所有m个样本的梯度数据。
注意:
- 因为在执⾏每次更新时,我们需要在整个数据集上计算所有的梯度,所以批梯度下降法的速度会很慢,同时,批梯度下降法⽆法处理超出内存容量限制的数据集。
- 批梯度下降法同样也不能在线更新模型,即在运⾏的过程中,不能增加新的样本。
2.2 随机梯度下降算法(SGD)
- 每次随机选取一个样本计算梯度,速度快但波动较大。
由于FGD每迭代更新⼀次权重都需要计算所有样本误差,⽽实际问题中经常有上亿的训练样本,故效率偏低,且容易陷⼊局部最优解,因此提出了随机梯度下降算法。
其每轮计算的⽬标函数不再是全体样本误差,⽽仅是单个样本误差,即每次只代⼊计算⼀个样本⽬标函数的梯度来更新权重,再取下⼀个样本重复此过程,直到损失函数值停⽌下降或损失函数值⼩于某个可以容忍的阈值。
此过程简单,⾼效,通常可以较好地避免更新迭代收敛到局部最优解。其迭代形式为

但是由于,SG每次只使⽤⼀个样本迭代,若遇上噪声则容易陷⼊局部最优解。
2.3 ⼩批量梯度下降算法(mini-batch GD)
- FGD和SGD的折中方案,每次使用一小批数据(如32、64个样本),平衡效率与稳定性。在⼀定程度上兼顾了以上两种⽅法的优点。
每次从训练样本集上随机抽取⼀个⼩样本集,在抽出来的⼩样本集上采⽤FG迭代更新权重。
被抽出的⼩样本集所含样本点的个数称为batch_size,通常设置为2的幂次⽅,更有利于GPU加速处理。
特别的,若batch_size=1,则变成了SGD;若batch_size=n,则变成了FGD.其迭代形式为
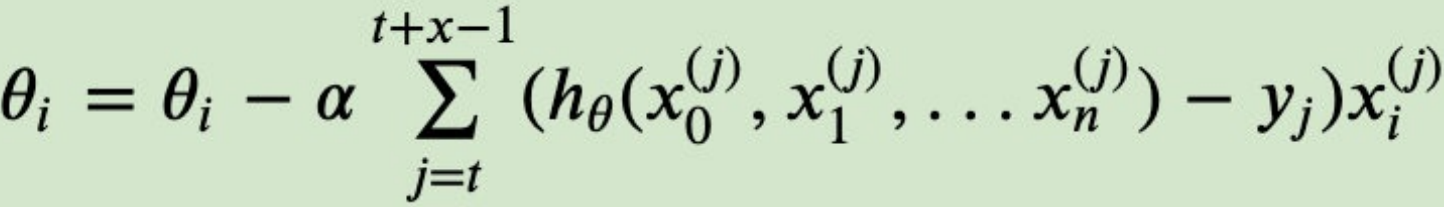
上式中,也就是我们从m个样本中,选择x个样本进⾏迭代(1<x<m)
2.4 随机平均梯度下降算法(SAG)
在SGD⽅法中,虽然避开了运算成本⼤的问题,但对于⼤数据训练⽽⾔,SGD效果常不尽如⼈意,因为每⼀轮梯度更新都完全与上⼀轮的数据和梯度⽆关。
随机平均梯度算法克服了这个问题,在内存中为每⼀个样本都维护⼀个旧的梯度,随机选择第i个样本来更新此样本的梯度,其他样本的梯度保持不变,然后求得所有梯度的平均值,进⽽更新了参数。
如此,每⼀轮更新仅需计算⼀个样本的梯度,计算成本等同于SGD,但收敛速度快得多。
其迭代形式为:
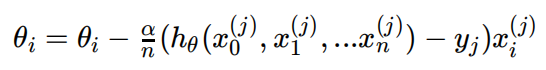
我们知道sgd是当前权重减去步⻓乘以梯度,得到新的权重。sag中的a,就是平均的意思,具体说,就是在第k步迭代的时候,我考虑的这⼀步和前⾯n-1个梯度的平均值,当前权重减去步⻓乘以最近n个梯度的平均值。
n是⾃⼰设置的,当n=1的时候,就是普通的sgd。
这个想法⾮常的简单,在随机中⼜增加了确定性,类似于mini-batch sgd的作⽤,但不同的是,sag⼜没有去计算更多的样本,只是利⽤了之前计算出来的梯度,所以每次迭代的计算成本远⼩于mini-batch sgd,和sgd相当。效果⽽⾔,sag相对于sgd,收敛速度快了很多。这⼀点下⾯的论⽂中有具体的描述和证明。
SAG论⽂链接:https://arxiv.org/pdf/1309.2388.pdf
拓展阅读:
梯度下降法算法⽐较和进⼀步优化
3 ⼩结
- 全梯度下降算法(FGD)【知道】
- 在进⾏计算的时候,计算所有样本的误差平均值,作为我的⽬标函数
- 随机梯度下降算法(SGD)【知道】
- 每次只选择⼀个样本进⾏考核
- ⼩批量梯度下降算法(mini-batch GD)【知道】
- 选择⼀部分样本进⾏考核
- 随机平均梯度下降算法(SAG)【知道】
- 会给每个样本都维持⼀个平均值,后期计算的时候,参考这个平均值
线性回归api
学习⽬标
知道线性回归api的简单使⽤
1最小二乘法的api
sklearn.linear_model.LinearRegression(fit_intercept=True)
通过正规⽅程(最小二乘法)优化
参数
- fit_intercept:是否计算偏置
属性
- LinearRegression.coef_:回归系数(斜率k)
- LinearRegression.intercept_:偏置(截距b)
2 举例

2.1 步骤分析
1.获取数据集
2.数据基本处理(该案例中省略)
3.特征⼯程(该案例中省略)
4.机器学习
5.模型评估(该案例中省略)
2.2 代码过程
导⼊模块
from sklearn.linear_model import LinearRegression构造数据集
x = [[80, 86],
[82, 80],
[85, 78],
[90, 90],
[86, 82],
[82, 90],
[78, 80],
[92, 94]]
y = [84.2, 80.6, 80.1, 90, 83.2, 87.6, 79.4, 93.4]机器学习-- 模型训练
# 实例化API
estimator = LinearRegression()
estimator.fit(x, y)#模型训练
# 模型预测
#打印回归系数
print(estimator.coef_)#[0.3 0.7]
print(estimator.predict([[100,80]]))#[86.]2随机梯度下降api
sklearn.linear_model.SGDRegressor(loss="squared_loss", fit_intercept=True, learning_rate ='invscaling',eta0=0.01)
SGDRegressor类实现了随机梯度下降学习,它⽀持不同的loss函数和正则化惩罚项来拟合线性回归模型。
参数:
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
loss |
str | 'squared_loss'普通最⼩⼆乘法 |
损失函数类型,可选 'huber'、'epsilon_insensitive'(支持向量回归)等。 |
penalty |
str | 'l2' |
正则化类型:'l1'、'l2'、'elasticnet'。 |
alpha |
float | 0.0001 |
正则化强度,值越大正则化越强。 |
learning_rate |
str | 'invscaling' |
学习率调度策略: - 'constant':固定学习率;- 'optimal':根据理论公式调整;- 'invscaling':逐步衰减。 |
eta0 |
float | 0.01 |
初始学习率,需与 learning_rate 配合使用。 |
max_iter |
int | 1000 |
最大迭代次数(遍历数据集的轮数)。 |
tol |
float | 1e-3 |
停止条件:损失下降小于 tol 时提前停止。 |
shuffle |
bool | True |
是否在每轮迭代前打乱数据。 |
epsilon |
float | 0.1 |
当 loss='huber' 时,Huber 损失的阈值参数。 |
power_t |
float | 0.25 |
'invscaling' 学习率的衰减指数。 |
| fit_intercept | 是否计算偏置 |
属性:
- SGDRegressor.coef_:回归系数
- SGDRegressor.intercept_:偏置
案例:波⼠顿房价预测
学习⽬标
通过案例掌握正规⽅程和梯度下降法api的使⽤
1 案例背景介绍
数据介绍


给定的这些特征,是专家们得出的影响房价的结果属性。我们此阶段不需要⾃⼰去探究特征是否有⽤,只需要使⽤这些特征。到后⾯量化很多特征需要我们⾃⼰去寻找
注意,波士顿房价数据官方以下架,代码采用官方推荐替代数据:加州房产数据:
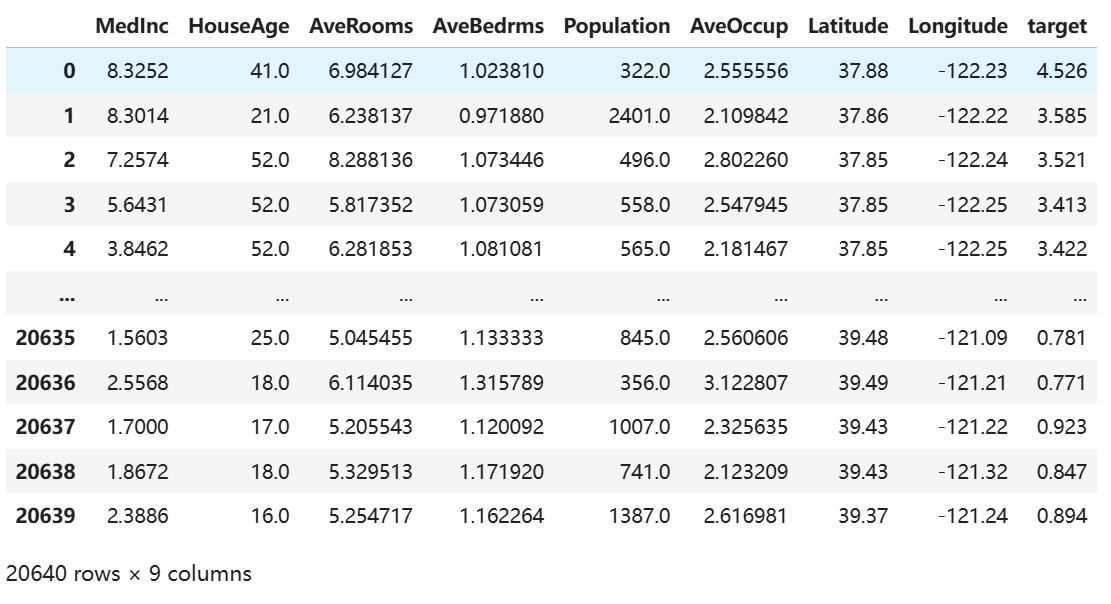
2 案例分析
- 回归当中的数据⼤⼩不⼀致,是否会导致结果影响较⼤。所以需要做标准化处理。
- 数据分割与标准化处理
- 回归预测
- 线性回归的算法效果评估
3 回归性能评估
均⽅误差(Mean Squared Error)MSE)评价机制:
![]()
注:yi为预测值,ȳ 为真实值
API
- sklearn.metrics.mean_squared_error(y_true, y_pred)
- 均⽅误差回归损失
- y_true:真实值
- y_pred:预测值
- return:浮点数结果
4 代码实现
公共代码
# from sklearn.datasets import load_boston
# Scikit-learn 从 1.2 版本起移除了波士顿房价数据集(load_boston),因其涉及伦理问题(数据中隐含种族歧视假设)。
# 原波士顿数据集中的 B 变量(黑人比例)被假设与房价负相关,隐含种族偏见。该数据集被广泛用于模型教学,但未对数据背后的歧视性假设进行批判性讨论。
# 1. 替代数据集推荐
# 1) 加州房价数据集(官方推荐)
import numpy as np
from contourpy.util import data
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.linear_model import SGDRegressor
# 加载数据
housing = fetch_california_housing(data_home=r'D:\learn\000人工智能数据大全\黑马数据\科学计算数据\california_housing')
housing_data = housing.data
target = housing.target4.1 最小二乘法
# 最小二乘法模型
def liner1():
"""
线性回归:正规⽅程
:return:None
"""
# 数据集划分
data_train, data_test, target_train, target_test = train_test_split(housing_data, target, test_size=0.2,
random_state=42)
print(data_train.shape)
print(data_test.shape)
# 特征工程-标准化
stand = StandardScaler()
data_train = stand.fit_transform(data_train)
data_test = stand.transform(data_test)
# 机器学习 - 线性回归(正规⽅程)
# 初始化API
estimator = LinearRegression()
# 模型训练
estimator.fit(data_train, target_train)
# 模型预测
predict = estimator.predict(data_test)
print("预测结果:", predict) # 预测结果: [0.71912284 1.76401657 2.70965883 ... 4.46877017 1.18751119 2.00940251]
print("结果条数:", predict.shape) # 结果条数: (4128,)
# 获取系数等值
print("模型的系数为:",
estimator.coef_) # 模型的系数为: [ 0.85438303 0.12254624 -0.29441013 0.33925949 -0.00230772 -0.0408291 -0.89692888 -0.86984178]
print("模型的偏执为:", estimator.intercept_) # 模型的偏执为: 2.071946937378619
# 模型评估
score = estimator.score(data_test, target_test)
print("score:", score) # score: 0.575787706032451
# MSE均方误差
MSE = mean_squared_error(target_test, predict)
print("均方误差:", MSE) # 均方误差: 0.5558915986952442
return None
liner1()4.2 梯度下降法
def liner2():
"""
线性回归:梯度下降
:return:None
"""
# 数据集划分
data_train, data_test, target_train, target_test = train_test_split(housing_data, target, test_size=0.2,
random_state=42)
print(data_train.shape)
print(data_test.shape)
# 特征工程-标准化
stand = StandardScaler()
data_train = stand.fit_transform(data_train)
data_test = stand.transform(data_test)
# 机器学习 - 线性回归(正规⽅程)
# 初始化API
estimator = SGDRegressor(max_iter=1000) # max_iter=1000设置最大迭代次数,梯度下降次数
# 模型训练
estimator.fit(data_train, target_train)
# 模型预测
predict = estimator.predict(data_test)
print("预测结果:", predict) # 预测结果: [0.85949318 1.66875409 3.01797268 ... 4.42609478 1.24498643 2.09051666]
print("结果条数:", predict.shape) # 结果条数: (4128,)
# 获取系数等值
print("模型的系数为:",
estimator.coef_) # 模型的系数为: [ 0.71640053 0.09373369 -0.03365791 0.15597457 -0.01004886 -0.49177261 -1.26320023 -1.21100354]
print("模型的偏执为:", estimator.intercept_) # 模型的偏执为: [2.07023947]
# 模型评估
score = estimator.score(data_test, target_test)
print("score:", score) # score: 0.5749345490339006
# MSE均方误差
MSE = mean_squared_error(target_test, predict)
print("均方误差:", MSE) # 均方误差: 0.5570095832859935
return None
liner2()预测结果与真实结果对比可视化:
plt.figure(figsize=(20,8))
plt.plot(target_test[50:100],label="真实值")
plt.plot(predict[50:100],label="预测值")
plt.legend(fontsize=20)
plt.ylabel("房价", fontsize=20)
plt.xticks(fontsize=20) # X轴刻度标签
plt.yticks(fontsize=20) # Y轴刻度标签
plt.show()
我们也可以尝试去修改学习率
estimator = SGDRegressor(max_iter=1000,learning_rate="constant",eta0=0.1)此时我们可以通过调参数,找到学习率效果更好的值。
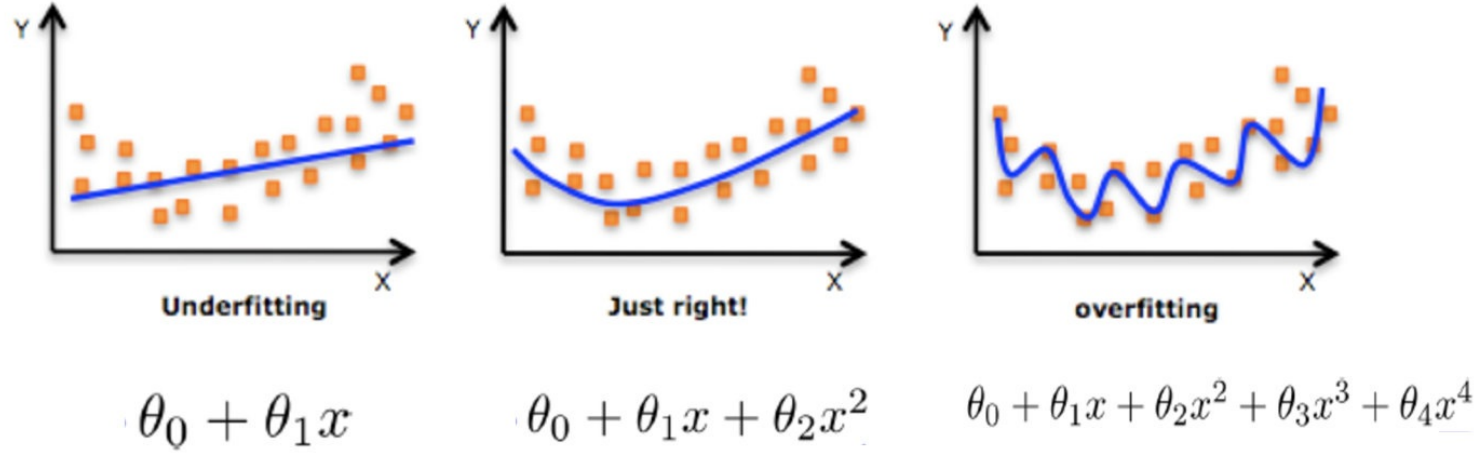
欠拟合&过拟合
正则化
什么是正则化
机器学习中的防过拟合核心技术
(注意,和正则表达式完全没关系)
机器学习中的一个核心问题是设计不仅在训练数据上表现好,并且能在新输入上泛化好的算法。在机器学习中,许多策略显式地被设计来减少测试误差(可能会以增大训练误差为代价)。这些策略被统称为正则化。我们将在后文看到,深度学习工作者可以使用许多不同形式的正则化策略。事实上,开发更有效的正则化策略已成为本领域的主要研究工作之一。————《花书》
正则化的分类
在解决回归过拟合中,我们选择正则化。但是对于其他机器学习算法如分类算法来说也会出现这样的问题,每种算法处理过拟合的方式各不相同:
| 算法类型 | 欠拟合处理 | 过拟合处理 |
|---|---|---|
| 线性模型 | 添加多项式特征 | 增加正则化强度(L1,L2) |
| 决策树 | 增大最大深度 | 剪枝、限制叶节点样本数 |
| 神经网络 | 增加层数/神经元 | Dropout、权重约束 |
| 集成方法 | 增加基学习器数量 | 限制基学习器复杂度 |
针对特征权重W的正则化(即L1和L2)
W:特征权重,即方程里未知数的系数
L1,L2正则化又叫权重衰减
在学习的时候,数据提供的特征有些影响模型复杂度或者这个特征的数据点异常较多,所以算法在学习的时候尽量减少这个特征的影响(甚⾄删除某个特征的影响)
简单记忆:尽量减少高次项的影响



注:调整时候,算法并不知道某个特征影响,⽽是去调整参数得出优化的结果
我们上面讲过算法拟合函数的误差,也就是损失函数:
原误差(损失函数)为:
![]()
正则化之后:
![]()
这就相当于给误差(损失函数)添加了所有次项未知数的系数。
理解:高次项可以很厉害的拟合各种数据(拟合曲线很多弯曲),就好比超人小朋友,看我多牛B...!这个时候爸爸就说了,不可以哦,我们是一个团队,万一你错了,岂不是把大家都带偏了,要想办法限制一下你,于是就把所有次项的系数也加到损失函数里(也会决定误差),系数越大可能造成的误差也就越大哦。根据添加的方式不同,分为L1和L2正则化:
如果添加所有系数的平方和,那就是L2:

如果添加所有系数的绝对值和,那就是L1:
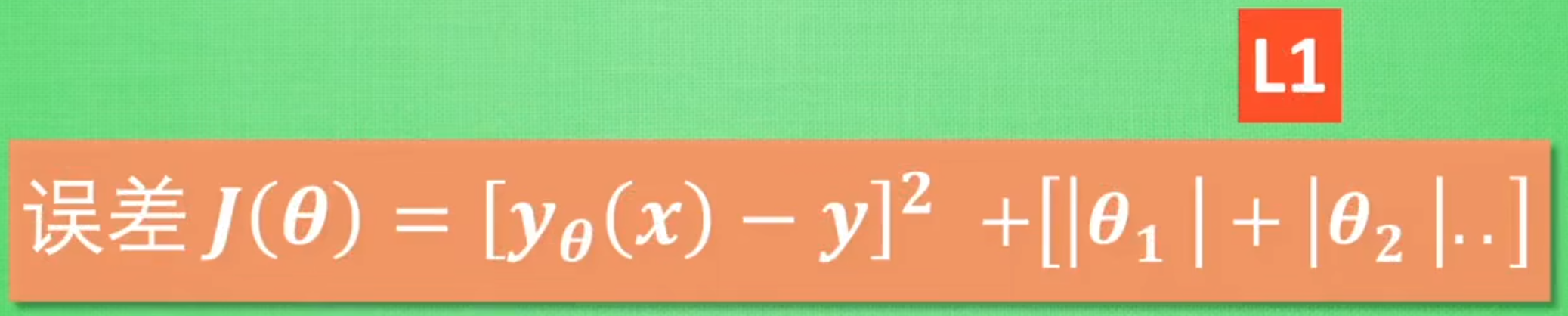
L1,L2范数
一、基础定义与数学表达
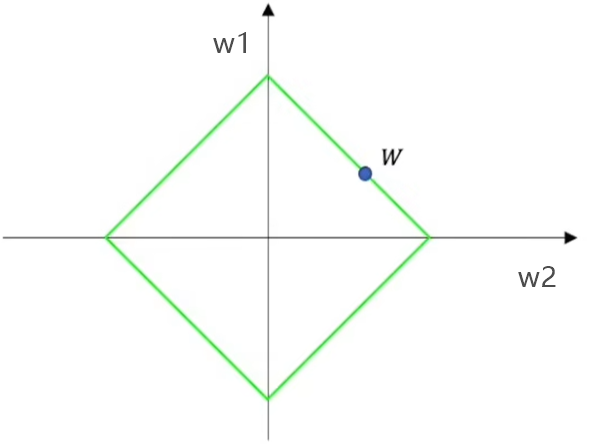
范数类型 数学定义 几何意义 别称 L1范数 曼哈顿距离(方格路径) 曼哈顿范数 L2范数 欧氏距离(直线距离) 欧几里得范数 L1,L2其实就是指L1范数和L2范数,就是把空间里两点的距离的概念进行扩展,也可以理解为是点W(高维向量)到原点的距离的不同表达方式。
这个距离如果是欧氏距离,即:
那么就是L2范数,那么所有到原点距离相等的W点,就构成下面的图形:
二维图展示:
L1范数就是,用W点包含的所有维度坐标值的绝对值之和来表示W到原点的距离,即:
那么所有到原点距离相等的W点,就构成下面的图形:
二维图展示:
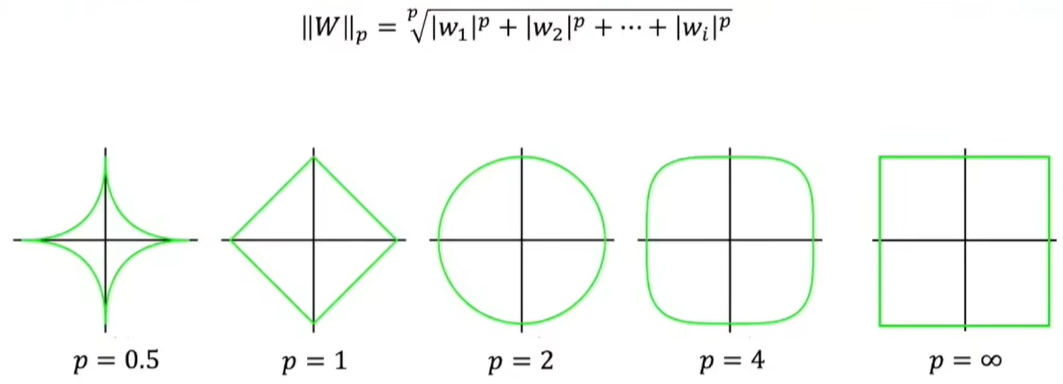
当然,范数有无数多个,只不过我们常用的是L1和L2:
因为只有p≥1的时候,得到的集合才是凸集,p在0~1之间得到的都是非凸集,凸集对应的问题就是凸优化问题,我们有很多成熟的凸优化方法。

L2正则化(岭回归)
岭回归是线性回归的一种正则化版本,即在原来的线性回归的损失函数中添加正则项(regularization term),正则项为权值向量的ℓ2范数:
![]()
以达到在拟合数据的同时,使模型权重尽可能⼩的⽬的,岭回归代价函数:

α又称惩罚力度(假设其他值都固定,α越大,θ就越小),α=0:岭回归退化为线性回归
即:
原误差(损失函数)为:
![]()
正则化之后:
![]()
即:
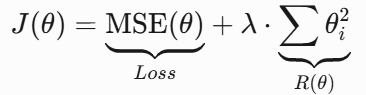

工作机理:

θ = θ(1 - 2ηα) - η∇MSE # 指数衰减机制权重衰减的数学原理(四步完整推导)
拟合曲线函数:
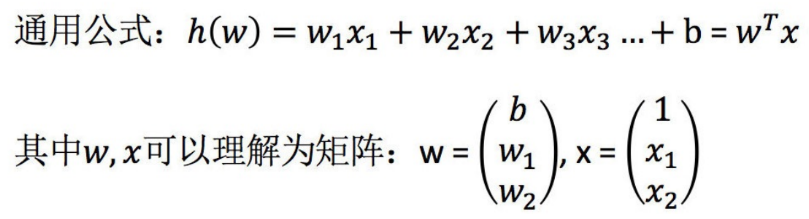
损失函数:
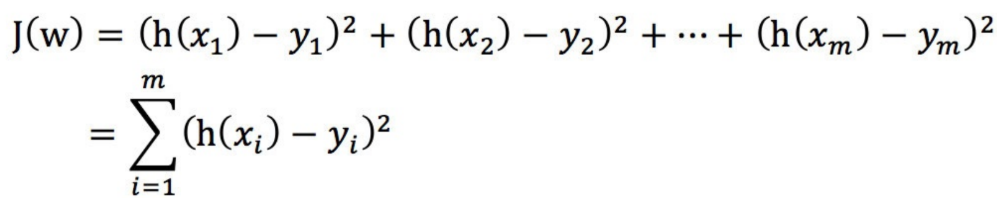


正是这个 (1 - ηα)θ 衰减项,让模型:
- 自动抑制不重要的权重
- 保留重要特征但限制其强度
- 提高对噪声的鲁棒性
几何理解:
损失方程就是原来的误差(蓝线),每条蓝线上的误差值相等
正规化函数产生额外误差(黄线)又叫惩罚度,整个黄线上误差值相等
黄线和蓝线相交时误差最小:

为什么相切时总误差最小?关键三步推演
步骤1:理解等高线与约束域
| 数学对象 | 物理意义 | 形状特性 |
|---|---|---|
| 损失函数等高线 | 相同预测误差的点集合 | 椭圆(中心是原始最优解) |
| L2约束域 | 所有满足正则化限制的参数空间 | 圆形 |
步骤2:相切点的唯一性
-
任意非切点位置(如图中点A):
while 点在约束域内但不在切点:
沿(-∇MSE)方向移动 → MSE减小
但会超出菱形约束域 → 违反正则化限制-
切点特性:
- 该点梯度方向 与约束域边界法向量平行
- 满足KKT条件:
(是拉格朗日乘子)
步骤3:严格数学证明
设切点 ,对任意满足约束的 :
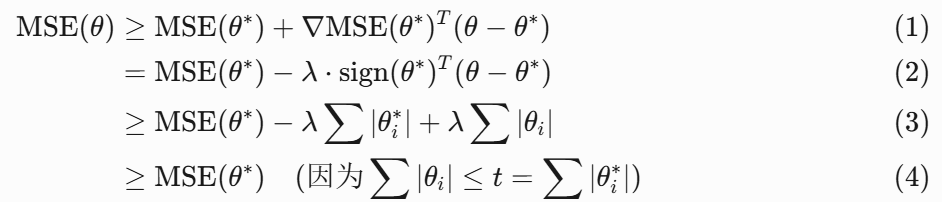
理解:减少高次项的影响
1. 权重衰减的真实对象
📉 衰减的不是高次项,而是所有权重参数本身!
"权重衰减指的是随着步数增加,模型的参数θᵢ在衰减"
- 每次更新:每个权重θᵢ都会乘以小于1的衰减因子
- 物理意义:所有参数值(包括线性项系数)都在向零点收缩
当使用多项式回归时:
- 高次项(如x²,x³)的系数θ₂,θ₃往往较大
- 正则化会特别压制这些大系数
- → 造成"高次项影响减小"的表象
但核心原理仍然是:
所有参数同等受罚,大权重衰减更显著!

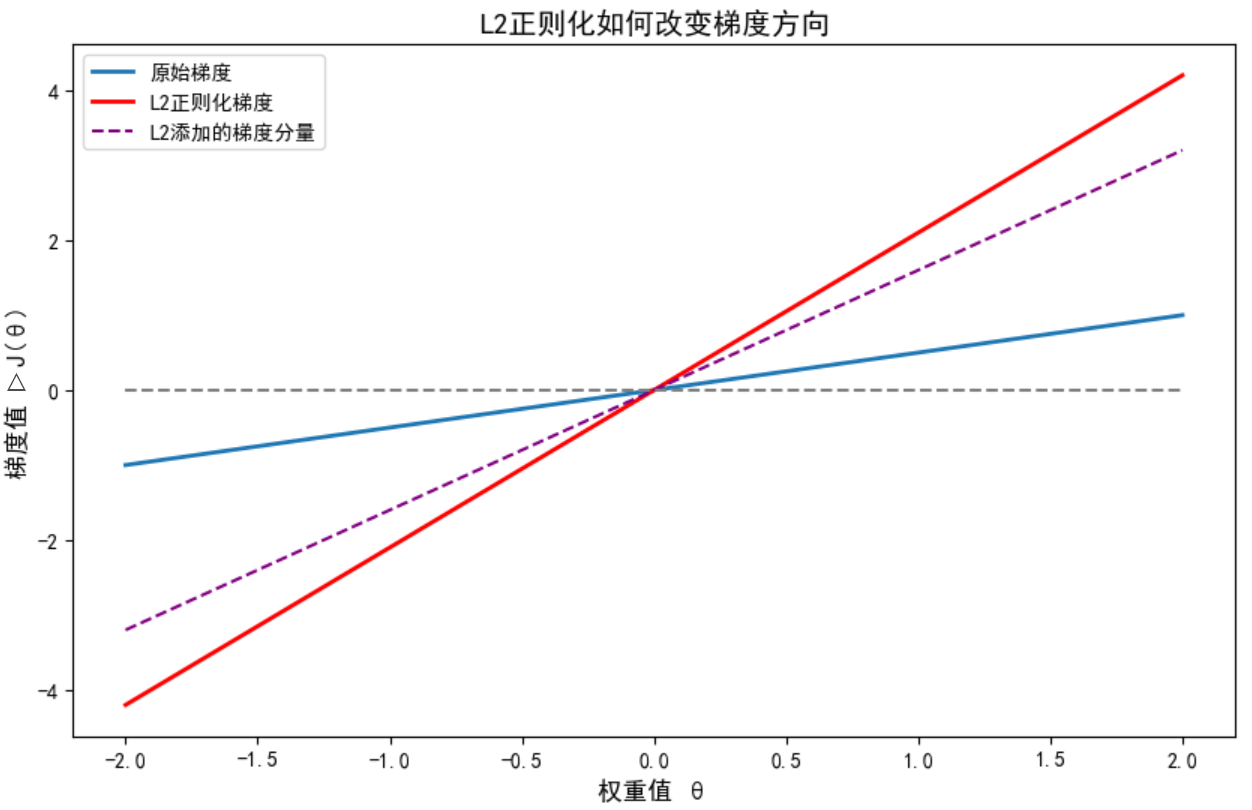
L1正则化
Lasso 回归是线性回归的另⼀种正则化版本,正则项为权值向量的ℓ1范数。
Lasso回归的代价函数 :

工作机理:

if |θ| <= ηα: # (学习率×正则强度)
θ = 0 # 精确归零
else:
θ = θ - ηα·sign(θ) - η∇MSEL1正则化(套索回归):
- 几何解释:损失函数等高线J(θ)与菱形约束域相切
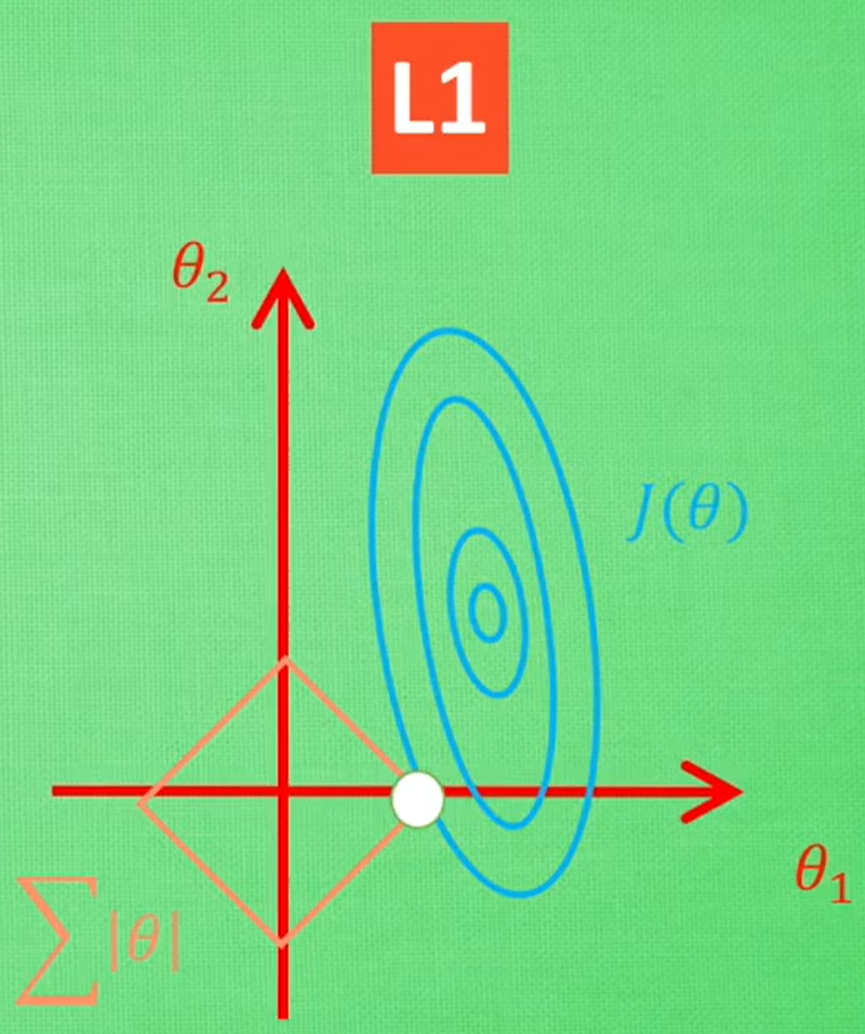
- 稀疏性原理:菱形顶点位于坐标轴,导致部分权重归零
损失函数J(θ)要取最小值,(椭圆的圆心最小),并且所有θ取值又必须满足L1或者L2范式约束,即:点θ即在J(θ)上,又在L约束范围内,因此,当J(θ)和L范式相切时J(θ)才能取得“满足范式约束”的最小值:

- 特征选择:由于使用L1的方法可能只保留一个θ,所以很多人也使用L1正则化来筛选对结果贡献最大的特征。
但是L1的解并不是很稳定,比如用批数据训练,每次批数据都会有不同的误差曲线,此时L1的切点会跳的其他顶点,因为这些地方总误差都会差不多,侧面说明了L1的解不稳定
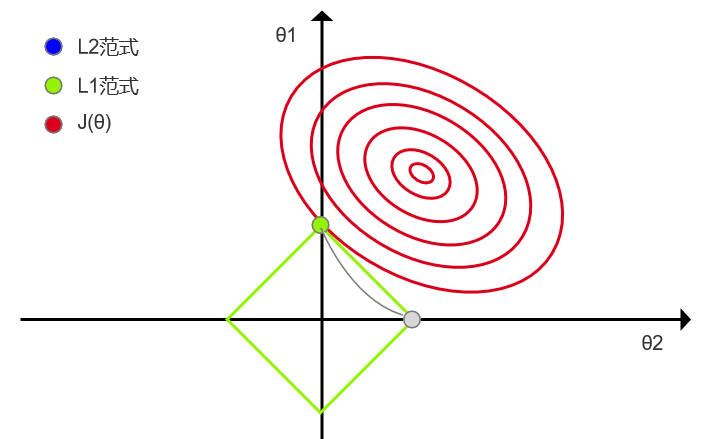
L1解的不稳定性源于菱形的尖角特性与损失函数等高线的动态变化相互作用。当使用批数据训练时,数据分布的变化导致等高线旋转/缩放,使切点可能在不同顶点间跳跃。
【注意 】
Lasso Regression 的代价函数在 θi=0处是不可导的.
解决⽅法:在θi=0处⽤⼀个次梯度向量(subgradient vector)代替梯度,如下式
Lasso Regression 的次梯度向量
L1求导后为:sign(θ)

Lasso Regression 有⼀个很重要的性质是:倾向于完全消除不重要的权重。
例如:当α 取值相对较⼤时,⾼阶多项式退化为⼆次甚⾄是线性:⾼阶多项式特征的权重被置为0。
也就是说,Lasso Regression 能够⾃动进⾏特征选择,并输出⼀个稀疏模型(只有少数特征的权重是⾮零的)。
深度理解:正则化本质是引入对模型复杂度的先验知识。L1对应拉普拉斯先验,L2对应高斯先验,Dropout对应伯努利先验。这种贝叶斯视角揭示了正则化让模型从“记忆数据”转向“理解模式”的哲学本质。
L1和L2正则化简单理解记忆
L1正则化
- 作⽤:可以使得其中⼀些W的值直接为0,删除这个特征的影响
- LASSO回归
L2正则化
- 作⽤:可以使得其中⼀些W的都很⼩,都接近于0,削弱某个特征的影响
- 优点:越⼩的参数说明模型越简单,越简单的模型则越不容易产⽣过拟合现象
- Ridge回归(岭回归)
弹性网络(Elastic Net)
结合L1和L2优势:
弹性⽹络在岭回归和Lasso回归中进⾏了折中,通过 混合⽐(mix ratio) r 进⾏控制
- r=0:弹性⽹络变为岭回归
- r=1:弹性⽹络便为Lasso回归
Early Stopping [了解]
Early Stopping 也是正则化迭代学习的⽅法之⼀。
其做法为:在验证错误率达到最⼩值的时候停⽌训练。
神经网络的特殊应用
Dropout(隐式L2正则化)
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
model = Sequential([
Dense(128, activation='relu'),
Dropout(0.5), # 随机丢弃50%神经元
Dense(64, activation='relu'),
Dropout(0.3),
Dense(10, activation='softmax')
])显式权重正则化
from tensorflow.keras import regularizers
model.add(Dense(64,
kernel_regularizer=regularizers.l1_l2(l1=0.01, l2=0.01),
activation='relu'))
⼀般来说,我们应避免使⽤朴素线性回归,⽽应对模型进⾏⼀定的正则化处理,那如何选择正则化⽅法呢
L1L2应用场景对比指南
| 场景特征 | 推荐方法 | 原因解析 |
|---|---|---|
| 高维特征选择 (p > n) | L1正则化 | 自动筛选相关特征 |
| 特征高度相关 | L2或Elastic | 避免L1随机选择特征 |
| 需要稀疏输出 | L1正则化 | 产生精确零解 |
| 防止过拟合(一般场景) | L2正则化 | 平滑权重,稳定收敛 |
| 异常值较多的数据 | L1正则化 | 对离群点不敏感 |
| 数值稳定性要求高 | L2正则化 | 改善条件数,防止数值溢出 |
常⽤:岭回归
假设只有少部分特征是有⽤的:
- 弹性⽹络
- Lasso
- ⼀般来说,弹性⽹络的使⽤更为⼴泛。因为在特征维度⾼于训练样本数,或者特征是强相关的情况下,Lasso回归的表现不太稳定。
正则化选择方法决策图

最终建议:实践中首选L2正则化作为基准,遇到特征选择需求时转向L1,当特征高度相关且仍需稀疏性时使用Elastic Net。理解这些范数的数学本质,能帮助您根据数据特性做出最佳选择。
岭回归API
API
- sklearn.linear_model.Ridge(alpha=1.0, fit_intercept=True,solver="auto", normalize=False)
- 具有l2正则化的线性回归
- 参数
- alpha:正则化⼒度,也叫 λ
- λ取值:0~1 或1~10
- solver:会根据数据⾃动选择优化⽅法
- sag:如果数据集、特征都⽐较⼤,选择该随机梯度下降优化
- normalize:数据是否进⾏标准化
- normalize=False:可以在fit之前调⽤preprocessing.StandardScaler标准化数据
- alpha:正则化⼒度,也叫 λ
- 返回值
- Ridge.coef_:回归权重
- Ridge.intercept_:回归偏置
Ridge⽅法相当于SGDRegressor(penalty='l2', loss="squared_loss"),只不过SGDRegressor实现了⼀个普通的随机 梯度下降学习,Ridge使用平均梯度下降,推荐使⽤Ridge(实现了SAG)
交叉验证:(筛选最适合的alpha即惩罚力度)
- sklearn.linear_model.RidgeCV(_BaseRidgeCV, RegressorMixin)
- 具有l2正则化的线性回归,可以进⾏交叉验证
- coef_:回归系数
class _BaseRidgeCV(LinearModel):
def __init__(self, alphas=(0.1, 1.0, 10.0),fit_intercept=True, normalize=False,scoring=None,cv=None, gcv_mode=None,store_cv_values=False):2 观察正则化程度的变化,对结果的影响?

正则化⼒度越⼤,权重系数会越⼩
正则化⼒度越⼩,权重系数会越⼤
波⼠顿房价预测案例
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error
from sklearn.linear_model import Ridge
from sklearn.linear_model import RidgeCV
# 加载数据
housing = fetch_california_housing(data_home=r'D:\learn\000人工智能数据大全\黑马数据\科学计算数据\california_housing')
housing_data = housing.data
target = housing.target
def liner3():
"""
线性回归:岭回归
:return:None
"""
# 数据集划分
data_train, data_test, target_train, target_test = train_test_split(housing_data, target, test_size=0.2,
random_state=42)
print(data_train.shape)
print(data_test.shape)
# 特征工程-标准化
stand = StandardScaler()
data_train = stand.fit_transform(data_train)
data_test = stand.transform(data_test)
# 机器学习 - 线性回归(正规⽅程)
# 初始化API
estimator = Ridge(alpha=1) # alpha=1设置惩罚力度
# 使用交叉验证
# estimator = RidgeCV(alphas=(0.1, 1, 10)) # 设置多个惩罚力度
# 模型训练
estimator.fit(data_train, target_train)
# 模型预测
predict = estimator.predict(data_test)
print("预测结果:", predict) # 预测结果: [0.71947224 1.76384666 2.709309 ... 4.46847645 1.18797174 2.00922052]
print("结果条数:", predict.shape) # 结果条数: (4128,)
# 获取系数等值
print("模型的系数为:",
estimator.coef_) # 模型的系数为: [ 0.85432679 0.12262397 -0.29421036 0.33900794 -0.00228221 -0.04083302 -0.89616759 -0.86907074]
print("模型的偏执为:", estimator.intercept_) # 模型的偏执为: 2.071946937378619
# 模型评估
score = estimator.score(data_test, target_test)
print("score:", score) # score: 0.5758157428913686
# MSE均方误差
MSE = mean_squared_error(target_test, predict)
print("均方误差:", MSE) # 均方误差: 0.5558548589435969
return None
liner3()
拓展阅读:
预备知识
数学:求导
学习⽬标
知道常⻅的求导⽅法
知道导数的四则运算
1 常⻅函数的导数

2 导数的四则运算
3 练习
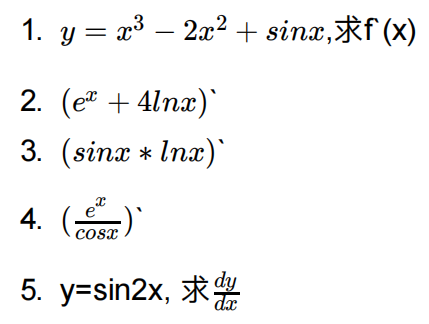
答案:

4 矩阵(向量)求导 [了解]
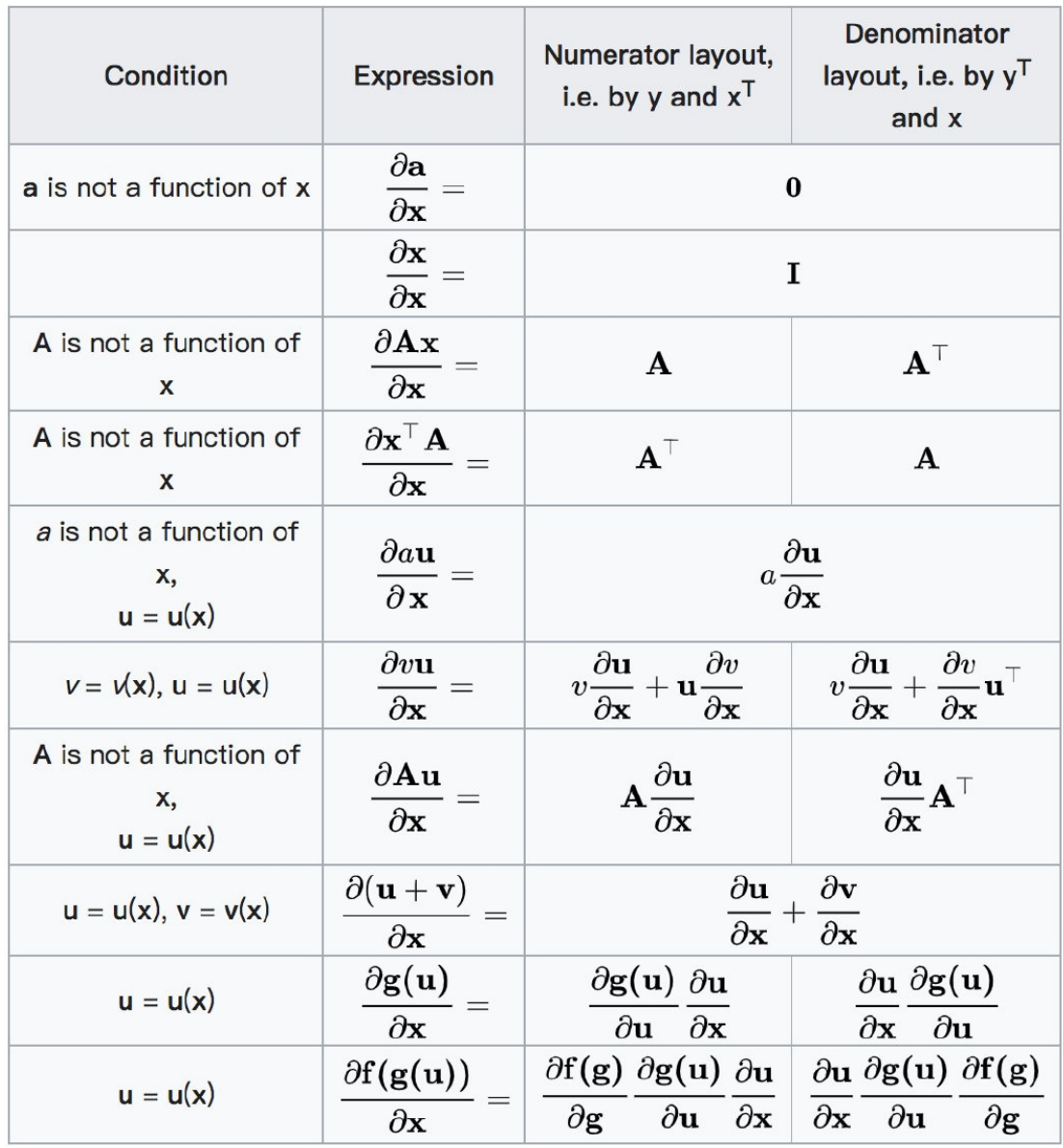
参考链接:https://en.wikipedia.org/wiki/Matrix_calculus#Scalar-by-vector_identities
损失函数
损失函数(Loss Function)是机器学习和深度学习的核心组件,用于量化模型预测结果与真实值之间的差异。通过最小化损失函数,模型逐步优化参数,提升预测能力。
常见损失函数分类
(1) 回归任务
-
均方误差(Mean Squared Error, MSE)
- 公式:

-
- 特点:
- 对离群值敏感(平方放大大误差)。
- 适用于连续值预测(如房价预测、温度预测)。
- 特点:
-
平均绝对误差(Mean Absolute Error, MAE)
- 公式:

-
- 特点:
- 对离群值鲁棒性强(线性惩罚)。
- 梯度不连续(在零点不可导),优化速度较慢。
- 特点:
-
Huber损失
- 公式:
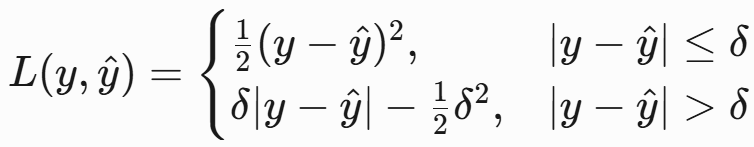
-
- 特点:
- 结合MSE和MAE,对离群值鲁棒且优化稳定。
- 超参数 需调优(通常取1.35)。
- 特点:
(2) 分类任务
-
交叉熵损失(Cross-Entropy Loss)
- 二分类公式(二元交叉熵):
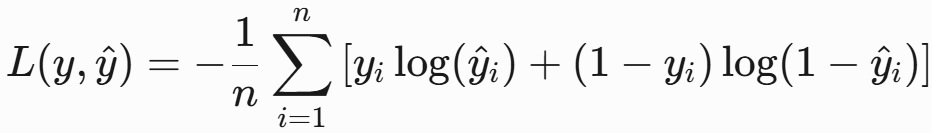
-
- 多分类公式(Softmax交叉熵):

-
- 特点:
- 适用于概率输出(如逻辑回归、神经网络)。
- 对预测错误(如概率接近0或1时)惩罚大,梯度更新高效。
- 特点:
-
Hinge损失(支持向量机损失)
- 公式:
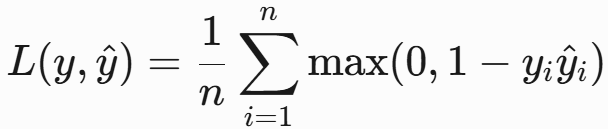
-
- 特点:
- 用于SVM,关注分类边界的样本(间隔最大化)。
- 对正确分类且置信度高的样本不惩罚(损失为0)。
- 特点:
-
Focal Loss
- 公式:

-
- 特点:
- 解决类别不平衡问题(如目标检测中的背景-前景不平衡)。
- 超参数 调整困难样本的权重()。
- 特点:
(3) 其他任务
-
对比损失(Contrastive Loss)
- 应用:度量学习(如人脸识别、嵌入学习)。
- 公式:
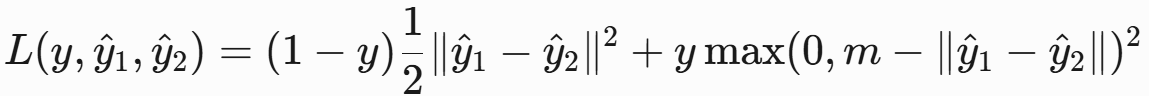
-
-
- 表示同类样本,拉近距离; 表示不同类样本,推开距离至间隔 以上。
-
-
KL散度(Kullback-Leibler Divergence)
- 公式:
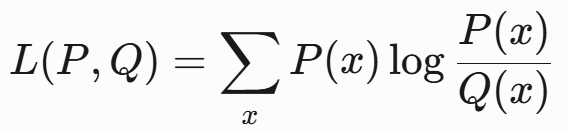
-
- 特点:
- 衡量两个概率分布的差异(如生成对抗网络、变分自编码器)。
- 特点:
损失函数的选择原则
-
任务类型:
- 回归任务:MSE、MAE、Huber。
- 分类任务:交叉熵、Hinge、Focal Loss。
-
数据分布:
- 离群值多:Huber、MAE。
- 类别不平衡:Focal Loss、加权交叉熵。
-
模型输出:
- 概率输出(如Softmax):交叉熵。
- 直接预测值(如线性回归):MSE。
-
优化效率:
- 交叉熵的梯度更新比均方误差更高效(尤其对概率模型)。
损失函数与梯度下降的关系
- 梯度计算:梯度下降依赖损失函数的一阶导数(如交叉熵的梯度与误差成比例)。
- 学习率调整:不同损失函数的梯度幅度差异大,需动态调整学习率(如Adam优化器)。
- 非凸优化:分类任务中交叉熵损失通常比平方损失更易优化(避免局部最优)。
实际应用技巧
- 多任务学习:多个损失函数加权组合(如目标检测中的分类+回归损失)。
- 自定义损失:根据业务需求设计(如推荐系统中的点击率+转化率联合优化)。
- 鲁棒性处理:
- 对噪声数据:使用Huber、MAE。
- 对异常值:Welsch损失(指数衰减大误差)。
代码示例(PyTorch)
# 回归任务:MSE
loss_fn = nn.MSELoss()
# 分类任务:交叉熵
loss_fn = nn.CrossEntropyLoss() # 内部包含Softmax
# 自定义加权交叉熵(处理类别不平衡)
weights = torch.tensor([0.1, 0.9]) # 类别权重
loss_fn = nn.CrossEntropyLoss(weight=weights)
# Focal Loss(需自定义实现)
class FocalLoss(nn.Module):
def __init__(self, alpha=0.25, gamma=2):
super().__init__()
self.alpha = alpha
self.gamma = gamma
def forward(self, inputs, targets):
BCE_loss = F.binary_cross_entropy_with_logits(inputs, targets, reduction='none')
pt = torch.exp(-BCE_loss)
loss = self.alpha * (1 - pt)**self.gamma * BCE_loss
return loss.mean()总结
损失函数是模型优化的指南针,其选择直接影响训练效率和最终性能:
- 回归任务:优先考虑MSE、MAE或Huber。
- 分类任务:交叉熵是默认选择,类别不平衡时用Focal Loss。
- 复杂任务:可组合多个损失函数或自定义设计(如对比学习)。
- 实践要点:结合数据特点、任务需求和模型结构灵活调整,并通过实验验证效果。
正规⽅程的推导
推导⽅式⼀:
把该损失函数转换成矩阵写法:

y是真实值矩阵,X是特征值矩阵,w是权重矩阵
求解关于w的最⼩值,其实就是在y,X 均已知的情况下,求解![]() 的最小值,很明显,
的最小值,很明显,![]() 关于W的函数的图像,是一个开口向上的抛物线,因此我们主需要对⼆次函数直接求导,导数为零的位置,即为最⼩值。
关于W的函数的图像,是一个开口向上的抛物线,因此我们主需要对⼆次函数直接求导,导数为零的位置,即为最⼩值。
求导:

另⼀种推导⽅式
把损失函数分开书写:
![]()
对展开上式进⾏求导:

需要求得求导函数的极⼩值,即上式求导结果为0,经过化解,得结果为:
![]()
经过化解为:
![]()
补充:需要⽤到的矩阵求导公式:

详解梯度下降算法
相关概念复习
在详细了解梯度下降的算法之前,我们先复习相关的⼀些概念。
- 步⻓(Learning rate):
- 步⻓决定了在梯度下降迭代的过程中,每⼀步沿梯度负⽅向前进的⻓度。⽤前⾯下⼭的例⼦,步⻓就是在当前这⼀步所在位置沿着最陡峭最易下⼭的位置⾛的那⼀步的⻓度。
- 特征(feature):
- 指的是样本中输⼊部分,⽐如2个单特征的样本(x (0) , y (0)),(x (1) , y (1)),则第⼀个样本特征为x (0),第⼀个样本输出为y (0)。
- 假设函数(hypothesis function):
- 在监督学习中,为了拟合输⼊样本,⽽使⽤的假设函数,记为hθ(x)。⽐如对于单个特征的m个样本(x (i) , y (i))(i = 1, 2, ...m),可以采⽤拟合函数如下: hθ(x) = θ0 + θ1x。
- 损失函数(loss function):
- 为了评估模型拟合的好坏,通常⽤损失函数来度量拟合的程度。损失函数极⼩化,意味着拟合程度最好,对应的模型参数即为最优参数。
- 在线性回归中,损失函数通常为样本输出和假设函数的差取平⽅。⽐如对于m个样本(xi, yi)(i = 1, 2, ...m),采⽤线性回归,损失函数为:
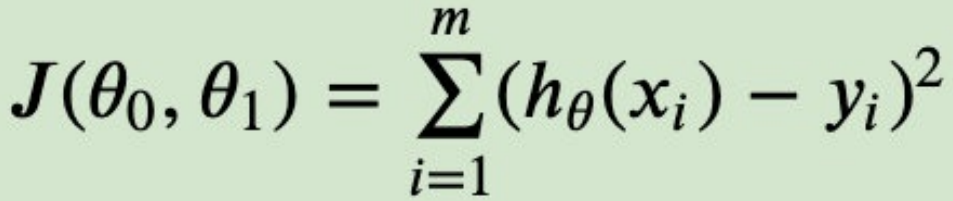
其中xi表示第i个样本特征,yi表示第i个样本对应的输出,hθ(xi)为假设函数
梯度下降法推导流程
1) 先决条件: 确认优化模型的假设函数和损失函数。
⽐如对于线性回归,假设函数表示为 hθ(x1, x2, ..., xn) = θ0 + θ1x1 + ... + θnxn, 其中θi(i = 0, 1, 2...n)为模型参数,xi(i = 0, 1, 2...n)为每个样本的n个特征值。我们增加⼀个特征x0 = 1 ,假设函数可以简化这样:
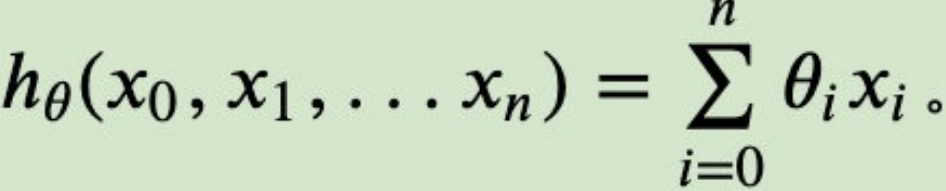
同样是线性回归,对应于上⾯的假设函数,损失函数为:

这里的1/2m纯属是为了后面好计算,因为后面的求导会有一个2乘到前面
2) 算法相关参数初始化,
主要是初始化θ0, θ1..., θn,算法终⽌距离ε以及步⻓α 。在没有任何先验知识的时候,我喜欢将所有的θ 初始化为0, 将步⻓初始化为1。在调优的时候再优化。
3) 算法过程:
3.1) 确定当前位置的损失函数的梯度,对于θi,其梯度表达式如下:

3.2) ⽤步⻓乘以损失函数的梯度,得到当前位置下降的距离,即
![]()
对应于前⾯登⼭例⼦中的某⼀步。
3.3) 确定是否所有的θi,梯度下降的距离都⼩于ε,如果⼩于ε则算法终⽌,当前所有的θi(i = 0, 1, ...n)即为最终结果。否则进⼊步骤4.
4)更新所有的θ ,对于θi,其更新表达式如下。更新完毕后继续转⼊步骤1.
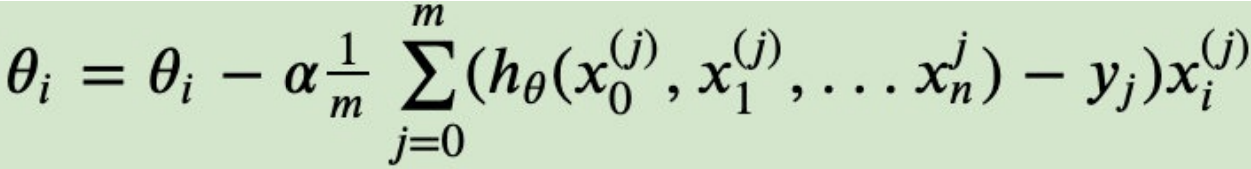
下⾯⽤线性回归的例⼦来具体描述梯度下降。假设我们的样本是:
![]()
损失函数如前⾯先决条件所述:
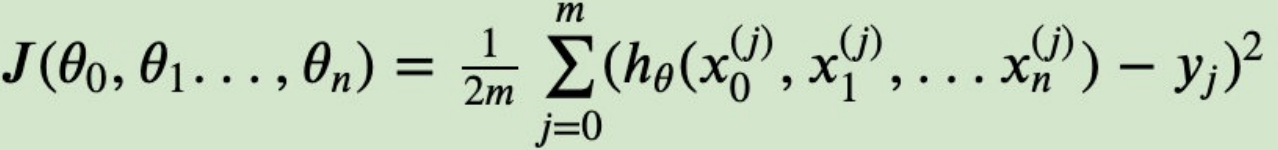
则在算法过程步骤1中对于θi 的偏导数计算如下:

由于样本中没有x0,上式中令所有的![]() 为1.
为1.
步骤4中θi的更新表达式如下:

从这个例⼦可以看出当前点的梯度⽅向是由所有的样本决定的,加1/m 是为了好理解。由于步⻓也为常数,他们的乘积也为常数,所以这⾥![]() 可以⽤⼀个常数表示。
可以⽤⼀个常数表示。
在下⾯⼀节中,咱们会详细讲到梯度下降法的变种,他们主要的区别就是对样本的采⽤⽅法不同。这⾥我们采⽤的是⽤所有样本。
思考:MSE和最⼩⼆乘法的区别是?
MSE(Mean Squared Error,均方误差)
- 定义:预测值与真实值之间平方误差的平均值,用于衡量模型预测的准确性。
- 公式:
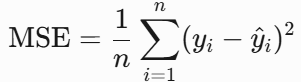
- 用途:作为损失函数或评估指标,适用于回归任务。
最小二乘法(Least Squares Method)
- 定义:一种通过最小化误差平方之和来估计模型参数的优化方法。
- 公式:

- 用途:主要用于线性回归模型的参数求解。
| MSE(均方误差) | 最小二乘法 | |
|---|---|---|
| 本质 | 一种损失函数或评估指标。 | 一种参数估计方法(优化目标是最小化平方误差之和)。 |
| 数学表达式 | 包含平均项()。 | 直接最小化平方误差之和(无平均项)。 |
| 应用范围 | 可用于任何模型的评估(如神经网络、树模型)。 | 主要应用于线性模型的参数估计。 |
| 计算复杂度 | 计算简单,仅用于评估。 | 可能需要矩阵求逆(解析解)或迭代优化(数值解)。 |
| 是否涉及正则化 | 通常不包含正则化项。 | 可扩展为带正则化的版本(如岭回归、Lasso)。 |
-
归一化处理的影响:
- MSE 的归一化(除以 )使得损失值在不同样本量下可比,但最小二乘法的参数估计不受归一化影响。
4. 应用场景对比
-
MSE的应用:
- 作为损失函数:用于训练模型(如神经网络、梯度下降优化的线性模型)。
- 作为评估指标:衡量模型在测试集上的性能。
-
最小二乘法的应用:
- 解析解场景:直接通过矩阵运算求解线性回归参数()。
- 数值解场景:当数据量过大或矩阵不可逆时,使用梯度下降等迭代方法最小化平方误差之和。
5. 直观示例
假设有以下数据(简单线性回归):
| 1 | 2 |
| 2 | 4 |
| 3 | 5 |
-
最小二乘法的目标:找到一条直线 ,使得:
通过解析解或迭代法求得 和 。
-
MSE的作用:
- 训练阶段:作为损失函数指导参数优化(如梯度下降)。
- 测试阶段:计算模型在测试集上的 MSE 值(例如 MSE = 0.5)
| 本质差异 | MSE 是误差的统计量,最小二乘法是参数估计方法。 |
- 最小二乘法是求解工具,MSE 是评估标准。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号